09. Implementación del modelo PyTorch¶
Bienvenido al Proyecto Milestone 3: ¡Implementación del modelo PyTorch!
Hemos recorrido un largo camino con nuestro proyecto FoodVision Mini.
Pero hasta ahora solo nosotros hemos podido acceder a nuestros modelos PyTorch.
¿Qué tal si le damos vida a FoodVision Mini y lo hacemos públicamente accesible?
En otras palabras, ¡vamos a implementar nuestro modelo FoodVision Mini en Internet como una aplicación utilizable!

Probando la versión implementada de FoodVision Mini (lo que vamos a crear) en mi almuerzo. ¡La modelo también acertó 🍣!
¿Qué es la implementación del modelo de aprendizaje automático?¶
Implementación del modelo de aprendizaje automático es el proceso de hacer que su modelo de aprendizaje automático sea accesible para alguien o algo más.
Alguien más es una persona que puede interactuar con tu modelo de alguna manera.
Por ejemplo, alguien que toma una fotografía de una comida con su teléfono inteligente y luego hace que nuestro modelo FoodVision Mini la clasifique en pizza, filete o sushi.
Otra cosa podría ser otro programa, aplicación o incluso otro modelo que interactúe con sus modelos de aprendizaje automático.
Por ejemplo, una base de datos bancaria podría depender de un modelo de aprendizaje automático que haga predicciones sobre si una transacción es fraudulenta o no antes de transferir fondos.
O un sistema operativo puede reducir su consumo de recursos basándose en un modelo de aprendizaje automático que hace predicciones sobre cuánta energía usa generalmente alguien en momentos específicos del día.
Estos casos de uso también se pueden mezclar y combinar.
Por ejemplo, el sistema de visión por computadora de un automóvil Tesla interactuará con el programa de planificación de rutas del automóvil (algo más) y luego el programa de planificación de rutas recibirá información y comentarios del conductor (otra persona).
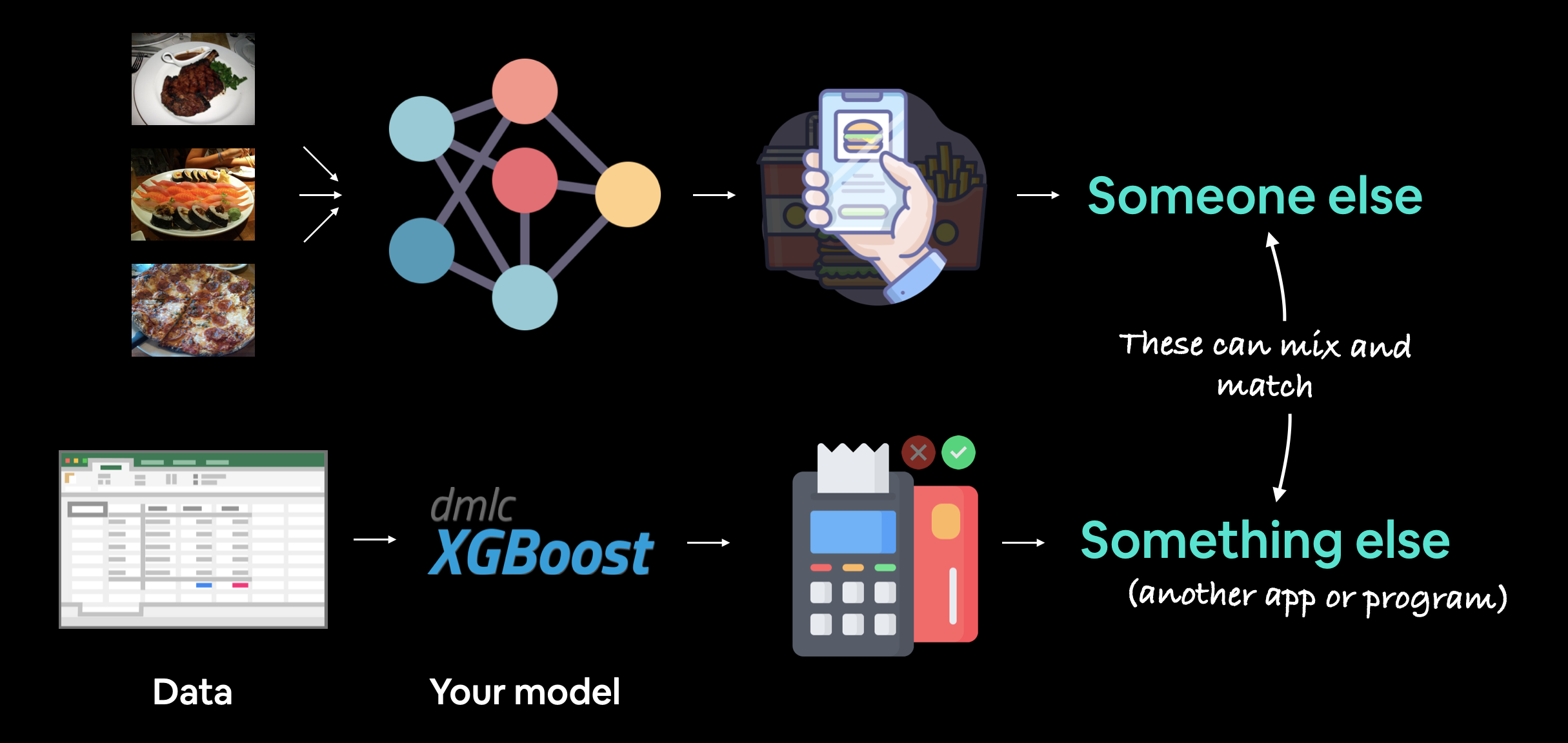
La implementación del modelo de aprendizaje automático implica poner su modelo a disposición de alguien o de algo más. Por ejemplo, alguien podría usar su modelo como parte de una aplicación de reconocimiento de alimentos (como FoodVision Mini o Nutrify). Y algo más podría ser otro modelo o programa que utilice su modelo, como un sistema bancario que utilice un modelo de aprendizaje automático para detectar si una transacción es fraudulenta o no.
¿Por qué implementar un modelo de aprendizaje automático?¶
Una de las cuestiones filosóficas más importantes en el aprendizaje automático es:

Implementar un modelo es tan importante como entrenarlo.
Porque aunque puedes tener una idea bastante clara de cómo funcionará tu modelo evaluándolo en un conjunto de pruebas bien diseñado o visualizando sus resultados, nunca sabes realmente cómo funcionará hasta que lo liberas.
Hacer que personas que nunca han usado su modelo interactúen con él a menudo revelará casos extremos en los que nunca pensó durante el entrenamiento.
Por ejemplo, ¿qué pasaría si alguien subiera una foto que no fuera de comida a nuestro modelo FoodVision Mini?
Una solución sería crear otro modelo que primero clasifique las imágenes como "comida" o "no comida" y pase primero la imagen de destino a través de ese modelo (esto es lo que hace Nutrify).
Luego, si la imagen es de "comida", pasa a nuestro modelo FoodVision Mini y se clasifica en pizza, bistec o sushi.
Y si "no es comida", se muestra un mensaje.
Pero ¿y si estas predicciones estuvieran equivocadas?
¿Qué pasa entonces?
Puedes ver cómo estas preguntas podrían continuar.
Por lo tanto, esto resalta la importancia de la implementación del modelo: le ayuda a descubrir errores en su modelo que no son obvios durante el entrenamiento/prueba.
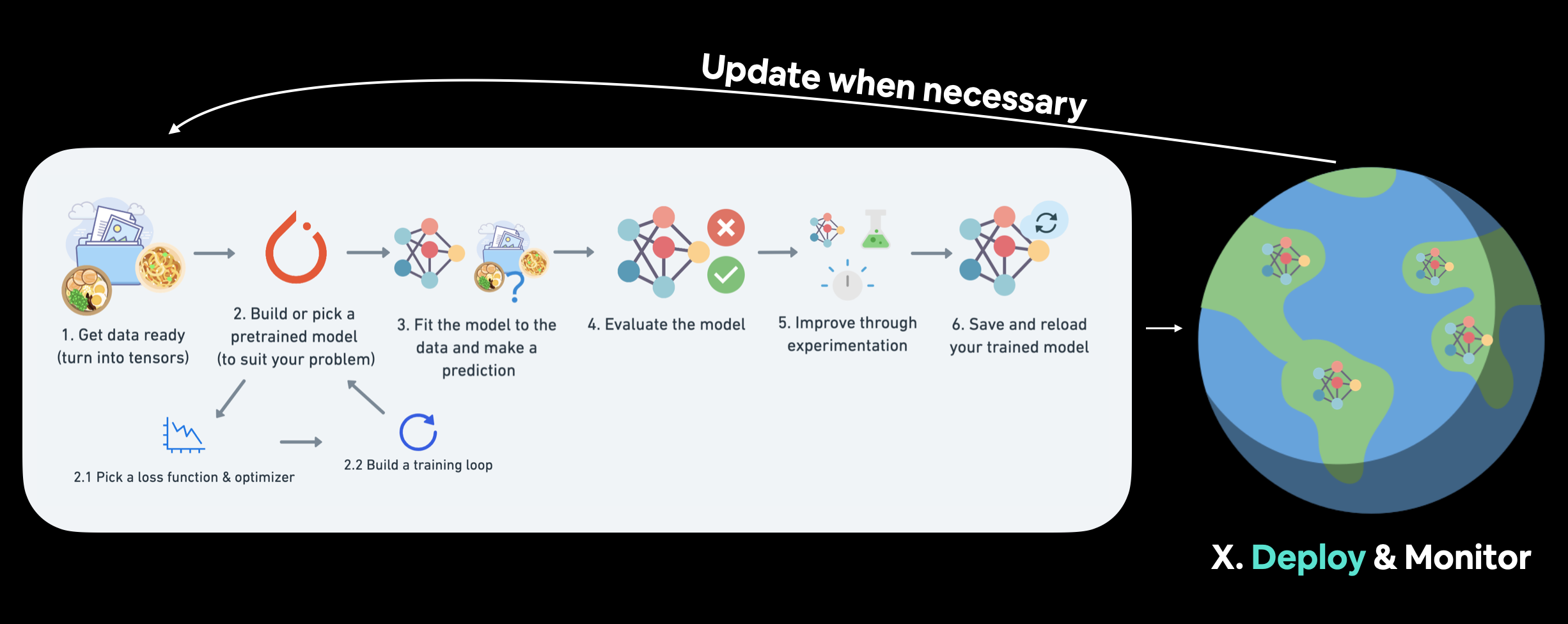
Cubrimos un flujo de trabajo de PyTorch en 01. Flujo de trabajo de PyTorch. Pero una vez que se tiene un buen modelo, la implementación es un buen siguiente paso. El monitoreo implica ver cómo funciona su modelo en la división de datos más importante: los datos del mundo real. Para obtener más recursos sobre implementación y monitoreo, consulte Recursos adicionales de PyTorch.
Diferentes tipos de implementación de modelos de aprendizaje automático¶
Se podrían escribir libros completos sobre los diferentes tipos de implementación de modelos de aprendizaje automático (y muchos buenos se enumeran en [Recursos adicionales de PyTorch](https://www.learnpytorch.io/pytorch_extra_resources/#resources-for-machine-learning-and -ingeniería-de-aprendizaje-profundo)).
Y el campo aún se está desarrollando en términos de mejores prácticas.
Pero me gusta empezar con la pregunta:
"¿Cuál es el escenario más ideal para utilizar mi modelo de aprendizaje automático?"
Y luego trabaje hacia atrás desde allí.
Por supuesto, es posible que no lo sepas de antemano. Pero eres lo suficientemente inteligente como para imaginar esas cosas.
En el caso de FoodVision Mini, nuestro escenario ideal podría ser:
- Alguien toma una foto en un dispositivo móvil (a través de una aplicación o navegador web).
- La predicción vuelve rápidamente.
Fácil.
Entonces tenemos dos criterios principales:
- El modelo debería funcionar en un dispositivo móvil (esto significa que habrá algunas restricciones informáticas).
- El modelo debe hacer predicciones rápidas (porque una aplicación lenta es una aplicación aburrida).
Y, por supuesto, según su caso de uso, sus requisitos pueden variar.
Puede notar que los dos puntos anteriores se dividen en otras dos preguntas:
- ¿A dónde irá? - Es decir, ¿dónde se almacenará?
- ¿Cómo va a funcionar? - Es decir, ¿devuelve predicciones inmediatamente? ¿O vienen más tarde?
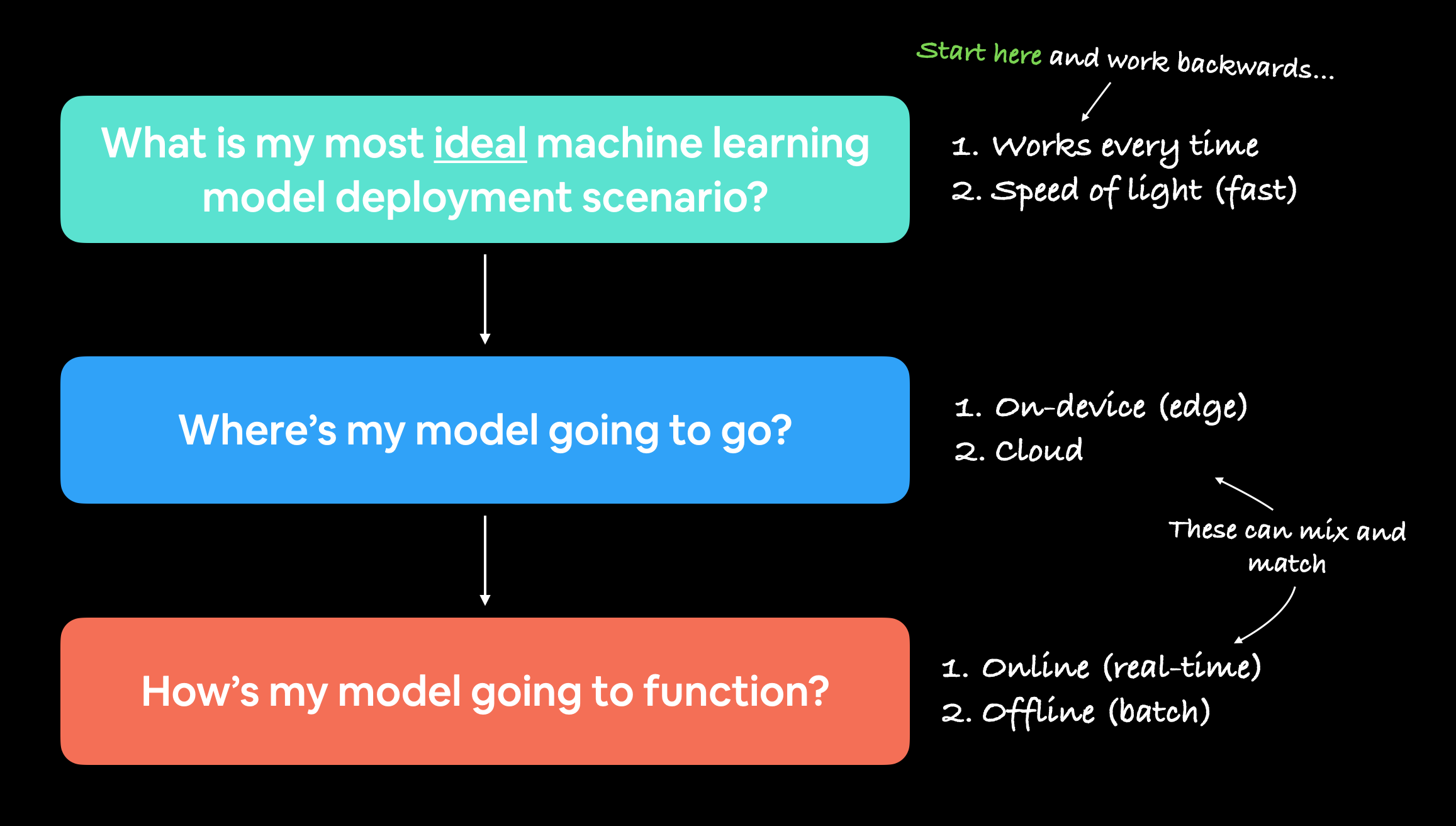
Al comenzar a implementar modelos de aprendizaje automático, es útil comenzar preguntando cuál es el caso de uso más ideal y luego trabajar hacia atrás desde allí, preguntando hacia dónde irá el modelo y luego cómo funcionará.
¿A dónde irá?¶
Cuando implementas tu modelo de aprendizaje automático, ¿dónde reside?
El debate principal aquí suele ser en el dispositivo (también llamado borde/en el navegador) o en la nube (una computadora/servidor que no es el dispositivo real desde donde alguien/algo llama al modelo).
Ambos tienen pros y contras.
| Ubicación de implementación | Ventajas | Desventajas |
|---|---|---|
| En el dispositivo (borde/en el navegador) | Puede ser muy rápido (ya que no salen datos del dispositivo) | Potencia informática limitada (los modelos más grandes tardan más en ejecutarse) |
| Preservación de la privacidad (nuevamente, ningún dato tiene que salir del dispositivo) | Espacio de almacenamiento limitado (se requiere un tamaño de modelo más pequeño) | |
| No se requiere conexión a Internet (a veces) | A menudo se requieren habilidades específicas del dispositivo | |
| En la nube | Potencia informática casi ilimitada (puede ampliarse cuando sea necesario) | Los costos pueden salirse de control (si no se aplican límites de escala adecuados) |
| Puede implementar un modelo y usarlo en todas partes (a través de API) | Las predicciones pueden ser más lentas debido a que los datos tienen que salir del dispositivo y las predicciones tienen que regresar (latencia de red) | |
| Vínculos con el ecosistema de nube existente | Los datos deben salir del dispositivo (esto puede causar problemas de privacidad) |
Hay más detalles sobre estos, pero dejé recursos en el extracurriculum para obtener más información.
Pongamos un ejemplo.
Si implementamos FoodVision Mini como una aplicación, queremos que funcione bien y rápido.
Entonces, ¿qué modelo preferiríamos?
- Un modelo en el dispositivo que funciona con una precisión del 95 % con un tiempo de inferencia (latencia) de un segundo por predicción.
- Un modelo en la nube que funciona con una precisión del 98 % con un tiempo de inferencia de 10 segundos por predicción (un modelo mejor y más grande, pero lleva más tiempo calcularlo).
He inventado estos números, pero muestran una diferencia potencial entre el dispositivo y la nube.
La opción 1 podría ser potencialmente un modelo más pequeño, de menor rendimiento y que funcione más rápido porque puede caber en un dispositivo móvil.
La opción 2 podría potencialmente ser un modelo más grande y con mayor rendimiento que requiere más computación y almacenamiento, pero tarda un poco más en ejecutarse porque tenemos que enviar datos desde el dispositivo y recuperarlos (por lo que, aunque la predicción real pueda ser rápida, el tiempo de red y la transferencia de datos debe tenerse en cuenta).
Para FoodVision Mini, probablemente preferiríamos la opción 1, porque el pequeño impacto en el rendimiento se ve superado con creces por la velocidad de inferencia más rápida.
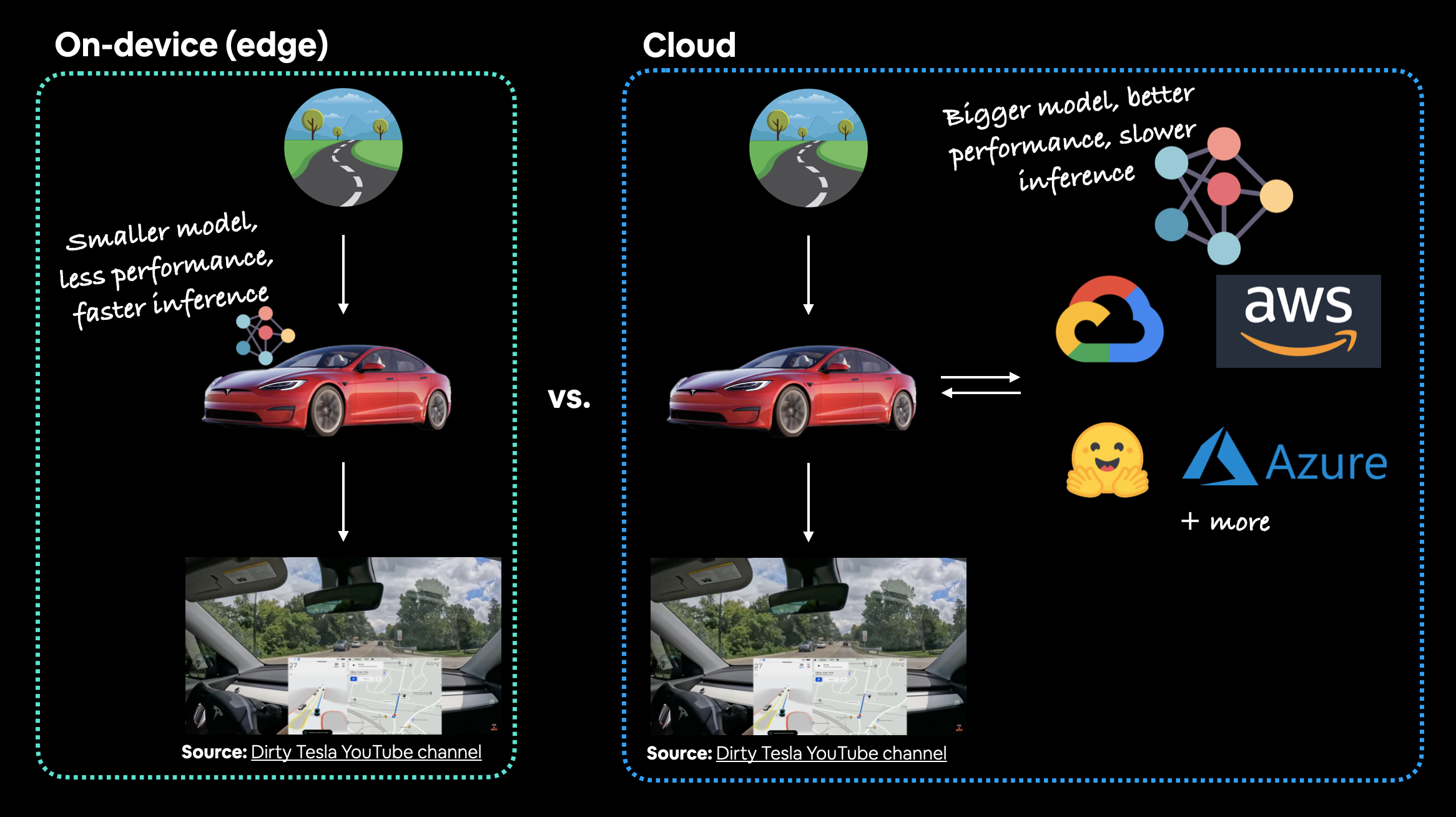
En el caso del sistema de visión por computadora de un automóvil Tesla, ¿cuál sería mejor? ¿Un modelo más pequeño que funciona bien en el dispositivo (el modelo está en el automóvil) o un modelo más grande que funciona mejor en la nube? En este caso, preferirías que el modelo estuviera en el auto. El tiempo de red adicional que tomaría para que los datos vayan del automóvil a la nube y luego de regreso al automóvil simplemente no valdría la pena (o incluso sería potencialmente imposible en áreas con mala señal).
Nota: Para ver un ejemplo completo de cómo es implementar un modelo de PyTorch en un dispositivo perimetral, consulte el [tutorial de PyTorch sobre cómo lograr inferencia en tiempo real (30 fps+)](https://pytorch.org/ tutorials/intermediate/realtime_rpi.html) con un modelo de visión por computadora en una Raspberry Pi.
¿Cómo va a funcionar?¶
Volviendo al caso de uso ideal, cuando implementa su modelo de aprendizaje automático, ¿cómo debería funcionar?
Es decir, ¿le gustaría que se le devolvieran las predicciones de inmediato?
¿O está bien que sucedan más tarde?
Estos dos escenarios generalmente se denominan:
- En línea (en tiempo real): las predicciones/inferencias ocurren inmediatamente. Por ejemplo, alguien sube una imagen, la imagen se transforma y se devuelven predicciones o alguien realiza una compra y un modelo verifica que la transacción no es fraudulenta para que la compra pueda realizarse.
- Sin conexión (por lotes): las predicciones/inferencias ocurren periódicamente. Por ejemplo, una aplicación de fotos clasifica sus imágenes en diferentes categorías (como playa, hora de comer, familia, amigos) mientras su dispositivo móvil está enchufado a la carga.
Nota: "Lote" se refiere a la inferencia que se realiza en varias muestras a la vez. Sin embargo, para agregar un poco de confusión, el procesamiento por lotes puede realizarse inmediatamente/en línea (se clasifican varias imágenes a la vez) y/o fuera de línea (se predicen/entrenan varias imágenes a la vez).
La principal diferencia entre cada ser: las predicciones se realizan de forma inmediata o periódica.
Periódicamente también puede tener una escala de tiempo variable, desde cada pocos segundos hasta cada pocas horas o días.
Y puedes mezclar y combinar los dos.
En el caso de FoodVision Mini, queremos que nuestro proceso de inferencia se realice en línea (en tiempo real), de modo que cuando alguien suba una imagen de pizza, bistec o sushi, los resultados de la predicción se devuelvan inmediatamente (cualquier cosa más lenta de lo que lo haría el tiempo real). hacer una experiencia aburrida).
Pero para nuestro proceso de capacitación, está bien que suceda por lotes (fuera de línea), que es lo que hemos estado haciendo a lo largo de los capítulos anteriores.
Formas de implementar un modelo de aprendizaje automático¶
Hemos analizado un par de opciones para implementar modelos de aprendizaje automático (en el dispositivo y en la nube).
Y cada uno de estos tendrá sus requisitos específicos:
| Herramienta/recurso | Tipo de implementación |
| ----- | ----- |
| Kit de aprendizaje automático de Google | En el dispositivo (Android e iOS) |
| Core ML de Apple y paquete Python coremltools | En el dispositivo (todos los dispositivos Apple) |
| Sagemaker de Amazon Web Service (AWS) | Nube |
| Vertex AI de Google Cloud | Nube |
| Aprendizaje automático de Azure de Microsoft | Nube |
| Abrazando espacios faciales | Nube |
| API con FastAPI | Servidor en la nube/autohospedado |
| API con TorchServe | Servidor en la nube/autohospedado |
| ONNX (Intercambio de redes neuronales abiertas) | Muchos/general |
| Muchos más... |
Nota: Una interfaz de programación de aplicaciones (API) es una forma en que dos (o más) programas informáticos interactúan entre sí. Por ejemplo, si su modelo se implementó como API, podría escribir un programa que pudiera enviarle datos y luego recibir predicciones.
La opción que elija dependerá en gran medida de lo que esté creando y con quién esté trabajando.
Pero con tantas opciones, puede resultar muy intimidante.
Así que lo mejor es empezar poco a poco y hacerlo sencillo.
Y una de las mejores formas de hacerlo es convertir su modelo de aprendizaje automático en una aplicación de demostración con Gradio y luego implementarlo en Hugging Face Spaces.
Más adelante haremos precisamente eso con FoodVision Mini.
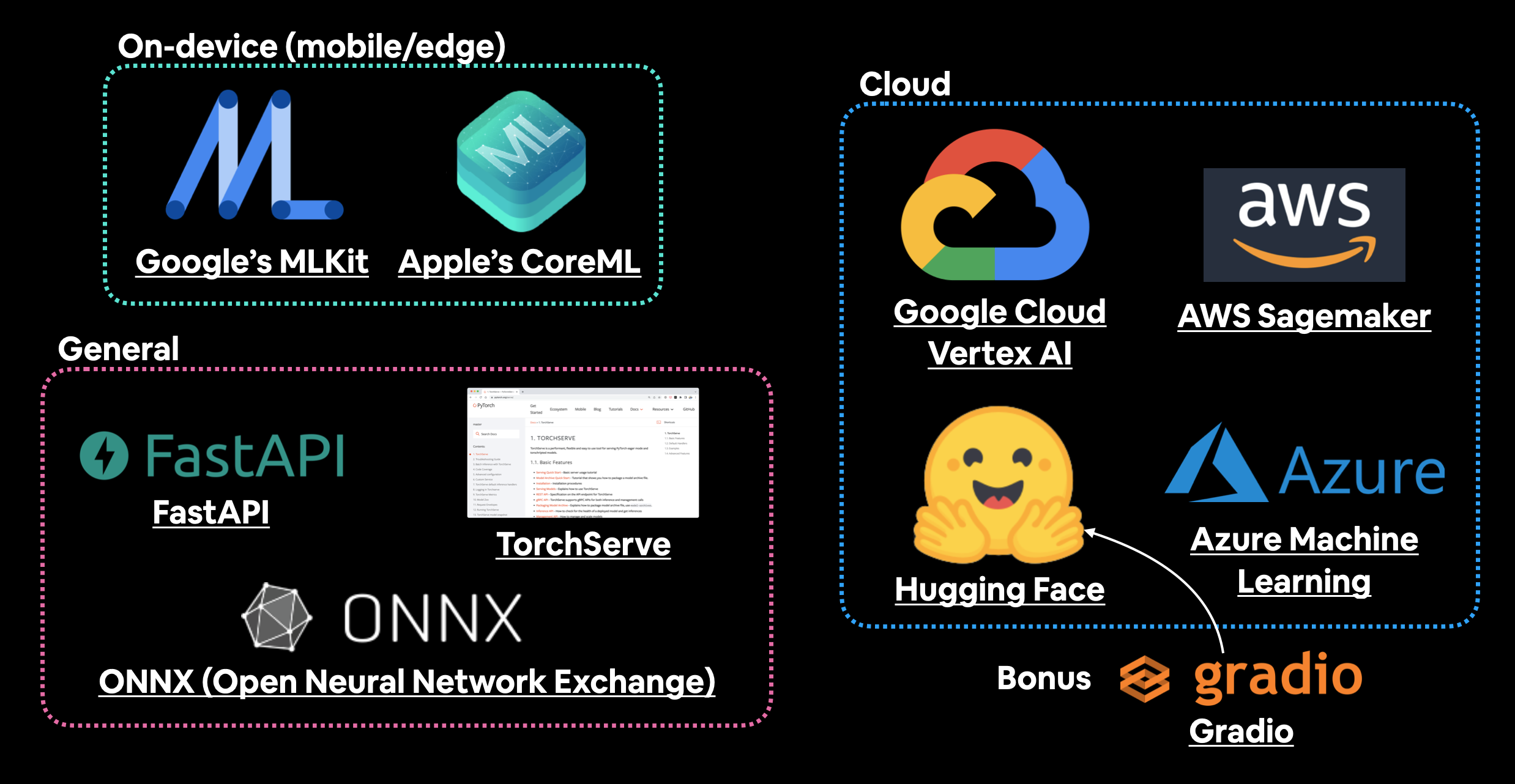
Un puñado de lugares y herramientas para alojar e implementar modelos de aprendizaje automático. Hay muchas cosas que me he perdido, así que si desea agregar más, deje una discusión en GitHub.
Qué vamos a cubrir¶
Ya basta de hablar de implementar un modelo de aprendizaje automático.
Convirtámonos en ingenieros de aprendizaje automático e implementemos uno.
Nuestro objetivo es implementar nuestro modelo FoodVision a través de una aplicación de demostración de Gradio con las siguientes métricas:
- Rendimiento: 95%+ precisión.
- Velocidad: inferencia en tiempo real de 30 FPS+ (cada predicción tiene una latencia inferior a ~0,03 s).
Comenzaremos ejecutando un experimento para comparar nuestros dos mejores modelos hasta el momento: extractores de funciones EffNetB2 y ViT.
Luego implementaremos el que se acerque más a nuestras métricas objetivo.
Finalmente, terminaremos con un (GRANDE) bono sorpresa.
| Tema | Contenido |
|---|---|
| 0. Obteniendo configuración | Hemos escrito bastante código útil en las últimas secciones, descarguémoslo y asegurémonos de poder usarlo nuevamente. |
| 1. Obtener datos | Descarguemos el conjunto de datos pizza_steak_sushi_20_percent.zip para que podamos entrenar nuestros modelos que anteriormente tenían mejor rendimiento en el mismo conjunto de datos. |
| 2. Esquema del experimento de implementación del modelo FoodVision Mini | Incluso en el proyecto del tercer hito, todavía realizaremos múltiples experimentos para ver qué modelo (EffNetB2 o ViT) se acerca más a nuestras métricas objetivo. |
| 3. Creando un extractor de funciones EffNetB2 | Un extractor de funciones EfficientNetB2 tuvo el mejor rendimiento en nuestro conjunto de datos de pizza, bistec y sushi en [07. Seguimiento de experimentos de PyTorch] (https://www.learnpytorch.io/07_pytorch_experiment_tracking/), vamos a recrearlo como candidato para su implementación. |
| 4. Creando un extractor de funciones ViT | Un extractor de funciones ViT ha sido el modelo con mejor rendimiento hasta ahora en nuestro conjunto de datos de pizza, bistec y sushi en 08. PyTorch Paper Replicating, vamos a recrearlo como candidato para su implementación junto con EffNetB2. |
| 5. Hacer predicciones con nuestros modelos entrenados y cronometrarlas | Hemos creado dos de los modelos con mejor rendimiento hasta el momento. Hagamos predicciones con ellos y realicemos un seguimiento de sus resultados. |
| 6. Comparación de resultados de modelos, tiempos de predicción y tamaño | Comparemos nuestros modelos para ver cuál funciona mejor con nuestros objetivos. |
| 7. Dar vida a FoodVision Mini creando una demostración de Gradio | Uno de nuestros modelos funciona mejor que el otro (en términos de nuestros objetivos), así que ¡convirtámoslo en una demostración de aplicación funcional! |
| 8. Convirtiendo nuestra demostración de FoodVision Mini Gradio en una aplicación implementable | Nuestra demostración de la aplicación Gradio funciona localmente, ¡preparémosla para su implementación! |
| 9. Implementando nuestra demostración de Gradio en HuggingFace Spaces | ¡Llevemos FoodVision Mini a la web y hagámoslo accesible públicamente para todos! |
| 10. Creando una GRAN sorpresa | Hemos creado FoodVision Mini, es hora de dar un paso más. |
| 11. Desplegando nuestra GRAN sorpresa | Implementar una aplicación fue divertido, ¿qué tal si hacemos dos? |
¿Dónde puedes obtener ayuda?¶
Todos los materiales de este curso están disponibles en GitHub.
Si tiene problemas, puede hacer una pregunta en el curso [página de debates de GitHub] (https://github.com/mrdbourke/pytorch-deep-learning/discussions).
Y, por supuesto, está la documentación de PyTorch y los foros de desarrolladores de PyTorch, un lugar muy útil para todo lo relacionado con PyTorch.
0. Configuración¶
Como lo hicimos anteriormente, asegurémonos de tener todos los módulos que necesitaremos para esta sección.
Importaremos los scripts de Python (como data_setup.py y engine.py) que creamos en 05. PyTorch se vuelve modular.
Para hacerlo, descargaremos el directorio going_modular del repositorio pytorch-deep-learning (si aún no lo tenemos).
También obtendremos el paquete torchinfo si no está disponible.
torchinfo nos ayudará más adelante a darnos una representación visual de nuestro modelo.
Y dado que más adelante usaremos el paquete torchvision v0.13 (disponible a partir de julio de 2022), nos aseguraremos de tener las últimas versiones.
Nota: Si estás usando Google Colab y aún no tienes una GPU activada, ahora es el momento de activar una a través de
Runtime -> Cambiar tipo de tiempo de ejecución -> Acelerador de hardware -> GPU.
# Para que este portátil se ejecute con API actualizadas, necesitamos torch 1.12+ y torchvision 0.13+.
try:
import torch
import torchvision
assert int(torch.__version__.split(".")[1]) >= 12, "torch version should be 1.12+"
assert int(torchvision.__version__.split(".")[1]) >= 13, "torchvision version should be 0.13+"
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
except:
print(f"[INFO] torch/torchvision versions not as required, installing nightly versions.")
!pip3 install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
import torch
import torchvision
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
Nota: Si está utilizando Google Colab y la celda de arriba comienza a instalar varios paquetes de software, es posible que deba reiniciar su tiempo de ejecución después de ejecutar la celda de arriba. Después de reiniciar, puede ejecutar la celda nuevamente y verificar que tenga las versiones correctas de
torchytorchvision.
Ahora continuaremos con las importaciones regulares, configurando el código independiente del dispositivo y esta vez también obtendremos [helper_functions.py](https://github.com/mrdbourke/pytorch-deep-learning/blob/ main/helper_functions.py) script de GitHub.
El script helper_functions.py contiene varias funciones que creamos en secciones anteriores:
set_seeds()para configurar las semillas aleatorias (creadas en 07. Sección 0 de seguimiento de experimentos de PyTorch).download_data()para descargar una fuente de datos mediante un enlace (creado en [07. Sección 1 de seguimiento de experimentos de PyTorch] (https://www.learnpytorch.io/07_pytorch_experiment_tracking/#1-get-data)).plot_loss_curves()para inspeccionar los resultados del entrenamiento de nuestro modelo (creado en [04. PyTorch Custom Datasets sección 7.8](https://www.learnpytorch.io/04_pytorch_custom_datasets/#78-plot-the-loss-curves-of- modelo-0))
Nota: Puede ser una mejor idea que muchas de las funciones en el script
helper_functions.pyse fusionen engoing_modular/going_modular/utils.py, tal vez sea una extensión que le gustaría probar .
# Continuar con las importaciones regulares
import matplotlib.pyplot as plt
import torch
import torchvision
from torch import nn
from torchvision import transforms
# Intente obtener torchinfo, instálelo si no funciona
try:
from torchinfo import summary
except:
print("[INFO] Couldn't find torchinfo... installing it.")
!pip install -q torchinfo
from torchinfo import summary
# Intente importar el directorio going_modular, descárguelo de GitHub si no funciona
try:
from going_modular.going_modular import data_setup, engine
from helper_functions import download_data, set_seeds, plot_loss_curves
except:
# Get the going_modular scripts
print("[INFO] Couldn't find going_modular or helper_functions scripts... downloading them from GitHub.")
!git clone https://github.com/mrdbourke/pytorch-deep-learning
!mv pytorch-deep-learning/going_modular .
!mv pytorch-deep-learning/helper_functions.py . # get the helper_functions.py script
!rm -rf pytorch-deep-learning
from going_modular.going_modular import data_setup, engine
from helper_functions import download_data, set_seeds, plot_loss_curves
Finalmente, configuraremos un código independiente del dispositivo para asegurarnos de que nuestros modelos se ejecuten en la GPU.
device = "cuda" if torch.cuda.is_available() else "cpu"
device
1. Obtener datos¶
Lo dejamos en 08. PyTorch Paper Replicating comparando nuestro propio modelo de extractor de funciones Vision Transformer (ViT) con El modelo de extracción de características EfficientNetB2 (EffNetB2) que creamos en 07. Seguimiento de experimentos de PyTorch.
Y descubrimos que había una ligera diferencia en la comparación.
El modelo EffNetB2 se entrenó en el 20 % de los datos de pizza, bistec y sushi de Food101, mientras que el modelo ViT se entrenó en el 10 %.
Dado que nuestro objetivo es implementar el mejor modelo para nuestro problema FoodVision Mini, comencemos descargando el [conjunto de datos del 20 % de pizza, bistec y sushi] (https://github.com/mrdbourke/pytorch-deep-learning/blob/main /data/pizza_steak_sushi_20_percent.zip) y entrene un extractor de funciones EffNetB2 y un extractor de funciones ViT en él y luego compare los dos modelos.
De esta manera, compararemos manzanas con manzanas (un modelo entrenado en un conjunto de datos con otro modelo entrenado en el mismo conjunto de datos).
Nota: El conjunto de datos que estamos descargando es una muestra de todo el conjunto de datos de Food101 (101 clases de comida con 1.000 imágenes cada una). Más específicamente, 20% se refiere al 20% de imágenes de las clases de pizza, bistec y sushi seleccionadas al azar. Puede ver cómo se creó este conjunto de datos en
extras/04_custom_data_creation.ipynby más detalles en [ 04. Sección 1 de conjuntos de datos personalizados de PyTorch] (https://www.learnpytorch.io/04_pytorch_custom_datasets/#1-get-data).
Podemos descargar los datos usando la función download_data() que creamos en 07. Sección 1 de seguimiento de experimentos de PyTorch de [helper_functions.py](https://github.com/mrdbourke/pytorch-deep-learning /blob/main/helper_functions.py).
# Descargue imágenes de pizza, bistec y sushi desde GitHub
data_20_percent_path = download_data(source="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi_20_percent.zip",
destination="pizza_steak_sushi_20_percent")
data_20_percent_path
¡Maravilloso!
Ahora que tenemos un conjunto de datos, creemos rutas de entrenamiento y prueba.
# Configurar rutas de directorio para entrenar y probar imágenes
train_dir = data_20_percent_path / "train"
test_dir = data_20_percent_path / "test"
2. Esquema del experimento de implementación del modelo FoodVision Mini¶
El modelo implementado ideal, FoodVision Mini, funciona bien y rápido.
Nos gustaría que nuestro modelo funcione lo más cerca posible del tiempo real.
En este caso, el tiempo real es ~30 FPS (cuadros por segundo) porque eso es [aproximadamente qué tan rápido puede ver el ojo humano] (https://www.healthline.com/health/human-eye-fps) (hay debate sobre esto, pero usemos ~30FPS como nuestro punto de referencia).
Y para clasificar tres clases diferentes (pizza, bistec y sushi), nos gustaría un modelo que funcione con una precisión superior al 95 %.
Por supuesto, una mayor precisión sería buena, pero esto podría sacrificar la velocidad.
Entonces nuestros objetivos son:
- Rendimiento: un modelo que funciona con una precisión superior al 95 %.
- Velocidad: un modelo que puede clasificar una imagen a ~30 FPS (tiempo de inferencia de 0,03 segundos por imagen, también conocido como latencia).
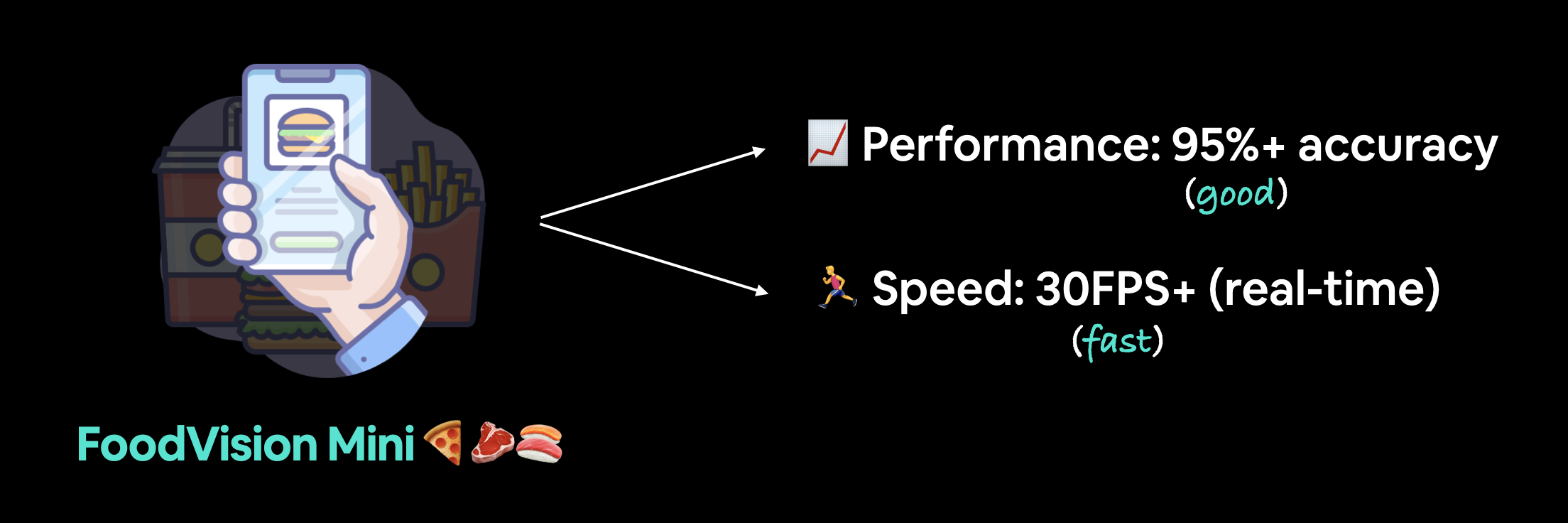
Objetivos de implementación de FoodVision Mini. Nos gustaría un modelo de predicción rápida y con buen rendimiento (porque una aplicación lenta es aburrida).
Pondremos énfasis en la velocidad, es decir, preferiríamos un modelo con un rendimiento superior al 90 % a ~30 FPS que un modelo con un rendimiento superior al 95 % a 10 FPS.
Para intentar lograr estos resultados, incluyamos nuestros modelos con mejor rendimiento de las secciones anteriores:
- Extractor de funciones EffNetB2 (EffNetB2 para abreviar): creado originalmente en 07. Sección 7.5 de seguimiento de experimentos de PyTorch usando [
torchvision.models.ficientnet_b2()](https://pytorch.org /vision/stable/models/generated/torchvision.models.ficientnet_b2.html#ficientnet-b2) con capas declasificadorajustadas. - Extractor de funciones ViT-B/16 (ViT para abreviar): creado originalmente en [08. Sección 10 de replicación de papel de PyTorch] (https://www.learnpytorch.io/08_pytorch_paper_replicating/#10-using-a-pretrained-vit-from-torchvisionmodels-on-the-same-dataset) usando
torchvision.models.vit_b_16 ()con capas decabezaajustadas.- Nota ViT-B/16 significa "Vision Transformer Base, tamaño de parche 16".
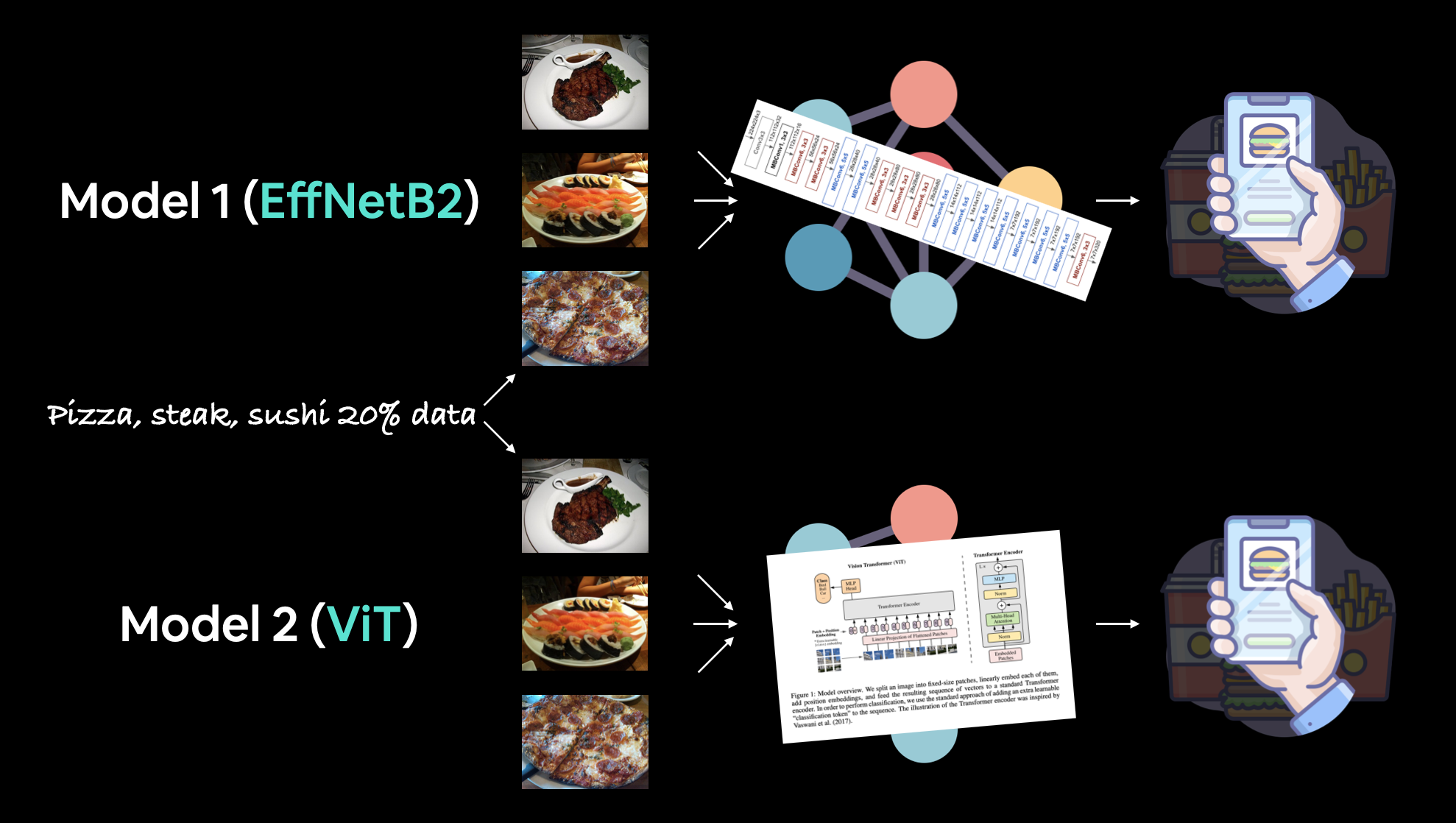
Nota: Un "modelo de extracción de características" a menudo comienza con un modelo que ha sido previamente entrenado en un conjunto de datos similar a su propio problema. Las capas base del modelo previamente entrenado a menudo se dejan congeladas (los patrones/pesos previamente entrenados permanecen iguales) mientras que algunas de las capas superiores (o clasificador/cabeza de clasificación) se personalizan según su propio problema entrenando con sus propios datos. Cubrimos el concepto de un modelo de extracción de características en [06. Sección 3.4 de aprendizaje por transferencia de PyTorch] (https://www.learnpytorch.io/06_pytorch_transfer_learning/#34-freezing-the-base-model-and-changing-the-output-layer-to-suit-our-needs).
3. Creando un extractor de funciones EffNetB2¶
Primero creamos un modelo de extracción de características EffNetB2 en [07. Sección 7.5 de seguimiento de experimentos de PyTorch] (https://www.learnpytorch.io/07_pytorch_experiment_tracking/#75-create-feature-extractor-models).
Y al final de esa sección vimos que funcionó muy bien.
Así que ahora vamos a recrearlo aquí para que podamos comparar sus resultados con un extractor de funciones de ViT entrenado con los mismos datos.
Para hacerlo podemos:
- Configure los pesos previamente entrenados como
weights=torchvision.models.EfficientNet_B2_Weights.DEFAULT, donde "DEFAULT" significa "mejor disponible actualmente" (o podría usarweights="DEFAULT"). - Obtenga las transformaciones de la imagen del modelo previamente entrenado a partir de los pesos con el método
transforms()(los necesitamos para poder convertir nuestras imágenes al mismo formato en el que se entrenó el EffNetB2 previamente entrenado). - Cree una instancia de modelo previamente entrenada pasando los pesos a una instancia de [
torchvision.models.ficientnet_b2](https://pytorch.org/vision/stable/models/generated/torchvision.models.ficientnet_b2.html#ficientnet -b2). - Congele las capas base en el modelo.
- Actualizar el cabezal del clasificador para adaptarlo a nuestros propios datos.
# 1. Configurar pesas EffNetB2 previamente entrenadas
effnetb2_weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
# 2. Obtenga transformaciones EffNetB2
effnetb2_transforms = effnetb2_weights.transforms()
# 3. Configurar el modelo previamente entrenado
effnetb2 = torchvision.models.efficientnet_b2(weights=effnetb2_weights) # could also use weights="DEFAULT"
# 4. Congele las capas base en el modelo (esto congelará todas las capas para empezar)
for param in effnetb2.parameters():
param.requires_grad = False
Ahora, para cambiar el encabezado del clasificador, primero inspeccionémoslo usando el atributo "clasificador" de nuestro modelo.
# Consulte el cabezal clasificador EffNetB2
effnetb2.classifier
¡Excelente! Para cambiar el encabezado del clasificador para adaptarlo a nuestro propio problema, reemplacemos la variable out_features con el mismo número de clases que tenemos (en nuestro caso, out_features=3, una para pizza, bistec, sushi).
Nota: Este proceso de cambiar las capas de salida/cabezal clasificador dependerá del problema en el que esté trabajando. Por ejemplo, si quisiera un número diferente de salidas o un tipo diferente de salida, tendría que cambiar las capas de salida en consecuencia.
# 5. Actualice el cabezal del clasificador.
effnetb2.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True), # keep dropout layer same
nn.Linear(in_features=1408, # keep in_features same
out_features=3)) # change out_features to suit our number of classes
¡Hermoso!
3.1 Creando una función para hacer un extractor de características EffNetB2¶
Parece que nuestro extractor de funciones EffNetB2 está listo para funcionar; sin embargo, dado que aquí hay bastantes pasos involucrados, ¿qué tal si convertimos el código anterior en una función que podamos reutilizar más adelante?
Lo llamaremos create_effnetb2_model() y necesitará un número personalizable de clases y un parámetro inicial aleatorio para su reproducibilidad.
Idealmente, devolverá un extractor de funciones EffNetB2 junto con sus transformaciones asociadas.
def create_effnetb2_model(num_classes:int=3,
seed:int=42):
"""Creates an EfficientNetB2 feature extractor model and transforms.
Args:
num_classes (int, optional): number of classes in the classifier head.
Defaults to 3.
seed (int, optional): random seed value. Defaults to 42.
Returns:
model (torch.nn.Module): EffNetB2 feature extractor model.
transforms (torchvision.transforms): EffNetB2 image transforms.
"""
# 1, 2, 3. Create EffNetB2 pretrained weights, transforms and model
weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.efficientnet_b2(weights=weights)
# 4. Freeze all layers in base model
for param in model.parameters():
param.requires_grad = False
# 5. Change classifier head with random seed for reproducibility
torch.manual_seed(seed)
model.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True),
nn.Linear(in_features=1408, out_features=num_classes),
)
return model, transforms
¡Guau! Es una función muy bonita, probémosla.
effnetb2, effnetb2_transforms = create_effnetb2_model(num_classes=3,
seed=42)
Sin errores, genial, ahora para probarlo realmente, obtengamos un resumen con torchinfo.summary().
from torchinfo import summary
# # Imprimir resumen del modelo EffNetB2 (descomentar para obtener un resultado completo)
# resumen(effnetb2,
# tamaño_entrada=(1, 3, 224, 224),
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"])
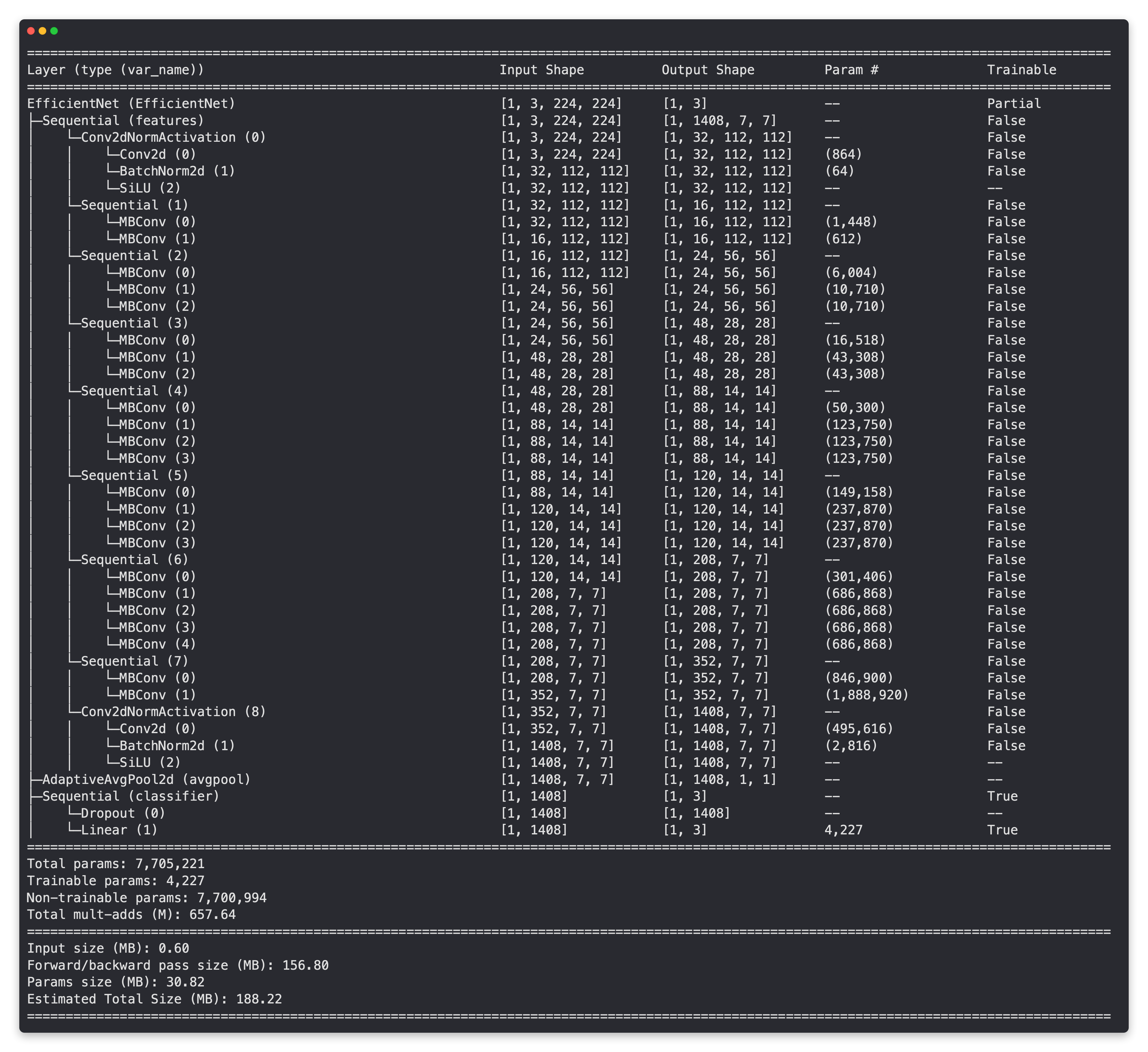
¡Capas base congeladas, capas superiores entrenables y personalizadas!
3.2 Creando cargadores de datos para EffNetB2¶
Nuestro extractor de funciones EffNetB2 está listo, es hora de crear algunos DataLoader.
Podemos hacer esto usando la función data_setup.create_dataloaders() que creamos en 05. PyTorch Going Modular sección 2.
Usaremos un batch_size de 32 y transformaremos nuestras imágenes usando effnetb2_transforms para que estén en el mismo formato en el que se entrenó nuestro modelo effnetb2.
# Configurar cargadores de datos
from going_modular.going_modular import data_setup
train_dataloader_effnetb2, test_dataloader_effnetb2, class_names = data_setup.create_dataloaders(train_dir=train_dir,
test_dir=test_dir,
transform=effnetb2_transforms,
batch_size=32)
3.3 Entrenamiento del extractor de funciones de EffNetB2¶
Modelo listo, DataLoaders listo, ¡entrenemos!
Al igual que en [07. Sección 7.6 de seguimiento de experimentos de PyTorch] (https://www.learnpytorch.io/07_pytorch_experiment_tracking/#76-create-experiments-and-set-up-training-code), diez épocas deberían ser suficientes para obtener buenos resultados.
Podemos hacerlo creando un optimizador (usaremos [torch.optim.Adam()](https://pytorch.org/docs/stable/generated/torch.optim.Adam.html#torch.optim .Adam) con una tasa de aprendizaje de 1e-3), una función de pérdida (usaremos [torch.nn.CrossEntropyLoss()](https://pytorch.org/docs/stable/generated/torch .nn.CrossEntropyLoss.html) para clasificación de clases múltiples) y luego pasarlos junto con nuestro DataLoaders al [engine.train()](https://github.com/mrdbourke/pytorch-deep -learning/blob/main/going_modular/going_modular/engine.py) función que creamos en 05. PyTorch Going Modular sección 4.
from going_modular.going_modular import engine
# Optimizador de configuración
optimizer = torch.optim.Adam(params=effnetb2.parameters(),
lr=1e-3)
# Función de pérdida de configuración
loss_fn = torch.nn.CrossEntropyLoss()
# Establezca semillas para la reproducibilidad y entrene el modelo.
set_seeds()
effnetb2_results = engine.train(model=effnetb2,
train_dataloader=train_dataloader_effnetb2,
test_dataloader=test_dataloader_effnetb2,
epochs=10,
optimizer=optimizer,
loss_fn=loss_fn,
device=device)
3.4 Inspeccionando las curvas de pérdida de EffNetB2¶
¡Lindo!
Como vimos en 07. Seguimiento de experimentos de PyTorch, el modelo de extracción de características EffNetB2 funciona bastante bien con nuestros datos.
Convirtamos sus resultados en curvas de pérdidas para inspeccionarlos más a fondo.
Nota: Las curvas de pérdida son una de las mejores formas de visualizar el rendimiento de su modelo. Para obtener más información sobre las curvas de pérdidas, consulte 04. Sección 8 de conjuntos de datos personalizados de PyTorch: ¿Cómo debería ser una curva de pérdida ideal?
from helper_functions import plot_loss_curves
plot_loss_curves(effnetb2_results)
¡Guau!
Esas son algunas curvas de pérdidas bonitas.
Parece que nuestro modelo está funcionando bastante bien y tal vez se beneficiaría de un entrenamiento un poco más largo y potencialmente de algo de [aumento de datos](https://www.learnpytorch.io/04_pytorch_custom_datasets/#6-other-forms-of-transforms-data -aumento) (para ayudar a prevenir un posible sobreajuste que se produzca debido a un entrenamiento más prolongado).
3.5 Guardar el extractor de funciones de EffNetB2¶
Ahora que tenemos un modelo entrenado con buen rendimiento, guardémoslo en un archivo para poder importarlo y usarlo más tarde.
Para guardar nuestro modelo podemos usar la función utils.save_model() que creamos en 05. PyTorch Going Modular sección 5.
Estableceremos target_dir en "models" y model_name en "09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth" (un poco completo, pero al menos sabemos lo que está pasando).
from going_modular.going_modular import utils
# guardar el modelo
utils.save_model(model=effnetb2,
target_dir="models",
model_name="09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth")
3.6 Comprobar el tamaño del extractor de funciones EffNetB2¶
Dado que uno de nuestros criterios para implementar un modelo que impulse FoodVision Mini es la velocidad (~30 FPS o mejor), verifiquemos el tamaño de nuestro modelo.
¿Por qué comprobar el tamaño?
Bueno, aunque no siempre es así, el tamaño de un modelo puede influir en su velocidad de inferencia.
Es decir, si un modelo tiene más parámetros, generalmente realiza más operaciones y cada una de estas operaciones requiere cierta potencia informática.
Y como nos gustaría que nuestro modelo funcione en dispositivos con potencia informática limitada (por ejemplo, en un dispositivo móvil o en un navegador web), generalmente, cuanto más pequeño sea el tamaño, mejor (siempre que siga funcionando bien en términos de precisión). .
Para verificar el tamaño de nuestro modelo en bytes, podemos usar pathlib.Path.stat("path_to_model").st_size de Python .stat) y luego podemos convertirlo (aproximadamente) a megabytes dividiéndolo por (1024*1024).
from pathlib import Path
# Obtenga el tamaño del modelo en bytes y luego conviértalo a megabytes
pretrained_effnetb2_model_size = Path("models/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth").stat().st_size // (1024*1024) # division converts bytes to megabytes (roughly)
print(f"Pretrained EffNetB2 feature extractor model size: {pretrained_effnetb2_model_size} MB")
3.7 Recopilación de estadísticas del extractor de funciones de EffNetB2¶
Tenemos algunas estadísticas sobre nuestro modelo de extractor de funciones EffNetB2, como pérdida de prueba, precisión de la prueba y tamaño del modelo. ¿Qué tal si las recopilamos todas en un diccionario para poder compararlas con el próximo extractor de funciones ViT?
Y calcularemos uno extra por diversión, el número total de parámetros.
Podemos hacerlo contando el número de elementos (o patrones/pesos) en effnetb2.parameters(). Accederemos al número de elementos en cada parámetro usando torch.numel() (abreviatura de "número de elementos ") método.
# Cuente el número de parámetros en EffNetB2
effnetb2_total_params = sum(torch.numel(param) for param in effnetb2.parameters())
effnetb2_total_params
¡Excelente!
Ahora pongamos todo en un diccionario para poder hacer comparaciones más adelante.
# Crear un diccionario con estadísticas de EffNetB2
effnetb2_stats = {"test_loss": effnetb2_results["test_loss"][-1],
"test_acc": effnetb2_results["test_acc"][-1],
"number_of_parameters": effnetb2_total_params,
"model_size (MB)": pretrained_effnetb2_model_size}
effnetb2_stats
¡Épico!
¡Parece que nuestro modelo EffNetB2 funciona con más del 95% de precisión!
Criterio número 1: actuar con una precisión superior al 95%, ¡marca!
4. Creación de un extractor de funciones ViT¶
Es hora de continuar con nuestros experimentos de modelado de FoodVision Mini.
Esta vez vamos a crear un extractor de funciones de ViT.
Y lo haremos de la misma manera que el extractor de funciones EffNetB2, excepto que esta vez con [torchvision.models.vit_b_16()](https://pytorch.org/vision/stable/models/generated/torchvision. models.vit_b_16.html#torchvision.models.vit_b_16) en lugar de torchvision.models.ficientnet_b2().
Comenzaremos creando una función llamada create_vit_model() que será muy similar a create_effnetb2_model() excepto, por supuesto, que devolverá un modelo extractor de características ViT y transformaciones en lugar de EffNetB2.
Otra pequeña diferencia es que la capa de salida de torchvision.models.vit_b_16() se llama cabezas en lugar de clasificador.
# Consulte la capa de cabezales ViT
vit = torchvision.models.vit_b_16()
vit.heads
Sabiendo esto, tenemos todas las piezas del rompecabezas que necesitamos.
def create_vit_model(num_classes:int=3,
seed:int=42):
"""Creates a ViT-B/16 feature extractor model and transforms.
Args:
num_classes (int, optional): number of target classes. Defaults to 3.
seed (int, optional): random seed value for output layer. Defaults to 42.
Returns:
model (torch.nn.Module): ViT-B/16 feature extractor model.
transforms (torchvision.transforms): ViT-B/16 image transforms.
"""
# Create ViT_B_16 pretrained weights, transforms and model
weights = torchvision.models.ViT_B_16_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.vit_b_16(weights=weights)
# Freeze all layers in model
for param in model.parameters():
param.requires_grad = False
# Change classifier head to suit our needs (this will be trainable)
torch.manual_seed(seed)
model.heads = nn.Sequential(nn.Linear(in_features=768, # keep this the same as original model
out_features=num_classes)) # update to reflect target number of classes
return model, transforms
¡La función de creación de modelos de extracción de características ViT está lista!
Probémoslo.
# Crear modelo ViT y transformaciones.
vit, vit_transforms = create_vit_model(num_classes=3,
seed=42)
Sin errores, ¡es encantador verlo!
Ahora obtengamos un resumen atractivo de nuestro modelo ViT usando torchinfo.summary().
from torchinfo import summary
# # Imprimir resumen del modelo del extractor de funciones de ViT (descomentar para obtener un resultado completo)
# resumen(vit,
# tamaño_entrada=(1, 3, 224, 224),
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"])
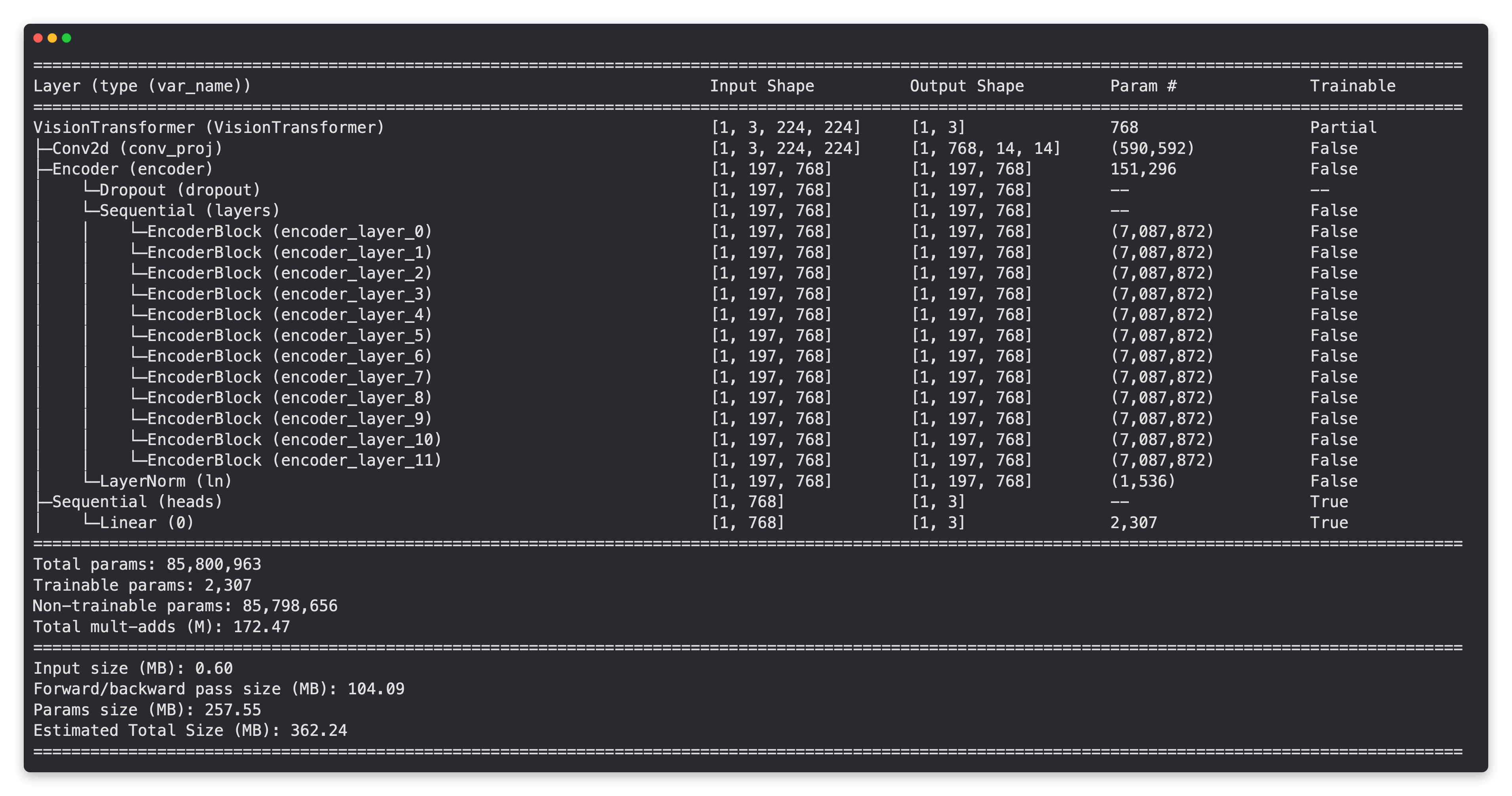
Al igual que nuestro modelo de extracción de funciones EffNetB2, las capas base de nuestro modelo ViT están congeladas y la capa de salida se personaliza según nuestras necesidades.
¿Notas la gran diferencia?
Nuestro modelo ViT tiene muchos más parámetros que nuestro modelo EffNetB2. Quizás esto entre en juego cuando comparemos nuestros modelos en cuanto a velocidad y rendimiento más adelante.
4.1 Crear cargadores de datos para ViT¶
Tenemos nuestro modelo ViT listo, ahora creemos algunos DataLoaders para él.
Haremos esto de la misma manera que hicimos para EffNetB2 excepto que usaremos vit_transforms para transformar nuestras imágenes al mismo formato en el que se entrenó el modelo ViT.
# Configurar cargadores de datos ViT
from going_modular.going_modular import data_setup
train_dataloader_vit, test_dataloader_vit, class_names = data_setup.create_dataloaders(train_dir=train_dir,
test_dir=test_dir,
transform=vit_transforms,
batch_size=32)
4.2 Extractor de funciones de ViT de entrenamiento¶
Sabes que hora es...
...es hora de entrenargggggg (cantado con la misma melodía que la canción Closing Time).
Entrenemos nuestro modelo de extracción de características ViT durante 10 épocas usando nuestra función engine.train() con torch.optim.Adam() y una tasa de aprendizaje de 1e-3 como nuestro optimizador y torch.nn.CrossEntropyLoss () como nuestra función de pérdida.
Usaremos nuestra función set_seeds() antes del entrenamiento para intentar que nuestros resultados sean lo más reproducibles posible.
from going_modular.going_modular import engine
# Optimizador de configuración
optimizer = torch.optim.Adam(params=vit.parameters(),
lr=1e-3)
# Función de pérdida de configuración
loss_fn = torch.nn.CrossEntropyLoss()
# Entrene el modelo ViT con semillas configuradas para lograr reproducibilidad
set_seeds()
vit_results = engine.train(model=vit,
train_dataloader=train_dataloader_vit,
test_dataloader=test_dataloader_vit,
epochs=10,
optimizer=optimizer,
loss_fn=loss_fn,
device=device)
4.3 Inspeccionando las curvas de pérdidas de ViT¶
Muy bien, está bien, está bien, modelo ViT entrenado, seamos visuales y veamos algunas curvas de pérdida.
Nota: No olvide que puede ver cómo debería verse un conjunto ideal de curvas de pérdida en [04. Sección 8 de conjuntos de datos personalizados de PyTorch] (https://www.learnpytorch.io/04_pytorch_custom_datasets/#8-what-should-an-ideal-loss-curve-look-like).
from helper_functions import plot_loss_curves
plot_loss_curves(vit_results)
¡Ohh si!
Esas son algunas curvas de pérdidas bonitas. Al igual que nuestro modelo de extracción de funciones EffNetB2, parece que nuestro modelo ViT podría beneficiarse de un tiempo de entrenamiento un poco más largo y tal vez algo de [aumento de datos](https://www.learnpytorch.io/04_pytorch_custom_datasets/#6-other-forms-of- transforma-datos-aumento) (para ayudar a prevenir el sobreajuste).
4.4 Guardar el extractor de funciones de ViT¶
¡Nuestro modelo ViT está funcionando de manera excelente!
Así que guardémoslo en un archivo para poder importarlo y usarlo más tarde si lo deseamos.
Podemos hacerlo usando la función utils.save_model() que creamos en 05. PyTorch Going Modular sección 5.
# guardar el modelo
from going_modular.going_modular import utils
utils.save_model(model=vit,
target_dir="models",
model_name="09_pretrained_vit_feature_extractor_pizza_steak_sushi_20_percent.pth")
4.5 Comprobar el tamaño del extractor de funciones ViT¶
Y como queremos comparar nuestro modelo EffNetB2 con nuestro modelo ViT en función de una serie de características, averigüemos su tamaño.
Para verificar el tamaño de nuestro modelo en bytes, podemos usar pathlib.Path.stat("path_to_model").st_size de Python y luego podemos convertirlo (aproximadamente) a megabytes dividiéndolo por (1024*1024).
from pathlib import Path
# Obtenga el tamaño del modelo en bytes y luego conviértalo a megabytes
pretrained_vit_model_size = Path("models/09_pretrained_vit_feature_extractor_pizza_steak_sushi_20_percent.pth").stat().st_size // (1024*1024) # division converts bytes to megabytes (roughly)
print(f"Pretrained ViT feature extractor model size: {pretrained_vit_model_size} MB")
Hmm, ¿cómo se compara el tamaño del modelo del extractor de funciones ViT con el tamaño de nuestro modelo EffNetB2?
Lo descubriremos en breve cuando comparemos todas las características de nuestro modelo.
4.6 Recopilación de estadísticas del extractor de funciones de ViT¶
Reunamos todas las estadísticas del modelo de extracción de funciones de ViT.
Lo vimos en el resumen anterior, pero calcularemos su número total de parámetros.
# Contar el número de parámetros en ViT
vit_total_params = sum(torch.numel(param) for param in vit.parameters())
vit_total_params
¡Vaya, eso parece bastante más que nuestro EffNetB2!
Nota: Una mayor cantidad de parámetros (o pesos/patrones) generalmente significa que un modelo tiene una mayor capacidad de aprender; si realmente utiliza esta capacidad adicional es otra historia. A la luz de esto, nuestro modelo EffNetB2 tiene 7.705.221 parámetros, mientras que nuestro modelo ViT tiene 85.800.963 (11,1 veces más), por lo que podríamos suponer que nuestro modelo ViT tiene más capacidad de aprender, si se le dan más datos (más oportunidades de aprender). Sin embargo, esta mayor capacidad de aprender a menudo viene acompañada de un mayor tamaño del modelo y un mayor tiempo para realizar la inferencia.
Ahora creemos un diccionario con algunas características importantes de nuestro modelo ViT.
# Crear diccionario de estadísticas de ViT
vit_stats = {"test_loss": vit_results["test_loss"][-1],
"test_acc": vit_results["test_acc"][-1],
"number_of_parameters": vit_total_params,
"model_size (MB)": pretrained_vit_model_size}
vit_stats
¡Lindo! Parece que nuestro modelo ViT también logra una precisión superior al 95%.
5. Hacer predicciones con nuestros modelos entrenados y cronometrarlas¶
Tenemos un par de modelos entrenados y ambos funcionan bastante bien.
Ahora, ¿qué tal si los probamos haciendo lo que nos gustaría que hicieran?
Es decir, veamos cómo hacen predicciones (realizando inferencias).
Sabemos que nuestros dos modelos funcionan con una precisión superior al 95 % en el conjunto de datos de prueba, pero ¿qué tan rápidos son?
Idealmente, si implementamos nuestro modelo FoodVision Mini en un dispositivo móvil para que las personas puedan tomar fotografías de sus alimentos e identificarlos, nos gustaría que las predicciones se realicen en tiempo real (~30 fotogramas por segundo).
Por eso nuestro segundo criterio es: un modelo rápido.
Para saber cuánto tiempo tarda cada uno de nuestros modelos en inferir el rendimiento, creemos una función llamada pred_and_store() para iterar sobre cada una de las imágenes del conjunto de datos de prueba una por una y realizar una predicción.
Calcularemos el tiempo de cada una de las predicciones y almacenaremos los resultados en un formato de predicción común: una lista de diccionarios (donde cada elemento de la lista es una predicción única y cada predicción única es un diccionario).
Nota: Calculamos las predicciones una por una en lugar de por lotes porque cuando se implementa nuestro modelo, probablemente solo hará una predicción en una imagen a la vez. Es decir, alguien toma una foto y nuestro modelo predice sobre esa única imagen.
Como nos gustaría hacer predicciones en todas las imágenes del conjunto de prueba, primero obtengamos una lista de todas las rutas de las imágenes de prueba para que podamos iterar sobre ellas.
Para hacerlo, usaremos pathlib.Path("target_dir").glob("*/*.jpg")) de Python. html#basic-use) para encontrar todas las rutas de archivos en un directorio de destino con la extensión .jpg (todas nuestras imágenes de prueba).
from pathlib import Path
# Obtenga todas las rutas de datos de prueba
print(f"[INFO] Finding all filepaths ending with '.jpg' in directory: {test_dir}")
test_data_paths = list(Path(test_dir).glob("*/*.jpg"))
test_data_paths[:5]
5.1 Crear una función para hacer predicciones en todo el conjunto de datos de prueba¶
Ahora que tenemos una lista de nuestras rutas de imágenes de prueba, comencemos a trabajar en nuestra función pred_and_store():
- Cree una función que tome una lista de rutas, un modelo PyTorch entrenado, una serie de transformaciones (para preparar imágenes), una lista de nombres de clases de destino y un dispositivo de destino.
- Cree una lista vacía para almacenar diccionarios de predicción (queremos que la función devuelva una lista de diccionarios, uno para cada predicción).
- Recorra las rutas de entrada de destino (los pasos 4 a 14 se realizarán dentro del bucle).
- Cree un diccionario vacío para cada iteración del bucle para almacenar los valores de predicción por muestra.
- Obtenga la ruta de muestra y el nombre de la clase de verdad fundamental (podemos hacer esto infiriendo la clase a partir de la ruta).
- Inicie el temporizador de predicción usando
timeit.default_timer()de Python. - Abra la imagen usando
PIL.Image.open(path). - Transforme la imagen para que pueda usarse con el modelo de destino, así como agregue una dimensión por lotes y envíe la imagen al dispositivo de destino.
- Prepare el modelo para la inferencia enviándolo al dispositivo de destino y activando el modo
eval(). - Active
torch.inference_mode()y pase la imagen transformada de destino al modelo y calcule la probabilidad de predicción usandotorch.softmax()y la etiqueta de destino usandotorch.argmax(). - Agregue la probabilidad de predicción y la clase de predicción al diccionario de predicción creado en el paso 4. También asegúrese de que la probabilidad de predicción esté en la CPU para que pueda usarse con bibliotecas que no son de GPU, como NumPy y pandas, para una inspección posterior.
- Finalice el temporizador de predicción iniciado en el paso 6 y agregue el tiempo al diccionario de predicción creado en el paso 4.
- Vea si la clase predicha coincide con la clase de verdad fundamental del paso 5 y agregue el resultado al diccionario de predicción creado en el paso 4.
- Agregue el diccionario de predicciones actualizado a la lista vacía de predicciones creada en el paso 2.
- Devuelve la lista de diccionarios de predicción.
¡Muchos pasos, pero nada que no podamos manejar!
Vamos a hacerlo.
import pathlib
import torch
from PIL import Image
from timeit import default_timer as timer
from tqdm.auto import tqdm
from typing import List, Dict
# 1. Cree una función para devolver una lista de diccionarios con muestra, etiqueta de verdad, predicción, probabilidad de predicción y tiempo de predicción.
def pred_and_store(paths: List[pathlib.Path],
model: torch.nn.Module,
transform: torchvision.transforms,
class_names: List[str],
device: str = "cuda" if torch.cuda.is_available() else "cpu") -> List[Dict]:
# 2. Create an empty list to store prediction dictionaires
pred_list = []
# 3. Loop through target paths
for path in tqdm(paths):
# 4. Create empty dictionary to store prediction information for each sample
pred_dict = {}
# 5. Get the sample path and ground truth class name
pred_dict["image_path"] = path
class_name = path.parent.stem
pred_dict["class_name"] = class_name
# 6. Start the prediction timer
start_time = timer()
# 7. Open image path
img = Image.open(path)
# 8. Transform the image, add batch dimension and put image on target device
transformed_image = transform(img).unsqueeze(0).to(device)
# 9. Prepare model for inference by sending it to target device and turning on eval() mode
model.to(device)
model.eval()
# 10. Get prediction probability, predicition label and prediction class
with torch.inference_mode():
pred_logit = model(transformed_image) # perform inference on target sample
pred_prob = torch.softmax(pred_logit, dim=1) # turn logits into prediction probabilities
pred_label = torch.argmax(pred_prob, dim=1) # turn prediction probabilities into prediction label
pred_class = class_names[pred_label.cpu()] # hardcode prediction class to be on CPU
# 11. Make sure things in the dictionary are on CPU (required for inspecting predictions later on)
pred_dict["pred_prob"] = round(pred_prob.unsqueeze(0).max().cpu().item(), 4)
pred_dict["pred_class"] = pred_class
# 12. End the timer and calculate time per pred
end_time = timer()
pred_dict["time_for_pred"] = round(end_time-start_time, 4)
# 13. Does the pred match the true label?
pred_dict["correct"] = class_name == pred_class
# 14. Add the dictionary to the list of preds
pred_list.append(pred_dict)
# 15. Return list of prediction dictionaries
return pred_list
¡Ho, ho!
¡Qué función tan atractiva!
Y sabes qué, dado que nuestro pred_and_store() es una función de utilidad bastante buena para hacer y almacenar predicciones, podría almacenarse en [going_modular.going_modular.predictions.py](https://github.com/mrdbourke /pytorch-deep-learning/blob/main/going_modular/going_modular/predictions.py) para su uso posterior. Podría ser una extensión que le gustaría probar; consulte 05. PyTorch Going Modular para obtener ideas.
5.2 Realización y sincronización de predicciones con EffNetB2¶
¡Es hora de probar nuestra función pred_and_store()!
Comencemos usándolo para hacer predicciones en todo el conjunto de datos de prueba con nuestro modelo EffNetB2, prestando atención a dos detalles:
- Dispositivo: codificaremos el parámetro "dispositivo" para usar "cpu" porque cuando implementemos nuestro modelo, no siempre tendremos acceso a un dispositivo "cuda" (GPU). .
- Hacer predicciones en la CPU también será un buen indicador de la velocidad de inferencia porque generalmente las predicciones en dispositivos con CPU son más lentas que las de los dispositivos con GPU.
- Transformaciones - También nos aseguraremos de establecer el parámetro
transformeneffnetb2_transformspara asegurarnos de que las imágenes se abran y transformen de la misma manera en la que se entrenó nuestro modeloeffnetb2.
# Haga predicciones en todo el conjunto de datos de prueba con EffNetB2
effnetb2_test_pred_dicts = pred_and_store(paths=test_data_paths,
model=effnetb2,
transform=effnetb2_transforms,
class_names=class_names,
device="cpu") # make predictions on CPU
¡Lindo! ¡Mira esas predicciones volar!
Inspeccionemos la primera pareja y veamos cómo se ven.
# Inspeccione los primeros 2 diccionarios de predicción.
effnetb2_test_pred_dicts[:2]
¡Guau!
Parece que nuestra función pred_and_store() funcionó bien.
Gracias a nuestra lista de estructura de datos de diccionarios, tenemos mucha información útil que podemos inspeccionar más a fondo.
Para hacerlo, convierta nuestra lista de diccionarios en un DataFrame de pandas.
# Convierta test_pred_dicts en un DataFrame
import pandas as pd
effnetb2_test_pred_df = pd.DataFrame(effnetb2_test_pred_dicts)
effnetb2_test_pred_df.head()
¡Hermoso!
Mire con qué facilidad esos diccionarios de predicción se convierten en un formato estructurado sobre el que podemos realizar análisis.
Como encontrar cuántas predicciones nuestro modelo EffNetB2 se equivocó...
# Comprobar número de predicciones correctas
effnetb2_test_pred_df.correct.value_counts()
Cinco predicciones erróneas de un total de 150, ¡nada mal!
¿Y qué tal el tiempo medio de predicción?
# Encuentre el tiempo promedio por predicción
effnetb2_average_time_per_pred = round(effnetb2_test_pred_df.time_for_pred.mean(), 4)
print(f"EffNetB2 average time per prediction: {effnetb2_average_time_per_pred} seconds")
Mmmm, ¿cómo cumple ese tiempo promedio de predicción con nuestros criterios de rendimiento de nuestro modelo en tiempo real (~30 FPS o 0,03 segundos por predicción)?
Nota: Los tiempos de predicción serán diferentes según los distintos tipos de hardware (por ejemplo, una CPU Intel i9 local frente a una CPU Google Colab). Cuanto mejor y más rápido sea el hardware, generalmente, más rápida será la predicción. Por ejemplo, en mi PC local de aprendizaje profundo con un chip Intel i9, mi tiempo promedio de predicción con EffNetB2 es de alrededor de 0,031 segundos (un poco menos que el tiempo real). Sin embargo, en Google Colab (no estoy seguro de qué hardware de CPU utiliza Colab, pero parece que podría ser un [Intel(R) Xeon(R)](https://stackoverflow.com/questions/47805170/whats-the -hardware-spec-for-google-colaboratory)), mi tiempo promedio de predicción con EffNetB2 es de aproximadamente 0,1396 segundos (3-4 veces más lento).
Agreguemos nuestro tiempo promedio por predicción de EffNetB2 a nuestro diccionario effnetb2_stats.
# Agregue el tiempo de predicción promedio de EffNetB2 al diccionario de estadísticas
effnetb2_stats["time_per_pred_cpu"] = effnetb2_average_time_per_pred
effnetb2_stats
5.3 Realizar y cronometrar predicciones con ViT¶
Hemos hecho predicciones con nuestro modelo EffNetB2, ahora hagamos lo mismo con nuestro modelo ViT.
Para hacerlo, podemos usar la función pred_and_store() que creamos anteriormente, excepto que esta vez pasaremos nuestro modelo vit así como vit_transforms.
Y mantendremos las predicciones en la CPU a través de device="cpu" (una extensión natural aquí sería probar los tiempos de predicción en la CPU y en la GPU).
# Haga una lista de diccionarios de predicción con el modelo de extracción de funciones de ViT en imágenes de prueba
vit_test_pred_dicts = pred_and_store(paths=test_data_paths,
model=vit,
transform=vit_transforms,
class_names=class_names,
device="cpu")
¡Predicciones hechas!
Ahora echemos un vistazo a la primera pareja.
# Verifique las primeras predicciones de ViT en el conjunto de datos de prueba
vit_test_pred_dicts[:2]
¡Maravilloso!
Y al igual que antes, dado que las predicciones de nuestro modelo ViT tienen la forma de una lista de diccionarios, podemos convertirlas fácilmente en un DataFrame de pandas para una inspección más detallada.
# Convierta vit_test_pred_dicts en un DataFrame
import pandas as pd
vit_test_pred_df = pd.DataFrame(vit_test_pred_dicts)
vit_test_pred_df.head()
¿Cuántas predicciones acertó nuestro modelo ViT?
# Cuente el número de predicciones correctas.
vit_test_pred_df.correct.value_counts()
¡Guau!
Nuestro modelo ViT funcionó un poco mejor que nuestro modelo EffNetB2 en términos de predicciones correctas, solo dos muestras incorrectas en todo el conjunto de datos de prueba.
Como extensión, es posible que desee visualizar las predicciones incorrectas del modelo ViT y ver si hay alguna razón por la cual podrían haberse equivocado.
¿Qué tal si calculamos cuánto tiempo tardó el modelo ViT en realizar cada predicción?
# Calcular el tiempo promedio por predicción para el modelo ViT
vit_average_time_per_pred = round(vit_test_pred_df.time_for_pred.mean(), 4)
print(f"ViT average time per prediction: {vit_average_time_per_pred} seconds")
Bueno, eso parece un poco más lento que el tiempo promedio por predicción de nuestro modelo EffNetB2, pero ¿cómo se ve en términos de nuestro segundo criterio: velocidad?
Por ahora, agreguemos el valor a nuestro diccionario vit_stats para que podamos compararlo con las estadísticas de nuestro modelo EffNetB2.
Nota: El tiempo promedio por valor de predicción dependerá en gran medida del hardware en el que los realice. Por ejemplo, para el modelo ViT, mi tiempo promedio por predicción (en la CPU) fue de 0,0693 a 0,0777 segundos en mi PC local de aprendizaje profundo con una CPU Intel i9. Mientras que en Google Colab, mi tiempo promedio por predicción con el modelo ViT fue de 0,6766 a 0,7113 segundos.
# Agregue el tiempo de predicción promedio para el modelo ViT en la CPU
vit_stats["time_per_pred_cpu"] = vit_average_time_per_pred
vit_stats
6. Comparación de resultados de modelos, tiempos de predicción y tamaño¶
Nuestros dos mejores modelos contendientes han sido capacitados y evaluados.
Ahora pongámoslos cara a cara y comparemos sus diferentes estadísticas.
Para hacerlo, convierta nuestros diccionarios effnetb2_stats y vit_stats en un DataFrame de pandas.
Agregaremos una columna para ver los nombres de los modelos y convertiremos la precisión de la prueba a un porcentaje completo en lugar de decimal.
# Convierta los diccionarios de estadísticas en DataFrame
df = pd.DataFrame([effnetb2_stats, vit_stats])
# Agregar columna para nombres de modelos
df["model"] = ["EffNetB2", "ViT"]
# Convertir precisión a porcentajes
df["test_acc"] = round(df["test_acc"] * 100, 2)
df
¡Maravilloso!
Parece que nuestros modelos son bastante parecidos en términos de precisión general de las pruebas, pero ¿cómo se ven en otros campos?
Una forma de averiguarlo sería dividir las estadísticas del modelo ViT por las estadísticas del modelo EffNetB2 para descubrir las diferentes proporciones entre los modelos.
Creemos otro DataFrame para hacerlo.
# Compare ViT con EffNetB2 según diferentes características
pd.DataFrame(data=(df.set_index("model").loc["ViT"] / df.set_index("model").loc["EffNetB2"]), # divide ViT statistics by EffNetB2 statistics
columns=["ViT to EffNetB2 ratios"]).T
Parece que nuestro modelo ViT supera al modelo EffNetB2 en todas las métricas de rendimiento (pérdida de prueba, donde menor es mejor y precisión de la prueba, donde mayor es mejor), pero a expensas de tener:
- 11x+ el número de parámetros.
- 11x+ el tamaño del modelo.
- 2,5 veces más el tiempo de predicción por imagen.
¿Valen la pena estas compensaciones?
Quizás si tuviéramos una potencia informática ilimitada, pero para nuestro caso de uso de implementar el modelo FoodVision Mini en un dispositivo más pequeño (por ejemplo, un teléfono móvil), probablemente comenzaríamos con el modelo EffNetB2 para realizar predicciones más rápidas con un rendimiento ligeramente reducido pero dramáticamente más pequeño. tamaño.
6.1 Visualización del equilibrio entre velocidad y rendimiento¶
Hemos visto que nuestro modelo ViT supera a nuestro modelo EffNetB2 en términos de métricas de rendimiento, como pérdida de prueba y precisión de prueba.
Sin embargo, nuestro modelo EffNetB2 realiza predicciones más rápido y tiene un tamaño de modelo mucho más pequeño.
Nota: El tiempo de rendimiento o inferencia también suele denominarse "latencia".
¿Qué tal si hacemos que este hecho sea visual?
Podemos hacerlo creando un gráfico con matplotlib:
- Cree un diagrama de dispersión a partir del marco de datos de comparación para comparar los valores
time_per_pred_cpuytest_accde EffNetB2 y ViT. - Agregue títulos y etiquetas correspondientes a los datos y personalice el tamaño de fuente por motivos estéticos.
- Anote las muestras en el diagrama de dispersión del paso 1 con sus etiquetas apropiadas (los nombres de los modelos).
- Cree una leyenda basada en los tamaños del modelo (
model_size (MB)).
# 1. Cree un gráfico a partir del marco de datos de comparación de modelos.
fig, ax = plt.subplots(figsize=(12, 8))
scatter = ax.scatter(data=df,
x="time_per_pred_cpu",
y="test_acc",
c=["blue", "orange"], # what colours to use?
s="model_size (MB)") # size the dots by the model sizes
# 2. Agregue títulos, etiquetas y personalice el tamaño de fuente por motivos estéticos.
ax.set_title("FoodVision Mini Inference Speed vs Performance", fontsize=18)
ax.set_xlabel("Prediction time per image (seconds)", fontsize=14)
ax.set_ylabel("Test accuracy (%)", fontsize=14)
ax.tick_params(axis='both', labelsize=12)
ax.grid(True)
# 3. Anotar con nombres de modelos
for index, row in df.iterrows():
ax.annotate(text=row["model"], # note: depending on your version of Matplotlib, you may need to use "s=..." or "text=...", see: https://github.com/faustomorales/keras-ocr/issues/183#issuecomment-977733270
xy=(row["time_per_pred_cpu"]+0.0006, row["test_acc"]+0.03),
size=12)
# 4. Crea una leyenda basada en los tamaños del modelo.
handles, labels = scatter.legend_elements(prop="sizes", alpha=0.5)
model_size_legend = ax.legend(handles,
labels,
loc="lower right",
title="Model size (MB)",
fontsize=12)
# guarda la figura
!mdkir images/
plt.savefig("images/09-foodvision-mini-inference-speed-vs-performance.jpg")
# mostrar la figura
plt.show()
¡Guau!
La gráfica realmente visualiza la velocidad versus rendimiento; en otras palabras, cuando tienes un modelo profundo más grande y de mejor rendimiento (como nuestro modelo ViT), generalmente lleva más tiempo realizar la inferencia (mayor latencia).
Hay excepciones a la regla y constantemente se publican nuevas investigaciones para ayudar a que los modelos más grandes funcionen más rápido.
Y puede resultar tentador simplemente implementar el modelo de mejor rendimiento, pero también es bueno tener en cuenta dónde funcionará el modelo.
En nuestro caso, las diferencias entre los niveles de rendimiento de nuestro modelo (en la pérdida de prueba y la precisión de la prueba) no son demasiado extremas.
Pero como para empezar nos gustaría poner énfasis en la velocidad, seguiremos implementando EffNetB2 ya que es más rápido y ocupa mucho menos espacio.
Nota: Los tiempos de predicción serán diferentes según los diferentes tipos de hardware (por ejemplo, Intel i9 frente a CPU de Google Colab frente a GPU), por lo que es importante pensar y probar dónde terminará su modelo. Hacer preguntas como "¿dónde se ejecutará el modelo?" o "¿cuál es el escenario ideal para ejecutar el modelo?" y luego realizar experimentos para intentar proporcionar respuestas en el camino hacia la implementación es muy útil.
7. Dar vida a FoodVision Mini creando una demostración de Gradio¶
Hemos decidido que nos gustaría implementar el modelo EffNetB2 (para empezar, esto siempre se puede cambiar más adelante).
Entonces, ¿cómo podemos hacer eso?
Hay varias formas de implementar un modelo de aprendizaje automático, cada una con casos de uso específicos (como se analizó anteriormente).
Nos centraremos en la que quizás sea la forma más rápida y ciertamente una de las más divertidas de implementar un modelo en Internet.
Y eso es usando Gradio.
¿Qué es Gradio?
La página de inicio lo describe maravillosamente:
Gradio es la forma más rápida de hacer una demostración de su modelo de aprendizaje automático con una interfaz web amigable para que cualquiera pueda usarlo, ¡en cualquier lugar!
¿Por qué crear una demostración de tus modelos?
Porque las métricas en el conjunto de prueba se ven bien, pero nunca se sabe realmente cómo se desempeña su modelo hasta que lo usa en la naturaleza.
¡Así que comencemos a implementar!
Comenzaremos importando Gradio con el alias común gr y, si no está presente, lo instalaremos.
# Importar/instalar Gradio
try:
import gradio as gr
except:
!pip -q install gradio
import gradio as gr
print(f"Gradio version: {gr.__version__}")
¡Gradio listo!
Convirtamos FoodVision Mini en una aplicación de demostración.
7.1 Descripción general de Gradio¶
La premisa general de Gradio es muy similar a la que hemos ido repitiendo a lo largo del curso.
¿Cuáles son nuestras entradas y salidas?
¿Y cómo deberíamos llegar allí?
Bueno, eso es lo que hace nuestro modelo de aprendizaje automático.
entradas -> modelo ML -> salidas
En nuestro caso, para FoodVision Mini, nuestras entradas son imágenes de comida, nuestro modelo ML es EffNetB2 y nuestras salidas son clases de comida (pizza, bistec o sushi).
imágenes de alimentos -> EffNetB2 -> salidas
Aunque los conceptos de entradas y salidas pueden vincularse a casi cualquier otro tipo de problema de ML.
Sus entradas y salidas pueden ser cualquier combinación de lo siguiente:
- Imágenes
- Texto
- Video
- Datos tabulados *Audio
- Números
- & más
Y el modelo de ML que cree dependerá de sus entradas y salidas.
Gradio emula este paradigma creando una interfaz (gradio.Interface()) desde las entradas hasta las salidas.
gradio.Interface(fn, entradas, salidas)
Donde, "fn" es una función de Python para asignar las "entradas" a las "salidas".
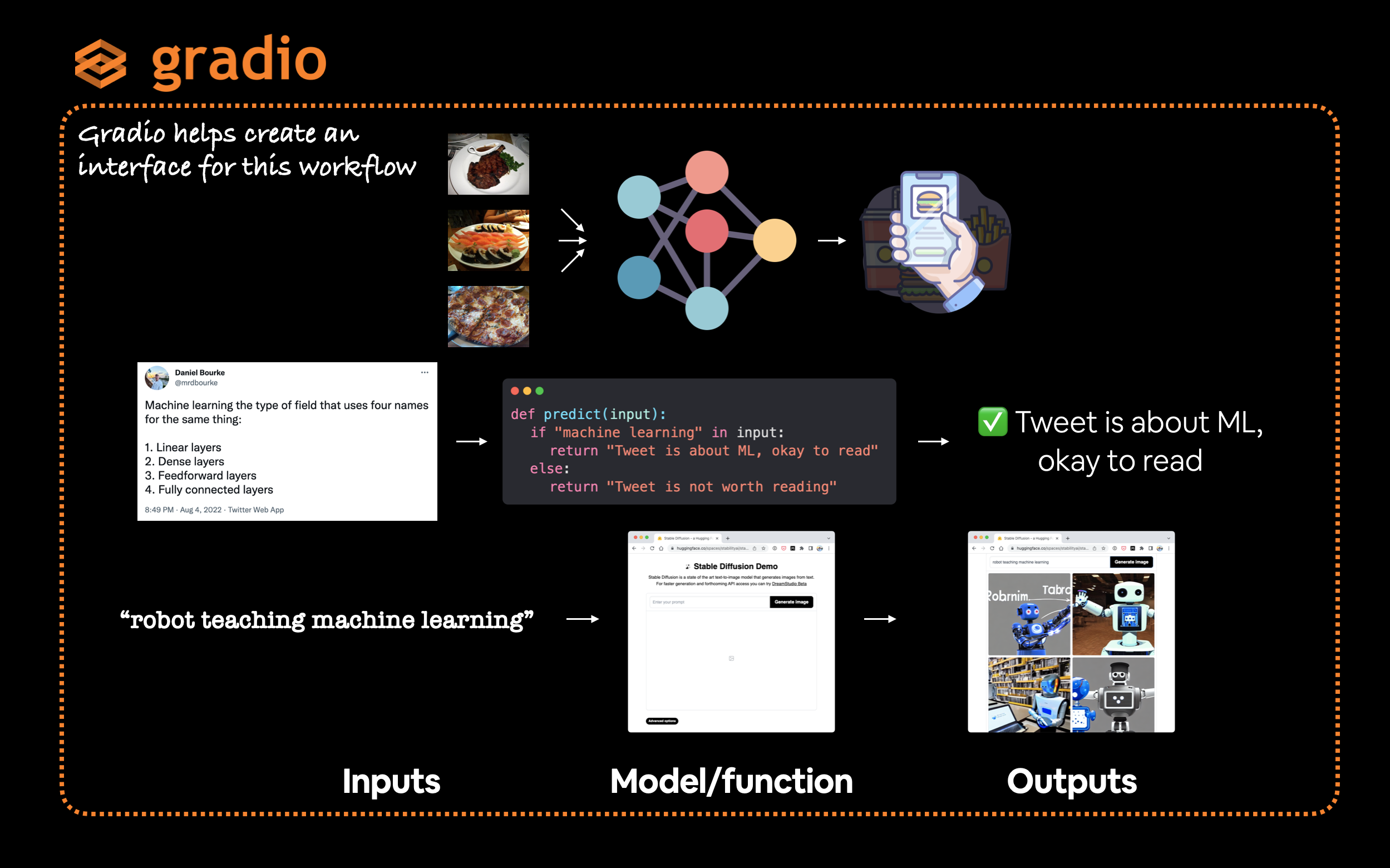
Gradio proporciona una clase Interfaz muy útil para crear fácilmente entradas -> modelo/función -> flujo de trabajo de salidas donde las entradas y salidas pueden ser casi cualquier cosa que desee. Por ejemplo, puede ingresar Tweets (texto) para ver si tratan sobre aprendizaje automático o no o ingrese un mensaje de texto para generar imágenes.
Nota: Gradio tiene una gran cantidad de posibles opciones de "entradas" y "salidas" conocidas como "Componentes", desde imágenes hasta texto, números, audio, videos y más. Puede verlos todos en la [documentación de componentes de Gradio] (https://gradio.app/docs/#components).
7.2 Creando una función para mapear nuestras entradas y salidas¶
Para crear nuestra demostración de FoodVision Mini con Gradio, necesitaremos una función para asignar nuestras entradas a nuestras salidas.
Anteriormente creamos una función llamada pred_and_store() para hacer predicciones con un modelo determinado en una lista de archivos de destino y almacenarlos en una lista de diccionarios.
¿Qué tal si creamos una función similar pero esta vez centrándonos en hacer una predicción en una sola imagen con nuestro modelo EffNetB2?
Más específicamente, queremos una función que tome una imagen como entrada, la preprocese (transforme), haga una predicción con EffNetB2 y luego devuelva la predicción (pred o etiqueta pred para abreviar), así como la probabilidad de predicción (pred prob).
Y ya que estamos aquí, retrocedamos el tiempo que nos llevó hacerlo también:
entrada: imagen -> transformar -> predecir con EffNetB2 -> salida: pred, pred prob, tiempo necesario
Este será nuestro parámetro fn para nuestra interfaz Gradio.
Primero, asegurémonos de que nuestro modelo EffNetB2 esté en la CPU (ya que nos atenemos a las predicciones solo de CPU, sin embargo, puedes cambiar esto si tienes acceso a una GPU).
# Ponga EffNetB2 en la CPU
effnetb2.to("cpu")
# Verifique el dispositivo
next(iter(effnetb2.parameters())).device
Y ahora creemos una función llamada predict() para replicar el flujo de trabajo anterior.
from typing import Tuple, Dict
def predict(img) -> Tuple[Dict, float]:
"""Transforms and performs a prediction on img and returns prediction and time taken.
"""
# Start the timer
start_time = timer()
# Transform the target image and add a batch dimension
img = effnetb2_transforms(img).unsqueeze(0)
# Put model into evaluation mode and turn on inference mode
effnetb2.eval()
with torch.inference_mode():
# Pass the transformed image through the model and turn the prediction logits into prediction probabilities
pred_probs = torch.softmax(effnetb2(img), dim=1)
# Create a prediction label and prediction probability dictionary for each prediction class (this is the required format for Gradio's output parameter)
pred_labels_and_probs = {class_names[i]: float(pred_probs[0][i]) for i in range(len(class_names))}
# Calculate the prediction time
pred_time = round(timer() - start_time, 5)
# Return the prediction dictionary and prediction time
return pred_labels_and_probs, pred_time
¡Hermoso!
Ahora veamos nuestra función en acción realizando una predicción en una imagen aleatoria del conjunto de datos de prueba.
Comenzaremos obteniendo una lista de todas las rutas de imágenes del directorio de prueba y luego seleccionaremos una al azar.
Luego abriremos la imagen seleccionada al azar con PIL.Image.open().
Finalmente, pasaremos la imagen a nuestra función predict().
import random
from PIL import Image
# Obtenga una lista de todas las rutas de archivos de imágenes de prueba
test_data_paths = list(Path(test_dir).glob("*/*.jpg"))
# Seleccione aleatoriamente una ruta de imagen de prueba
random_image_path = random.sample(test_data_paths, k=1)[0]
# Abra la imagen de destino
image = Image.open(random_image_path)
print(f"[INFO] Predicting on image at path: {random_image_path}\n")
# Predecir sobre la imagen de destino e imprimir los resultados.
pred_dict, pred_time = predict(img=image)
print(f"Prediction label and probability dictionary: \n{pred_dict}")
print(f"Prediction time: {pred_time} seconds")
¡Lindo!
Al ejecutar la celda de arriba varias veces, podemos ver diferentes probabilidades de predicción para cada etiqueta de nuestro modelo EffNetB2, así como el tiempo que tomó cada predicción.
7.3 Crear una lista de imágenes de ejemplo¶
Nuestra función predict() nos permite ir desde entradas -> transformar -> modelo ML -> salidas.
Que es exactamente lo que necesitamos para nuestra demostración de Graido.
Pero antes de crear la demostración, creemos una cosa más: una lista de ejemplos.
La clase Interface de Gradio toma una lista de ejemplos como parámetro opcional (gradio.Interface(examples=List[Any])).
Y el formato del parámetro "ejemplos" es una lista de listas.
Entonces, creemos una lista de listas que contengan rutas de archivos aleatorias a nuestras imágenes de prueba.
Tres ejemplos deberían ser suficientes.
# Cree una lista de entradas de ejemplo para nuestra demostración de Gradio
example_list = [[str(filepath)] for filepath in random.sample(test_data_paths, k=3)]
example_list
¡Perfecto!
Nuestra demostración de Gradio los mostrará como entradas de ejemplo para nuestra demostración para que las personas puedan probarlo y ver qué hace sin cargar ninguno de sus propios datos.
7.4 Construyendo una interfaz Gradio¶
¡Es hora de juntar todo y darle vida a nuestra demostración de FoodVision Mini!
Creemos una interfaz Gradio para replicar el flujo de trabajo:
entrada: imagen -> transformar -> predecir con EffNetB2 -> salida: pred, pred prob, tiempo necesario
Lo podemos hacer con la clase gradio.Interface() con los siguientes parámetros:
fn- una función de Python para asignarentradasasalidas; en nuestro caso, usaremos nuestra funciónpredict().inputs: la entrada a nuestra interfaz, como una imagen usandogradio.Image()o"image".outputs- la salida de nuestra interfaz una vez que lasinputshan pasado porfn, como una etiqueta usandogradio.Label()(para las etiquetas predichas de nuestro modelo) o número usandogradio.Number()(para el tiempo de predicción de nuestro modelo).- Nota: Gradio viene con muchas opciones integradas de
entradasysalidasconocidas como "Componentes".
- Nota: Gradio viene con muchas opciones integradas de
ejemplos: una lista de ejemplos para mostrar en la demostración.title- un título de cadena de la demostración.descripción: una cadena de descripción de la demostración.artículo: una nota de referencia al final de la demostración.
Una vez que hayamos creado nuestra instancia de demostración de gr.Interface(), podemos darle vida usando [gradio.Interface().launch()](https://gradio.app/docs/#launch -header) o el comando demo.launch().
¡Fácil!
import gradio as gr
# Crear cadenas de título, descripción y artículo.
title = "FoodVision Mini 🍕🥩🍣"
description = "An EfficientNetB2 feature extractor computer vision model to classify images of food as pizza, steak or sushi."
article = "Created at [09. PyTorch Model Deployment](https://www.learnpytorch.io/09_pytorch_model_deployment/)."
# Crea la demostración de Gradio
demo = gr.Interface(fn=predict, # mapping function from input to output
inputs=gr.Image(type="pil"), # what are the inputs?
outputs=[gr.Label(num_top_classes=3, label="Predictions"), # what are the outputs?
gr.Number(label="Prediction time (s)")], # our fn has two outputs, therefore we have two outputs
examples=example_list,
title=title,
description=description,
article=article)
# ¡Lanza la demostración!
demo.launch(debug=False, # print errors locally?
share=True) # generate a publically shareable URL?

Demo de FoodVision Mini Gradio ejecutándose en Google Colab y en el navegador (el enlace cuando se ejecuta desde Google Colab solo dura 72 horas). Puedes ver la demo permanente en vivo en Hugging Face Spaces.
¡¡¡Guau!!! ¡¡¡Qué demostración tan épica!!!
FoodVision Mini ha cobrado vida oficialmente en una interfaz que alguien podría usar y probar.
Si configura el parámetro share=True en el método launch(), Gradio también le proporciona un enlace para compartir como https://123XYZ.gradio.app (este enlace es solo un ejemplo y probablemente esté vencido). ) que es válido por 72 horas.
El enlace proporciona un proxy a la interfaz de Gradio que inició.
Para un alojamiento más permanente, puede cargar su aplicación Gradio en Hugging Face Spaces o en cualquier lugar que ejecute código Python.
8. Convertir nuestra demostración FoodVision Mini Gradio en una aplicación implementable¶
Hemos visto nuestro modelo FoodVision Mini cobrar vida a través de una demostración de Gradio.
Pero ¿y si quisiéramos compartirlo con nuestros amigos?
Bueno, podríamos usar el enlace de Gradio proporcionado, sin embargo, el enlace compartido solo dura 72 horas.
Para que nuestra demostración de FoodVision Mini sea más permanente, podemos empaquetarla en una aplicación y cargarla en Hugging Face Spaces.
8.1 ¿Qué es abrazar los espacios faciales?¶
Hugging Face Spaces es un recurso que le permite alojar y compartir aplicaciones de aprendizaje automático.
Crear una demostración es una de las mejores formas de mostrar y probar lo que ha hecho.
Y Spaces te permite hacer precisamente eso.
Puedes pensar en Hugging Face como el GitHub del aprendizaje automático.
Si tener un buen portafolio de GitHub muestra tus habilidades de codificación, tener un buen portafolio de Hugging Face puede mostrar tus habilidades de aprendizaje automático.
Nota: Hay muchos otros lugares donde podríamos cargar y alojar nuestra aplicación Gradio, como Google Cloud, AWS (Amazon Web Services) u otros proveedores de nube; sin embargo, usaremos Hugging Face Spaces debido a la facilidad de uso y la amplia adopción por parte de la comunidad de aprendizaje automático.
8.2 Estructura de la aplicación Gradio implementada¶
Para cargar nuestra aplicación de demostración Gradio, queremos colocar todo lo relacionado con ella en un solo directorio.
Por ejemplo, nuestra demostración podría estar en la ruta demos/foodvision_mini/ con la estructura de archivos:
población/
└── comidavision_mini/
├── 09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth
├── aplicación.py
├── ejemplos/
│ ├── ejemplo_1.jpg
│ ├── ejemplo_2.jpg
│ └── ejemplo_3.jpg
├── modelo.py
└── requisitos.txt
Dónde:
09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pthes nuestro archivo modelo PyTorch entrenado.app.pycontiene nuestra aplicación Gradio (similar al código que inició la aplicación).- Nota:
app.pyes el nombre de archivo predeterminado utilizado para Hugging Face Spaces. Si implementas tu aplicación allí, Spaces buscará de manera predeterminada un archivo llamadoapp.pypara ejecutar. Esto se puede cambiar en la configuración.
- Nota:
examples/contiene imágenes de ejemplo para usar con nuestra aplicación Gradio.model.pycontiene la definición del modelo, así como cualquier transformación asociada con el modelo.requirements.txtcontiene las dependencias para ejecutar nuestra aplicación, comotorch,torchvisionygradio.
¿Por qué de esta manera?
Porque es uno de los diseños más simples con los que podríamos empezar.
Nuestro enfoque es: ¡experimentar, experimentar, experimentar!
Cuanto más rápido podamos realizar experimentos más pequeños, mejores serán los más grandes.
Vamos a trabajar para recrear la estructura anterior, pero puedes ver una aplicación de demostración en vivo ejecutándose en Hugging Face Spaces, así como la estructura de archivos:
8.3 Creando una carpeta demos para almacenar los archivos de nuestra aplicación FoodVision Mini¶
Para comenzar, primero creemos un directorio demos/ para almacenar todos los archivos de nuestra aplicación FoodVision Mini.
Podemos hacerlo con pathlib.Path("path_to_dir") de Python para establecer la ruta del directorio y pathlib. Path("path_to_dir").mkdir() para crearlo.
import shutil
from pathlib import Path
# Crear una mini ruta de demostración de FoodVision
foodvision_mini_demo_path = Path("demos/foodvision_mini/")
# Elimine los archivos que ya puedan existir allí y cree un nuevo directorio
if foodvision_mini_demo_path.exists():
shutil.rmtree(foodvision_mini_demo_path)
foodvision_mini_demo_path.mkdir(parents=True, # make the parent folders?
exist_ok=True) # create it even if it already exists?
else:
# If the file doesn't exist, create it anyway
foodvision_mini_demo_path.mkdir(parents=True,
exist_ok=True)
# Comprueba lo que hay en la carpeta.
!ls demos/foodvision_mini/
8.4 Crear una carpeta de imágenes de ejemplo para usar con nuestra demostración de FoodVision Mini¶
Ahora que tenemos un directorio para almacenar nuestros archivos de demostración de FoodVision Mini, agreguemos algunos ejemplos.
Tres imágenes de ejemplo del conjunto de datos de prueba deberían ser suficientes.
Para hacerlo haremos:
- Cree un directorio
examples/dentro del directoriodemos/foodvision_mini. - Elija tres imágenes aleatorias del conjunto de datos de prueba y recopile sus rutas de archivo en una lista.
- Copie las tres imágenes aleatorias del conjunto de datos de prueba al directorio
demos/foodvision_mini/examples/.
import shutil
from pathlib import Path
# 1. Cree un directorio de ejemplos
foodvision_mini_examples_path = foodvision_mini_demo_path / "examples"
foodvision_mini_examples_path.mkdir(parents=True, exist_ok=True)
# 2. Recopile tres rutas de imágenes de conjuntos de datos de prueba aleatorias
foodvision_mini_examples = [Path('data/pizza_steak_sushi_20_percent/test/sushi/592799.jpg'),
Path('data/pizza_steak_sushi_20_percent/test/steak/3622237.jpg'),
Path('data/pizza_steak_sushi_20_percent/test/pizza/2582289.jpg')]
# 3. Copie las tres imágenes aleatorias al directorio de ejemplos.
for example in foodvision_mini_examples:
destination = foodvision_mini_examples_path / example.name
print(f"[INFO] Copying {example} to {destination}")
shutil.copy2(src=example, dst=destination)
Ahora, para verificar que nuestros ejemplos estén presentes, enumeremos el contenido de nuestro directorio demos/foodvision_mini/examples/ con [os.listdir()](https://docs.python.org/3/library/os. html#os.listdir) y luego formatee las rutas de archivo en una lista de listas (para que sea compatible con el parámetro example gradio.Interface() de Gradio) .
import os
# Obtenga rutas de archivos de ejemplo en una lista de listas
example_list = [["examples/" + example] for example in os.listdir(foodvision_mini_examples_path)]
example_list
8.5 Mover nuestro modelo EffNetB2 entrenado a nuestro directorio de demostración FoodVision Mini¶
Anteriormente guardamos nuestro modelo de extractor de funciones FoodVision Mini EffNetB2 en models/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth.
Y en lugar de duplicar los archivos de modelo guardados, muevamos nuestro modelo a nuestro directorio demos/foodvision_mini.
Podemos hacerlo usando el método shutil.move() de Python y pasando src (la ruta fuente de el archivo de destino) y dst (la ruta de destino del archivo de destino al que se va a mover).
import shutil
# Crear una ruta de origen para nuestro modelo de destino.
effnetb2_foodvision_mini_model_path = "models/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth"
# Crear una ruta de destino para nuestro modelo objetivo.
effnetb2_foodvision_mini_model_destination = foodvision_mini_demo_path / effnetb2_foodvision_mini_model_path.split("/")[1]
# Intenta mover el archivo
try:
print(f"[INFO] Attempting to move {effnetb2_foodvision_mini_model_path} to {effnetb2_foodvision_mini_model_destination}")
# Move the model
shutil.move(src=effnetb2_foodvision_mini_model_path,
dst=effnetb2_foodvision_mini_model_destination)
print(f"[INFO] Model move complete.")
# Si el modelo ya ha sido movido, verifique si existe.
except:
print(f"[INFO] No model found at {effnetb2_foodvision_mini_model_path}, perhaps its already been moved?")
print(f"[INFO] Model exists at {effnetb2_foodvision_mini_model_destination}: {effnetb2_foodvision_mini_model_destination.exists()}")
8.6 Convirtiendo nuestro modelo EffNetB2 en un script Python (model.py)¶
El state_dict de nuestro modelo actual se guarda en demos/foodvision_mini/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth.
Para cargarlo podemos usar model.load_state_dict() junto con torch.load().
Nota: Para obtener una actualización sobre cómo guardar y cargar un modelo (o el
state_dictde un modelo en PyTorch, consulte [01. Fundamentos del flujo de trabajo de PyTorch, sección 5: Guardar y cargar un modelo de PyTorch](https://www. learnpytorch.io/01_pytorch_workflow/#5-served-and-loading-a-pytorch-model) o consulte la receta de PyTorch para [¿Qué es unstate_dicten PyTorch?](https://pytorch.org/tutorials/recipes /recetas/what_is_state_dict.html)
Pero antes de que podamos hacer esto, primero necesitamos una forma de crear una instancia de un "modelo".
Para hacer esto de forma modular, crearemos un script llamado model.py que contiene nuestra función create_effnetb2_model() que creamos en [sección 3.1: Creación de una función para crear un extractor de funciones EffNetB2](https: //www.learnpytorch.io/09_pytorch_model_deployment/#31-creating-a-function-to-make-an-effnetb2-feature-extractor).
De esa manera podemos importar la función en otro script (ver app.py a continuación) y luego usarla para crear nuestra instancia de modelo EffNetB2, así como obtener sus transformaciones apropiadas.
Al igual que en 05. PyTorch Going Modular, usaremos el comando mágico %%writefile path/to/file para convertir una celda de código en un archivo.
%%writefile demos/foodvision_mini/model.py
import torch
import torchvision
from torch import nn
def create_effnetb2_model(num_classes:int=3,
seed:int=42):
"""Creates an EfficientNetB2 feature extractor model and transforms.
Args:
num_classes (int, optional): number of classes in the classifier head.
Defaults to 3.
seed (int, optional): random seed value. Defaults to 42.
Returns:
model (torch.nn.Module): EffNetB2 feature extractor model.
transforms (torchvision.transforms): EffNetB2 image transforms.
"""
# Create EffNetB2 pretrained weights, transforms and model
weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.efficientnet_b2(weights=weights)
# Freeze all layers in base model
for param in model.parameters():
param.requires_grad = False
# Change classifier head with random seed for reproducibility
torch.manual_seed(seed)
model.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True),
nn.Linear(in_features=1408, out_features=num_classes),
)
return model, transforms
8.7 Convirtiendo nuestra aplicación FoodVision Mini Gradio en un script Python (app.py)¶
Ahora tenemos un script model.py así como una ruta a un modelo guardado state_dict que podemos cargar.
Es hora de construir app.py.
Lo llamamos app.py porque, de forma predeterminada, cuando creas un espacio HuggingFace, busca un archivo llamado app.py para ejecutarlo y alojarlo (aunque puedes cambiar esto en la configuración).
Nuestro script app.py juntará todas las piezas del rompecabezas para crear nuestra demostración de Gradio y tendrá cuatro partes principales:
- Configuración de importaciones y nombres de clases - Aquí importaremos las diversas dependencias para nuestra demostración, incluida la función
create_effnetb2_model()demodel.py, así como también configuraremos los diferentes nombres de clases para nuestra aplicación FoodVision Mini. . - Preparación de modelos y transformaciones: aquí crearemos una instancia de modelo EffNetB2 junto con las transformaciones que la acompañan y luego cargaremos los pesos/
state_dictdel modelo guardado. Cuando cargamos el modelo, también configuraremosmap_location=torch.device("cpu")en [torch.load()](https://pytorch.org/docs/stable/generated/torch.load .html) para que nuestro modelo se cargue en la CPU independientemente del dispositivo en el que se entrenó (hacemos esto porque no necesariamente tendremos una GPU cuando implementemos y obtendremos un error si nuestro modelo está entrenado en GPU pero intente implementarlo en la CPU sin decirlo explícitamente). - Función de predicción -
gradio.Interface()de Gradio toma un parámetrofnpara asignar entradas a salidas, nuestra funciónpredict()será la misma que definimos anteriormente en la sección 7.2 : Creando una función para mapear nuestras entradas y salidas, lo hará tome una imagen y luego use las transformaciones cargadas para preprocesarla antes de usar el modelo cargado para hacer una predicción sobre ella.- Nota: Tendremos que crear la lista de ejemplo sobre la marcha mediante el parámetro
examples. Podemos hacerlo creando una lista de archivos dentro del directorioexamples/con:[["examples/" + example] por ejemplo en os.listdir("examples")].
- Nota: Tendremos que crear la lista de ejemplo sobre la marcha mediante el parámetro
- Aplicación Gradio - Aquí es donde vivirá la lógica principal de nuestra demostración, crearemos una instancia
gradio.Interface()llamadademopara juntar nuestras entradas, funciónpredict()y salidas. ¡Y terminaremos el script llamando ademo.launch()para iniciar nuestra demostración de FoodVision Mini!
%%writefile demos/foodvision_mini/app.py
# ## 1. Configuración de importaciones y nombres de clases ###
import gradio as gr
import os
import torch
from model import create_effnetb2_model
from timeit import default_timer as timer
from typing import Tuple, Dict
# Configurar nombres de clases
class_names = ["pizza", "steak", "sushi"]
# ## 2. Preparación del modelo y transforma ###
# Crear modelo EffNetB2
effnetb2, effnetb2_transforms = create_effnetb2_model(
num_classes=3, # len(class_names) would also work
)
# Cargar pesos guardados
effnetb2.load_state_dict(
torch.load(
f="09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth",
map_location=torch.device("cpu"), # load to CPU
)
)
# ## 3. Función de predicción ###
# Crear función de predicción
def predict(img) -> Tuple[Dict, float]:
"""Transforms and performs a prediction on img and returns prediction and time taken.
"""
# Start the timer
start_time = timer()
# Transform the target image and add a batch dimension
img = effnetb2_transforms(img).unsqueeze(0)
# Put model into evaluation mode and turn on inference mode
effnetb2.eval()
with torch.inference_mode():
# Pass the transformed image through the model and turn the prediction logits into prediction probabilities
pred_probs = torch.softmax(effnetb2(img), dim=1)
# Create a prediction label and prediction probability dictionary for each prediction class (this is the required format for Gradio's output parameter)
pred_labels_and_probs = {class_names[i]: float(pred_probs[0][i]) for i in range(len(class_names))}
# Calculate the prediction time
pred_time = round(timer() - start_time, 5)
# Return the prediction dictionary and prediction time
return pred_labels_and_probs, pred_time
# ## 4. Aplicación Gradio ###
# Crear cadenas de título, descripción y artículo.
title = "FoodVision Mini 🍕🥩🍣"
description = "An EfficientNetB2 feature extractor computer vision model to classify images of food as pizza, steak or sushi."
article = "Created at [09. PyTorch Model Deployment](https://www.learnpytorch.io/09_pytorch_model_deployment/)."
# Crear una lista de ejemplos desde el directorio "examples/"
example_list = [["examples/" + example] for example in os.listdir("examples")]
# Crea la demostración de Gradio
demo = gr.Interface(fn=predict, # mapping function from input to output
inputs=gr.Image(type="pil"), # what are the inputs?
outputs=[gr.Label(num_top_classes=3, label="Predictions"), # what are the outputs?
gr.Number(label="Prediction time (s)")], # our fn has two outputs, therefore we have two outputs
# Create examples list from "examples/" directory
examples=example_list,
title=title,
description=description,
article=article)
# ¡Lanza la demostración!
demo.launch()
8.8 Creación de un archivo de requisitos para FoodVision Mini (requirements.txt)¶
El último archivo que debemos crear para nuestra aplicación FoodVision Mini es un [archivo requirements.txt] (https://learnpython.com/blog/python-requirements-file/).
Este será un archivo de texto que contendrá todas las dependencias necesarias para nuestra demostración.
Cuando implementemos nuestra aplicación de demostración en Hugging Face Spaces, buscará en este archivo e instalará las dependencias que definimos para que nuestra aplicación pueda ejecutarse.
¡La buena noticia es que sólo hay tres!
antorcha==1.12.0torchvision==0.13.0gradio==3.1.4
"==1.12.0" indica el número de versión a instalar.
Definir el número de versión no es 100% obligatorio, pero lo haremos por ahora, de modo que si se producen actualizaciones importantes en futuras versiones, nuestra aplicación aún se ejecuta (PD: si encuentra algún error, no dude en publicarlo en el curso [Problemas de GitHub](https: //github.com/mrdbourke/pytorch-deep-learning/issues)).
%%writefile demos/foodvision_mini/requirements.txt
torch==1.12.0
torchvision==0.13.0
gradio==3.1.4
¡Lindo!
¡Tenemos oficialmente todos los archivos que necesitamos para implementar nuestra demostración de FoodVision Mini!
9. Implementación de nuestra aplicación FoodVision Mini en HuggingFace Spaces¶
Tenemos un archivo que contiene nuestra demostración de FoodVision Mini. Ahora, ¿cómo hacemos para que se ejecute en Hugging Face Spaces?
Hay dos opciones principales para cargar en un Hugging Face Space (también llamado Repositorio de Hugging Face, similares a un repositorio de git):
- Carga a través de la interfaz web de Hugging Face (más fácil).
- [Carga a través de la línea de comando o terminal] (https://huggingface.co/docs/hub/repositories-getting-started#terminal).
- Bonificación: También puedes usar la biblioteca
huggingface_hubpara interactuar con Hugging Face, esta sería una buena extensión de las dos opciones anteriores. .
- Bonificación: También puedes usar la biblioteca
No dude en leer la documentación sobre ambas opciones, pero optaremos por la opción dos.
Nota: Para alojar cualquier cosa en Hugging Face, deberás registrarte para obtener una cuenta gratuita de Hugging Face.
9.1 Descarga de los archivos de nuestra aplicación FoodVision Mini¶
Veamos los archivos de demostración que tenemos dentro de demos/foodvision_mini.
Para hacerlo, podemos usar el comando !ls seguido de la ruta del archivo de destino.
ls significa "lista" y ! significa que queremos ejecutar el comando en el nivel de shell.
!ls demos/foodvision_mini
¡Estos son todos los archivos que hemos creado!
Para comenzar a cargar nuestros archivos en Hugging Face, descarguémoslos ahora desde Google Colab (o dondequiera que esté ejecutando este cuaderno).
Para hacerlo, primero comprimiremos los archivos en una única carpeta zip mediante el comando:
zip -r ../foodvision_mini.zip * -x "*.pyc" "*.ipynb" "*__pycache__*" "*ipynb_checkpoints*"
Dónde:
zipsignifica "zip", como en "comprima los archivos en el siguiente directorio".-rsignifica "recursivo", como en "revisar todos los archivos en el directorio de destino".../foodvision_mini.zipes el directorio de destino donde nos gustaría comprimir nuestros archivos.*significa "todos los archivos en el directorio actual".-xsignifica "excluir estos archivos".
Podemos descargar nuestro archivo zip de Google Colab usando google.colab.files.download("demos/foodvision_mini.zip") ( Pondremos esto dentro de un bloque try y except en caso de que no estemos ejecutando el código dentro de Google Colab y, de ser así, imprimiremos un mensaje que indicará que descarguemos los archivos manualmente).
¡Probémoslo!
# Cambie y luego comprima la carpeta foodvision_mini pero excluya ciertos archivos
!cd demos/foodvision_mini && zip -r ../foodvision_mini.zip * -x "*.pyc" "*.ipynb" "*__pycache__*" "*ipynb_checkpoints*"
# Descargue la aplicación FoodVision Mini comprimida (si se ejecuta en Google Colab)
try:
from google.colab import files
files.download("demos/foodvision_mini.zip")
except:
print("Not running in Google Colab, can't use google.colab.files.download(), please manually download.")
¡Guau!
Parece que nuestro comando zip fue exitoso.
Si está ejecutando este cuaderno en Google Colab, debería ver que un archivo comienza a descargarse en su navegador.
De lo contrario, puede ver la carpeta foodvision_mini.zip (y más) en el [curso GitHub en el directorio demos/](https://github.com/mrdbourke/pytorch-deep-learning/tree/main/ población).
9.2 Ejecución de nuestra demostración FoodVision Mini localmente¶
Si descarga el archivo foodvision_mini.zip, puede probarlo localmente de la siguiente manera:
- Descomprimiendo el archivo.
- Abrir la terminal o una línea de comando.
- Cambiar al directorio
foodvision_mini(cd foodvision_mini). - Crear un entorno (
python3 -m venv env). - Activar el entorno (
source env/bin/activate). - Instalar los requisitos (
pip install -r requisitos.txt, "-r" es para recursivo).- Nota: Este paso puede tardar entre 5 y 10 minutos dependiendo de tu conexión a Internet. Y si enfrenta errores, es posible que primero necesite actualizar
pip:pip install --upgrade pip.
- Nota: Este paso puede tardar entre 5 y 10 minutos dependiendo de tu conexión a Internet. Y si enfrenta errores, es posible que primero necesite actualizar
- Ejecute la aplicación (
python3 app.py).
Esto debería dar como resultado una demostración de Gradio como la que creamos anteriormente ejecutándose localmente en su máquina en una URL como http://127.0.0.1:7860/.
Nota: Si ejecuta la aplicación localmente y observa que aparece un directorio
marcado/, contiene muestras que han sido "marcadas".Por ejemplo, si alguien prueba la demostración y el modelo produce un resultado incorrecto, la muestra se puede "marcar" y revisar para más adelante.
Para obtener más información sobre cómo marcar en Gradio, consulte la documentación sobre cómo marcar.
9.3 Subir a Hugging Face¶
Hemos verificado que nuestra aplicación FoodVision Mini funciona localmente; sin embargo, lo divertido de crear una demostración de aprendizaje automático es mostrársela a otras personas y permitirles usarla.
Para hacerlo, cargaremos nuestra demostración de FoodVision Mini en Hugging Face.
Nota: La siguiente serie de pasos utiliza un flujo de trabajo Git (un sistema de seguimiento de archivos). Para obtener más información sobre cómo funciona Git, recomiendo consultar el tutorial de Git y GitHub para principiantes en freeCodeCamp.
- Regístrese para obtener una cuenta de Hugging Face.
- Inicie un nuevo Hugging Face Space yendo a su perfil y luego haciendo clic en "Nuevo espacio".
- Nota: Un espacio en Hugging Face también se conoce como "repositorio de códigos" (un lugar para almacenar su código/archivos) o "repositorio" para abreviar.
- Dale un nombre al Espacio, por ejemplo, el mío se llama
mrdbourke/foodvision_mini, puedes verlo aquí: https://huggingface.co/spaces/mrdbourke/foodvision_mini - Seleccione una licencia (yo usé MIT).
- Seleccione Gradio como Space SDK (kit de desarrollo de software).
- Nota: Puedes usar otras opciones como Streamlit, pero como nuestra aplicación está construida con Gradio, nos quedaremos con eso.
- Elija si su Espacio es público o privado (seleccioné público porque me gustaría que mi Espacio esté disponible para otros).
- Haga clic en "Crear espacio".
- Clone el repositorio localmente ejecutando algo como:
git clone https://huggingface.co/spaces/[YOUR_USERNAME]/[YOUR_SPACE_NAME]en la terminal o en el símbolo del sistema.- Nota: También puedes agregar archivos cargándolos en la pestaña "Archivos y versiones".
- Copie/mueva el contenido de la carpeta
foodvision_minidescargada a la carpeta del repositorio clonado. - Para cargar y rastrear archivos más grandes (por ejemplo, archivos de más de 10 MB o, en nuestro caso, nuestro archivo modelo PyTorch), necesitará instalar Git LFS (que significa para "almacenamiento de archivos grandes de git").
- Después de haber instalado Git LFS, puedes activarlo ejecutando
git lfs install. - En el directorio
foodvision_mini, realice un seguimiento de los archivos de más de 10 MB con Git LFS congit lfs track "*.file_extension".- Realice un seguimiento del archivo de modelo EffNetB2 PyTorch con
git lfs track "09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth".
- Realice un seguimiento del archivo de modelo EffNetB2 PyTorch con
- Seguimiento de
.gitattributes(creado automáticamente al clonar desde HuggingFace; este archivo ayudará a garantizar que nuestros archivos más grandes sean rastreados con Git LFS). Puede ver un archivo.gitattributesde ejemplo en [FoodVision Mini Hugging Face Space] (https://huggingface.co/spaces/mrdbourke/foodvision_mini/blob/main/.gitattributes).git agregar .gitattributes
- Agregue el resto de los archivos de la aplicación
foodvision_miniy confírmelos con:git agregar *git commit -m "primer compromiso"
- Envíe (cargue) los archivos a Hugging Face:
*
git push - Espere de 3 a 5 minutos hasta que se complete la compilación (las compilaciones futuras serán más rápidas) y su aplicación estará activa.
Si todo funcionó, debería ver un ejemplo en vivo de nuestra demostración de FoodVision Mini Gradio como este: https://huggingface.co/spaces/mrdbourke/foodvision_mini
E incluso podemos insertar nuestra demostración de FoodVision Mini Gradio en nuestra computadora portátil como un iframe con [IPython.display.IFrame](https:/ /ipython.readthedocs.io/en/stable/api/generated/IPython.display.html#IPython.display.IFrame) y un enlace a nuestro espacio en el formato https://hf.space/embed/[YOUR_USERNAME] /[TU_NOMBRE_ESPACIO]/+.
# IPython es una biblioteca para ayudar a que Python sea interactivo
from IPython.display import IFrame
# Incrustar la demostración de FoodVision Mini Gradio
IFrame(src="https://hf.space/embed/mrdbourke/foodvision_mini/+", width=900, height=750)
10. Creando FoodVision a lo grande¶
Hemos pasado las últimas secciones y capítulos trabajando para darle vida a FoodVision Mini.
Y ahora que lo hemos visto funcionar en una demostración en vivo, ¿qué tal si damos un paso más?
¿Cómo?
¡Visión alimentaria a lo grande!
Dado que FoodVision Mini está entrenado con imágenes de pizza, bistec y sushi del [conjunto de datos Food101] (https://pytorch.org/vision/main/generated/torchvision.datasets.Food101.html) (101 clases de alimentos x 1000 imágenes cada una ), ¿qué tal si hacemos FoodVision Big entrenando un modelo en las 101 clases?
¡Pasaremos de tres clases a 101!
¡Desde pizza, bistec, sushi hasta pizza, bistec, sushi, hot dog, tarta de manzana, pastel de zanahoria, pastel de chocolate, fuegos franceses, pan de ajo, ramen, nachos, tacos y más!
¿Cómo?
Bueno, tenemos todos los pasos implementados, todo lo que tenemos que hacer es modificar ligeramente nuestro modelo EffNetB2 y preparar un conjunto de datos diferente.
Para finalizar Milestone Project 3, recreemos una demostración de Gradio similar a FoodVision Mini (tres clases) pero para FoodVision Big (101 clases).

FoodVision Mini funciona con tres clases de alimentos: pizza, bistec y sushi. Y FoodVision Big va un paso más allá para trabajar en 101 clases de alimentos: todas las [clases en el conjunto de datos Food101](https://github.com/mrdbourke/pytorch-deep-learning/blob/main/extras/food101_class_names. TXT).
10.1 Creando un modelo y transformaciones para FoodVision Big¶
Al crear FoodVision Mini vimos que el modelo EffNetB2 era un buen equilibrio entre velocidad y rendimiento (funcionó bien a alta velocidad).
Así que continuaremos usando el mismo modelo para FoodVision Big.
Podemos crear un extractor de funciones EffNetB2 para Food101 usando nuestra función create_effnetb2_model() que creamos anteriormente, en la [sección 3.1](https://www.learnpytorch.io/09_pytorch_model_deployment/#31-creating-a-function-to -make-an-effnetb2-feature-extractor), y pasándole el parámetro num_classes=101 (ya que Food101 tiene 101 clases).
# Cree un modelo EffNetB2 capaz de adaptarse a 101 clases para Food101
effnetb2_food101, effnetb2_transforms = create_effnetb2_model(num_classes=101)
¡Hermoso!
Ahora obtengamos un resumen de nuestro modelo.
from torchinfo import summary
# # Obtenga un resumen del extractor de funciones EffNetB2 para Food101 con 101 clases de salida (descomentar para obtener una salida completa)
# resumen(effnetb2_food101,
# tamaño_entrada=(1, 3, 224, 224),
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"])
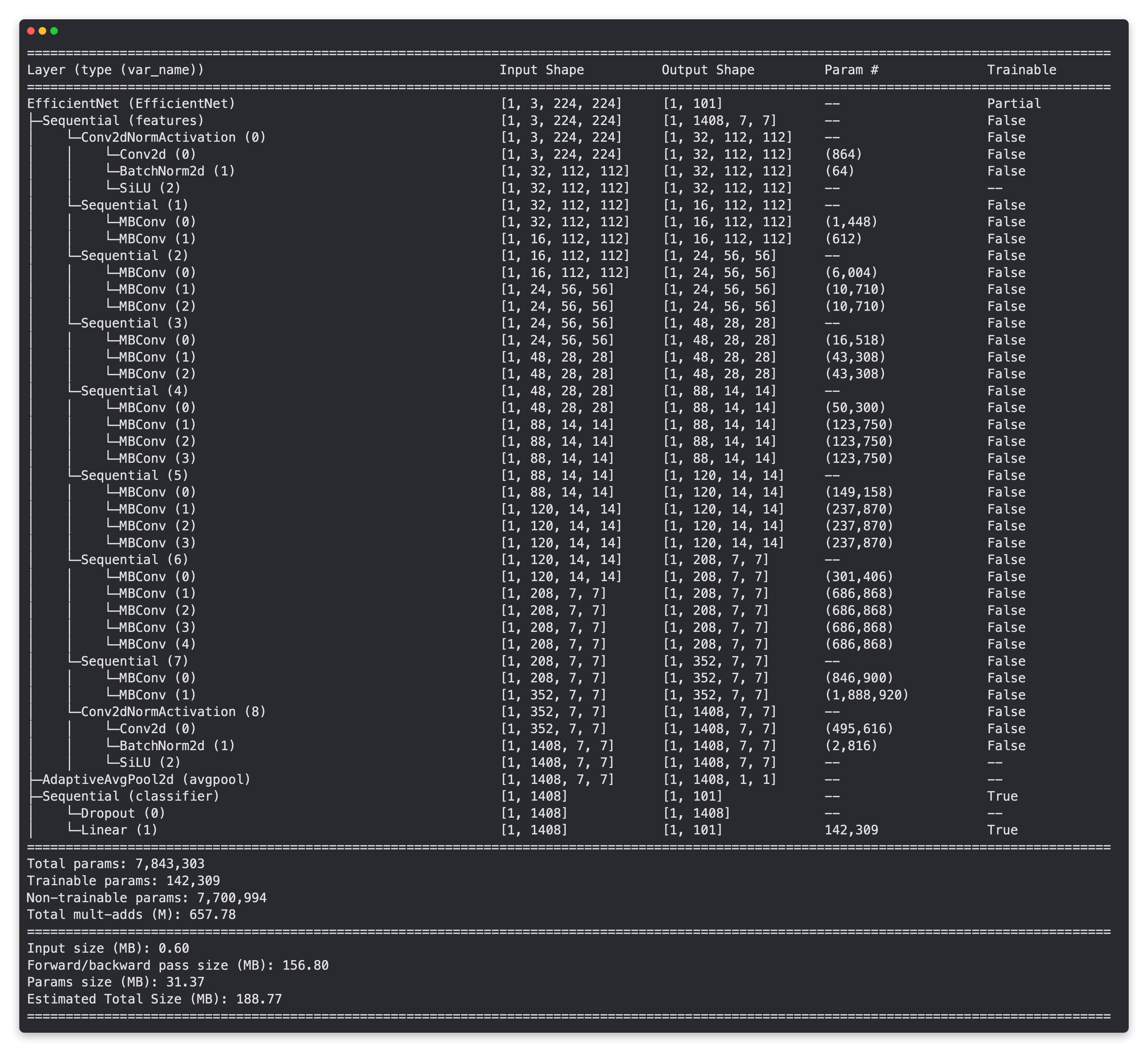 ¡Lindo!
¡Lindo!
Vea cómo, al igual que nuestro modelo EffNetB2 para FoodVision Mini, las capas base están congeladas (éstas están previamente entrenadas en ImageNet) y las capas externas (las capas clasificadoras) se pueden entrenar con una forma de salida de [batch_size, 101] (101 para 101 clases en Food101).
Ahora que vamos a tratar con bastante más datos de lo habitual, ¿qué tal si agregamos un poco de aumento de datos a nuestras transformaciones (effnetb2_transforms) para aumentar los datos de entrenamiento?
Nota: El aumento de datos es una técnica que se utiliza para alterar la apariencia de una muestra de entrenamiento de entrada (por ejemplo, rotar una imagen o sesgarla ligeramente) para aumentar artificialmente la diversidad de un conjunto de datos de entrenamiento y, con suerte, evitar el sobreajuste. Puede ver más sobre el aumento de datos en [04. Sección 6 de conjuntos de datos personalizados de PyTorch] (https://www.learnpytorch.io/04_pytorch_custom_datasets/#6-other-forms-of-transforms-data-augmentation).
Compongamos una canalización torchvision.transforms para usar torchvision.transforms.TrivialAugmentWide() (el mismo aumento de datos utilizado por el equipo de PyTorch en sus [recetas de visión por computadora] (https://pytorch.org/blog/how-to-train-state-of-the-art-models-using-torchvision-latest-primitives/#break- mejoras de precisión de clave)) así como effnetb2_transforms para transformar nuestras imágenes de entrenamiento.
# Cree transformaciones de datos de entrenamiento de Food101 (realice solo aumento de datos en las imágenes de entrenamiento)
food101_train_transforms = torchvision.transforms.Compose([
torchvision.transforms.TrivialAugmentWide(),
effnetb2_transforms,
])
¡Épico!
Ahora comparemos food101_train_transforms (para los datos de entrenamiento) y effnetb2_transforms (para los datos de prueba/inferencia).
print(f"Training transforms:\n{food101_train_transforms}\n")
print(f"Testing transforms:\n{effnetb2_transforms}")
10.2 Obtención de datos para FoodVision Big¶
Para FoodVision Mini, creamos nuestras propias divisiones de datos personalizadas de todo el conjunto de datos de Food101.
Para obtener el conjunto de datos completo de Food101, podemos usar torchvision.datasets.Food101().
Primero configuraremos una ruta al directorio data/ para almacenar las imágenes.
Luego descargaremos y transformaremos las divisiones del conjunto de datos de entrenamiento y prueba usando food101_train_transforms y effnetb2_transforms para transformar cada conjunto de datos respectivamente.
Nota: Si está utilizando Google Colab, la siguiente celda tardará entre 3 y 5 minutos en ejecutarse por completo y descargar las imágenes de Food101 desde PyTorch.
Esto se debe a que se están descargando más de 100.000 imágenes (101 clases x 1000 imágenes por clase). Si reinicia el tiempo de ejecución de Google Colab y regresa a esta celda, las imágenes deberán volver a descargarse. Alternativamente, si está ejecutando este cuaderno localmente, las imágenes se almacenarán en caché y se almacenarán en el directorio especificado por el parámetro
rootdetorchvision.datasets.Food101().
from torchvision import datasets
# Directorio de datos de configuración
from pathlib import Path
data_dir = Path("data")
# Obtenga datos de entrenamiento (~750 imágenes x 101 clases de alimentos)
train_data = datasets.Food101(root=data_dir, # path to download data to
split="train", # dataset split to get
transform=food101_train_transforms, # perform data augmentation on training data
download=True) # want to download?
# Obtenga datos de prueba (~250 imágenes x 101 clases de alimentos)
test_data = datasets.Food101(root=data_dir,
split="test",
transform=effnetb2_transforms, # perform normal EffNetB2 transforms on test data
download=True)
¡Datos descargados!
Ahora podemos obtener una lista de todos los nombres de clases usando train_data.classes.
# Obtener nombres de clases de Food101
food101_class_names = train_data.classes
# Ver los primeros 10
food101_class_names[:10]
¡Ho, ho! Esas son algunas comidas que suenan deliciosas (aunque nunca he oído hablar de los "buñuelos"... actualización: después de una búsqueda rápida en Google, los buñuelos también se ven deliciosos).
Puede ver una lista completa de los nombres de las clases Food101 en el curso GitHub en [extras/food101_class_names.txt](https://github.com/mrdbourke/pytorch-deep-learning/blob/main/extras/food101_class_names. TXT).
10.3 Creación de un subconjunto del conjunto de datos Food101 para experimentar más rápido¶
Esto es opcional.
No necesitamos crear otro subconjunto del conjunto de datos de Food101, podríamos entrenar y evaluar un modelo en las 101.000 imágenes completas.
Pero para seguir entrenando rápido, creemos una división del 20 % de los conjuntos de datos de entrenamiento y prueba.
Nuestro objetivo será ver si podemos superar los mejores resultados del [documento Food101] original (https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/) con solo el 20 % de los datos.
Para desglosar los conjuntos de datos que hemos utilizado/utilizaremos:
| Cuadernos(s) | Nombre del proyecto | Conjunto de datos | Número de clases | Imágenes de entrenamiento | Imágenes de prueba |
|---|---|---|---|---|---|
| 04, 05, 06, 07, 08 | FoodVision Mini (10% de datos) | Food101 división personalizada | 3 (pizza, bistec, sushi) | 225 | 75 |
| 07, 08, 09 | FoodVision Mini (20% de datos) | Food101 división personalizada | 3 (pizza, bistec, sushi) | 450 | 150 |
| 09 (este) | FoodVision Big (20% de datos) | Food101 división personalizada | 101 (todas las clases de Food101) | 15150 | 5050 |
| Ampliación | FoodVision grande | Food101 todos los datos | 101 | 75750 | 25250 |
¿Puedes ver la tendencia?
Así como el tamaño de nuestro modelo aumentó lentamente con el tiempo, también lo hizo el tamaño del conjunto de datos que hemos estado usando para los experimentos.
Nota: Para superar realmente los resultados del artículo original de Food101 con el 20 % de los datos, tendríamos que entrenar un modelo con el 20 % de los datos de entrenamiento y luego evaluar nuestro modelo en el conjunto de pruebas completo en lugar de que la división que creamos. Dejaré esto como un ejercicio de extensión para que lo pruebes. También le recomiendo que intente entrenar un modelo en todo el conjunto de datos de entrenamiento de Food101.
Para dividir nuestro FoodVision Big (20% de datos), creemos una función llamada split_dataset() para dividir un conjunto de datos determinado en ciertas proporciones.
Podemos usar torch.utils.data.random_split() para crear divisiones de tamaños determinados usando ` parámetro de longitudes.
El parámetro longitudes acepta una lista de longitudes divididas deseadas donde el total de la lista debe ser igual a la longitud total del conjunto de datos.
Por ejemplo, con un conjunto de datos de tamaño 100, podría pasar longitudes=[20, 80] para recibir una división del 20 % y del 80 %.
Querremos que nuestra función devuelva dos divisiones, una con la longitud objetivo (por ejemplo, el 20 % de los datos de entrenamiento) y la otra con la longitud restante (por ejemplo, el 80 % restante de los datos de entrenamiento).
Finalmente, estableceremos el parámetro generador en un valor torch.manual_seed() para mayor reproducibilidad.
def split_dataset(dataset:torchvision.datasets, split_size:float=0.2, seed:int=42):
"""Randomly splits a given dataset into two proportions based on split_size and seed.
Args:
dataset (torchvision.datasets): A PyTorch Dataset, typically one from torchvision.datasets.
split_size (float, optional): How much of the dataset should be split?
E.g. split_size=0.2 means there will be a 20% split and an 80% split. Defaults to 0.2.
seed (int, optional): Seed for random generator. Defaults to 42.
Returns:
tuple: (random_split_1, random_split_2) where random_split_1 is of size split_size*len(dataset) and
random_split_2 is of size (1-split_size)*len(dataset).
"""
# Create split lengths based on original dataset length
length_1 = int(len(dataset) * split_size) # desired length
length_2 = len(dataset) - length_1 # remaining length
# Print out info
print(f"[INFO] Splitting dataset of length {len(dataset)} into splits of size: {length_1} ({int(split_size*100)}%), {length_2} ({int((1-split_size)*100)}%)")
# Create splits with given random seed
random_split_1, random_split_2 = torch.utils.data.random_split(dataset,
lengths=[length_1, length_2],
generator=torch.manual_seed(seed)) # set the random seed for reproducible splits
return random_split_1, random_split_2
¡Se creó la función de división del conjunto de datos!
Ahora probémoslo creando una división del 20% del conjunto de datos de prueba y capacitación de Food101.
# Crear capacitación División del 20% de Food101
train_data_food101_20_percent, _ = split_dataset(dataset=train_data,
split_size=0.2)
# Crear pruebas con una división del 20% de Food101
test_data_food101_20_percent, _ = split_dataset(dataset=test_data,
split_size=0.2)
len(train_data_food101_20_percent), len(test_data_food101_20_percent)
¡Excelente!
10.4 Convirtiendo nuestros conjuntos de datos de Food101 en DataLoaders¶
Ahora conviertamos nuestras divisiones del conjunto de datos Food101 20% en DataLoader usando torch.utils.data.DataLoader().
Estableceremos shuffle=True solo para los datos de entrenamiento y el tamaño del lote en 32 para ambos conjuntos de datos.
Y estableceremos num_workers en 4 si el recuento de CPU está disponible o 2 si no lo está (aunque el valor de num_workers es muy experimental y dependerá del hardware que estés usando, hay un hilo de discusión activo sobre esto en los foros de PyTorch).
import os
import torch
BATCH_SIZE = 32
NUM_WORKERS = 2 if os.cpu_count() <= 4 else 4 # this value is very experimental and will depend on the hardware you have available, Google Colab generally provides 2x CPUs
# Crear Food101 20 por ciento de entrenamiento DataLoader
train_dataloader_food101_20_percent = torch.utils.data.DataLoader(train_data_food101_20_percent,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS)
# Crear Food101 20 por ciento de prueba DataLoader
test_dataloader_food101_20_percent = torch.utils.data.DataLoader(test_data_food101_20_percent,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS)
10.5 Entrenamiento FoodVision Modelo grande¶
¡El modelo FoodVision Big y DataLoaders están listos!
Hora de entrenar.
Crearemos un optimizador usando torch.optim.Adam() y una tasa de aprendizaje de 1e-3.
Y debido a que tenemos tantas clases, también configuraremos una función de pérdida usando torch.nn.CrossEntropyLoss() con label_smoothing=0.1, en línea con la tecnología de punta de torchvision receta de entrenamiento.
¿Qué es suavizado de etiquetas?
El suavizado de etiquetas es una técnica de regularización (regularización es otra palabra para describir el proceso de prevención del sobreajuste) que reduce la valor que un modelo le da a cualquier etiqueta y lo distribuye entre las demás etiquetas.
En esencia, en lugar de que un modelo se demasiado confiado en una sola etiqueta, el suavizado de etiquetas otorga un valor distinto de cero a otras etiquetas para ayudar en la generalización.
Por ejemplo, si un modelo sin suavizado de etiquetas tuviera los siguientes resultados para 5 clases:
[0, 0, 0,99, 0,01, 0]
Un modelo con suavizado de etiquetas puede tener los siguientes resultados:
[0,01, 0,01, 0,96, 0,01, 0,01]
El modelo todavía confía en su predicción de la clase 3, pero dar valores pequeños a las otras etiquetas obliga al modelo a considerar al menos otras opciones.
Finalmente, para agilizar las cosas, entrenaremos nuestro modelo durante cinco épocas usando la función engine.train() que creamos en 05. PyTorch Going Modular sección 4 con el objetivo de superar al Food101 original resultado del artículo de 56,4% de precisión en el conjunto de prueba.
¡Entrenemos a nuestro modelo más grande hasta el momento!
Nota: La ejecución de la siguiente celda tardará entre 15 y 20 minutos en Google Colab. Esto se debe a que está entrenando el modelo más grande con la mayor cantidad de datos que hemos usado hasta ahora (15,150 imágenes de entrenamiento, 5050 imágenes de prueba). Y es una de las razones por las que antes decidimos dividir el 20% del conjunto de datos completo de Food101 (para que el entrenamiento no tomara más de una hora).
from going_modular.going_modular import engine
# Optimizador de configuración
optimizer = torch.optim.Adam(params=effnetb2_food101.parameters(),
lr=1e-3)
# Función de pérdida de configuración
loss_fn = torch.nn.CrossEntropyLoss(label_smoothing=0.1) # throw in a little label smoothing because so many classes
# Quiere superar el artículo original de Food101 con un 20 % de datos, necesita más del 56,4 % según el conjunto de datos de prueba
set_seeds()
effnetb2_food101_results = engine.train(model=effnetb2_food101,
train_dataloader=train_dataloader_food101_20_percent,
test_dataloader=test_dataloader_food101_20_percent,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=5,
device=device)
Woooo!!!!
Parece que superamos los resultados del artículo original de Food101 de 56,4% de precisión con solo el 20% de los datos de entrenamiento (aunque solo evaluamos el 20% de los datos de las pruebas también, para replicar completamente los resultados, podríamos evaluar el 100% de las pruebas). datos).
¡Ese es el poder del aprendizaje por transferencia!
10.6 Inspeccionando las curvas de pérdidas del modelo FoodVision Big¶
Hagamos visuales nuestras curvas de pérdidas de FoodVision Big.
Podemos hacerlo con la función plot_loss_curves() de helper_functions.py.
from helper_functions import plot_loss_curves
# Consulte las curvas de pérdidas de FoodVision Big
plot_loss_curves(effnetb2_food101_results)
¡¡¡Lindo!!!
Parece que nuestras técnicas de regularización (aumento de datos y suavizado de etiquetas) ayudaron a evitar que nuestro modelo se sobreajustara (la pérdida de entrenamiento sigue siendo mayor que la pérdida de prueba), lo que indica que nuestro modelo tiene un poco más de capacidad para aprender y podría mejorar con más entrenamiento.
10.7 Guardar y cargar FoodVision Big¶
Ahora que hemos entrenado nuestro modelo más grande hasta el momento, guardémoslo para poder volver a cargarlo más tarde.
from going_modular.going_modular import utils
# Crear una ruta modelo
effnetb2_food101_model_path = "09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth"
# Guardar modelo FoodVision Big
utils.save_model(model=effnetb2_food101,
target_dir="models",
model_name=effnetb2_food101_model_path)
¡Modelo guardado!
Antes de continuar, asegurémonos de poder volver a cargarlo.
Lo haremos creando primero una instancia de modelo con create_effnetb2_model(num_classes=101) (101 clases para todas las clases de Food101).
Y luego cargar el state_dict() guardado con [torch.nn.Module.load_state_dict()](https://pytorch.org/docs/stable/generated/torch.nn.Module.html?highlight=load_state_dict #torch.nn.Module.load_state_dict) y torch.load().
# Crear una instancia EffNetB2 compatible con Food101
loaded_effnetb2_food101, effnetb2_transforms = create_effnetb2_model(num_classes=101)
# Cargue el state_dict() del modelo guardado
loaded_effnetb2_food101.load_state_dict(torch.load("models/09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth"))
10.8 Comprobación del tamaño del modelo grande de FoodVision¶
Nuestro modelo FoodVision Big es capaz de clasificar 101 clases frente a las 3 clases de FoodVision Mini, ¡un aumento de 33,6 veces!
¿Cómo afecta esto al tamaño del modelo?
Vamos a averiguar.
from pathlib import Path
# Obtenga el tamaño del modelo en bytes y luego conviértalo a megabytes
pretrained_effnetb2_food101_model_size = Path("models", effnetb2_food101_model_path).stat().st_size // (1024*1024) # division converts bytes to megabytes (roughly)
print(f"Pretrained EffNetB2 feature extractor Food101 model size: {pretrained_effnetb2_food101_model_size} MB")
Mmm, parece que el tamaño del modelo se mantuvo prácticamente igual (30 MB para FoodVision Big y 29 MB para FoodVision Mini) a pesar del gran aumento en el número de clases.
Esto se debe a que todos los parámetros adicionales para FoodVision Big están solo en la última capa (el encabezado del clasificador).
Todas las capas base son iguales entre FoodVision Big y FoodVision Mini.
Volver arriba y comparar los resúmenes de los modelos dará más detalles.
| Modelo | Forma de salida (núm. de clases) | Parámetros entrenables | Parámetros totales | Tamaño del modelo (MB) |
|---|---|---|---|---|
| FoodVision Mini (extractor de funciones EffNetB2) | 3 | 4.227 | 7.705.221 | 29 |
| FoodVision Big (extractor de funciones EffNetB2) | 101 | 142.309 | 7.843.303 | 30 |
11. Convertir nuestro modelo FoodVision Big en una aplicación implementable¶
Tenemos un modelo EffNetB2 entrenado y guardado en el 20% del conjunto de datos de Food101.
Y en lugar de dejar que nuestro modelo viva en una carpeta toda su vida, ¡implementémoslo!
Implementaremos nuestro modelo FoodVision Big de la misma manera que implementamos nuestro modelo FoodVision Mini, como una demostración de Gradio en Hugging Face Spaces.
Para comenzar, creemos un directorio demos/foodvision_big/ para almacenar nuestros archivos de demostración de FoodVision Big, así como un directorio demos/foodvision_big/examples para guardar una imagen de ejemplo con la que probar la demostración.
Cuando hayamos terminado tendremos la siguiente estructura de archivos:
población/
comidavision_big/
09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth
aplicación.py
nombres_clase.txt
ejemplos/
ejemplo_1.jpg
modelo.py
requisitos.txt
Dónde:
09_pretrained_effnetb2_feature_extractor_food101_20_percent.pthes nuestro archivo de modelo PyTorch entrenado.app.pycontiene nuestra aplicación FoodVision Big Gradio.class_names.txtcontiene todos los nombres de clases de FoodVision Big.examples/contiene imágenes de ejemplo para usar con nuestra aplicación Gradio.model.pycontiene la definición del modelo, así como cualquier transformación asociada con el modelo.requirements.txtcontiene las dependencias para ejecutar nuestra aplicación, comotorch,torchvisionygradio.
from pathlib import Path
# Crear ruta de demostración de FoodVision Big
foodvision_big_demo_path = Path("demos/foodvision_big/")
# Haga el directorio de demostración de FoodVision Big
foodvision_big_demo_path.mkdir(parents=True, exist_ok=True)
# Directorio de ejemplos de demostración de Make FoodVision Big
(foodvision_big_demo_path / "examples").mkdir(parents=True, exist_ok=True)
11.1 Descargar una imagen de ejemplo y moverla al directorio ejemplos¶
Para nuestra imagen de ejemplo, usaremos la fiel [imagen pizza-dad] (https://github.com/mrdbourke/pytorch-deep-learning/blob/main/images/04-pizza-dad. jpeg) (una foto de mi papá comiendo pizza).
Así que descarguémoslo del curso GitHub mediante el comando !wget y luego podemos moverlo a demos/foodvision_big/examples con el comando !mv (abreviatura de "mover").
Mientras estamos aquí, trasladaremos nuestro modelo Food101 EffNetB2 entrenado de models/09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth a demos/foodvision_big también.
# Descargar y mover una imagen de ejemplo
!wget https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/images/04-pizza-dad.jpeg
!mv 04-pizza-dad.jpeg demos/foodvision_big/examples/04-pizza-dad.jpg
# Mueva el modelo entrenado a la carpeta de demostración de FoodVision Big (se producirá un error si el modelo ya se ha movido)
!mv models/09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth demos/foodvision_big
11.2 Guardar nombres de clases de Food101 en un archivo (class_names.txt)¶
Debido a que hay tantas clases en el conjunto de datos Food101, en lugar de almacenarlas como una lista en nuestro archivo app.py, guardémoslas en un archivo .txt y leámoslas cuando sea necesario.
Primero recordaremos cómo se ven revisando food101_class_names.
# Consulte los primeros 10 nombres de clases de Food101
food101_class_names[:10]
Maravilloso, ahora podemos escribirlos en un archivo de texto creando primero una ruta a demos/foodvision_big/class_names.txt y luego abriendo un archivo con open() de Python y luego escribiendo en él dejando una nueva línea para cada clase. .
Idealmente, queremos que los nombres de nuestras clases se guarden como:
tarta de manzana
Costillitas
baklava
Carpaccio de carne
tartar_de_carne
...
# Crear ruta a los nombres de clases de Food101
foodvision_big_class_names_path = foodvision_big_demo_path / "class_names.txt"
# Escriba la lista de nombres de clases de Food101 en el archivo
with open(foodvision_big_class_names_path, "w") as f:
print(f"[INFO] Saving Food101 class names to {foodvision_big_class_names_path}")
f.write("\n".join(food101_class_names)) # leave a new line between each class
Excelente, ahora asegurémonos de poder leerlos.
Para hacerlo usaremos open() de Python en modo lectura ("r") y luego usaremos readlines( ) método para leer cada línea de nuestro archivo class_names.txt.
Y podemos guardar los nombres de las clases en una lista eliminando el valor de nueva línea de cada uno de ellos con una lista de comprensión y strip().
# Abra el archivo de nombres de clases Food101 y lea cada línea en una lista
with open(foodvision_big_class_names_path, "r") as f:
food101_class_names_loaded = [food.strip() for food in f.readlines()]
# Ver los primeros 5 nombres de clases cargados nuevamente en
food101_class_names_loaded[:5]
11.3 Convirtiendo nuestro modelo FoodVision Big en un script de Python (model.py)¶
Al igual que en la demostración de FoodVision Mini, creemos un script que sea capaz de crear una instancia de un modelo de extracción de características EffNetB2 junto con sus transformaciones necesarias.
%%writefile demos/foodvision_big/model.py
import torch
import torchvision
from torch import nn
def create_effnetb2_model(num_classes:int=3,
seed:int=42):
"""Creates an EfficientNetB2 feature extractor model and transforms.
Args:
num_classes (int, optional): number of classes in the classifier head.
Defaults to 3.
seed (int, optional): random seed value. Defaults to 42.
Returns:
model (torch.nn.Module): EffNetB2 feature extractor model.
transforms (torchvision.transforms): EffNetB2 image transforms.
"""
# Create EffNetB2 pretrained weights, transforms and model
weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.efficientnet_b2(weights=weights)
# Freeze all layers in base model
for param in model.parameters():
param.requires_grad = False
# Change classifier head with random seed for reproducibility
torch.manual_seed(seed)
model.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True),
nn.Linear(in_features=1408, out_features=num_classes),
)
return model, transforms
11.4 Convirtiendo nuestra aplicación FoodVision Big Gradio en un script Python (app.py)¶
Tenemos un script model.py de FoodVision Big, ahora creemos un script app.py de FoodVision Big.
De nuevo, esto será prácticamente igual que el script app.py de FoodVision Mini, excepto que cambiaremos:
- Configuración de importaciones y nombres de clases - La variable
class_namesserá una lista para todas las clases de Food101 en lugar de pizza, bistec o sushi. Podemos acceder a ellos a través dedemos/foodvision_big/class_names.txt. - Preparación de modelos y transformaciones - El
modelotendránum_classes=101en lugar denum_classes=3. También nos aseguraremos de cargar los pesos de"09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth"(nuestra ruta del modelo FoodVision Big). - Función de predicción: seguirá siendo la misma que
app.pyde FoodVision Mini. - Aplicación Gradio: la interfaz de Gradio tendrá diferentes parámetros de "título", "descripción" y "artículo" para reflejar los detalles de FoodVision Big.
También nos aseguraremos de guardarlo en demos/foodvision_big/app.py usando el comando mágico %%writefile.
%%writefile demos/foodvision_big/app.py
# ## 1. Configuración de importaciones y nombres de clases ###
import gradio as gr
import os
import torch
from model import create_effnetb2_model
from timeit import default_timer as timer
from typing import Tuple, Dict
# Configurar nombres de clases
with open("class_names.txt", "r") as f: # reading them in from class_names.txt
class_names = [food_name.strip() for food_name in f.readlines()]
# ## 2. Preparación del modelo y transforma ###
# Crear modelo
effnetb2, effnetb2_transforms = create_effnetb2_model(
num_classes=101, # could also use len(class_names)
)
# Cargar pesos guardados
effnetb2.load_state_dict(
torch.load(
f="09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth",
map_location=torch.device("cpu"), # load to CPU
)
)
# ## 3. Función de predicción ###
# Crear función de predicción
def predict(img) -> Tuple[Dict, float]:
"""Transforms and performs a prediction on img and returns prediction and time taken.
"""
# Start the timer
start_time = timer()
# Transform the target image and add a batch dimension
img = effnetb2_transforms(img).unsqueeze(0)
# Put model into evaluation mode and turn on inference mode
effnetb2.eval()
with torch.inference_mode():
# Pass the transformed image through the model and turn the prediction logits into prediction probabilities
pred_probs = torch.softmax(effnetb2(img), dim=1)
# Create a prediction label and prediction probability dictionary for each prediction class (this is the required format for Gradio's output parameter)
pred_labels_and_probs = {class_names[i]: float(pred_probs[0][i]) for i in range(len(class_names))}
# Calculate the prediction time
pred_time = round(timer() - start_time, 5)
# Return the prediction dictionary and prediction time
return pred_labels_and_probs, pred_time
# ## 4. Aplicación Gradio ###
# Crear cadenas de título, descripción y artículo.
title = "FoodVision Big 🍔👁"
description = "An EfficientNetB2 feature extractor computer vision model to classify images of food into [101 different classes](https://github.com/mrdbourke/pytorch-deep-learning/blob/main/extras/food101_class_names.txt)."
article = "Created at [09. PyTorch Model Deployment](https://www.learnpytorch.io/09_pytorch_model_deployment/)."
# Crear una lista de ejemplos desde el directorio "examples/"
example_list = [["examples/" + example] for example in os.listdir("examples")]
# Crear interfaz Gradio
demo = gr.Interface(
fn=predict,
inputs=gr.Image(type="pil"),
outputs=[
gr.Label(num_top_classes=5, label="Predictions"),
gr.Number(label="Prediction time (s)"),
],
examples=example_list,
title=title,
description=description,
article=article,
)
# ¡Inicia la aplicación!
demo.launch()
11.5 Creación de un archivo de requisitos para FoodVision Big (requirements.txt)¶
Ahora todo lo que necesitamos es un archivo requirements.txt para indicarle a nuestro Hugging Face Space qué dependencias requiere nuestra aplicación FoodVision Big.
%%writefile demos/foodvision_big/requirements.txt
torch==1.12.0
torchvision==0.13.0
gradio==3.1.4
11.6 Descarga de nuestros archivos de la aplicación FoodVision Big¶
Tenemos todos los archivos que necesitamos para implementar nuestra aplicación FoodVision Big en Hugging Face, ahora comprimámoslos y descargámoslos.
Usaremos el mismo proceso que usamos para la aplicación FoodVision Mini anterior en la [sección 9.1: Descarga de los archivos de nuestra aplicación Foodvision Mini](https://www.learnpytorch.io/09_pytorch_model_deployment/#91-downloading-our-foodvision -archivos-mini-aplicación).
# Comprima la carpeta foodvision_big pero excluya ciertos archivos
!cd demos/foodvision_big && zip -r ../foodvision_big.zip * -x "*.pyc" "*.ipynb" "*__pycache__*" "*ipynb_checkpoints*"
# Descargue la aplicación FoodVision Big comprimida (si se ejecuta en Google Colab)
try:
from google.colab import files
files.download("demos/foodvision_big.zip")
except:
print("Not running in Google Colab, can't use google.colab.files.download()")
11.7 Implementación de nuestra aplicación FoodVision Big en HuggingFace Spaces¶
¡Hermoso!
¡Es hora de darle vida a nuestro modelo más grande de todo el curso!
Implementemos nuestra demostración de FoodVision Big Gradio en Hugging Face Spaces para que podamos probarla de forma interactiva y permitir que otros experimenten la magia de nuestros esfuerzos de aprendizaje automático.
Nota: Hay varias formas de cargar archivos en Hugging Face Spaces. Los siguientes pasos tratan a Hugging Face como un repositorio git para rastrear archivos. Sin embargo, también puede cargar directamente en Hugging Face Spaces a través de la interfaz web o por la biblioteca
huggingface_hub.
La buena noticia es que ya hemos realizado los pasos para hacerlo con FoodVision Mini, así que ahora todo lo que tenemos que hacer es personalizarlos para que se adapten a FoodVision Big:
- Regístrese para obtener una cuenta de Hugging Face.
- Inicie un nuevo Hugging Face Space yendo a su perfil y luego haciendo clic en "Nuevo espacio".
- Nota: Un espacio en Hugging Face también se conoce como "repositorio de códigos" (un lugar para almacenar su código/archivos) o "repositorio" para abreviar.
- Dale un nombre al Espacio, por ejemplo, el mío se llama
mrdbourke/foodvision_big, puedes verlo aquí: https://huggingface.co/spaces/mrdbourke/foodvision_big - Seleccione una licencia (yo usé MIT).
- Seleccione Gradio como Space SDK (kit de desarrollo de software).
- Nota: Puedes usar otras opciones como Streamlit, pero como nuestra aplicación está construida con Gradio, nos quedaremos con eso.
- Elija si su Espacio es público o privado (seleccioné público porque me gustaría que mi Espacio esté disponible para otros).
- Haga clic en "Crear espacio".
- Clone el repositorio localmente ejecutando:
git clone https://huggingface.co/spaces/[YOUR_USERNAME]/[YOUR_SPACE_NAME]en la terminal o en el símbolo del sistema.- Nota: También puedes agregar archivos cargándolos en la pestaña "Archivos y versiones".
- Copie/mueva el contenido de la carpeta
foodvision_bigdescargada a la carpeta del repositorio clonado. - Para cargar y rastrear archivos más grandes (por ejemplo, archivos de más de 10 MB o, en nuestro caso, nuestro archivo modelo PyTorch), necesitará instalar Git LFS (que significa para "almacenamiento de archivos grandes de git").
- Después de haber instalado Git LFS, puedes activarlo ejecutando
git lfs install. - En el directorio
foodvision_big, realice un seguimiento de los archivos de más de 10 MB con Git LFS congit lfs track "*.file_extension".- Realice un seguimiento del archivo de modelo EffNetB2 PyTorch con
git lfs track "09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth". - Nota: Si recibe algún error al cargar imágenes, es posible que también deba rastrearlas con
git lfs, por ejemplo,git lfs track "examples/04-pizza-dad.jpg"
- Realice un seguimiento del archivo de modelo EffNetB2 PyTorch con
- Seguimiento de
.gitattributes(creado automáticamente al clonar desde HuggingFace; este archivo ayudará a garantizar que nuestros archivos más grandes sean rastreados con Git LFS). Puede ver un archivo.gitattributesde ejemplo en [FoodVision Big Hugging Face Space] (https://huggingface.co/spaces/mrdbourke/foodvision_big/blob/main/.gitattributes).git agregar .gitattributes
- Agregue el resto de los archivos de la aplicación
foodvision_bigy confírmelos con:git agregar *git commit -m "primer compromiso"
- Envíe (cargue) los archivos a Hugging Face:
*
git push - Espere de 3 a 5 minutos hasta que se complete la compilación (las compilaciones futuras serán más rápidas) y su aplicación estará activa.
Si todo funcionó correctamente, ¡nuestra demostración de FoodVision Big Gradio debería estar lista para clasificar!
Puedes ver mi versión aquí: https://huggingface.co/spaces/mrdbourke/foodvision_big/
O incluso podemos insertar nuestra demostración de FoodVision Big Gradio directamente en nuestro cuaderno como un iframe con [IPython.display.IFrame](https: //ipython.readthedocs.io/en/stable/api/generated/IPython.display.html#IPython.display.IFrame) y un enlace a nuestro espacio en el formato https://hf.space/embed/[YOUR_USERNAME ]/[TU_NOMBRE_ESPACIO]/+.
# IPython es una biblioteca para ayudar a trabajar con Python de forma interactiva
from IPython.display import IFrame
# Incruste la demostración de FoodVision Big Gradio como un iFrame
IFrame(src="https://hf.space/embed/mrdbourke/foodvision_big/+", width=900, height=750)
¡¿¡Cuan genial es eso!?!
Hemos recorrido un largo camino desde la construcción de modelos PyTorch para predecir una línea recta... ¡ahora estamos construyendo modelos de visión por computadora accesibles para personas de todo el mundo!
Principales conclusiones¶
- La implementación es tan importante como la capacitación. Una vez que tenga un buen modelo de trabajo, su primera pregunta debería ser: ¿cómo puedo implementarlo y hacerlo accesible para otros? La implementación le permite probar su modelo en el mundo real en lugar de en conjuntos de prueba y capacitación privados.
- Tres preguntas para la implementación del modelo de aprendizaje automático:
- ¿Cuál es el caso de uso más ideal para el modelo (qué tan bien y qué tan rápido funciona)?
- ¿A dónde irá el modelo (en el dispositivo o en la nube)?
- ¿Cómo funcionará el modelo (las predicciones están en línea o fuera de línea)?
- Las opciones de implementación son abundantes. Pero es mejor empezar de forma sencilla. Una de las mejores formas actuales (digo actual porque estas cosas siempre están cambiando) es usar Gradio para crear una demostración y alojarla en Hugging Face Spaces. Comience de manera simple y amplíelo cuando sea necesario.
- Nunca dejes de experimentar. Las necesidades de tu modelo de aprendizaje automático probablemente cambiarán con el tiempo, por lo que implementar un único modelo no es el último paso. Es posible que encuentre cambios en el conjunto de datos, por lo que tendrá que actualizar su modelo. O se publica una nueva investigación y hay una mejor arquitectura para usar.
- Por lo tanto, implementar un modelo es un paso excelente, pero probablemente querrás actualizarlo con el tiempo.
- La implementación del modelo de aprendizaje automático es parte de la práctica de ingeniería de MLOps (operaciones de aprendizaje automático). MLOps es una extensión de DevOps (operaciones de desarrollo) e involucra todas las partes de ingeniería relacionadas con el entrenamiento de un modelo: recopilación y almacenamiento de datos, datos preprocesamiento, implementación de modelos, monitoreo de modelos, control de versiones y más. Es un campo que evoluciona rápidamente, pero existen algunos recursos sólidos para aprender más, muchos de los cuales se encuentran en [Recursos adicionales de PyTorch](https://www.learnpytorch.io/pytorch_extra_resources/#resources-for-machine-learning-and -ingeniería-de-aprendizaje-profundo).
Ejercicios¶
Todos los ejercicios se centran en practicar el código anterior.
Debería poder completarlos haciendo referencia a cada sección o siguiendo los recursos vinculados.
Recursos:
- [Cuaderno de plantilla de ejercicios para 09] (https://github.com/mrdbourke/pytorch-deep-learning/blob/main/extras/exercises/09_pytorch_model_deployment_exercises.ipynb).
- Cuaderno de soluciones de ejemplo para 09 pruebe los ejercicios antes de mirar esto.
- Vea un [video tutorial de las soluciones en YouTube] en vivo (https://youtu.be/jOX5ZCkWO-0) (errores y todo).
- Realice y programe predicciones con ambos modelos de extracción de características en el conjunto de datos de prueba utilizando la GPU (
device="cuda"). Compare los tiempos de predicción del modelo en GPU y CPU: ¿esto cierra la brecha entre ellos? Por ejemplo, ¿hacer predicciones en la GPU hace que los tiempos de predicción del extractor de funciones de ViT se acerquen más a los tiempos de predicción del extractor de funciones de EffNetB2?- Encontrarás el código para realizar estos pasos en la [sección 5. Hacer predicciones con nuestros modelos entrenados y cronometrarlas](https://www.learnpytorch.io/09_pytorch_model_deployment/#5-making-predictions-with-our-trained -models-and-timing-them) y [sección 6. Comparación de resultados de modelos, tiempos de predicción y tamaño](https://www.learnpytorch.io/09_pytorch_model_deployment/#6-comparing-model-results-prediction-times-and -tamaño).
- El extractor de funciones de ViT parece tener más capacidad de aprendizaje (debido a más parámetros) que EffNetB2. ¿Cómo le va en la división más grande del 20 % de todo el conjunto de datos de Food101?
- Entrene un extractor de funciones ViT en el conjunto de datos 20% Food101 durante 5 épocas, tal como lo hicimos con EffNetB2 en la sección 10. Creando FoodVision Big.
- Haga predicciones en el conjunto de datos de prueba 20 % de Food101 con el extractor de funciones ViT del ejercicio 2 y encuentre las predicciones "más incorrectas".
- Las predicciones serán las que tengan mayor probabilidad de predicción pero con la etiqueta de predicción incorrecta.
- Escribe una oración o dos sobre por qué crees que el modelo se equivocó en estas predicciones.
- Evalúe el extractor de funciones de ViT en todo el conjunto de datos de prueba de Food101 en lugar de solo la versión del 20 %, ¿cómo funciona?
- ¿Supera el mejor resultado del artículo original de Food101 con una precisión del 56,4%?
- Diríjase a Paperswithcode.com y busque el modelo actual con mejor rendimiento en el conjunto de datos de Food101.
- ¿Qué modelo de arquitectura utiliza?
- Escriba de 1 a 3 posibles puntos de falla de nuestros modelos FoodVision implementados y cuáles podrían ser algunas posibles soluciones.
- Por ejemplo, ¿qué pasaría si alguien subiera una foto que no fuera de comida a nuestro modelo FoodVision Mini?
- Elija cualquier conjunto de datos de
torchvision.datasetsy entrene un modelo de extracción de características usando un modelo detorchvision.models(puede usar uno de los modelos que ya hemos creado, por ejemplo, EffNetB2 o ViT) durante 5 épocas y luego implementar su modelo como una aplicación Gradio en Hugging Face Espacios.- Es posible que desee elegir un conjunto de datos más pequeño/hacer una división más pequeña para que el entrenamiento no demore demasiado.
- ¡Me encantaría ver tus modelos implementados! Así que asegúrese de compartirlos en Discord o en la [página de debates de GitHub del curso] (https://github.com/mrdbourke/pytorch-deep-learning/discussions).
Extracurricular¶
- La implementación del modelo de aprendizaje automático es generalmente un desafío de ingeniería en lugar de un desafío de aprendizaje automático puro; consulte la [sección de ingeniería de aprendizaje automático de recursos adicionales de PyTorch] (https://www.learnpytorch.io/pytorch_extra_resources/#resources-for-machine-learning -y-deep-learning-engineering) para obtener recursos sobre cómo aprender más.
- En el interior encontrará recomendaciones de recursos como el libro de Chip Huyen Designing Machine Learning Systems ( especialmente el capítulo 7 sobre implementación de modelos) y el [curso Made with ML MLOps] de Goku Mohandas (https://madewithml.com/#mlops).
- A medida que empieces a construir más y más proyectos propios, es probable que empieces a usar Git (y potencialmente GitHub) con bastante frecuencia. Para obtener más información sobre ambos, recomiendo el video Git y GitHub para principiantes: curso intensivo en el canal de YouTube freeCodeCamp.
- Sólo hemos arañado la superficie de lo que es posible con Gradio. Para obtener más información, recomiendo consultar la documentación completa, especialmente:
- Todos los diferentes tipos de [componentes de entrada y salida] (https://gradio.app/docs/#components).
- La API de Gradio Blocks para flujos de trabajo más avanzados.
- El capítulo del curso Hugging Face sobre [cómo usar Gradio con Hugging Face] (https://huggingface.co/course/chapter9/1).
- Los dispositivos Edge no se limitan a teléfonos móviles, incluyen computadoras pequeñas como Raspberry Pi y el equipo de PyTorch tiene un fantástico tutorial de publicación de blog sobre la implementación un modelo de PyTorch a uno.
- Para obtener una guía fantástica sobre el desarrollo de aplicaciones basadas en inteligencia artificial y aprendizaje automático, consulte la [Guía de personas + inteligencia artificial de Google] (https://pair.withgoogle.com/guidebook). Una de mis favoritas es la sección sobre [establecer las expectativas correctas] (https://pair.withgoogle.com/guidebook/patterns#set-the-right-expectations).
- Cubrí más de este tipo de recursos, incluidas guías de Apple, Microsoft y más en la edición de abril de 2021 de Machine Learning Monthly (un boletín mensual que envío con lo último y lo mejor del campo de ML).
- Si desea acelerar el tiempo de ejecución de su modelo en la CPU, debe conocer TorchScript, [ONNX](https://pytorch .org/docs/stable/onnx.html) (Open Neural Network Exchange) y [OpenVINO](https://docs.openvino.ai/latest/notebooks/102-pytorch-onnx-to-openvino-with-output. HTML). Al pasar de PyTorch puro a modelos ONNX/OpenVINO, he visto un aumento de ~2x+ en el rendimiento.
- Para convertir modelos en una API implementable y escalable, consulte la biblioteca TorchServe.
- Para ver un excelente ejemplo y una justificación de por qué implementar un modelo de aprendizaje automático en el navegador (una forma de implementación perimetral) ofrece varios beneficios (sin retraso en la latencia de transferencia de red), consulte el artículo de Jo Kristian Bergum sobre Moving ML Inference from the Cloud hasta el borde.