01. Fundamentos del flujo de trabajo de PyTorch¶
La esencia del aprendizaje automático y del aprendizaje profundo es tomar algunos datos del pasado, construir un algoritmo (como una red neuronal) para descubrir patrones en ellos y utilizar los patrones descubiertos para predecir el futuro.
Hay muchas maneras de hacer esto y constantemente se descubren muchas nuevas.
Pero empecemos poco a poco.
¿Qué tal si comenzamos con una línea recta?
Y vemos si podemos construir un modelo de PyTorch que aprenda el patrón de la línea recta y lo iguale.
Qué vamos a cubrir¶
En este módulo, cubriremos un flujo de trabajo estándar de PyTorch (se puede cortar y cambiar según sea necesario, pero cubre el esquema principal de pasos).
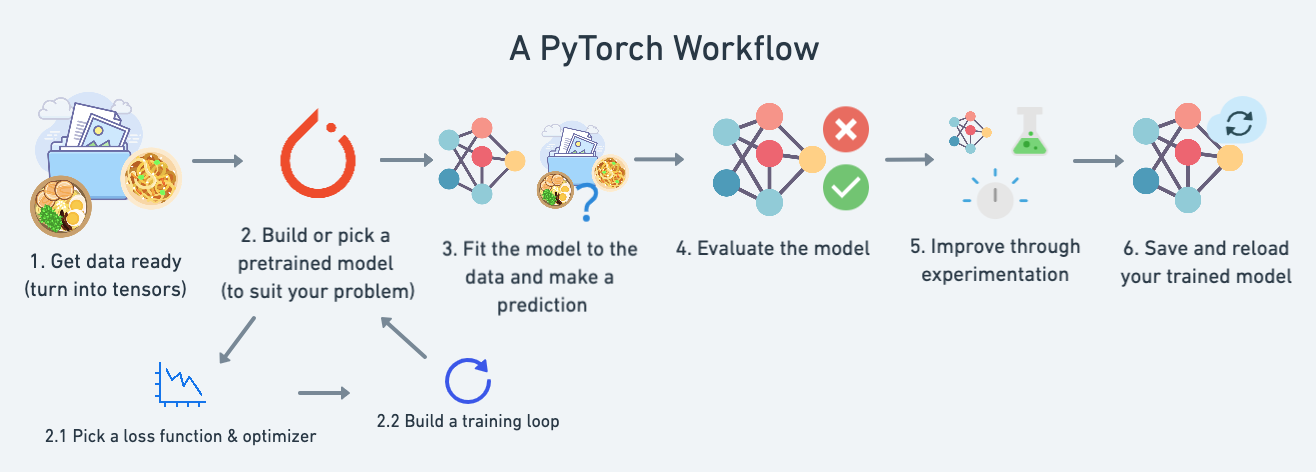
Por ahora, usaremos este flujo de trabajo para predecir una línea recta simple, pero los pasos del flujo de trabajo se pueden repetir y cambiar según el problema en el que esté trabajando.
Específicamente, cubriremos:
| Tema | Contenido |
|---|
| 1. Preparando datos | Los datos pueden ser casi cualquier cosa, pero para empezar vamos a crear una línea recta simple. | 2. Construyendo un modelo | Aquí crearemos un modelo para aprender patrones en los datos, también elegiremos una función de pérdida, un optimizador y crearemos un bucle de entrenamiento. | | 3. Ajustar el modelo a los datos (entrenamiento) | Tenemos datos y un modelo, ahora dejemos que el modelo (intente) encontrar patrones en los datos (entrenamiento). | | 4. Hacer predicciones y evaluar un modelo (inferencia) | Nuestro modelo encontró patrones en los datos. Comparemos sus hallazgos con los datos reales (pruebas). | | 5. Guardar y cargar un modelo | Es posible que desees utilizar tu modelo en otro lugar o volver a él más tarde; aquí lo cubriremos. | | 6. Poniéndolo todo junto | Tomemos todo lo anterior y combinémoslo. |
¿Dónde puedes obtener ayuda?¶
Todos los materiales de este curso están disponibles en GitHub.
Y si tiene problemas, también puede hacer una pregunta en la página de debates.
También están los foros de desarrolladores de PyTorch, un lugar muy útil para todo lo relacionado con PyTorch.
Comencemos poniendo lo que estamos cubriendo en un diccionario para consultarlo más adelante.
what_were_covering = {1: "data (prepare and load)",
2: "build model",
3: "fitting the model to data (training)",
4: "making predictions and evaluating a model (inference)",
5: "saving and loading a model",
6: "putting it all together"
}
Y ahora importemos lo que necesitaremos para este módulo.
Obtendremos torch, torch.nn (nn significa red neuronal y este paquete contiene los componentes básicos para crear redes neuronales en PyTorch) y matplotlib.
import torch
from torch import nn # nn contains all of PyTorch's building blocks for neural networks
import matplotlib.pyplot as plt
# Verifique la versión de PyTorch
torch.__version__
1. Datos (preparación y carga)¶
Quiero enfatizar que los "datos" en el aprendizaje automático pueden ser casi cualquier cosa que puedas imaginar. Una tabla de números (como una gran hoja de cálculo de Excel), imágenes de cualquier tipo, vídeos (¡YouTube tiene muchos datos!), archivos de audio como canciones o podcasts, estructuras de proteínas, texto y más.

El aprendizaje automático es un juego de dos partes:
- Convierte tus datos, sean los que sean, en números (una representación).
- Elija o construya un modelo para aprender la representación lo mejor posible.
A veces se pueden hacer uno y dos al mismo tiempo.
¿Pero qué pasa si no tienes datos?
Bueno, ahí es donde estamos ahora.
Sin datos.
Pero podemos crear algunos.
Creemos nuestros datos como una línea recta.
Usaremos regresión lineal para crear los datos con parámetros conocidos (cosas que un modelo puede aprender) y luego usaremos PyTorch para ver si podemos construir un modelo para estimar estos parámetros usando descenso de gradiente.
No se preocupe si los términos anteriores no significan mucho ahora, los veremos en acción y pondré recursos adicionales a continuación donde podrá obtener más información.
# Crear parámetros *conocidos*
weight = 0.7
bias = 0.3
# Crear datos
start = 0
end = 1
step = 0.02
X = torch.arange(start, end, step).unsqueeze(dim=1)
y = weight * X + bias
X[:10], y[:10]
¡Hermoso! Ahora vamos a avanzar hacia la construcción de un modelo que pueda aprender la relación entre "X" (características) e "y" (etiquetas).
Dividir datos en conjuntos de entrenamiento y prueba¶
Tenemos algunos datos.
Pero antes de construir un modelo debemos dividirlo.
Uno de los pasos más importantes en un proyecto de aprendizaje automático es crear un conjunto de capacitación y prueba (y, cuando sea necesario, un conjunto de validación).
Cada división del conjunto de datos tiene un propósito específico:
| Dividir | Propósito | Cantidad de datos totales | ¿Con qué frecuencia se usa? |
|---|---|---|---|
| Conjunto de entrenamiento | El modelo aprende de estos datos (como los materiales del curso que estudia durante el semestre). | ~60-80% | Siempre |
| Conjunto de validación | El modelo se ajusta a estos datos (como el examen de práctica que realiza antes del examen final). | ~10-20% | A menudo pero no siempre |
| Conjunto de prueba | El modelo se evalúa con estos datos para probar lo que ha aprendido (como el examen final que realiza al final del semestre). | ~10-20% | Siempre |
Por ahora, solo usaremos un conjunto de entrenamiento y prueba, esto significa que tendremos un conjunto de datos para que nuestro modelo aprenda y evalúe.
Podemos crearlos dividiendo nuestros tensores X e y.
Nota: Cuando se trata de datos del mundo real, este paso generalmente se realiza justo al comienzo de un proyecto (el conjunto de prueba siempre debe mantenerse separado de todos los demás datos). Queremos que nuestro modelo aprenda de los datos de entrenamiento y luego los evalúe con datos de prueba para obtener una indicación de qué tan bien generaliza a ejemplos no vistos.
# Crear división de tren/prueba
train_split = int(0.8 * len(X)) # 80% of data used for training set, 20% for testing
X_train, y_train = X[:train_split], y[:train_split]
X_test, y_test = X[train_split:], y[train_split:]
len(X_train), len(y_train), len(X_test), len(y_test)
Maravilloso, tenemos 40 muestras para entrenamiento (X_train & y_train) y 10 muestras para prueba (X_test & y_test).
El modelo que creamos intentará aprender la relación entre X_train e y_train y luego evaluaremos lo que aprende en X_test e y_test.
Pero ahora nuestros datos son sólo números en una página.
Creemos una función para visualizarlo.
def plot_predictions(train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=None):
"""
Plots training data, test data and compares predictions.
"""
plt.figure(figsize=(10, 7))
# Plot training data in blue
plt.scatter(train_data, train_labels, c="b", s=4, label="Training data")
# Plot test data in green
plt.scatter(test_data, test_labels, c="g", s=4, label="Testing data")
if predictions is not None:
# Plot the predictions in red (predictions were made on the test data)
plt.scatter(test_data, predictions, c="r", s=4, label="Predictions")
# Show the legend
plt.legend(prop={"size": 14});
plot_predictions();
¡Épico!
Ahora, en lugar de ser sólo números en una página, nuestros datos son una línea recta.
Nota: Ahora es un buen momento para presentarle el lema del explorador de datos... "¡visualizar, visualizar, visualizar!"
Piensa en esto siempre que trabajes con datos y los conviertas en números: si puedes visualizar algo, puede hacer maravillas para la comprensión.
A las máquinas les encantan los números y a nosotros, los humanos, también nos gustan los números, pero también nos gusta mirar las cosas.
2. Construir modelo¶
Ahora que tenemos algunos datos, construyamos un modelo para usar los puntos azules para predecir los puntos verdes.
Vamos a saltar de inmediato.
Primero escribiremos el código y luego explicaremos todo.
Replicamos un modelo de regresión lineal estándar usando PyTorch puro.
# Crear una clase de modelo de regresión lineal
class LinearRegressionModel(nn.Module): # <- almost everything in PyTorch is a nn.Module (think of this as neural network lego blocks)
def __init__(self):
super().__init__()
self.weights = nn.Parameter(torch.randn(1, # <- start with random weights (this will get adjusted as the model learns)
dtype=torch.float), # <- PyTorch loves float32 by default
requires_grad=True) # <- can we update this value with gradient descent?)
self.bias = nn.Parameter(torch.randn(1, # <- start with random bias (this will get adjusted as the model learns)
dtype=torch.float), # <- PyTorch loves float32 by default
requires_grad=True) # <- can we update this value with gradient descent?))
# Forward defines the computation in the model
def forward(self, x: torch.Tensor) -> torch.Tensor: # <- "x" is the input data (e.g. training/testing features)
return self.weights * x + self.bias # <- this is the linear regression formula (y = m*x + b)
Muy bien, están sucediendo bastantes cosas arriba, pero analicémoslas poco a poco.
Recurso: Usaremos clases de Python para crear fragmentos para construir redes neuronales. Si no está familiarizado con la notación de clases de Python, le recomiendo leer la [Guía de programación orientada a objetos de Real Python en Python 3] (https://realpython.com/python3-object- Oriented-programming/) varias veces.
Conceptos básicos de construcción de modelos PyTorch¶
PyTorch tiene cuatro módulos esenciales (más o menos) que puedes usar para crear casi cualquier tipo de red neuronal que puedas imaginar.
Son torch.nn, torch.optim, torch.utils.data.Dataset y [torch.utils.data.DataLoader] (https://pytorch.org/docs/stable/data.html). Por ahora, nos centraremos en los dos primeros y llegaremos a los otros dos más adelante (aunque es posible que puedas adivinar qué hacen).
| Módulo PyTorch | ¿Qué hace? |
|---|---|
torch.nn |
Contiene todos los componentes básicos de los gráficos computacionales (esencialmente una serie de cálculos ejecutados de una manera particular). |
torch.nn.Parameter |
Almacena tensores que se pueden usar con nn.Module. Si los gradientes requires_grad=True (utilizados para actualizar los parámetros del modelo a través de gradient descent) se calculan automáticamente, esto es a menudo denominado "autogrado". |
torch.nn.Module |
La clase base para todos los módulos de redes neuronales, todos los componentes básicos de las redes neuronales son subclases. Si está construyendo una red neuronal en PyTorch, sus modelos deben subclasificar nn.Module. Requiere la implementación de un método forward(). |
torch.optim |
Contiene varios algoritmos de optimización (estos indican a los parámetros del modelo almacenados en nn.Parameter cómo cambiar mejor para mejorar el descenso del gradiente y, a su vez, reducir la pérdida). |
def adelante() |
Todas las subclases de nn.Module requieren un método forward(), que define el cálculo que se realizará con los datos pasados al nn.Module particular (por ejemplo, la fórmula de regresión lineal anterior). |
Si lo anterior suena complejo, piense así: casi todo en una red neuronal PyTorch proviene de torch.nn,
nn.Modulecontiene los bloques de construcción más grandes (capas)nn.Parametercontiene los parámetros más pequeños como pesos y sesgos (juntelos para crearnn.Module(s))forward()le dice a los bloques más grandes cómo hacer cálculos en las entradas (tensores llenos de datos) dentro denn.Module(s)torch.optimcontiene métodos de optimización sobre cómo mejorar los parámetros dentro denn.Parameterpara representar mejor los datos de entrada
 Bloques de construcción básicos para la creación de un modelo PyTorch mediante la subclasificación de
Bloques de construcción básicos para la creación de un modelo PyTorch mediante la subclasificación de nn.Module. Para los objetos que son subclases nn.Module, se debe definir el método forward().
Recurso: Vea más de estos módulos esenciales y sus casos de uso en la Hoja de referencia de PyTorch.
Comprobando el contenido de un modelo de PyTorch¶
Ahora que los hemos eliminado, creemos una instancia de modelo con la clase que hemos creado y verifiquemos sus parámetros usando [.parameters()](https://pytorch.org/docs/stable/generated /torch.nn.Module.html#torch.nn.Module.parameters).
# Establezca la semilla manual ya que nn. Los parámetros se inicializan aleatoriamente
torch.manual_seed(42)
# Cree una instancia del modelo (esta es una subclase de nn.Module que contiene nn.Parameter(s))
model_0 = LinearRegressionModel()
# Verifique los nn.Parameter(s) dentro de la subclase nn.Module que creamos
list(model_0.parameters())
También podemos obtener el estado (lo que contiene el modelo) del modelo usando [.state_dict()](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn .Module.state_dict).
# Lista de parámetros con nombre
model_0.state_dict()
¿Observa cómo los valores de pesos y sesgo de model_0.state_dict() aparecen como tensores flotantes aleatorios?
Esto se debe a que los inicializamos anteriormente usando torch.randn().
Básicamente, queremos comenzar a partir de parámetros aleatorios y hacer que el modelo los actualice hacia los parámetros que mejor se ajusten a nuestros datos (los valores codificados de "peso" y "sesgo" que configuramos al crear nuestros datos en línea recta).
Ejercicio: Intente cambiar el valor
torch.manual_seed()dos celdas arriba, vea qué sucede con los pesos y los valores de sesgo.
Debido a que nuestro modelo comienza con valores aleatorios, en este momento tendrá poco poder predictivo.
Hacer predicciones usando torch.inference_mode()¶
Para verificar esto, podemos pasarle los datos de prueba X_test para ver qué tan cerca predice y_test.
Cuando pasamos datos a nuestro modelo, pasará por el método forward() del modelo y producirá un resultado utilizando el cálculo que hemos definido.
Hagamos algunas predicciones.
# Hacer predicciones con modelo.
with torch.inference_mode():
y_preds = model_0(X_test)
# Nota: en el código PyTorch anterior es posible que también vea torch.no_grad()
# con antorcha.no_grad():
# y_preds = model_0(X_test)
¿Mmm?
Probablemente hayas notado que usamos torch.inference_mode() como [administrador de contexto](https://realpython.com/ python-with-statement/) (eso es lo que es with torch.inference_mode():) para hacer las predicciones.
Como sugiere el nombre, torch.inference_mode() se utiliza cuando se utiliza un modelo para inferencia (hacer predicciones).
torch.inference_mode() desactiva un montón de cosas (como el seguimiento de gradiente, que es necesario para el entrenamiento pero no para la inferencia) para hacer pasos hacia adelante (datos que pasan por el método forward()) más rápido .
Nota: En el código PyTorch anterior, también puede ver que se usa
torch.no_grad()para inferencia. Mientras quetorch.inference_mode()ytorch.no_grad()hacen cosas similares,torch.inference_mode()es más nuevo, potencialmente más rápido y preferido. Consulte este Tweet de PyTorch para obtener más información.
Hemos hecho algunas predicciones, veamos cómo son.
# Consulta las predicciones
print(f"Number of testing samples: {len(X_test)}")
print(f"Number of predictions made: {len(y_preds)}")
print(f"Predicted values:\n{y_preds}")
Observe cómo hay un valor de predicción por muestra de prueba.
Esto se debe al tipo de datos que estamos utilizando. Para nuestra línea recta, un valor "X" se asigna a un valor "y".
Sin embargo, los modelos de aprendizaje automático son muy flexibles. Podría tener 100 valores "X" asignados a uno, dos, tres o 10 valores "y". Todo depende de en qué estés trabajando.
Nuestras predicciones siguen siendo números en una página, visualicémoslas con nuestra función plot_predictions() que creamos anteriormente.
plot_predictions(predictions=y_preds)
y_test - y_preds
¡Guau! Esas predicciones parecen bastante malas...
Sin embargo, esto tiene sentido si recuerda que nuestro modelo solo usa valores de parámetros aleatorios para hacer predicciones.
Ni siquiera ha mirado los puntos azules para intentar predecir los puntos verdes.
Es hora de cambiar eso.
3. Modelo de tren¶
En este momento, nuestro modelo está haciendo predicciones utilizando parámetros aleatorios para realizar cálculos, básicamente está adivinando (al azar).
Para solucionarlo, podemos actualizar sus parámetros internos (también me refiero a parámetros como patrones), los valores de pesos y bias que configuramos aleatoriamente usando nn.Parameter() y torch.randn() ser algo que represente mejor los datos.
Podríamos codificar esto (ya que conocemos los valores predeterminados weight=0.7 y bias=0.3), pero ¿dónde está la diversión en eso?
Muchas veces no sabrás cuáles son los parámetros ideales para un modelo.
En cambio, es mucho más divertido escribir código para ver si el modelo puede intentar resolverlos por sí mismo.
Creando una función de pérdida y optimizador en PyTorch¶
Para que nuestro modelo actualice sus parámetros por sí solo, necesitaremos agregar algunas cosas más a nuestra receta.
Y esa es una función de pérdida así como un optimizador.
Los rollos de estos son:
| Función | ¿Qué hace? | ¿Dónde vive en PyTorch? | Valores comunes |
|---|---|---|---|
| Función de pérdida | Mide qué tan erróneas se comparan las predicciones de sus modelos (por ejemplo, y_preds) con las etiquetas de verdad (por ejemplo, y_test). Baja cuanto mejor. |
PyTorch tiene muchas funciones de pérdida integradas en torch.nn. |
Error absoluto medio (MAE) para problemas de regresión (torch.nn.L1Loss()). Entropía cruzada binaria para problemas de clasificación binaria (torch.nn.BCELoss()). |
| Optimizador | Le indica a su modelo cómo actualizar sus parámetros internos para reducir mejor la pérdida. | Puede encontrar varias implementaciones de funciones de optimización en torch.optim. |
Descenso de gradiente estocástico (torch.optim.SGD()). Optimizador Adam (torch.optim.Adam()). |
Creemos una función de pérdida y un optimizador que podamos usar para ayudar a mejorar nuestro modelo.
Dependiendo del tipo de problema en el que esté trabajando, dependerá de qué función de pérdida y qué optimizador utilice.
Sin embargo, hay algunos valores comunes que se sabe que funcionan bien, como el SGD (descenso de gradiente estocástico) o el optimizador Adam. Y la función de pérdida MAE (error absoluto medio) para problemas de regresión (predecir un número) o la función de pérdida de entropía cruzada binaria para problemas de clasificación (predecir una cosa u otra).
Para nuestro problema, dado que estamos prediciendo un número, usemos MAE (que se encuentra en torch.nn.L1Loss()) en PyTorch como nuestra función de pérdida.
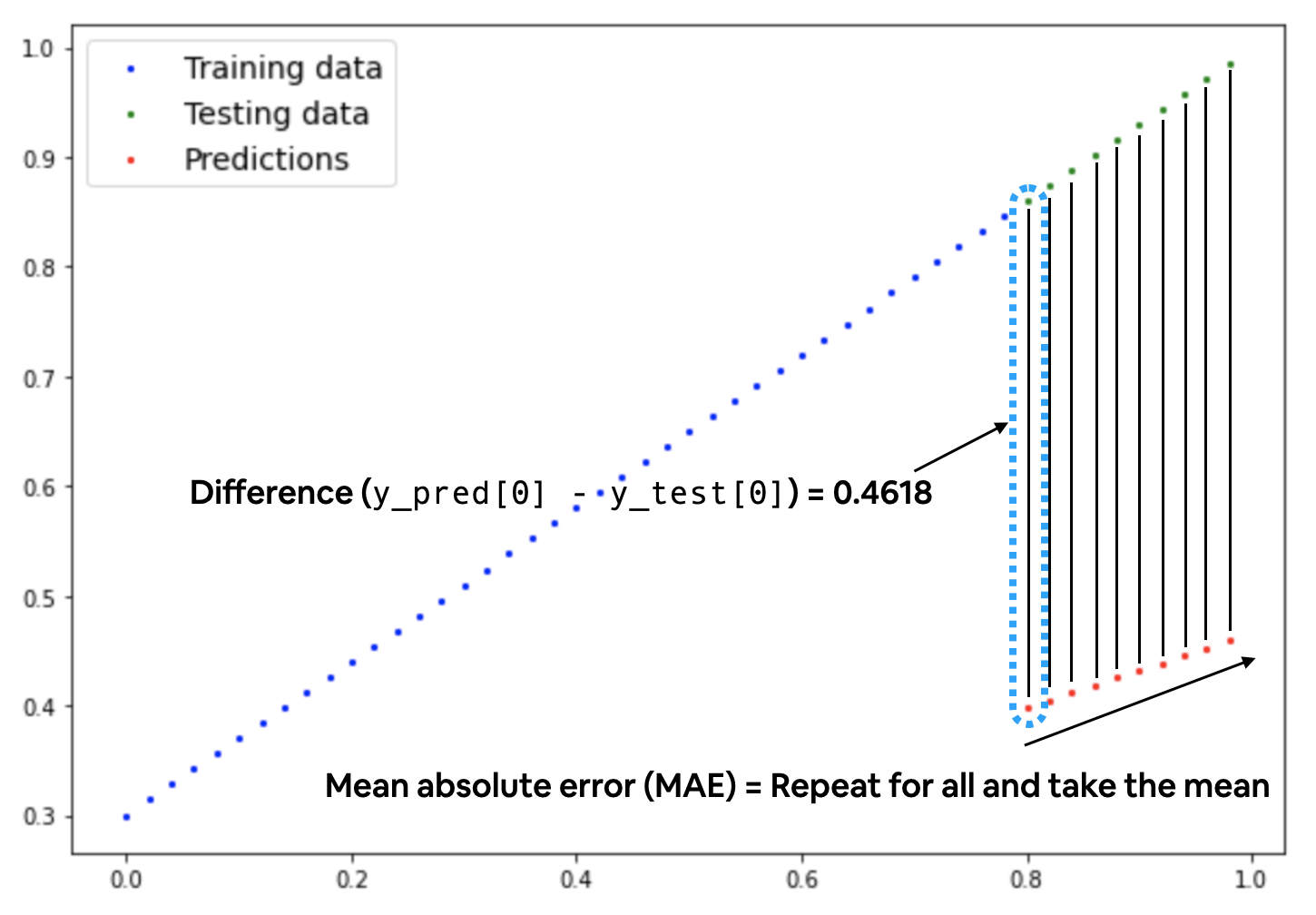 El error absoluto medio (MAE, en PyTorch:
El error absoluto medio (MAE, en PyTorch: torch.nn.L1Loss) mide la diferencia absoluta entre dos puntos (predicciones y etiquetas) y luego toma la media en todos los ejemplos.
Y usaremos SGD, torch.optim.SGD(params, lr) donde:
paramsson los parámetros del modelo de destino que le gustaría optimizar (por ejemplo, los valores depesosysesgoque configuramos aleatoriamente antes).lres la tasa de aprendizaje a la que desea que el optimizador actualice los parámetros; mayor significa que el optimizador intentará actualizaciones más grandes (a veces pueden ser demasiado grandes y el optimizador no funcionará), menor significa el optimizador intentará actualizaciones más pequeñas (a veces pueden ser demasiado pequeñas y el optimizador tardará demasiado en encontrar los valores ideales). La tasa de aprendizaje se considera un hiperparámetro (porque la establece un ingeniero de aprendizaje automático). Los valores iniciales comunes para la tasa de aprendizaje son0.01,0.001,0.0001; sin embargo, estos también se pueden ajustar con el tiempo (esto se llama [programación de la tasa de aprendizaje](https://pytorch.org/docs/stable /optim.html#how-to-adjust-learning-rate)).
Vaya, eso es mucho, veámoslo en código.
# Crear la función de pérdida
loss_fn = nn.L1Loss() # MAE loss is same as L1Loss
# Crear el optimizador
optimizer = torch.optim.SGD(params=model_0.parameters(), # parameters of target model to optimize
lr=0.01) # learning rate (how much the optimizer should change parameters at each step, higher=more (less stable), lower=less (might take a long time))
Creando un bucle de optimización en PyTorch¶
¡Guau! Ahora que tenemos una función de pérdida y un optimizador, es el momento de crear un bucle de entrenamiento (y un bucle de prueba).
El ciclo de entrenamiento implica que el modelo revise los datos de entrenamiento y aprenda las relaciones entre las "características" y las "etiquetas".
El ciclo de prueba implica revisar los datos de prueba y evaluar qué tan buenos son los patrones que el modelo aprendió en los datos de entrenamiento (el modelo nunca ve los datos de prueba durante el entrenamiento).
Cada uno de estos se denomina "bucle" porque queremos que nuestro modelo observe (recorra) cada muestra en cada conjunto de datos.
Para crearlos, vamos a escribir un bucle for de Python en el tema de la [canción no oficial del bucle de optimización de PyTorch] (https://twitter.com/mrdbourke/status/1450977868406673410?s=20) (hay un versión en vídeo también).
 La canción no oficial de los bucles de optimización de PyTorch, una forma divertida de recordar los pasos en un bucle de entrenamiento (y prueba) de PyTorch.
La canción no oficial de los bucles de optimización de PyTorch, una forma divertida de recordar los pasos en un bucle de entrenamiento (y prueba) de PyTorch.
Habrá bastante código, pero nada que no podamos manejar.
Bucle de entrenamiento de PyTorch¶
Para el ciclo de entrenamiento, crearemos los siguientes pasos:
| Número | Nombre del paso | ¿Qué hace? | Ejemplo de código |
|---|---|---|---|
| 1 | Pase hacia adelante | El modelo revisa todos los datos de entrenamiento una vez y realiza los cálculos de la función forward(). |
modelo(x_train) |
| 2 | Calcular la pérdida | Los resultados del modelo (predicciones) se comparan con la verdad fundamental y se evalúan para ver qué tan equivocados están. | pérdida = pérdida_fn(y_pred, y_train) |
| 3 | gradientes cero | Los gradientes de los optimizadores se establecen en cero (se acumulan de forma predeterminada) para que puedan recalcularse para el paso de entrenamiento específico. | optimizador.zero_grad() |
| 4 | Realizar retropropagación de la pérdida | Calcula el gradiente de pérdida con respecto a cada parámetro del modelo que se actualizará (cada parámetro con requires_grad=True). Esto se conoce como propagación hacia atrás, de ahí "hacia atrás". |
pérdida.hacia atrás() |
| 5 | Actualizar el optimizador (descenso de gradiente) | Actualice los parámetros con requires_grad=True con respecto a los gradientes de pérdida para mejorarlos. |
optimizador.paso() |
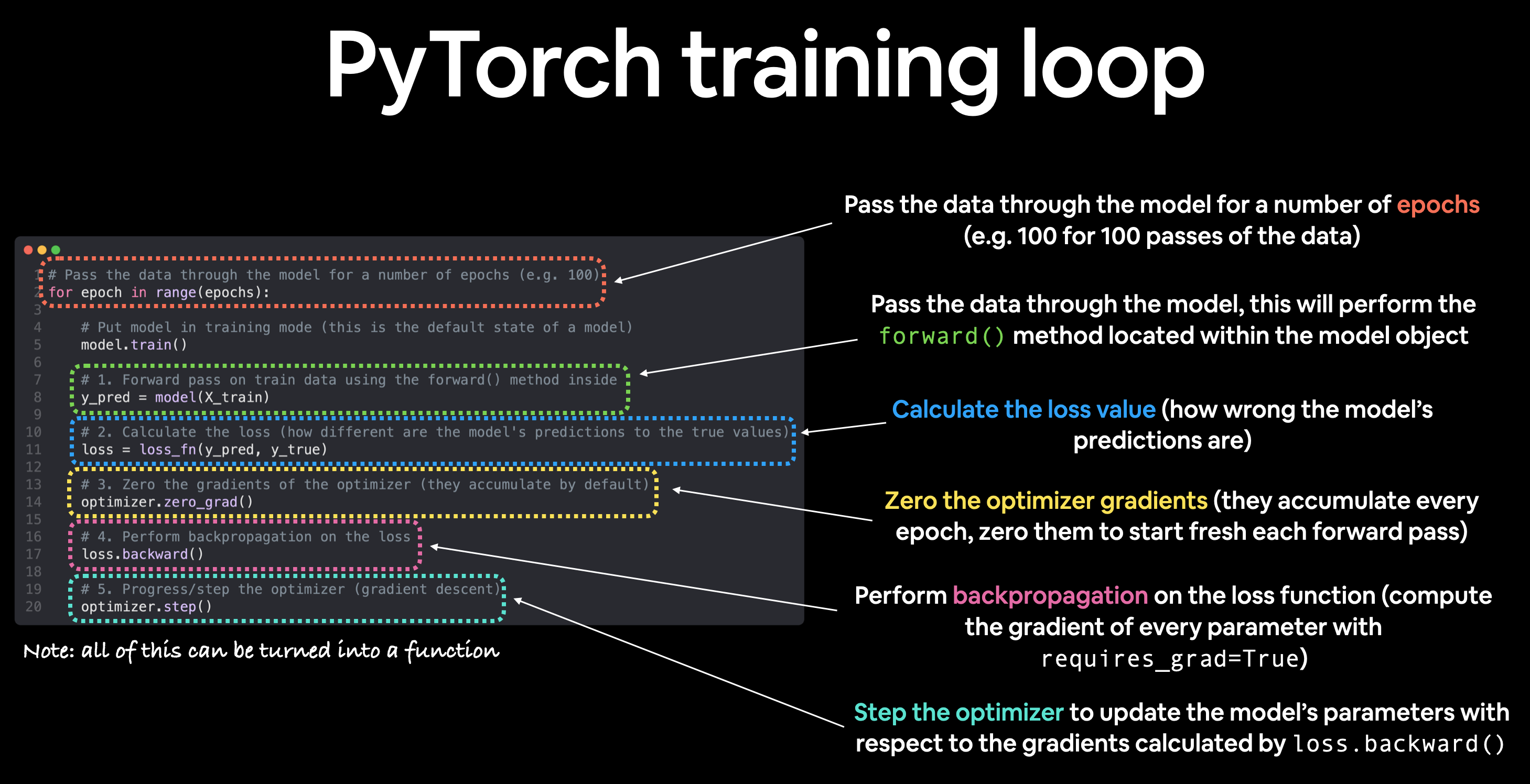
Nota: Lo anterior es sólo un ejemplo de cómo se pueden ordenar o describir los pasos. Con experiencia, descubrirá que crear bucles de entrenamiento de PyTorch puede ser bastante flexible.
Y en cuanto al orden de las cosas, el anterior es un buen orden predeterminado, pero es posible que veas pedidos ligeramente diferentes. Algunas reglas generales:
- Calcule la pérdida (
loss = ...) antes de realizar la retropropagación (loss.backward()).- Cero gradientes (
optimizer.zero_grad()) antes de pasarlos por pasos (optimizer.step()).- Paso del optimizador (
optimizer.step()) después de realizar la retropropagación de la pérdida (loss.backward()).
Para obtener recursos que le ayuden a comprender lo que sucede detrás de escena con la retropropagación y el descenso de gradiente, consulte la sección extracurricular.
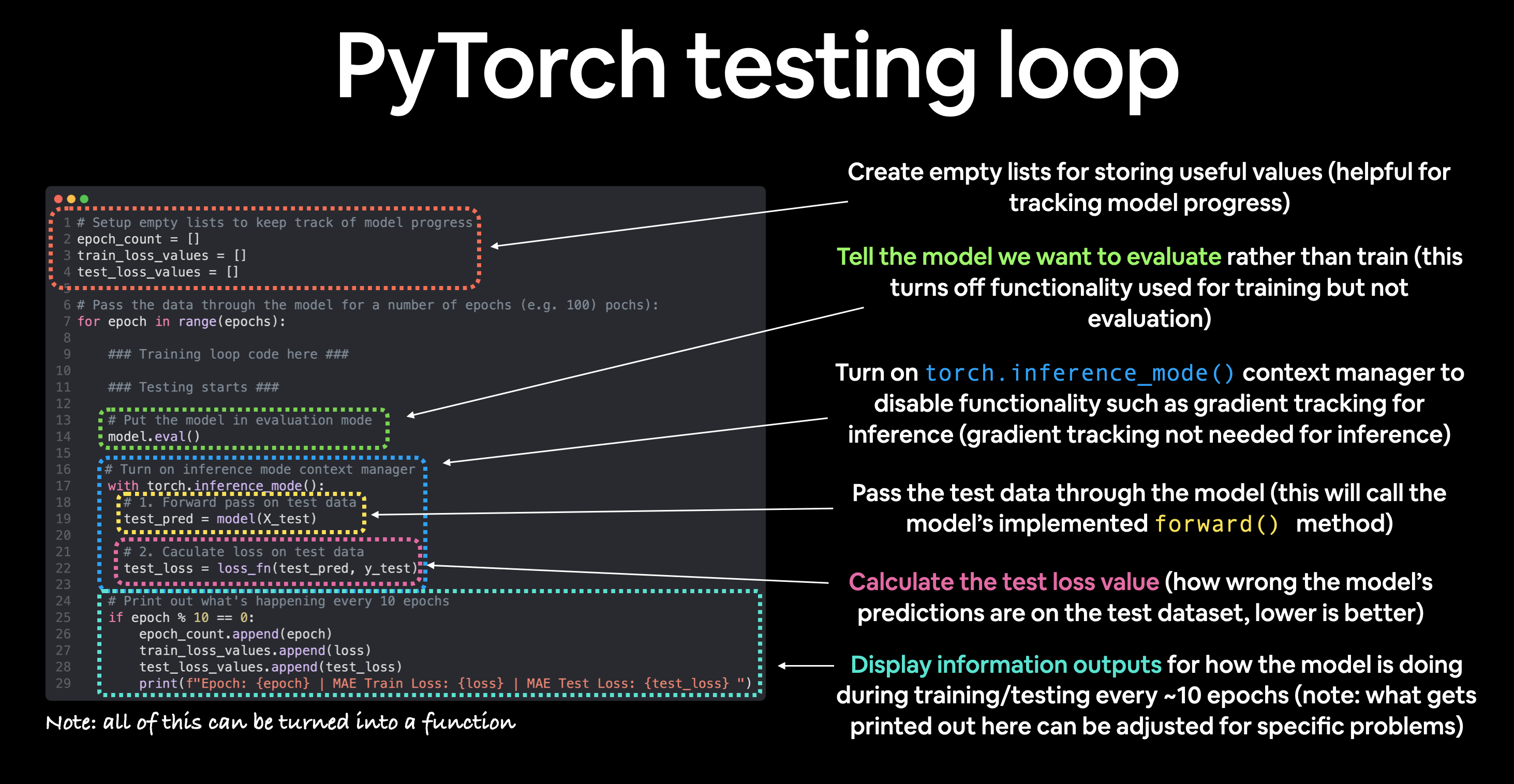
Bucle de prueba de PyTorch¶
En cuanto al ciclo de prueba (evaluación de nuestro modelo), los pasos típicos incluyen:
| Número | Nombre del paso | ¿Qué hace? | Ejemplo de código |
|---|---|---|---|
| 1 | Pase hacia adelante | El modelo revisa todos los datos de entrenamiento una vez y realiza los cálculos de la función forward(). |
modelo(x_test) |
| 2 | Calcular la pérdida | Los resultados del modelo (predicciones) se comparan con la verdad fundamental y se evalúan para ver qué tan equivocados están. | pérdida = pérdida_fn(y_pred, y_test) |
| 3 | Calcular métricas de evaluación (opcional) | Además del valor de pérdida, es posible que desee calcular otras métricas de evaluación, como la precisión en el conjunto de prueba. | Funciones personalizadas |
Observe que el ciclo de prueba no contiene realizar retropropagación (loss.backward()) ni avanzar el optimizador (optimizer.step()), esto se debe a que no se cambian parámetros en el modelo durante la prueba, ya ha sido calculado. Para las pruebas, solo nos interesa el resultado del paso directo a través del modelo.
Juntemos todo lo anterior y entrenemos nuestro modelo durante 100 épocas (pasos directos a través de los datos) y lo evaluaremos cada 10 épocas.
torch.manual_seed(42)
# Establezca el número de épocas (cuántas veces el modelo pasará por los datos de entrenamiento)
epochs = 100
# Cree listas de pérdidas vacías para realizar un seguimiento de los valores
train_loss_values = []
test_loss_values = []
epoch_count = []
for epoch in range(epochs):
### Training
# Put model in training mode (this is the default state of a model)
model_0.train()
# 1. Forward pass on train data using the forward() method inside
y_pred = model_0(X_train)
# print(y_pred)
# 2. Calculate the loss (how different are our models predictions to the ground truth)
loss = loss_fn(y_pred, y_train)
# 3. Zero grad of the optimizer
optimizer.zero_grad()
# 4. Loss backwards
loss.backward()
# 5. Progress the optimizer
optimizer.step()
### Testing
# Put the model in evaluation mode
model_0.eval()
with torch.inference_mode():
# 1. Forward pass on test data
test_pred = model_0(X_test)
# 2. Caculate loss on test data
test_loss = loss_fn(test_pred, y_test.type(torch.float)) # predictions come in torch.float datatype, so comparisons need to be done with tensors of the same type
# Print out what's happening
if epoch % 10 == 0:
epoch_count.append(epoch)
train_loss_values.append(loss.detach().numpy())
test_loss_values.append(test_loss.detach().numpy())
print(f"Epoch: {epoch} | MAE Train Loss: {loss} | MAE Test Loss: {test_loss} ")
¡Oh, mirarías eso! Parece que nuestra pérdida disminuye con cada época, tracemos un diagrama para descubrirlo.
# Trazar las curvas de pérdida
plt.plot(epoch_count, train_loss_values, label="Train loss")
plt.plot(epoch_count, test_loss_values, label="Test loss")
plt.title("Training and test loss curves")
plt.ylabel("Loss")
plt.xlabel("Epochs")
plt.legend();
¡Lindo! Las curvas de pérdida muestran que la pérdida disminuye con el tiempo. Recuerde, la pérdida es la medida de qué tan incorrecto es su modelo, por lo que cuanto menor sea, mejor.
Pero ¿por qué disminuyó la pérdida?
Bueno, gracias a nuestra función de pérdida y optimizador, los parámetros internos del modelo ("pesos" y "sesgo") se actualizaron para reflejar mejor los patrones subyacentes en los datos.
Inspeccionemos el .state_dict() de nuestro modelo para ver qué tan cerca llega nuestro modelo de los valores originales que establecimos para ponderaciones y sesgos.
# Encuentre los parámetros aprendidos de nuestro modelo.
print("The model learned the following values for weights and bias:")
print(model_0.state_dict())
print("\nAnd the original values for weights and bias are:")
print(f"weights: {weight}, bias: {bias}")
¡Guau! ¿Cuan genial es eso?
Nuestro modelo se acercó mucho para calcular los valores originales exactos de "peso" y "sesgo" (y probablemente se acercaría aún más si lo entrenáramos por más tiempo).
Ejercicio: Intente cambiar el valor de
épocasanterior a 200, ¿qué sucede con las curvas de pérdida y los pesos y valores de los parámetros de sesgo del modelo?
Probablemente nunca los adivine perfectamente (especialmente cuando se usan conjuntos de datos más complicados), pero está bien, a menudo puedes hacer cosas muy interesantes con una aproximación cercana.
Esta es la idea completa del aprendizaje automático y el aprendizaje profundo, hay algunos valores ideales que describen nuestros datos y en lugar de descifrarlos a mano, podemos entrenar un modelo para descifrarlos mediante programación.
4. Hacer predicciones con un modelo PyTorch entrenado (inferencia)¶
Una vez que haya entrenado un modelo, probablemente querrá hacer predicciones con él.
Ya hemos visto un vistazo de esto en el código de entrenamiento y prueba anterior; los pasos para hacerlo fuera del ciclo de entrenamiento/prueba son similares.
Hay tres cosas que se deben recordar al hacer predicciones (también llamadas realizar inferencias) con un modelo de PyTorch:
- Configure el modelo en modo de evaluación (
model.eval()). - Realice las predicciones utilizando el administrador de contexto del modo de inferencia (
with torch.inference_mode(): ...). - Todas las predicciones deben realizarse con objetos en el mismo dispositivo (por ejemplo, datos y modelo solo en GPU o datos y modelo solo en CPU).
Los primeros dos elementos garantizan que todos los cálculos y configuraciones útiles que PyTorch utiliza detrás de escena durante el entrenamiento, pero que no son necesarios para la inferencia, estén desactivados (esto da como resultado un cálculo más rápido). Y el tercero garantiza que no se encontrará con errores entre dispositivos.
# 1. Configure el modelo en modo de evaluación.
model_0.eval()
# 2. Configurar el administrador de contexto del modo de inferencia.
with torch.inference_mode():
# 3. Make sure the calculations are done with the model and data on the same device
# in our case, we haven't setup device-agnostic code yet so our data and model are
# on the CPU by default.
# model_0.to(device)
# X_test = X_test.to(device)
y_preds = model_0(X_test)
y_preds
¡Lindo! Hemos hecho algunas predicciones con nuestro modelo entrenado, ¿cómo se ven ahora?
plot_predictions(predictions=y_preds)
¡Guau! ¡Esos puntos rojos se ven mucho más cerca que antes!
Pasemos a guardar y recargar un modelo en PyTorch.
5. Guardar y cargar un modelo de PyTorch¶
Si ha entrenado un modelo de PyTorch, es probable que desee guardarlo y exportarlo a algún lugar.
Es decir, puede entrenarlo en Google Colab o en su máquina local con una GPU, pero ahora le gustaría exportarlo a algún tipo de aplicación donde otros puedan usarlo.
O tal vez quieras guardar tu progreso en un modelo y volver a cargarlo más tarde.
Para guardar y cargar modelos en PyTorch, existen tres métodos principales que debe conocer (todos los siguientes se han tomado de la [guía para guardar y cargar modelos de PyTorch] (https://pytorch.org/tutorials/beginner/ Saving_loading_models. html#ahorrar-cargar-modelo-para-inferencia)):
| Método PyTorch | ¿Qué hace? |
|---|---|
torch.save |
Guarda un objeto serializado en el disco usando la utilidad pickle de Python. Los modelos, tensores y varios otros objetos de Python, como diccionarios, se pueden guardar usando torch.save. |
torch.load |
Utiliza las funciones de deseleccionado de pickle para deserializar y cargar archivos de objetos Python encurtidos (como modelos, tensores o diccionarios) en la memoria. También puede configurar en qué dispositivo cargar el objeto (CPU, GPU, etc.). |
torch.nn.Module.load_state_dict |
Carga el diccionario de parámetros de un modelo (model.state_dict()) usando un objeto state_dict() guardado. |
Nota: Como se indica en la documentación
picklede Python, el módulopickleno es seguro. Eso significa que sólo debes deshacer (cargar) los datos en los que confías. Esto también se aplica a la carga de modelos de PyTorch. Utilice únicamente modelos PyTorch guardados de fuentes en las que confíe.
Guardar el state_dict() de un modelo de PyTorch¶
La [forma recomendada](https://pytorch.org/tutorials/beginner/ Saving_loading_models.html#served-loading-model-for-inference) para guardar y cargar un modelo para inferencia (hacer predicciones) es guardando y cargando un state_dict() del modelo.
Veamos cómo podemos hacerlo en unos pocos pasos:
- Crearemos un directorio para guardar modelos llamado "modelos" usando el módulo "pathlib" de Python.
- Crearemos una ruta de archivo para guardar el modelo.
- Llamaremos a
torch.save(obj, f)dondeobjes elstate_dict()del modelo de destino yfes el nombre de archivo donde guardar el modelo.
Nota: Es una convención común que los modelos u objetos guardados de PyTorch terminen con
.pto.pth, comosaved_model_01.pth.
from pathlib import Path
# 1. Crear directorio de modelos
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exist_ok=True)
# 2. Crear ruta para guardar el modelo
MODEL_NAME = "01_pytorch_workflow_model_0.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
# 3. Guarde el dictado del estado del modelo.
print(f"Saving model to: {MODEL_SAVE_PATH}")
torch.save(obj=model_0.state_dict(), # only saving the state_dict() only saves the models learned parameters
f=MODEL_SAVE_PATH)
# Verifique la ruta del archivo guardado
!ls -l models/01_pytorch_workflow_model_0.pth
Cargando state_dict() de un modelo PyTorch guardado¶
Como ahora tenemos un modelo guardado state_dict() en models/01_pytorch_workflow_model_0.pth, ahora podemos cargarlo usando torch.nn.Module.load_state_dict(torch.load(f)) donde f es la ruta de archivo de nuestro modelo guardado state_dict().
¿Por qué llamar a torch.load() dentro de torch.nn.Module.load_state_dict()?
Debido a que solo guardamos el state_dict() del modelo, que es un diccionario de parámetros aprendidos y no el modelo completo, primero tenemos que cargar el state_dict() con torch.load() y luego pasar ese state_dict() a una nueva instancia de nuestro modelo (que es una subclase de nn.Module).
¿Por qué no guardar todo el modelo?
Guardar el modelo completo en lugar de solo state_dict() es más intuitivo, sin embargo, para citar PyTorch documentación (cursiva mía):
La desventaja de este enfoque (guardar el modelo completo) es que los datos serializados están vinculados a las clases específicas y a la estructura de directorio exacta utilizada cuando se guarda el modelo...
Debido a esto, su código puede romperse de varias maneras cuando se usa en otros proyectos o después de refactorizaciones.
Entonces, en lugar de eso, estamos usando el método flexible de guardar y cargar solo state_dict(), que nuevamente es básicamente un diccionario de parámetros del modelo.
Probémoslo creando otra instancia de LinearRegressionModel(), que es una subclase de torch.nn.Module y, por lo tanto, tendrá el método incorporado load_state_dict().
# Crear una nueva instancia de nuestro modelo (esto se creará con pesos aleatorios)
loaded_model_0 = LinearRegressionModel()
# Cargue el state_dict de nuestro modelo guardado (esto actualizará la nueva instancia de nuestro modelo con pesos entrenados)
loaded_model_0.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
¡Excelente! Parece que las cosas coincidieron.
Ahora, para probar nuestro modelo cargado, realicemos inferencias con él (hagamos predicciones) en los datos de prueba.
¿Recuerda las reglas para realizar inferencias con modelos de PyTorch?
Si no, aquí hay un repaso:
- Establezca el modelo en modo de evaluación (
model.eval()). - Realice las predicciones utilizando el administrador de contexto del modo de inferencia (
con torch.inference_mode(): ...). - Todas las predicciones deben realizarse con objetos en el mismo dispositivo (por ejemplo, datos y modelo solo en GPU o datos y modelo solo en CPU).
# 1. Ponga el modelo cargado en modo de evaluación.
loaded_model_0.eval()
# 2. Utilice el administrador de contexto del modo de inferencia para hacer predicciones.
with torch.inference_mode():
loaded_model_preds = loaded_model_0(X_test) # perform a forward pass on the test data with the loaded model
Ahora que hemos hecho algunas predicciones con el modelo cargado, veamos si son las mismas que las predicciones anteriores.
# Compare las predicciones del modelo anterior con las predicciones del modelo cargado (deberían ser iguales)
y_preds == loaded_model_preds
¡Lindo!
Parece que las predicciones del modelo cargado son las mismas que las predicciones del modelo anterior (predicciones realizadas antes de guardar). Esto indica que nuestro modelo se está guardando y cargando como se esperaba.
Nota: Hay más métodos para guardar y cargar modelos de PyTorch, pero los dejaré para actividades extracurriculares y lecturas adicionales. Consulte la guía de PyTorch para guardar y cargar modelos para obtener más información.
6. Poniéndolo todo junto¶
Hemos cubierto bastante terreno hasta ahora.
Pero una vez que hayas practicado un poco, realizarás los pasos anteriores como si estuvieras bailando por la calle.
Hablando de práctica, juntemos todo lo que hemos hecho hasta ahora.
Excepto que esta vez haremos que nuestro código sea independiente del dispositivo (de modo que si hay una GPU disponible, la usará y, si no, usará de forma predeterminada la CPU).
Habrá muchos menos comentarios en esta sección que en la anterior, ya que lo que vamos a ver ya ha sido cubierto.
Comenzaremos importando las bibliotecas estándar que necesitamos.
Nota: Si está utilizando Google Colab, para configurar una GPU, vaya a Tiempo de ejecución -> Cambiar tipo de tiempo de ejecución -> Aceleración de hardware -> GPU. Si hace esto, se restablecerá el tiempo de ejecución de Colab y perderá las variables guardadas.
# Importar PyTorch y matplotlib
import torch
from torch import nn # nn contains all of PyTorch's building blocks for neural networks
import matplotlib.pyplot as plt
# Verifique la versión de PyTorch
torch.__version__
Ahora comencemos a hacer que nuestro código sea independiente del dispositivo configurando device="cuda" si está disponible; de lo contrario, el valor predeterminado será device="cpu".
# Configurar código independiente del dispositivo
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
Si tiene acceso a una GPU, lo anterior debería haberse impreso:
Dispositivo de uso: cuda
De lo contrario, utilizará una CPU para los siguientes cálculos. Esto está bien para nuestro pequeño conjunto de datos, pero llevará más tiempo para conjuntos de datos más grandes.
6.1 Datos¶
Creemos algunos datos como antes.
Primero, codificaremos algunos valores de "peso" y "sesgo".
Luego haremos un rango de números entre 0 y 1, estos serán nuestros valores "X".
Finalmente, usaremos los valores "X", así como los valores "peso" y "sesgo" para crear "y" usando la fórmula de regresión lineal (y = peso * X + sesgo).
# Crear peso y sesgo
weight = 0.7
bias = 0.3
# Crear valores de rango
start = 0
end = 1
step = 0.02
# Crear X e y (características y etiquetas)
X = torch.arange(start, end, step).unsqueeze(dim=1) # without unsqueeze, errors will happen later on (shapes within linear layers)
y = weight * X + bias
X[:10], y[:10]
¡Maravilloso!
Ahora que tenemos algunos datos, dividámoslos en conjuntos de entrenamiento y prueba.
Usaremos una división 80/20 con 80% de datos de entrenamiento y 20% de datos de prueba.
# Dividir datos
train_split = int(0.8 * len(X))
X_train, y_train = X[:train_split], y[:train_split]
X_test, y_test = X[train_split:], y[train_split:]
len(X_train), len(y_train), len(X_test), len(y_test)
Excelente, visualicémoslos para asegurarnos de que se vean bien.
# Nota: Si ha restablecido su tiempo de ejecución, esta función no funcionará.
# Tendrás que volver a ejecutar la celda de arriba donde se creó la instancia.
plot_predictions(X_train, y_train, X_test, y_test)
6.2 Construyendo un modelo lineal de PyTorch¶
Tenemos algunos datos, ahora es el momento de hacer un modelo.
Crearemos el mismo estilo de modelo que antes, excepto que esta vez, en lugar de definir los parámetros de peso y sesgo de nuestro modelo manualmente usando nn.Parameter(), usaremos nn.Linear(in_features, out_features) para que lo haga por nosotros.
Donde in_features es la cantidad de dimensiones que tienen sus datos de entrada y out_features es la cantidad de dimensiones a las que le gustaría que se generen.
En nuestro caso, ambos son 1 ya que nuestros datos tienen la característica de entrada 1 (X) por etiqueta (y).

Crear un modelo de regresión lineal usando nn.Parameter versus usar nn.Linear. Hay muchos más ejemplos en los que el módulo torch.nn tiene cálculos prediseñados, incluidas muchas capas de redes neuronales populares y útiles.
# Subclase nn.Módulo para realizar nuestro modelo.
class LinearRegressionModelV2(nn.Module):
def __init__(self):
super().__init__()
# Use nn.Linear() for creating the model parameters
self.linear_layer = nn.Linear(in_features=1,
out_features=1)
# Define the forward computation (input data x flows through nn.Linear())
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.linear_layer(x)
# Establezca la semilla manual al crear el modelo (esto no siempre es necesario, pero se usa con fines demostrativos, intente comentarlo y ver qué sucede)
torch.manual_seed(42)
model_1 = LinearRegressionModelV2()
model_1, model_1.state_dict()
Observe las salidas de model_1.state_dict(), la capa nn.Linear() creó un parámetro aleatorio de peso y bias para nosotros.
Ahora coloquemos nuestro modelo en la GPU (si está disponible).
Podemos cambiar el dispositivo en el que se encuentran nuestros objetos PyTorch usando .to(device).
Primero, verifiquemos el dispositivo actual del modelo.
# Comprobar modelo de dispositivo
next(model_1.parameters()).device
Maravilloso, parece que el modelo está en la CPU de forma predeterminada.
Cambiémoslo para que esté en la GPU (si está disponible).
# Configure el modelo en GPU si está disponible; de lo contrario, el valor predeterminado será CPU
model_1.to(device) # the device variable was set above to be "cuda" if available or "cpu" if not
next(model_1.parameters()).device
¡Lindo! Debido a nuestro código independiente del dispositivo, la celda anterior funcionará independientemente de si hay una GPU disponible o no.
Si tiene acceso a una GPU habilitada para CUDA, debería ver un resultado similar a:
dispositivo (tipo = 'cuda', índice = 0)
6.3 Formación¶
Es hora de crear un circuito de capacitación y prueba.
Primero necesitaremos una función de pérdida y un optimizador.
Usemos las mismas funciones que usamos antes, nn.L1Loss() y torch.optim.SGD().
Tendremos que pasar los parámetros del nuevo modelo (model.parameters()) al optimizador para que los ajuste durante el entrenamiento.
La tasa de aprendizaje de 0.01 también funcionó bien antes, así que usémosla nuevamente.
# Crear función de pérdida
loss_fn = nn.L1Loss()
# Crear optimizador
optimizer = torch.optim.SGD(params=model_1.parameters(), # optimize newly created model's parameters
lr=0.01)
Hermoso, función de pérdida y optimizador listo, ahora entrenemos y evaluemos nuestro modelo usando un ciclo de entrenamiento y prueba.
La única diferencia que haremos en este paso en comparación con el ciclo de entrenamiento anterior es colocar los datos en el "dispositivo" de destino.
Ya hemos puesto nuestro modelo en el dispositivo de destino usando model_1.to(device).
Y podemos hacer lo mismo con los datos.
De esa manera, si el modelo está en la GPU, los datos están en la GPU (y viceversa).
Esta vez demos un paso más y establezcamos epochs=1000.
Si necesita un recordatorio de los pasos del ciclo de entrenamiento de PyTorch, consulte a continuación.
- Pase hacia adelante: el modelo revisa todos los datos de entrenamiento una vez y realiza su
Función
adelante() cálculos (model(x_train)). - Calcule la pérdida: los resultados del modelo (predicciones) se comparan con la verdad fundamental y se evalúan.
para ver como
Están equivocados (
loss = loss_fn(y_pred, y_train). - Gradientes cero: los gradientes del optimizador se establecen en cero (se acumulan de forma predeterminada) para que
puede ser
recalculado para el paso de entrenamiento específico (
optimizer.zero_grad()). - Realizar retropropagación de la pérdida: calcula el gradiente de la pérdida con respecto a cada modelo.
parámetro a
ser actualizado (cada parámetro
con
requires_grad=True). Esto se conoce como propagación hacia atrás, por lo tanto, "hacia atrás". (pérdida.backward()). - Pasa el optimizador (descenso de gradiente) - Actualiza los parámetros con
requires_grad=Truecon respecto a la pérdida gradientes para mejorarlos (optimizer.step()).
torch.manual_seed(42)
# Establecer el número de épocas
epochs = 1000
# Poner datos en el dispositivo disponible.
# Sin esto, se producirá un error (no todos los modelos/datos del dispositivo)
X_train = X_train.to(device)
X_test = X_test.to(device)
y_train = y_train.to(device)
y_test = y_test.to(device)
for epoch in range(epochs):
### Training
model_1.train() # train mode is on by default after construction
# 1. Forward pass
y_pred = model_1(X_train)
# 2. Calculate loss
loss = loss_fn(y_pred, y_train)
# 3. Zero grad optimizer
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Step the optimizer
optimizer.step()
### Testing
model_1.eval() # put the model in evaluation mode for testing (inference)
# 1. Forward pass
with torch.inference_mode():
test_pred = model_1(X_test)
# 2. Calculate the loss
test_loss = loss_fn(test_pred, y_test)
if epoch % 100 == 0:
print(f"Epoch: {epoch} | Train loss: {loss} | Test loss: {test_loss}")
Nota: Debido a la naturaleza aleatoria del aprendizaje automático, es probable que obtenga resultados ligeramente diferentes (diferentes valores de pérdida y predicción) dependiendo de si su modelo fue entrenado en CPU o GPU. Esto es cierto incluso si usa la misma semilla aleatoria en cualquiera de los dispositivos. Si la diferencia es grande, es posible que desee buscar errores; sin embargo, si es pequeña (idealmente lo es), puede ignorarla.
¡Lindo! Esa pérdida parece bastante baja.
Verifiquemos los parámetros que nuestro modelo ha aprendido y compárelos con los parámetros originales que codificamos.
# Encuentre los parámetros aprendidos de nuestro modelo.
from pprint import pprint # pprint = pretty print, see: https://docs.python.org/3/library/pprint.html
print("The model learned the following values for weights and bias:")
pprint(model_1.state_dict())
print("\nAnd the original values for weights and bias are:")
print(f"weights: {weight}, bias: {bias}")
¡Ho, ho! Eso está bastante cerca de ser un modelo perfecto.
Sin embargo, recuerde que, en la práctica, es raro que conozca los parámetros perfectos de antemano.
Y si supiera de antemano los parámetros que su modelo debe aprender, ¿cuál sería la diversión del aprendizaje automático?
Además, en muchos problemas de aprendizaje automático del mundo real, la cantidad de parámetros puede superar las decenas de millones.
No sé ustedes, pero prefiero escribir código para que una computadora los resuelva en lugar de hacerlo a mano.
6.4 Hacer predicciones¶
Ahora que tenemos un modelo entrenado, activemos su modo de evaluación y hagamos algunas predicciones.
# Convertir el modelo en modo de evaluación
model_1.eval()
# Hacer predicciones sobre los datos de prueba.
with torch.inference_mode():
y_preds = model_1(X_test)
y_preds
Si está haciendo predicciones con datos en la GPU, es posible que observe que el resultado anterior tiene device='cuda:0' hacia el final. Eso significa que los datos están en el dispositivo CUDA 0 (la primera GPU a la que tiene acceso su sistema debido a la indexación cero); si termina usando varias GPU en el futuro, este número puede ser mayor.
Ahora tracemos las predicciones de nuestro modelo.
Nota: Muchas bibliotecas de ciencia de datos, como pandas, matplotlib y NumPy, no son capaces de utilizar datos almacenados en la GPU. Por lo tanto, es posible que tenga algunos problemas al intentar utilizar una función de una de estas bibliotecas con datos tensoriales no almacenados en la CPU. Para solucionar este problema, puede llamar a
.cpu()en su tensor objetivo para devolver una copia de su tensor objetivo. en la CPU.
# plot_predictions(predictions=y_preds) # -> no funcionará... los datos no están en la CPU
# Poner datos en la CPU y trazarlos.
plot_predictions(predictions=y_preds.cpu())
¡Guau! Mira esos puntos rojos, se alinean casi perfectamente con los puntos verdes. Supongo que las épocas adicionales ayudaron.
6.5 Guardar y cargar un modelo¶
Estamos contentos con las predicciones de nuestros modelos, así que guardémoslo en un archivo para poder usarlo más tarde.
from pathlib import Path
# 1. Crear directorio de modelos
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exist_ok=True)
# 2. Crear ruta para guardar el modelo
MODEL_NAME = "01_pytorch_workflow_model_1.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
# 3. Guarde el dictado del estado del modelo.
print(f"Saving model to: {MODEL_SAVE_PATH}")
torch.save(obj=model_1.state_dict(), # only saving the state_dict() only saves the models learned parameters
f=MODEL_SAVE_PATH)
Y solo para asegurarnos de que todo funcionó bien, volvamos a cargarlo.
Bien:
- Crear una nueva instancia de la clase
LinearRegressionModelV2() - Cargar en el dictado de estado del modelo usando
torch.nn.Module.load_state_dict() - Enviar la nueva instancia del modelo al dispositivo de destino (para garantizar que nuestro código sea independiente del dispositivo)
# Crear una instancia nueva de LinearRegressionModelV2
loaded_model_1 = LinearRegressionModelV2()
# Cargar dictado de estado del modelo
loaded_model_1.load_state_dict(torch.load(MODEL_SAVE_PATH))
# Coloque el modelo en el dispositivo de destino (si sus datos están en la GPU, el modelo deberá estar en la GPU para hacer predicciones)
loaded_model_1.to(device)
print(f"Loaded model:\n{loaded_model_1}")
print(f"Model on device:\n{next(loaded_model_1.parameters()).device}")
Ahora podemos evaluar el modelo cargado para ver si sus predicciones se alinean con las predicciones realizadas antes de guardar.
# Evaluar modelo cargado
loaded_model_1.eval()
with torch.inference_mode():
loaded_model_1_preds = loaded_model_1(X_test)
y_preds == loaded_model_1_preds
¡Todo suma! ¡Lindo!
Bueno, hemos recorrido un largo camino. ¡Ya ha creado y entrenado sus dos primeros modelos de redes neuronales en PyTorch!
Es hora de practicar tus habilidades.
Ejercicios¶
Todos los ejercicios se han inspirado en el código del cuaderno.
Hay un ejercicio por sección principal.
Debería poder completarlos consultando su sección específica.
Nota: Para todos los ejercicios, su código debe ser independiente del dispositivo (lo que significa que podría ejecutarse en CPU o GPU si está disponible).
- Cree un conjunto de datos de línea recta utilizando la fórmula de regresión lineal (
peso * X + sesgo).
- Establezca
weight=0.3ybias=0.9y debe haber al menos 100 puntos de datos en total. - Divida los datos en 80% de entrenamiento y 20% de pruebas.
- Trazar los datos de entrenamiento y prueba para que sean visuales.
- Cree un modelo de PyTorch subclasificando
nn.Module.
- Dentro debe haber un
nn.Parameter()inicializado aleatoriamente conrequires_grad=True, uno paraweightsy otro parabias. - Implemente el método
forward()para calcular la función de regresión lineal que utilizó para crear el conjunto de datos en 1. - Una vez que haya construido el modelo, cree una instancia del mismo y verifique su
state_dict(). - Nota: Si desea utilizar
nn.Linear()en lugar denn.Parameter(), puede hacerlo.
- Cree una función de pérdida y un optimizador usando
nn.L1Loss()ytorch.optim.SGD(params, lr)respectivamente.
- Establezca la tasa de aprendizaje del optimizador en 0,01 y los parámetros a optimizar deben ser los parámetros del modelo que creó en 2.
- Escriba un ciclo de entrenamiento para realizar los pasos de entrenamiento apropiados durante 300 épocas.
- El bucle de entrenamiento debe probar el modelo en el conjunto de datos de prueba cada 20 épocas.
- Haga predicciones con el modelo entrenado sobre los datos de prueba.
- Visualice estas predicciones en comparación con los datos de prueba y entrenamiento originales (nota: es posible que deba asegurarse de que las predicciones no estén en la GPU si desea utilizar bibliotecas no habilitadas para CUDA, como matplotlib, para trazar) .
- Guarde el
state_dict()de su modelo entrenado en un archivo.
- Cree una nueva instancia de su clase de modelo que creó en 2. y cárguela en el
state_dict()que acaba de guardar. - Realice predicciones sobre los datos de su prueba con el modelo cargado y confirme que coincidan con las predicciones del modelo original de 4.
Recurso: Consulte las plantillas de cuadernos de ejercicios y las [soluciones](https://github. com/mrdbourke/pytorch-deep-learning/tree/main/extras/solutions) en el curso GitHub.
Extracurricular¶
- Escuche [La canción no oficial del bucle de optimización de PyTorch] (https://youtu.be/Nutpusq_AFw) (para ayudar a recordar los pasos en un bucle de prueba/entrenamiento de PyTorch).
- Lea ¿Qué es realmente
torch.nn? de Jeremy Howard para obtener una comprensión más profunda de cómo funciona uno de los módulos más importantes de PyTorch. - Dedique 10 minutos a desplazarse y consultar la [hoja de referencia de la documentación de PyTorch] (https://pytorch.org/tutorials/beginner/ptcheat.html) para conocer todos los diferentes módulos de PyTorch que pueda encontrar.
- Dedique 10 minutos a leer la [documentación de carga y guardado en el sitio web de PyTorch] (https://pytorch.org/tutorials/beginner/ Saving_loading_models.html) para familiarizarse con las diferentes opciones de guardar y cargar en PyTorch.
- Dedique 1 a 2 horas a leer/ver lo siguiente para obtener una descripción general de los aspectos internos del descenso de gradiente y la retropropagación, los dos algoritmos principales que han estado trabajando en segundo plano para ayudar a que nuestro modelo aprenda.
- Página de Wikipedia para descenso de gradiente
- [Algoritmo de descenso de gradiente: una inmersión profunda] (https://towardsdatascience.com/gradient-descent-algorithm-a-deep-dive-cf04e8115f21) por Robert Kwiatkowski
- Video de descenso de gradiente, cómo aprenden las redes neuronales por 3Blue1Brown
- ¿Qué hace realmente la retropropagación? vídeo de 3Blue1Brown
- [Página de Wikipedia sobre retropropagación] (https://en.wikipedia.org/wiki/Backpropagation)