00. Fundamentos de PyTorch¶
¿Qué es PyTorch?¶
PyTorch es un marco de aprendizaje automático y aprendizaje profundo de código abierto.
¿Para qué se puede utilizar PyTorch?¶
PyTorch le permite manipular y procesar datos y escribir algoritmos de aprendizaje automático utilizando código Python.
¿Quién usa PyTorch?¶
Muchas de las empresas de tecnología más grandes del mundo, como Meta (Facebook), Tesla y Microsoft, así como empresas de investigación de inteligencia artificial como OpenAI utiliza PyTorch para impulsar la investigación y llevar el aprendizaje automático a sus productos.
Por ejemplo, Andrej Karpathy (director de IA de Tesla) ha dado varias charlas (PyTorch DevCon 2019, [Tesla AI Day 2021](https://youtu.be/j0z4FweCy4M ?t=2904)) sobre cómo Tesla usa PyTorch para impulsar sus modelos de visión por computadora autónomos.
PyTorch también se utiliza en otras industrias, como la agricultura, para impulsar la visión por computadora en tractores.
¿Por qué utilizar PyTorch?¶
A los investigadores de aprendizaje automático les encanta usar PyTorch. Y a partir de febrero de 2022, PyTorch es el marco de aprendizaje profundo más utilizado en Papers With Code, un sitio web para realizar un seguimiento de los artículos de investigación sobre aprendizaje automático y los repositorios de código adjuntos a ellos.
PyTorch también ayuda a encargarse de muchas cosas, como la aceleración de GPU (hacer que su código se ejecute más rápido) detrás de escena.
Por lo tanto, puede concentrarse en manipular datos y escribir algoritmos y PyTorch se asegurará de que se ejecute rápidamente.
Y si empresas como Tesla y Meta (Facebook) lo utilizan para construir modelos que implementan para impulsar cientos de aplicaciones, conducir miles de automóviles y entregar contenido a miles de millones de personas, es evidente que también es capaz en el frente del desarrollo.
Qué vamos a cubrir en este módulo¶
Este curso se divide en diferentes secciones (cuadernos).
Cada cuaderno cubre ideas y conceptos importantes dentro de PyTorch.
Los cuadernos posteriores se basan en el conocimiento del anterior (la numeración comienza en 00, 01, 02 y continúa hasta donde termina).
Este cuaderno trata sobre el componente básico del aprendizaje automático y el aprendizaje profundo, el tensor.
Específicamente, cubriremos:
| Tema | Contenido |
|---|---|
| Introducción a los tensores | Los tensores son el componente básico de todo el aprendizaje automático y el aprendizaje profundo. |
| Creando tensores | Los tensores pueden representar casi cualquier tipo de datos (imágenes, palabras, tablas de números). |
| Obtener información de tensores | Si puedes poner información en un tensor, también querrás sacarla. |
| Manipulación de tensores | Los algoritmos de aprendizaje automático (como las redes neuronales) implican la manipulación de tensores de muchas formas diferentes, como sumar, multiplicar y combinar. |
| Tratando con formas tensoriales | Uno de los problemas más comunes en el aprendizaje automático es lidiar con desajustes de formas (intentar mezclar tensores con formas incorrectas con otros tensores). |
| Indexación de tensores | Si ha indexado en una lista de Python o una matriz NumPy, es muy similar con los tensores, excepto que pueden tener muchas más dimensiones. |
| Mezcla de tensores de PyTorch y NumPy | PyTorch juega con tensores (torch.Tensor), a NumPy le gustan las matrices ([np.ndarray](https://numpy.org /doc/stable/reference/generated/numpy.ndarray.html)) a veces querrás mezclarlos y combinarlos. |
| Reproducibilidad | El aprendizaje automático es muy experimental y dado que utiliza mucha aleatoriedad para funcionar, a veces querrás que esa aleatoriedad no sea tan aleatoria. |
| Ejecución de tensores en GPU | Las GPU (Unidades de procesamiento de gráficos) hacen que su código sea más rápido, PyTorch facilita la ejecución de su código en las GPU. |
¿Dónde puedes obtener ayuda?¶
Todos los materiales de este curso en vivo en GitHub.
Y si tiene problemas, también puede hacer una pregunta en la página de debates.
También están los foros de desarrolladores de PyTorch, un lugar muy útil para todo lo relacionado con PyTorch.
Importando PyTorch¶
Nota: Antes de ejecutar cualquier código de este cuaderno, debería haber seguido los pasos de configuración de PyTorch.
Sin embargo, si estás ejecutando Google Colab, todo debería funcionar (Google Colab viene con PyTorch y otras bibliotecas instaladas).
Comencemos importando PyTorch y verificando la versión que estamos usando.
import torch
torch.__version__
Maravilloso, parece que tenemos PyTorch 1.10.0+.
Esto significa que si está leyendo estos materiales, verá la mayor compatibilidad con PyTorch 1.10.0+; sin embargo, si su número de versión es mucho mayor, es posible que note algunas inconsistencias.
Y si tiene algún problema, publíquelo en el curso [página de debates de GitHub] (https://github.com/mrdbourke/pytorch-deep-learning/discussions).
Introducción a los tensores¶
Ahora que importamos PyTorch, es hora de aprender sobre los tensores.
Los tensores son el componente fundamental del aprendizaje automático.
Su trabajo es representar datos de forma numérica.
Por ejemplo, podría representar una imagen como un tensor con la forma [3, 224, 224] que significaría [color_channels, height, width], ya que en la imagen tiene 3 canales de color (rojo, verde, azul), una altura de 224 píxeles y una anchura de 224 píxeles.

En lenguaje tensorial (el lenguaje utilizado para describir tensores), el tensor tendría tres dimensiones, una para "color_channels", "altura" y "ancho".
Pero nos estamos adelantando.
Aprendamos más sobre los tensores codificándolos.
Creando tensores¶
A PyTorch le encantan los tensores. Tanto es así que hay una página de documentación completa dedicada a la clase torch.Tensor.
Su primera tarea es leer la documentación en torch.Tensor durante 10 minutos. Pero puedes llegar a eso más tarde.
Codifiquemos.
Lo primero que vamos a crear es un escalar.
Un escalar es un número único y en términos tensoriales es un tensor de dimensión cero.
Nota: Esa es una tendencia para este curso. Nos centraremos en escribir código específico. Pero a menudo establezco ejercicios que implican leer y familiarizarse con la documentación de PyTorch. Porque después de todo, una vez que hayas terminado este curso, sin duda querrás aprender más. Y la documentación está en algún lugar donde se encontrará con bastante frecuencia.
# Escalar
scalar = torch.tensor(7)
scalar
¿Ves cómo lo anterior imprimió tensor (7)?
Eso significa que aunque "escalar" es un número único, es del tipo "torch.Tensor".
Podemos verificar las dimensiones de un tensor usando el atributo ndim.
scalar.ndim
¿Qué pasaría si quisiéramos recuperar el número del tensor?
Como en, ¿convertirlo de torch.Tensor a un entero de Python?
Para hacerlo podemos usar el método item().
# Obtener el número de Python dentro de un tensor (solo funciona con tensores de un elemento)
scalar.item()
Bien, ahora veamos un vector.
Un vector es un tensor de una sola dimensión pero puede contener muchos números.
Por ejemplo, podría tener un vector [3, 2] para describir [dormitorios, baños] en su casa. O podría tener "[3, 2, 2]" para describir "[dormitorios, baños, aparcamientos]" en su casa.
La tendencia importante aquí es que un vector es flexible en lo que puede representar (lo mismo ocurre con los tensores).
# Vector
vector = torch.tensor([7, 7])
vector
Maravilloso, "vector" ahora contiene dos 7, mi número favorito.
¿Cuántas dimensiones crees que tendrá?
# Verifique el número de dimensiones del vector.
vector.ndim
Hmm, eso es extraño, "vector" contiene dos números pero solo tiene una dimensión.
Te contaré un truco.
Puede saber la cantidad de dimensiones que tiene un tensor en PyTorch por la cantidad de corchetes en el exterior ([) y solo necesita contar un lado.
¿Cuántos corchetes tiene "vector"?
Otro concepto importante para los tensores es su atributo de "forma". La forma te dice cómo están dispuestos los elementos dentro de ella.
Veamos la forma del "vector".
# Comprobar la forma del vector
vector.shape
Lo anterior devuelve torch.Size([2]) lo que significa que nuestro vector tiene la forma [2]. Esto se debe a los dos elementos que colocamos entre corchetes ([7, 7]).
Veamos ahora una matriz.
# Matriz
MATRIX = torch.tensor([[7, 8],
[9, 10]])
MATRIX
¡Guau! ¡Más números! Las matrices son tan flexibles como los vectores, excepto que tienen una dimensión extra.
# Comprobar número de dimensiones
MATRIX.ndim
MATRIX tiene dos dimensiones (¿contaste el número de corchetes en el exterior de un lado?).
¿Qué "forma" crees que tendrá?
MATRIX.shape
Obtenemos el resultado torch.Size([2, 2]) porque MATRIX tiene dos elementos de profundidad y dos elementos de ancho.
¿Qué tal si creamos un tensor?
# Tensor
TENSOR = torch.tensor([[[1, 2, 3],
[3, 6, 9],
[2, 4, 5]]])
TENSOR
¡Guau! Que bonito tensor.
Quiero enfatizar que los tensores pueden representar casi cualquier cosa.
El que acabamos de crear podrían ser las cifras de ventas de una tienda de carnes y mantequilla de almendras (dos de mis comidas favoritas).
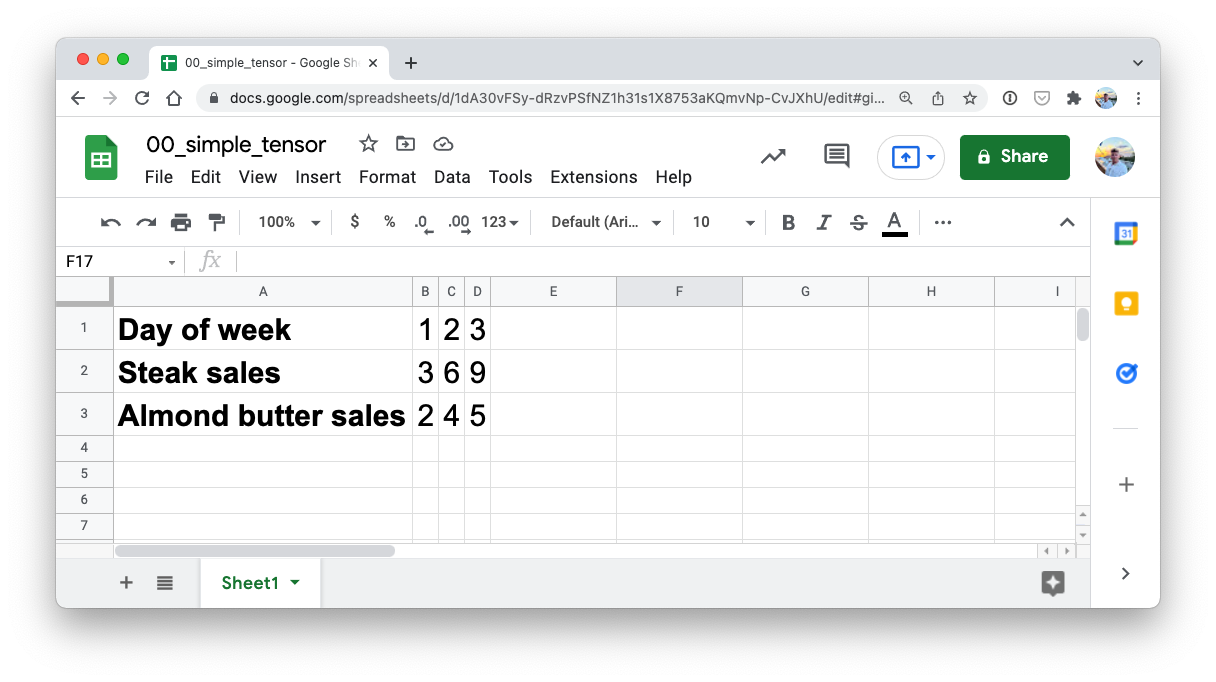
¿Cuántas dimensiones crees que tiene? (pista: utilice el truco de contar corchetes)
# Consultar número de dimensiones para TENSOR
TENSOR.ndim
¿Y qué pasa con su forma?
# Comprobar la forma del TENSOR
TENSOR.shape
Muy bien, genera torch.Size([1, 3, 3]).
Las dimensiones van de exterior a interior.
Eso significa que hay 1 dimensión de 3 por 3.

Nota: Es posible que hayas notado que uso letras minúsculas para
escalaryvectory letras mayúsculas paraMATRIXyTENSOR. Esto fue a propósito. En la práctica, a menudo verás escalares y vectores indicados con letras minúsculas como "y" o "a". Y matrices y tensores indicados con letras mayúsculas como "X" o "W".También puedes notar que los nombres matriz y tensor se usan indistintamente. Esto es común. Sin embargo, dado que en PyTorch a menudo se trata con
torch.Tensors (de ahí el nombre del tensor), la forma y las dimensiones de lo que hay dentro dictarán lo que realmente es.
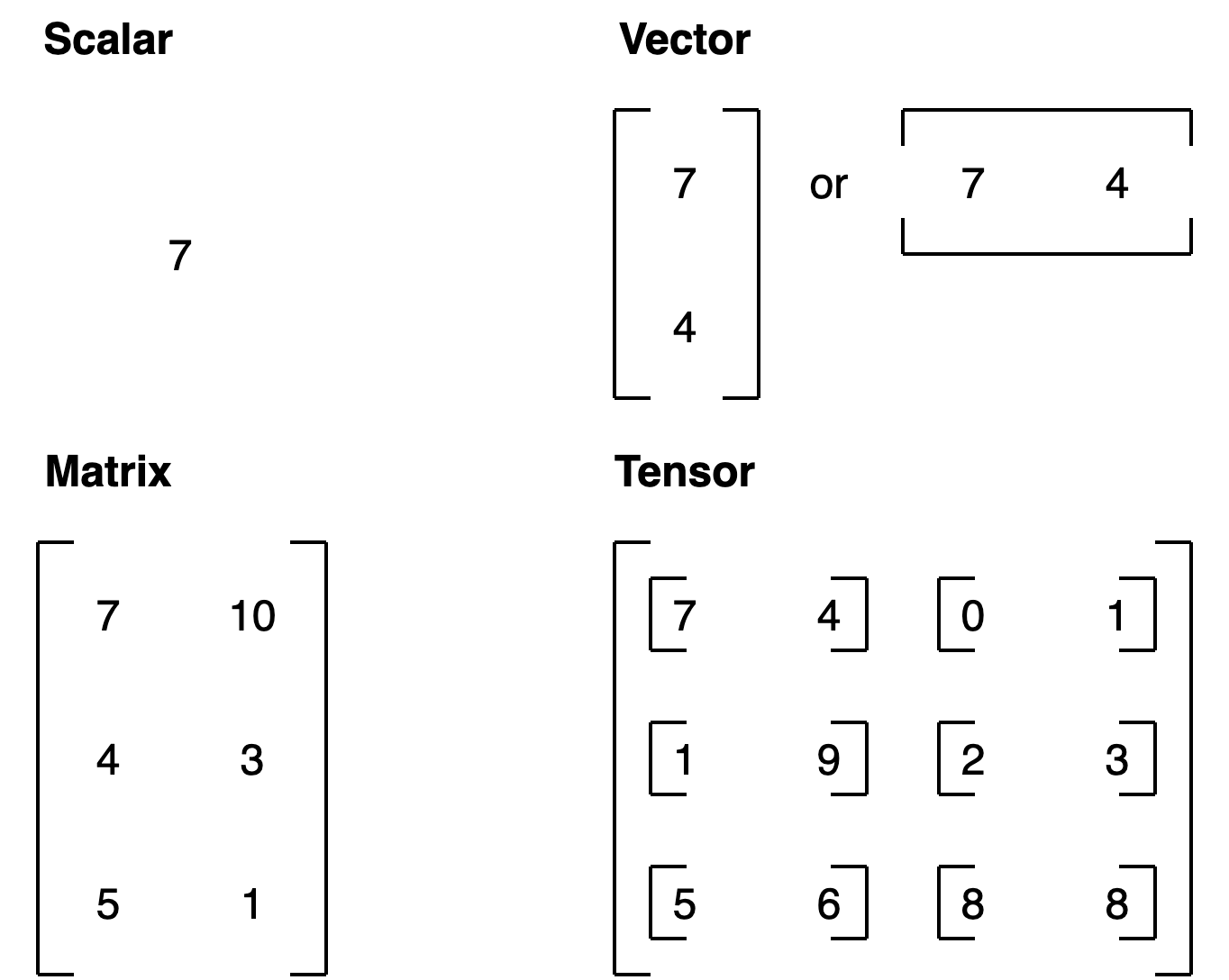
Resumamos.
| Nombre | ¿Qué es? | Número de dimensiones | Inferior o superior (normalmente/ejemplo) |
|---|---|---|---|
| escalar | un solo número | 0 | Inferior (a) |
| vector | un número con dirección (por ejemplo, velocidad del viento con dirección) pero también puede tener muchos otros números | 1 | Inferior (y) |
| matriz | una matriz bidimensional de números | 2 | Superior (Q) |
| tensor | una matriz de números n-dimensional | puede ser cualquier número, un tensor de dimensión 0 es un escalar, un tensor de dimensión 1 es un vector | Superior (X) |
Tensores aleatorios¶
Hemos establecido que los tensores representan algún tipo de datos.
Y los modelos de aprendizaje automático, como las redes neuronales, manipulan y buscan patrones dentro de los tensores.
Pero al construir modelos de aprendizaje automático con PyTorch, es raro que crees tensores a mano (como lo que estamos haciendo nosotros).
En cambio, un modelo de aprendizaje automático a menudo comienza con grandes tensores de números aleatorios y ajusta estos números aleatorios a medida que trabaja con datos para representarlos mejor.
En esencia:
Comience con números aleatorios -> mire los datos -> actualice los números aleatorios -> mire los datos -> actualice los números aleatorios...
Como científico de datos, puede definir cómo se inicia el modelo de aprendizaje automático (inicialización), analiza los datos (representación) y actualiza (optimización) sus números aleatorios.
Nos pondremos manos a la obra con estos pasos más adelante.
Por ahora, veamos cómo crear un tensor de números aleatorios.
Podemos hacerlo usando torch.rand() y pasando el parámetro size.
# Crea un tensor aleatorio de tamaño (3, 4)
random_tensor = torch.rand(size=(3, 4))
random_tensor, random_tensor.dtype
La flexibilidad de torch.rand() es que podemos ajustar el tamaño para que sea lo que queramos.
Por ejemplo, supongamos que desea un tensor aleatorio con la forma de imagen común de [224, 224, 3] ([alto, ancho, color_channels]).
# Crea un tensor aleatorio de tamaño (224, 224, 3)
random_image_size_tensor = torch.rand(size=(224, 224, 3))
random_image_size_tensor.shape, random_image_size_tensor.ndim
Ceros y unos¶
A veces simplemente querrás llenar los tensores con ceros o unos.
Esto sucede mucho con el enmascaramiento (como enmascarar algunos de los valores en un tensor con ceros para que el modelo sepa que no debe aprenderlos).
Creemos un tensor lleno de ceros con torch.zeros()
Nuevamente entra en juego el parámetro "tamaño".
# Crea un tensor de todos ceros.
zeros = torch.zeros(size=(3, 4))
zeros, zeros.dtype
Podemos hacer lo mismo para crear un tensor de todos unos excepto usar torch.ones() en su lugar.
# Crea un tensor de todos unos.
ones = torch.ones(size=(3, 4))
ones, ones.dtype
Creando un rango y tensores como¶
A veces es posible que desees un rango de números, como del 1 al 10 o del 0 al 100.
Puede utilizar torch.arange(inicio, fin, paso) para hacerlo.
Dónde:
start= inicio del rango (por ejemplo, 0)end= fin del rango (por ejemplo, 10)paso= cuántos pasos hay entre cada valor (por ejemplo, 1)
Nota: En Python, puedes usar
range()para crear un rango. Sin embargo, en PyTorch,torch.range()está en desuso y puede mostrar un error en el futuro.
# Utilice torch.arange(), torch.range() está en desuso
zero_to_ten_deprecated = torch.range(0, 10) # Note: this may return an error in the future
# Crea un rango de valores del 0 al 10
zero_to_ten = torch.arange(start=0, end=10, step=1)
zero_to_ten
A veces es posible que desees un tensor de cierto tipo con la misma forma que otro tensor.
Por ejemplo, un tensor de todos ceros con la misma forma que un tensor anterior.
Para hacerlo, puede utilizar torch.zeros_like(input) o [torch.ones_like(input)](https ://pytorch.org/docs/1.9.1/generated/torch.ones_like.html) que devuelven un tensor lleno de ceros o unos con la misma forma que la "entrada", respectivamente.
# También puede crear un tensor de ceros similar a otro tensor.
ten_zeros = torch.zeros_like(input=zero_to_ten) # will have same shape
ten_zeros
Tipos de datos tensoriales¶
Hay muchos [tipos de datos tensoriales disponibles en PyTorch] diferentes (https://pytorch.org/docs/stable/tensors.html#data-types).
Algunos son específicos para CPU y otros son mejores para GPU.
Saber cuál es cuál puede llevar algún tiempo.
Generalmente, si ve torch.cuda en cualquier lugar, el tensor se está usando para la GPU (ya que las GPU de Nvidia usan un conjunto de herramientas informáticas llamado CUDA).
El tipo más común (y generalmente el predeterminado) es torch.float32 o torch.float.
Esto se conoce como "coma flotante de 32 bits".
Pero también hay punto flotante de 16 bits (torch.float16 o torch.half) y punto flotante de 64 bits (torch.float64 o torch.double).
Y para confundir aún más las cosas, también hay números enteros de 8, 16, 32 y 64 bits.
¡Y mucho más!
Nota: Un número entero es un número plano y redondo como "7", mientras que un flotante tiene un decimal "7.0".
La razón de todo esto tiene que ver con la precisión en la informática.
La precisión es la cantidad de detalles utilizados para describir un número.
Cuanto mayor sea el valor de precisión (8, 16, 32), más detalles y, por tanto, más datos se utilizarán para expresar un número.
Esto es importante en el aprendizaje profundo y la computación numérica porque al realizar tantas operaciones, cuanto más detalles tenga para calcular, más computación tendrá que usar.
Por lo tanto, los tipos de datos de menor precisión generalmente son más rápidos de calcular, pero sacrifican algo de rendimiento en métricas de evaluación como la precisión (más rápido de calcular pero menos preciso).
Recursos:
- Consulte la [documentación de PyTorch para obtener una lista de todos los tipos de datos tensoriales disponibles] (https://pytorch.org/docs/stable/tensors.html#data-types).
- Lea la [página de Wikipedia para obtener una descripción general de qué es la precisión en informática] (https://en.wikipedia.org/wiki/Precision_(computer_science)).
Veamos cómo crear algunos tensores con tipos de datos específicos. Podemos hacerlo usando el parámetro dtype.
# El tipo de datos predeterminado para tensores es float32
float_32_tensor = torch.tensor([3.0, 6.0, 9.0],
dtype=None, # defaults to None, which is torch.float32 or whatever datatype is passed
device=None, # defaults to None, which uses the default tensor type
requires_grad=False) # if True, operations performed on the tensor are recorded
float_32_tensor.shape, float_32_tensor.dtype, float_32_tensor.device
Aparte de los problemas de forma (las formas de los tensores no coinciden), dos de los otros problemas más comunes que encontrará en PyTorch son problemas de tipo de datos y de dispositivo.
Por ejemplo, uno de los tensores es torch.float32 y el otro es torch.float16 (a PyTorch a menudo le gusta que los tensores tengan el mismo formato).
O uno de sus tensores está en la CPU y el otro en la GPU (a PyTorch le gusta que los cálculos entre tensores se realicen en el mismo dispositivo).
Veremos más sobre este dispositivo más adelante.
Por ahora creemos un tensor con dtype=torch.float16.
float_16_tensor = torch.tensor([3.0, 6.0, 9.0],
dtype=torch.float16) # torch.half would also work
float_16_tensor.dtype
Obtener información de tensores¶
Una vez que haya creado tensores (o alguien más o un módulo de PyTorch los haya creado para usted), es posible que desee obtener información de ellos.
Ya los hemos visto antes, pero tres de los atributos más comunes que querrás conocer sobre los tensores son:
forma- ¿qué forma tiene el tensor? (algunas operaciones requieren reglas de forma específicas)dtype: ¿en qué tipo de datos se almacenan los elementos dentro del tensor?dispositivo: ¿en qué dispositivo está almacenado el tensor? (generalmente GPU o CPU)
Creemos un tensor aleatorio y descubramos detalles al respecto.
# Crear un tensor
some_tensor = torch.rand(3, 4)
# Conoce detalles al respecto
print(some_tensor)
print(f"Shape of tensor: {some_tensor.shape}")
print(f"Datatype of tensor: {some_tensor.dtype}")
print(f"Device tensor is stored on: {some_tensor.device}") # will default to CPU
Nota: Cuando tienes problemas en PyTorch, muy a menudo tiene que ver con uno de los tres atributos anteriores. Entonces, cuando aparezcan los mensajes de error, cante una pequeña canción llamada "qué, qué, dónde":
- "¿Qué forma tienen mis tensores? ¿Qué tipo de datos son y dónde se almacenan? ¿Qué forma, qué tipo de datos, dónde, dónde, dónde"
Manipulación de tensores (operaciones tensoriales)¶
En el aprendizaje profundo, los datos (imágenes, texto, vídeo, audio, estructuras de proteínas, etc.) se representan como tensores.
Un modelo aprende investigando esos tensores y realizando una serie de operaciones (podrían ser más de 1.000.000 de operaciones) en tensores para crear una representación de los patrones en los datos de entrada.
Estas operaciones suelen ser un baile maravilloso entre:
- Suma
- Resta
- Multiplicación (por elementos)
- División
- Multiplicación de matrices
Y eso es. Seguro que hay algunos más aquí y allá, pero estos son los componentes básicos de las redes neuronales.
Al apilar estos bloques de construcción de la manera correcta, puedes crear las redes neuronales más sofisticadas (¡como Lego!).
Operaciones básicas¶
Comencemos con algunas de las operaciones fundamentales, suma (+), resta (-), multiplicación (*).
Funcionan tal como crees que lo harían.
# Crea un tensor de valores y agrégale un número.
tensor = torch.tensor([1, 2, 3])
tensor + 10
# Multiplicalo por 10
tensor * 10
Observe cómo los valores del tensor anteriores no terminaron siendo "tensor ([110, 120, 130])", esto se debe a que los valores dentro del tensor no cambian a menos que sean reasignados.
# Los tensores no cambian a menos que se reasignen
tensor
Restemos un número y esta vez reasignaremos la variable tensor.
# Restar y reasignar
tensor = tensor - 10
tensor
# Agregar y reasignar
tensor = tensor + 10
tensor
PyTorch también tiene un montón de funciones integradas como torch.mul() (abreviatura de multiplicación) y torch.add() para realizar operaciones básicas.
# También puede utilizar funciones de antorcha.
torch.multiply(tensor, 10)
# El tensor original aún no ha cambiado.
tensor
Sin embargo, es más común usar símbolos de operador como * en lugar de torch.mul()
# Multiplicación por elementos (cada elemento multiplica su equivalente, índice 0->0, 1->1, 2->2)
print(tensor, "*", tensor)
print("Equals:", tensor * tensor)
Multiplicación de matrices (es todo lo que necesitas)¶
Una de las operaciones más comunes en los algoritmos de aprendizaje automático y aprendizaje profundo (como las redes neuronales) es la [multiplicación de matrices] (https://www.mathsisfun.com/algebra/matrix-multiplying.html).
PyTorch implementa la funcionalidad de multiplicación de matrices en el método torch.matmul().
Las dos reglas principales que hay que recordar para la multiplicación de matrices son:
- Las dimensiones interiores deben coincidir:
(3, 2) @ (3, 2)no funcionará(2, 3) @ (3, 2)funcionará(3, 2) @ (2, 3)funcionará
- La matriz resultante tiene la forma de dimensiones exteriores:
(2, 3) @ (3, 2)->(2, 2)(3, 2) @ (2, 3)->(3, 3)
Nota: "
@" en Python es el símbolo para la multiplicación de matrices.
Recurso: Puede ver todas las reglas para la multiplicación de matrices usando
torch.matmul()[en la documentación de PyTorch](https://pytorch.org/docs/stable/generated/torch.matmul. HTML).
Creemos un tensor y realicemos una multiplicación de elementos y una multiplicación de matrices en él.
import torch
tensor = torch.tensor([1, 2, 3])
tensor.shape
La diferencia entre la multiplicación por elementos y la multiplicación de matrices es la suma de valores.
Para nuestra variable tensor con valores [1, 2, 3]:
| Operación | Cálculo | Código |
|---|---|---|
| Multiplicación por elementos | [1*1, 2*2, 3*3] = [1, 4, 9] |
tensor * tensor |
| Multiplicación de matrices | [1*1 + 2*2 + 3*3] = [14] |
tensor.matmul(tensor) |
# Multiplicación de matrices por elementos
tensor * tensor
# Multiplicación de matrices
torch.matmul(tensor, tensor)
# También se puede utilizar el símbolo "@" para la multiplicación de matrices, aunque no se recomienda.
tensor @ tensor
Puedes hacer la multiplicación de matrices a mano, pero no es recomendable.
El método incorporado torch.matmul() es más rápido.
%%time
# Multiplicación de matrices a mano.
# (evite a toda costa realizar operaciones con bucles for, son computacionalmente costosos)
value = 0
for i in range(len(tensor)):
value += tensor[i] * tensor[i]
value
%%time
torch.matmul(tensor, tensor)
Uno de los errores más comunes en el aprendizaje profundo (errores de forma)¶
Debido a que gran parte del aprendizaje profundo consiste en multiplicar y realizar operaciones en matrices, y las matrices tienen una regla estricta sobre qué formas y tamaños se pueden combinar, uno de los errores más comunes con los que se encontrará en el aprendizaje profundo son las discrepancias de formas.
# Las formas deben estar en la forma correcta.
tensor_A = torch.tensor([[1, 2],
[3, 4],
[5, 6]], dtype=torch.float32)
tensor_B = torch.tensor([[7, 10],
[8, 11],
[9, 12]], dtype=torch.float32)
torch.matmul(tensor_A, tensor_B) # (this will error)
Podemos hacer que la multiplicación de matrices funcione entre tensor_A y tensor_B haciendo que sus dimensiones internas coincidan.
Una de las formas de hacer esto es con una transposición (cambiar las dimensiones de un tensor determinado).
Puede realizar transposiciones en PyTorch usando:
torch.transpose(input, dim0, dim1)- dondeinputes el tensor que se desea transponer ydim0ydim1son las dimensiones que se van a intercambiar.tensor.T- dondetensores el tensor que se desea transponer.
Probemos esto último.
# Ver tensor_A y tensor_B
print(tensor_A)
print(tensor_B)
# Ver tensor_A y tensor_B.T
print(tensor_A)
print(tensor_B.T)
# La operación funciona cuando se transpone tensor_B
print(f"Original shapes: tensor_A = {tensor_A.shape}, tensor_B = {tensor_B.shape}\n")
print(f"New shapes: tensor_A = {tensor_A.shape} (same as above), tensor_B.T = {tensor_B.T.shape}\n")
print(f"Multiplying: {tensor_A.shape} * {tensor_B.T.shape} <- inner dimensions match\n")
print("Output:\n")
output = torch.matmul(tensor_A, tensor_B.T)
print(output)
print(f"\nOutput shape: {output.shape}")
También puede usar torch.mm() que es una abreviatura de torch.matmul().
# torch.mm es un atajo para matmul
torch.mm(tensor_A, tensor_B.T)
Sin la transpuesta, las reglas de multiplicación de matrices no se cumplen y obtenemos un error como el anterior.
¿Qué tal una imagen?

Puede crear sus propios elementos visuales de multiplicación de matrices como este en http://matrixmultiplication.xyz/.
Nota: Una multiplicación de matrices como esta también se conoce como producto escalar de dos matrices .
Las redes neuronales están llenas de multiplicaciones de matrices y productos escalares.
El módulo torch.nn.Linear() (lo veremos en acción más adelante), También conocida como capa de avance o capa completamente conectada, implementa una multiplicación de matrices entre una entrada "x" y una matriz de pesos "A".
$$ y = x\cdot{A^T} + b $$
Dónde:
xes la entrada a la capa (el aprendizaje profundo es una pila de capas comotorch.nn.Linear()y otras una encima de la otra).Aes la matriz de pesos creada por la capa, esto comienza como números aleatorios que se ajustan a medida que una red neuronal aprende a representar mejor los patrones en los datos (observe la "T", eso se debe a que la matriz de pesos se transpone ).- Nota: Es posible que también veas a menudo "W" u otra letra como "X" utilizada para mostrar la matriz de pesos.
bes el término de sesgo utilizado para compensar ligeramente los pesos y las entradas.yes la salida (una manipulación de la entrada con la esperanza de descubrir patrones en ella).
Esta es una función lineal (es posible que hayas visto algo como $y = mx+b$ en la escuela secundaria o en cualquier otro lugar) y se puede usar para dibujar una línea recta.
Juguemos con una capa lineal.
Intente cambiar los valores de in_features y out_features a continuación y vea qué sucede.
¿Notas algo que ver con las formas?
# Dado que la capa lineal comienza con una matriz de pesos aleatorios, hagámosla reproducible (más sobre esto más adelante)
torch.manual_seed(42)
# Esto usa la multiplicación de matrices.
linear = torch.nn.Linear(in_features=2, # in_features = matches inner dimension of input
out_features=6) # out_features = describes outer value
x = tensor_A
output = linear(x)
print(f"Input shape: {x.shape}\n")
print(f"Output:\n{output}\n\nOutput shape: {output.shape}")
Pregunta: ¿Qué sucede si cambia
in_featuresdel 2 al 3 anterior? ¿Tiene error? ¿Cómo podría cambiar la forma de la entrada (x) para adaptarse al error? Pista: ¿qué tuvimos que hacer con eltensor_Banterior?
Si nunca lo has hecho antes, la multiplicación de matrices puede ser un tema confuso al principio.
Pero después de haber jugado con él unas cuantas veces e incluso haber abierto algunas redes neuronales, notarás que está en todas partes.
Recuerde, la multiplicación de matrices es todo lo que necesita.
Cuando empieces a profundizar en las capas de la red neuronal y a construir la tuya propia, encontrarás multiplicaciones de matrices por todas partes. Fuente: https://marksaroufim.substack.com/p/working-class-deep-learner
Encontrar el mínimo, máximo, media, suma, etc. (agregación)¶
Ahora que hemos visto algunas formas de manipular tensores, veamos algunas formas de agregarlos (pasar de más valores a menos valores).
Primero crearemos un tensor y luego encontraremos su máximo, mínimo, media y suma.
# Crear un tensor
x = torch.arange(0, 100, 10)
x
Ahora realicemos alguna agregación.
print(f"Minimum: {x.min()}")
print(f"Maximum: {x.max()}")
# print(f"Mean: {x.mean()}") # esto generará un error
print(f"Mean: {x.type(torch.float32).mean()}") # won't work without float datatype
print(f"Sum: {x.sum()}")
Nota: Es posible que algunos métodos como
torch.mean()requieran que los tensores estén entorch.float32(el más común) u otro tipo de datos específico; de lo contrario, la operación fallará.
También puedes hacer lo mismo que arriba con los métodos "antorcha".
torch.max(x), torch.min(x), torch.mean(x.type(torch.float32)), torch.sum(x)
Posicional mín/máx¶
También puede encontrar el índice de un tensor donde ocurre el máximo o el mínimo con torch.argmax() y torch .argmin() respectivamente.
Esto es útil en caso de que solo desee la posición donde está el valor más alto (o más bajo) y no el valor real en sí (veremos esto en una sección posterior cuando utilice la [función de activación softmax](https://pytorch.org /docs/stable/generated/torch.nn.Softmax.html)).
# Crear un tensor
tensor = torch.arange(10, 100, 10)
print(f"Tensor: {tensor}")
# Devuelve el índice de valores máximo y mínimo.
print(f"Index where max value occurs: {tensor.argmax()}")
print(f"Index where min value occurs: {tensor.argmin()}")
Cambiar el tipo de datos del tensor¶
Como se mencionó, un problema común con las operaciones de aprendizaje profundo es tener tensores en diferentes tipos de datos.
Si un tensor está en torch.float64 y otro está en torch.float32, es posible que se encuentre con algunos errores.
Pero hay una solución.
Puede cambiar los tipos de datos de los tensores usando torch.Tensor.type(dtype=None) donde el dtype El parámetro es el tipo de datos que desea utilizar.
Primero crearemos un tensor y verificaremos su tipo de datos (el valor predeterminado es torch.float32).
# Crea un tensor y verifica su tipo de datos.
tensor = torch.arange(10., 100., 10.)
tensor.dtype
Ahora crearemos otro tensor igual que antes pero cambiaremos su tipo de datos a torch.float16.
# Crea un tensor float16
tensor_float16 = tensor.type(torch.float16)
tensor_float16
Y podemos hacer algo similar para crear un tensor torch.int8.
# Crear un tensor int8
tensor_int8 = tensor.type(torch.int8)
tensor_int8
Nota: Para empezar, diferentes tipos de datos pueden resultar confusos. Pero piénselo así: cuanto menor es el número (por ejemplo, 32, 16, 8), menos precisa es la computadora que almacena el valor. Y con una menor cantidad de almacenamiento, esto generalmente resulta en un cálculo más rápido y un modelo general más pequeño. Las redes neuronales móviles a menudo operan con números enteros de 8 bits, más pequeños y más rápidos de ejecutar, pero menos precisos que sus contrapartes float32. Para obtener más información sobre esto, leí sobre [precisión en informática] (https://en.wikipedia.org/wiki/Precision_(computer_science)).
Ejercicio: Hasta ahora hemos cubierto algunos métodos tensoriales, pero hay muchos más en la documentación
torch.Tensor, recomendaría pasar 10 minutos desplazándose y mirando cualquiera que le llame la atención. Haga clic en ellos y luego escríbalos usted mismo en código para ver qué sucede.
Remodelar, apilar, apretar y descomprimir¶
Muchas veces querrás remodelar o cambiar las dimensiones de tus tensores sin cambiar realmente los valores dentro de ellos.
Para hacerlo, algunos métodos populares son:
| Método | Descripción de una línea |
|---|---|
torch.reshape(entrada, forma) |
Cambia la forma de input a shape (si es compatible), también puede usar torch.Tensor.reshape(). |
Tensor.view(forma) |
Devuelve una vista del tensor original en una "forma" diferente pero comparte los mismos datos que el tensor original. |
torch.stack(tensores, dim=0) |
Concatena una secuencia de "tensores" a lo largo de una nueva dimensión ("dim"), todos los "tensores" deben tener el mismo tamaño. |
torch.squeeze(entrada) |
Aprieta input para eliminar todas las dimensiones con valor 1. |
torch.unsqueeze(entrada, tenue) |
Devuelve "entrada" con un valor de dimensión de "1" agregado en "tenue". |
torch.permute(entrada, atenuaciones) |
Devuelve una vista de la "entrada" original con sus dimensiones permutadas (reorganizadas) a "atenuadas". |
¿Por qué hacer algo de esto?
Porque los modelos de aprendizaje profundo (redes neuronales) tratan de manipular tensores de alguna manera. Y debido a las reglas de la multiplicación de matrices, si las formas no coinciden, se producirán errores. Estos métodos le ayudan a asegurarse de que los elementos correctos de sus tensores se mezclen con los elementos correctos de otros tensores.
Probémoslos.
Primero, crearemos un tensor.
# Crear un tensor
import torch
x = torch.arange(1., 8.)
x, x.shape
Ahora agreguemos una dimensión adicional con torch.reshape().
# Añade una dimensión extra
x_reshaped = x.reshape(1, 7)
x_reshaped, x_reshaped.shape
También podemos cambiar la vista con torch.view().
# Cambiar vista (mantiene los mismos datos que el original pero cambia la vista)
# Ver más: https://stackoverflow.com/a/54507446/7900723
z = x.view(1, 7)
z, z.shape
Sin embargo, recuerde que cambiar la vista de un tensor con torch.view() en realidad solo crea una nueva vista del mismo tensor.
Entonces, cambiar la vista también cambia el tensor original.
# Cambiar z cambia x
z[:, 0] = 5
z, x
Si quisiéramos apilar nuestro nuevo tensor encima de sí mismo cinco veces, podríamos hacerlo con torch.stack().
# Apilar tensores uno encima del otro
x_stacked = torch.stack([x, x, x, x], dim=0) # try changing dim to dim=1 and see what happens
x_stacked
¿Qué tal eliminar todas las dimensiones individuales de un tensor?
Para hacerlo, puedes usar torch.squeeze() (recuerdo esto como apretar el tensor para que solo tenga dimensiones superiores a 1).
print(f"Previous tensor: {x_reshaped}")
print(f"Previous shape: {x_reshaped.shape}")
# Eliminar dimensión adicional de x_reshaped
x_squeezed = x_reshaped.squeeze()
print(f"\nNew tensor: {x_squeezed}")
print(f"New shape: {x_squeezed.shape}")
Y para hacer lo contrario de torch.squeeze() puedes usar torch.unsqueeze() para agregar un valor de dimensión de 1 en un índice específico.
print(f"Previous tensor: {x_squeezed}")
print(f"Previous shape: {x_squeezed.shape}")
# # Añade una dimensión extra con unsqueeze
x_unsqueezed = x_squeezed.unsqueeze(dim=0)
print(f"\nNew tensor: {x_unsqueezed}")
print(f"New shape: {x_unsqueezed.shape}")
También puede reorganizar el orden de los valores de los ejes con torch.permute(input, dims), donde la input se convierte en una vista con nuevas dims.
# Crear tensor con forma específica.
x_original = torch.rand(size=(224, 224, 3))
# Permutar el tensor original para reorganizar el orden de los ejes.
x_permuted = x_original.permute(2, 0, 1) # shifts axis 0->1, 1->2, 2->0
print(f"Previous shape: {x_original.shape}")
print(f"New shape: {x_permuted.shape}")
Nota: Debido a que la permutación devuelve una vista (comparte los mismos datos que el original), los valores en el tensor permutado serán los mismos que los del tensor original y si cambia los valores en la vista, también cambiar los valores del original.
Indexación (seleccionando datos de tensores)¶
A veces querrás seleccionar datos específicos de los tensores (por ejemplo, solo la primera columna o la segunda fila).
Para hacerlo, puede utilizar la indexación.
Si alguna vez ha indexado en listas de Python o matrices NumPy, la indexación en PyTorch con tensores es muy similar.
# Crear un tensor
import torch
x = torch.arange(1, 10).reshape(1, 3, 3)
x, x.shape
Los valores de indexación van a la dimensión exterior -> dimensión interior (consulte los corchetes).
# Indexemos paréntesis por paréntesis
print(f"First square bracket:\n{x[0]}")
print(f"Second square bracket: {x[0][0]}")
print(f"Third square bracket: {x[0][0][0]}")
También puede usar : para especificar "todos los valores en esta dimensión" y luego usar una coma (,) para agregar otra dimensión.
# Obtenga todos los valores de la dimensión 0 y el índice 0 de la dimensión 1
x[:, 0]
# Obtenga todos los valores de la 0.ª y la 1.ª dimensión, pero solo el índice 1 de la 2.ª dimensión
x[:, :, 1]
# Obtenga todos los valores de la dimensión 0 pero solo el valor del índice 1 de la primera y segunda dimensión
x[:, 1, 1]
# Obtenga el índice 0 de la 0.ª y 1.ª dimensión y todos los valores de la 2.ª dimensión
x[0, 0, :] # same as x[0][0]
Para empezar, la indexación puede resultar bastante confusa, especialmente con tensores más grandes (todavía tengo que intentar indexar varias veces para hacerlo bien). Pero con un poco de práctica y siguiendo el lema del explorador de datos (visualizar, visualizar, visualizar), empezarás a cogerle el tranquillo.
Tensores de PyTorch y NumPy¶
Dado que NumPy es una biblioteca de computación numérica popular de Python, PyTorch tiene una funcionalidad para interactuar bien con ella.
Los dos métodos principales que querrás usar para NumPy a PyTorch (y viceversa) son:
torch.from_numpy(ndarray)- Matriz NumPy -> tensor de PyTorch.torch.Tensor.numpy()- Tensor de PyTorch -> Matriz NumPy.
Probémoslos.
# matriz NumPy a tensor
import torch
import numpy as np
array = np.arange(1.0, 8.0)
tensor = torch.from_numpy(array)
array, tensor
Nota: De forma predeterminada, las matrices NumPy se crean con el tipo de datos
float64y si lo convierte a un tensor de PyTorch, mantendrá el mismo tipo de datos (como arriba).Sin embargo, muchos cálculos de PyTorch utilizan de forma predeterminada
float32.Entonces, si desea convertir su matriz NumPy (float64) -> tensor PyTorch (float64) -> tensor PyTorch (float32), puede usar
tensor = torch.from_numpy(array).type(torch.float32).
Debido a que reasignamos el "tensor" arriba, si cambia el tensor, la matriz permanece igual.
# Cambia la matriz, mantén el tensor.
array = array + 1
array, tensor
Y si desea pasar del tensor de PyTorch a la matriz NumPy, puede llamar a tensor.numpy().
# Tensor a matriz NumPy
tensor = torch.ones(7) # create a tensor of ones with dtype=float32
numpy_tensor = tensor.numpy() # will be dtype=float32 unless changed
tensor, numpy_tensor
Y se aplica la misma regla anterior, si cambia el tensor original, el nuevo numpy_tensor permanece igual.
# Cambia el tensor, mantén la matriz igual
tensor = tensor + 1
tensor, numpy_tensor
Reproducibilidad (tratar de sacar lo aleatorio de lo aleatorio)¶
A medida que aprenda más sobre las redes neuronales y el aprendizaje automático, comenzará a descubrir en qué medida influye la aleatoriedad.
Bueno, pseudoaleatoriedad, eso es. Porque después de todo, tal como están diseñadas, una computadora es fundamentalmente determinista (cada paso es predecible), por lo que la aleatoriedad que crean es aleatoriedad simulada (aunque también hay debate sobre esto, pero como no soy un científico informático, no Te dejaremos descubrir más tú mismo).
Entonces, ¿cómo se relaciona esto con las redes neuronales y el aprendizaje profundo?
Hemos discutido que las redes neuronales comienzan con números aleatorios para describir patrones en los datos (estos números son descripciones deficientes) y tratamos de mejorar esos números aleatorios usando operaciones tensoriales (y algunas otras cosas que aún no hemos discutido) para describir mejor los patrones en datos.
En breve:
comience con números aleatorios -> operaciones tensoriales -> intente hacerlo mejor (una y otra vez)
Aunque la aleatoriedad es agradable y poderosa, a veces te gustaría que hubiera un poco menos de aleatoriedad.
¿Por qué?
Para que pueda realizar experimentos repetibles.
Por ejemplo, crea un algoritmo capaz de lograr un rendimiento X.
Y luego tu amigo lo prueba para comprobar que no estás loco.
¿Cómo pudieron hacer tal cosa?
Ahí es donde entra en juego la reproducibilidad.
En otras palabras, ¿puedes obtener los mismos resultados (o muy similares) en tu computadora ejecutando el mismo código que yo obtengo en la mía?
Veamos un breve ejemplo de reproducibilidad en PyTorch.
Comenzaremos creando dos tensores aleatorios, ya que son aleatorios, uno esperaría que fueran diferentes, ¿verdad?
import torch
# Crea dos tensores aleatorios
random_tensor_A = torch.rand(3, 4)
random_tensor_B = torch.rand(3, 4)
print(f"Tensor A:\n{random_tensor_A}\n")
print(f"Tensor B:\n{random_tensor_B}\n")
print(f"Does Tensor A equal Tensor B? (anywhere)")
random_tensor_A == random_tensor_B
Tal como era de esperar, los tensores salen con valores diferentes.
Pero, ¿qué pasaría si quisieras crear dos tensores aleatorios con los mismos valores?
Como en, los tensores aún contendrían valores aleatorios pero serían del mismo tipo.
Ahí es donde entra torch.manual_seed(seed), donde seed es un número entero (como 42 pero podría ser cualquier cosa) que le dé sabor a la aleatoriedad.
Probémoslo creando algunos tensores aleatorios más con sabor.
import torch
import random
# # Establecer la semilla aleatoria
RANDOM_SEED=42 # try changing this to different values and see what happens to the numbers below
torch.manual_seed(seed=RANDOM_SEED)
random_tensor_C = torch.rand(3, 4)
# Tienes que restablecer la semilla cada vez que se llama a un nuevo rand()
# Sin esto, tensor_D sería diferente a tensor_C
torch.random.manual_seed(seed=RANDOM_SEED) # try commenting this line out and seeing what happens
random_tensor_D = torch.rand(3, 4)
print(f"Tensor C:\n{random_tensor_C}\n")
print(f"Tensor D:\n{random_tensor_D}\n")
print(f"Does Tensor C equal Tensor D? (anywhere)")
random_tensor_C == random_tensor_D
¡Lindo!
Parece que la semilla funcionó.
Recurso: Lo que acabamos de cubrir solo roza la superficie de la reproducibilidad en PyTorch. Para obtener más información sobre la reproducibilidad en general y las semillas aleatorias, consultaría:
- La documentación de reproducibilidad de PyTorch (un buen ejercicio sería leer esto durante 10 minutos e incluso si no lo entiendes ahora, ser consciente de ello es importante).
- La página de semillas aleatorias de Wikipedia (esto brindará una buena descripción general de las semillas aleatorias y la pseudoaleatoriedad en general).
Ejecutar tensores en GPU (y realizar cálculos más rápidos)¶
Los algoritmos de aprendizaje profundo requieren muchas operaciones numéricas.
Y, de forma predeterminada, estas operaciones suelen realizarse en una CPU (unidad de procesamiento de computadora).
Sin embargo, existe otra pieza común de hardware llamada GPU (unidad de procesamiento de gráficos), que suele ser mucho más rápida a la hora de realizar los tipos específicos de operaciones que necesitan las redes neuronales (multiplicaciones de matrices) que las CPU.
Es posible que su computadora tenga uno.
Si es así, deberías intentar usarlo siempre que puedas para entrenar redes neuronales porque es probable que acelere drásticamente el tiempo de entrenamiento.
Hay algunas formas de obtener acceso primero a una GPU y, en segundo lugar, hacer que PyTorch use la GPU.
Nota: Cuando hago referencia a "GPU" a lo largo de este curso, me refiero a una GPU Nvidia con CUDA habilitada (CUDA es una plataforma informática y API que ayuda a permitir que las GPU se utilicen para computación de propósito general y no solo para gráficos) a menos que se especifique lo contrario.
1. Obtener una GPU¶
Quizás ya sepas lo que pasa cuando digo GPU. Pero si no, hay algunas formas de acceder a uno.
| Método | Dificultad de configuración | Ventajas | Desventajas | Cómo configurar |
|---|---|---|---|---|
| Colaboración de Google | Fácil | De uso gratuito, casi no requiere configuración, puede compartir el trabajo con otras personas tan fácilmente como un enlace | No guarda sus salidas de datos, cálculo limitado, sujeto a tiempos de espera | Siga la guía de Google Colab |
| Utilice el suyo propio | Medio | Ejecute todo localmente en su propia máquina | Las GPU no son gratuitas, requieren un costo inicial | Siga las directrices de instalación de PyTorch |
| Computación en la nube (AWS, GCP, Azure) | Medio-Duro | Pequeño costo inicial, acceso a computación casi infinita | Puede resultar costoso si se ejecuta continuamente, lleva algo de tiempo configurarlo correctamente | Siga las directrices de instalación de PyTorch |
Hay más opciones para usar GPU, pero las tres anteriores serán suficientes por ahora.
Personalmente, uso una combinación de Google Colab y mi propia computadora personal para experimentos a pequeña escala (y para crear este curso) y recurro a recursos de la nube cuando necesito más potencia informática.
Recurso: Si está pensando en comprar su propia GPU pero no está seguro de qué comprar, [Tim Dettmers tiene una guía excelente](https://timdettmers.com/2020/09/07/ Which -gpu-para-aprendizaje-profundo/).
Para verificar si tiene acceso a una GPU Nvidia, puede ejecutar !nvidia-smi donde ! (también llamado bang) significa "ejecutar esto en la línea de comando".
!nvidia-smi
Si no tiene una GPU Nvidia accesible, lo anterior generará algo como:
NVIDIA-SMI falló porque no pudo comunicarse con el controlador NVIDIA. Asegúrese de que el controlador NVIDIA más reciente esté instalado y ejecutándose.
En ese caso, vuelva a subir y siga los pasos de instalación.
Si tiene una GPU, la línea anterior generará algo como:
miércoles 19 de enero 22:09:08 2022
+------------------------------------------------- ----------------------------+
| NVIDIA-SMI 495.46 Versión del controlador: 460.32.03 Versión CUDA: 11.2 |
|-------------------------------+------------------ -----+----------------------+
| Persistencia del nombre de GPU-M| Visualización de ID de bus A | Incorrección volátil. CEC |
| Fan Temp Perf Pwr:Uso/Cap| Uso de memoria | GPU-Util Compute M. |
| | | MIG M. |
|===============================+================== =====+======================|
| 0 Tesla P100-PCIE... Apagado | 00000000:00:04.0 Apagado | 0 |
| N/D 35C P0 27W / 250W | 0MiB/16280MiB | 0% Predeterminado |
| | | N/A |
+-------------------------------+------------------ -----+----------------------+
+------------------------------------------------- ----------------------------+
| Procesos: |
| GPU GI CI PID Tipo Nombre del proceso GPU Memoria |
| Uso de identificación |
|=================================================== ============================|
| No se encontraron procesos en ejecución |
+------------------------------------------------- ----------------------------+
2. Hacer que PyTorch se ejecute en la GPU¶
Una vez que tenga una GPU lista para acceder, el siguiente paso es utilizar PyTorch para almacenar datos (tensores) y calcular datos (realizar operaciones con tensores).
Para hacerlo, puede utilizar el paquete torch.cuda.
En lugar de hablar de ello, probémoslo.
Puede probar si PyTorch tiene acceso a una GPU usando torch.cuda.is_available().
# Comprobar GPU
import torch
torch.cuda.is_available()
Si lo anterior genera "True", PyTorch puede ver y usar la GPU, si genera "False", no puede ver la GPU y, en ese caso, tendrá que volver a realizar los pasos de instalación.
Ahora, digamos que desea configurar su código para que se ejecute en la CPU o la GPU, si está disponible.
De esa manera, si usted o alguien decide ejecutar su código, funcionará independientemente del dispositivo informático que esté utilizando.
Creemos una variable "dispositivo" para almacenar qué tipo de dispositivo está disponible.
# Establecer tipo de dispositivo
device = "cuda" if torch.cuda.is_available() else "cpu"
device
Si el resultado anterior es "cuda", significa que podemos configurar todo nuestro código PyTorch para usar el dispositivo CUDA disponible (una GPU) y si genera "cpu", nuestro código PyTorch se quedará con la CPU.
Nota: En PyTorch, se recomienda escribir código independiente del dispositivo. Esto significa código que se ejecutará en la CPU (siempre disponible) o GPU (si está disponible).
Si desea realizar una informática más rápida, puede utilizar una GPU, pero si desea realizar una informática mucho más rápida, puede utilizar varias GPU.
Puede contar la cantidad de GPU a las que PyTorch tiene acceso usando [torch.cuda.device_count()](https://pytorch.org/docs/stable/generated/torch.cuda.device_count.html#torch.cuda. recuento_dispositivo).
# Contar el número de dispositivos
torch.cuda.device_count()
Saber la cantidad de GPU a las que tiene acceso PyTorch es útil en caso de que desee ejecutar un proceso específico en una GPU y otro proceso en otra (PyTorch también tiene funciones que le permiten ejecutar un proceso en todas las GPU).
2.1 Hacer que PyTorch se ejecute en Apple Silicon¶
Para ejecutar PyTorch en las GPU M1/M2/M3 de Apple, puede utilizar el módulo torch.backends.mps.
Asegúrese de que las versiones de macOS y Pytorch estén actualizadas.
Puede probar si PyTorch tiene acceso a una GPU usando torch.backends.mps.is_available().
# Compruebe si hay GPU Apple Silicon
import torch
torch.backends.mps.is_available() # Note this will print false if you're not running on a Mac
# Establecer tipo de dispositivo
device = "mps" if torch.backends.mps.is_available() else "cpu"
device
Como antes, si el resultado anterior es "mps", significa que podemos configurar todo nuestro código PyTorch para usar la GPU Apple Silicon disponible.
if torch.cuda.is_available():
device = "cuda" # Use NVIDIA GPU (if available)
elif torch.backends.mps.is_available():
device = "mps" # Use Apple Silicon GPU (if available)
else:
device = "cpu" # Default to CPU if no GPU is available
3. Poner tensores (y modelos) en la GPU¶
Puede colocar tensores (y modelos, lo veremos más adelante) en un dispositivo específico llamando a [to(device)](https://pytorch.org/docs/stable/generated/torch.Tensor.to. html) en ellos. Donde "dispositivo" es el dispositivo de destino al que desea que vaya el tensor (o modelo).
¿Por qué hacer esto?
Las GPU ofrecen computación numérica mucho más rápida que las CPU y, si no hay una GPU disponible, debido a nuestro código independiente del dispositivo (ver arriba), se ejecutará en la CPU.
Nota: Poner un tensor en la GPU usando
to(dispositivo)(por ejemplo,some_tensor.to(device)) devuelve una copia de ese tensor, p.ej. el mismo tensor estará en CPU y GPU. Para sobrescribir tensores, reasígnalos:
algún_tensor = algún_tensor.to(dispositivo)
Intentemos crear un tensor y ponerlo en la GPU (si está disponible).
# Crear tensor (predeterminado en la CPU)
tensor = torch.tensor([1, 2, 3])
# Tensor no en GPU
print(tensor, tensor.device)
# Mover tensor a GPU (si está disponible)
tensor_on_gpu = tensor.to(device)
tensor_on_gpu
Si tiene una GPU disponible, el código anterior generará algo como:
tensor([1, 2, 3]) CPU
tensor([1, 2, 3], dispositivo='cuda:0')
Observe que el segundo tensor tiene 'device='cuda:0', esto significa que está almacenado en la 0.ª GPU disponible (las GPU están indexadas a 0, si hubiera dos GPU disponibles, serían 'cuda:0' y ' cuda:1' respectivamente, hasta 'cuda:n').
4. Mover tensores de regreso a la CPU¶
¿Qué pasaría si quisiéramos mover el tensor de nuevo a la CPU?
Por ejemplo, querrás hacer esto si quieres interactuar con tus tensores con NumPy (NumPy no aprovecha la GPU).
Intentemos usar el método torch.Tensor.numpy() en nuestro tensor_on_gpu.
# Si el tensor está en la GPU, no se puede transformar a NumPy (esto generará un error)
tensor_on_gpu.numpy()
En su lugar, para devolver un tensor a la CPU y poder usarlo con NumPy, podemos usar Tensor.cpu().
Esto copia el tensor a la memoria de la CPU para que pueda usarse con CPU.
# En su lugar, copie el tensor nuevamente a la CPU.
tensor_back_on_cpu = tensor_on_gpu.cpu().numpy()
tensor_back_on_cpu
Lo anterior devuelve una copia del tensor de la GPU en la memoria de la CPU, por lo que el tensor original todavía está en la GPU.
tensor_on_gpu
Ejercicios¶
Todos los ejercicios se centran en practicar el código anterior.
Debería poder completarlos haciendo referencia a cada sección o siguiendo los recursos vinculados.
Recursos:
- Cuaderno de plantilla de ejercicios para 00.
- Cuaderno de soluciones de ejemplo para 00 (pruebe los ejercicios antes de mirar esto).
- Lectura de documentación: una gran parte del aprendizaje profundo (y de aprender a codificar en general) es familiarizarse con la documentación de un marco determinado que estás utilizando. Usaremos mucho la documentación de PyTorch durante el resto de este curso. Así que recomendaría dedicar 10 minutos a leer lo siguiente (está bien si no entiendes algunas cosas por ahora, el enfoque aún no es la comprensión total, sino la conciencia). Consulte la documentación en
torch.Tensory para [torch.cuda](https://pytorch.org/ docs/master/notes/cuda.html#cuda-semantics). - Crea un tensor aleatorio con forma
(7, 7). - Realiza una multiplicación matricial del tensor de 2 con otro tensor aleatorio con forma
(1, 7)(pista: es posible que tengas que transponer el segundo tensor). - Establezca la semilla aleatoria en "0" y repita los ejercicios 2 y 3.
- Hablando de semillas aleatorias, vimos cómo configurarlas con
torch.manual_seed()pero ¿existe una GPU equivalente? (Pista: necesitarás consultar la documentación detorch.cudapara este caso). Si es así, configure la semilla aleatoria de la GPU en "1234". - Cree dos tensores aleatorios de forma
(2, 3)y envíelos a la GPU (necesitará acceso a una GPU para esto). Configuretorch.manual_seed(1234)al crear los tensores (no tiene que ser la semilla aleatoria de la GPU). - Realiza una multiplicación de matrices en los tensores que creaste en 6 (nuevamente, es posible que tengas que ajustar las formas de uno de los tensores).
- Encuentre los valores máximo y mínimo de la salida de 7.
- Encuentre los valores de índice máximo y mínimo de la salida de 7.
- Haga un tensor aleatorio con forma
(1, 1, 1, 10)y luego cree un nuevo tensor con todas las dimensiones1eliminadas para quedar con un tensor de forma(10). Establezca la semilla en7cuando la cree e imprima el primer tensor y su forma, así como el segundo tensor y su forma.
Extracurricular¶
- Dedique 1 hora a leer el tutorial básico de PyTorch (recomiendo el [Inicio rápido](https://pytorch.org/ tutorials/beginner/basics/quickstart_tutorial.html) y Tensores secciones).
- Para obtener más información sobre cómo un tensor puede representar datos, vea este vídeo: ¿Qué es un tensor?