03. Visión por computadora PyTorch¶
Visión por computadora es el arte de enseñarle a ver a una computadora.
Por ejemplo, podría implicar la construcción de un modelo para clasificar si una foto es de un gato o de un perro (clasificación binaria).
O si una foto es de un gato, un perro o una gallina (clasificación multiclase).
O identificar dónde aparece un automóvil en un cuadro de video (detección de objetos).
O descubrir dónde se pueden separar los diferentes objetos de una imagen (segmentación panóptica).
 Ejemplos de problemas de visión por computadora para clasificación binaria, clasificación multiclase, detección y segmentación de objetos.
Ejemplos de problemas de visión por computadora para clasificación binaria, clasificación multiclase, detección y segmentación de objetos.
¿Dónde se utiliza la visión por computadora?¶
Si usa un teléfono inteligente, ya ha utilizado la visión por computadora.
Las aplicaciones de cámara y fotografía utilizan visión por computadora para mejorar y ordenan imágenes.
Los automóviles modernos utilizan visión por computadora para evitar otros automóviles y mantenerse dentro de las líneas de los carriles.
Los fabricantes utilizan la visión por computadora para identificar defectos en varios productos.
Las cámaras de seguridad utilizan visión por computadora para detectar posibles intrusos.
En esencia, cualquier cosa que pueda describirse en un sentido visual puede ser un posible problema de visión por computadora.
Qué vamos a cubrir¶
Aplicaremos el flujo de trabajo de PyTorch que hemos estado aprendiendo en las últimas secciones a la visión por computadora.
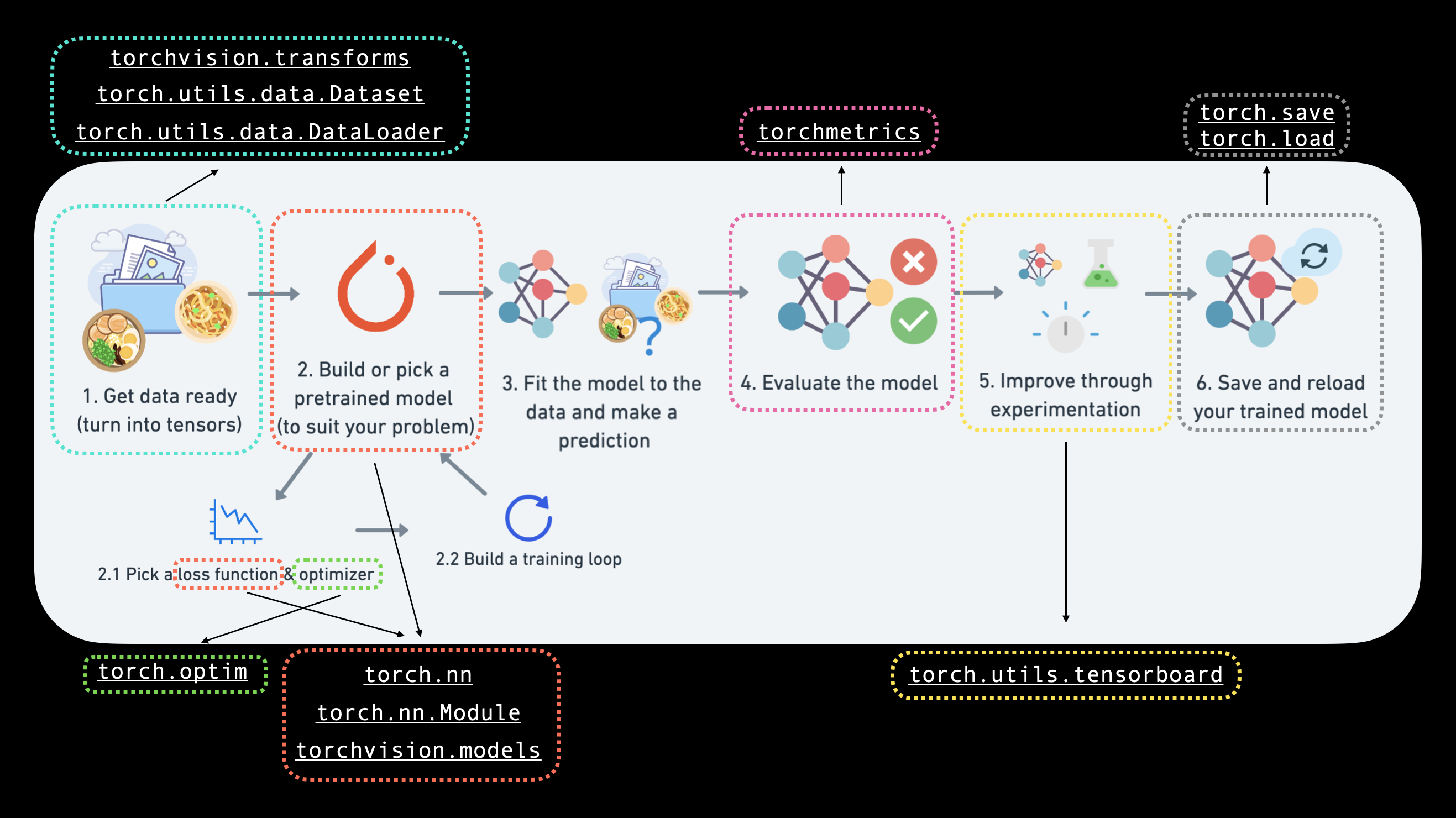
Específicamente, cubriremos:
| Tema | Contenido |
|---|---|
| 0. Bibliotecas de visión por computadora en PyTorch | PyTorch tiene un montón de bibliotecas de visión por computadora útiles integradas, echémosle un vistazo. |
| 1. Cargar datos | Para practicar la visión por computadora, comenzaremos con algunas imágenes de diferentes prendas de vestir de [FashionMNIST] (https://github.com/zalandoresearch/fashion-mnist). |
| 2. Preparar datos | Tenemos algunas imágenes, carguémoslas con un PyTorch DataLoader para que podamos usarlas con nuestro bucle de entrenamiento. |
| 3. Modelo 0: construcción de un modelo de referencia | Aquí crearemos un modelo de clasificación de múltiples clases para aprender patrones en los datos, también elegiremos una función de pérdida, un optimizador y crearemos un bucle de entrenamiento. |
| 4. Hacer predicciones y evaluar el modelo 0 | Hagamos algunas predicciones con nuestro modelo de referencia y evalúémoslas. |
| 5. Configurar código independiente del dispositivo para modelos futuros | Es una buena práctica escribir código independiente del dispositivo, así que configurémoslo. |
| 6. Modelo 1: Agregar no linealidad | Experimentar es una gran parte del aprendizaje automático. Intentemos mejorar nuestro modelo de referencia agregando capas no lineales. |
| 7. Modelo 2: Red neuronal convolucional (CNN) | Es hora de especificar la visión por computadora e introducir la poderosa arquitectura de red neuronal convolucional. |
| 8. Comparando nuestros modelos | Hemos construido tres modelos diferentes, comparémoslos. |
| 9. Evaluando nuestro mejor modelo | Hagamos algunas predicciones sobre imágenes aleatorias y evaluemos nuestro mejor modelo. |
| 10. Haciendo una matriz de confusión | Una matriz de confusión es una excelente manera de evaluar un modelo de clasificación; veamos cómo podemos crear una. |
| 11. Guardar y cargar el modelo con mejor rendimiento | Dado que es posible que queramos usar nuestro modelo para más adelante, guardémoslo y asegurémonos de que se vuelva a cargar correctamente. |
¿Dónde puedes conseguir ayuda?¶
Todos los materiales de este curso en vivo en GitHub.
Si tiene problemas, también puede hacer una pregunta en el curso página de debates de GitHub.
Y, por supuesto, está la documentación de PyTorch y los foros de desarrolladores de PyTorch, un lugar muy útil para todo lo relacionado con PyTorch.
0. Bibliotecas de visión por computadora en PyTorch¶
Antes de comenzar a escribir código, hablemos de algunas bibliotecas de visión por computadora de PyTorch que debe conocer.
| Módulo PyTorch | ¿Qué hace? |
|---|---|
torchvision |
Contiene conjuntos de datos, arquitecturas de modelos y transformaciones de imágenes que se utilizan a menudo para problemas de visión por computadora. |
torchvision.datasets |
Aquí encontrará muchos conjuntos de datos de visión por computadora de ejemplo para una variedad de problemas, desde clasificación de imágenes, detección de objetos, subtítulos de imágenes, clasificación de videos y más. También contiene una serie de clases base para crear conjuntos de datos personalizados. |
torchvision.models |
Este módulo contiene arquitecturas de modelos de visión por computadora de buen rendimiento y de uso común implementadas en PyTorch; puede usarlas con sus propios problemas. |
torchvision.transforms |
A menudo, las imágenes deben transformarse (convertirse en números/procesarse/aumentarse) antes de usarse con un modelo; las transformaciones de imágenes comunes se encuentran aquí. |
torch.utils.data.Dataset |
Clase de conjunto de datos base para PyTorch. |
torch.utils.data.DataLoader |
Crea un iterable de Python sobre un conjunto de datos (creado con torch.utils.data.Dataset). |
Nota: Las clases
torch.utils.data.Datasetytorch.utils.data.DataLoaderno son solo para visión por computadora en PyTorch, sino que son capaces de manejar muchos tipos diferentes de datos.
Ahora que hemos cubierto algunas de las bibliotecas de visión por computadora de PyTorch más importantes, importemos las dependencias relevantes.
# Importar PyTorch
import torch
from torch import nn
# Importar visión de antorcha
import torchvision
from torchvision import datasets
from torchvision.transforms import ToTensor
# Importar matplotlib para visualización
import matplotlib.pyplot as plt
# Consultar versiones
# Nota: su versión de PyTorch no debe ser inferior a 1.10.0 y la versión de torchvision no debe ser inferior a 0.11
print(f"PyTorch version: {torch.__version__}\ntorchvision version: {torchvision.__version__}")
1. Obtener un conjunto de datos¶
Para comenzar a trabajar en un problema de visión por computadora, obtengamos un conjunto de datos de visión por computadora.
Vamos a empezar con FashionMNIST.
MNIST significa Instituto Nacional Modificado de Estándares y Tecnología.
El [conjunto de datos MNIST original] (https://en.wikipedia.org/wiki/MNIST_database) contiene miles de ejemplos de dígitos escritos a mano (del 0 al 9) y se utilizó para crear modelos de visión por computadora para identificar números para los servicios postales.
FashionMNIST, creado por Zalando Research, es una configuración similar.
Excepto que contiene imágenes en escala de grises de 10 tipos diferentes de ropa.

torchvision.datasets contiene muchos conjuntos de datos de ejemplo que puedes usar para practicar la escritura de código de visión por computadora. FashionMNIST es uno de esos conjuntos de datos. Y dado que tiene 10 clases de imágenes diferentes (diferentes tipos de ropa), es un problema de clasificación de clases múltiples.
Más adelante, construiremos una red neuronal de visión por computadora para identificar los diferentes estilos de ropa en estas imágenes.
PyTorch tiene un montón de conjuntos de datos de visión por computadora comunes almacenados en "torchvision.datasets".
Incluyendo FashionMNIST en torchvision.datasets.FashionMNIST().
Para descargarlo, proporcionamos los siguientes parámetros:
root: str- ¿a qué carpeta desea descargar los datos?train: Bool- ¿Quieres dividir el entrenamiento o la prueba?descargar: Bool- ¿deben descargarse los datos?transform: torchvision.transforms: ¿qué transformaciones le gustaría realizar en los datos?target_transform: también puedes transformar los objetivos (etiquetas) si lo deseas.
Muchos otros conjuntos de datos en "torchvision" tienen estas opciones de parámetros.
# Configurar datos de entrenamiento
train_data = datasets.FashionMNIST(
root="data", # where to download data to?
train=True, # get training data
download=True, # download data if it doesn't exist on disk
transform=ToTensor(), # images come as PIL format, we want to turn into Torch tensors
target_transform=None # you can transform labels as well
)
# Configurar datos de prueba
test_data = datasets.FashionMNIST(
root="data",
train=False, # get test data
download=True,
transform=ToTensor()
)
Veamos la primera muestra de los datos de entrenamiento.
# Ver el primer ejemplo de entrenamiento
image, label = train_data[0]
image, label
1.1 Formas de entrada y salida de un modelo de visión por computadora¶
Tenemos un gran tensor de valores (la imagen) que conduce a un valor único para el objetivo (la etiqueta).
Veamos la forma de la imagen.
# ¿Cuál es la forma de la imagen?
image.shape
La forma del tensor de imagen es [1, 28, 28] o más específicamente:
[color_channels=1, alto=28, ancho=28]
Tener color_channels=1 significa que la imagen está en escala de grises.
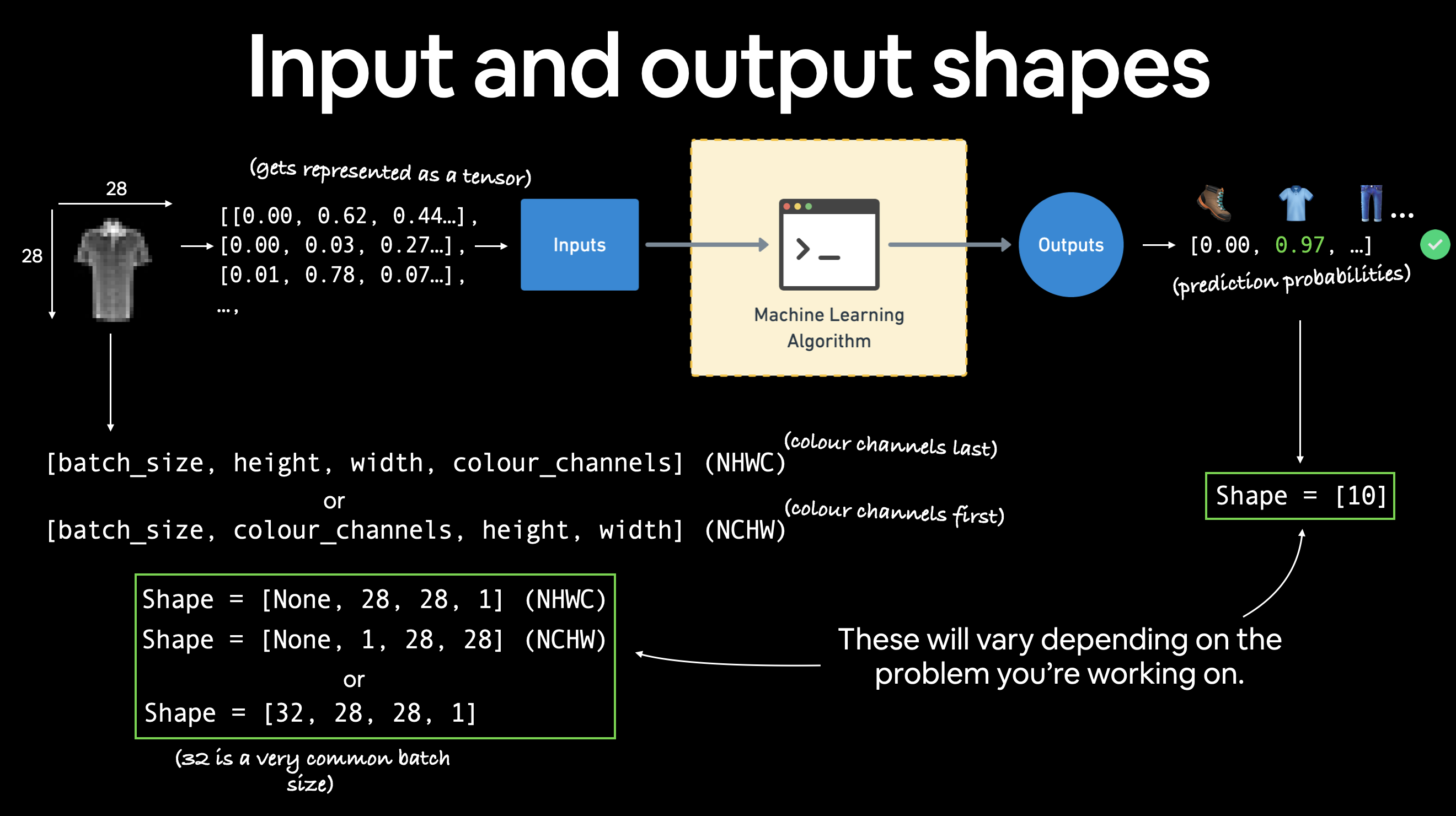 Varios problemas tendrán diversas formas de entrada y salida. Pero la premisa sigue siendo: codificar datos en números, construir un modelo para encontrar patrones en esos números, convertir esos patrones en algo significativo.
Varios problemas tendrán diversas formas de entrada y salida. Pero la premisa sigue siendo: codificar datos en números, construir un modelo para encontrar patrones en esos números, convertir esos patrones en algo significativo.
Si color_channels=3, la imagen viene en valores de píxeles para rojo, verde y azul (esto también se conoce como [modelo de color RGB] (https://en.wikipedia.org/wiki/RGB_color_model)).
El orden de nuestro tensor actual a menudo se denomina "CHW" (Canales de color, alto, ancho).
Existe un debate sobre si las imágenes deben representarse como "CHW" (canales de color primero) o "HWC" (canales de color al final).
Nota: También verá los formatos
NCHWyNHWCdondeNsignifica número de imágenes. Por ejemplo, si tiene unbatch_size=32, la forma de su tensor puede ser[32, 1, 28, 28]. Cubriremos los tamaños de lote más adelante.
PyTorch generalmente acepta NCHW (canales primero) como valor predeterminado para muchos operadores.
Sin embargo, PyTorch también explica que "NHWC" (los últimos canales) funcionan mejor y se [considera una mejor práctica] (https://pytorch.org/blog/tensor-memory-format-matters/#pytorch-best-practice).
Por ahora, dado que nuestro conjunto de datos y modelos son relativamente pequeños, esto no supondrá una gran diferencia.
Pero téngalo en cuenta cuando trabaje en conjuntos de datos de imágenes más grandes y utilice redes neuronales convolucionales (las veremos más adelante).
Veamos más formas de nuestros datos.
# ¿Cuántas muestras hay?
len(train_data.data), len(train_data.targets), len(test_data.data), len(test_data.targets)
Tenemos 60.000 muestras de entrenamiento y 10.000 muestras de prueba.
¿Qué clases hay?
Podemos encontrarlos a través del atributo .classes.
# Ver clases
class_names = train_data.classes
class_names
¡Dulce! Parece que estamos ante 10 tipos diferentes de ropa.
Debido a que estamos trabajando con 10 clases diferentes, significa que nuestro problema es clasificación de clases múltiples.
Seamos visuales.
1.2 Visualizando nuestros datos¶
import matplotlib.pyplot as plt
image, label = train_data[0]
print(f"Image shape: {image.shape}")
plt.imshow(image.squeeze()) # image shape is [1, 28, 28] (colour channels, height, width)
plt.title(label);
Podemos convertir la imagen en escala de grises usando el parámetro cmap de plt.imshow().
plt.imshow(image.squeeze(), cmap="gray")
plt.title(class_names[label]);
Hermoso, tan hermoso como lo puede ser un botín pixelado en escala de grises.
Veamos algunos más.
# Trazar más imágenes
torch.manual_seed(42)
fig = plt.figure(figsize=(9, 9))
rows, cols = 4, 4
for i in range(1, rows * cols + 1):
random_idx = torch.randint(0, len(train_data), size=[1]).item()
img, label = train_data[random_idx]
fig.add_subplot(rows, cols, i)
plt.imshow(img.squeeze(), cmap="gray")
plt.title(class_names[label])
plt.axis(False);
Hmmm, este conjunto de datos no parece demasiado estético.
Pero los principios que aprenderemos sobre cómo construir un modelo serán similares en una amplia gama de problemas de visión por computadora.
En esencia, tomar valores de píxeles y construir un modelo para encontrar patrones en ellos para usarlos en valores de píxeles futuros.
Además, incluso para este pequeño conjunto de datos (sí, incluso 60.000 imágenes en aprendizaje profundo se consideran bastante pequeñas), ¿podrías escribir un programa para clasificar cada una de ellas?
Probablemente podrías.
Pero creo que codificar un modelo en PyTorch sería más rápido.
Pregunta: ¿Crees que los datos anteriores se pueden modelar solo con líneas rectas (lineales)? ¿O crees que también necesitarías líneas no rectas (no lineales)?
2. Preparar el cargador de datos¶
Ahora tenemos un conjunto de datos listo para funcionar.
El siguiente paso es prepararlo con un torch.utils.data.DataLoader o DataLoader para corto.
El DataLoader hace lo que usted cree que podría hacer.
Ayuda a cargar datos en un modelo.
Para entrenamiento y para inferencia.
Convierte un gran "conjunto de datos" en un Python iterable de fragmentos más pequeños.
Estos fragmentos más pequeños se denominan lotes o minilotes y se pueden configurar mediante el parámetro batch_size.
¿Por qué hacer esto?
Porque es más eficiente computacionalmente.
En un mundo ideal, podría realizar el pase hacia adelante y hacia atrás a través de todos sus datos a la vez.
Pero una vez que empiezas a utilizar conjuntos de datos realmente grandes, a menos que tengas una potencia informática infinita, es más fácil dividirlos en lotes.
También le brinda a su modelo más oportunidades de mejorar.
Con minilotes (pequeñas porciones de datos), el descenso de gradiente se realiza con más frecuencia por época (una vez por minilote en lugar de una vez por época).
¿Cuál es un buen tamaño de lote?
32 es un buen lugar para comenzar para una buena cantidad de problemas.
Pero dado que este es un valor que puede establecer (un hiperparámetro), puede probar todos los tipos diferentes de valores, aunque generalmente se usan potencias de 2 con mayor frecuencia (por ejemplo, 32, 64, 128, 256, 512).
 Lote de FashionMNIST con un tamaño de lote de 32 y reproducción aleatoria activada. Se producirá un proceso de procesamiento por lotes similar para otros conjuntos de datos, pero diferirá según el tamaño del lote.
Lote de FashionMNIST con un tamaño de lote de 32 y reproducción aleatoria activada. Se producirá un proceso de procesamiento por lotes similar para otros conjuntos de datos, pero diferirá según el tamaño del lote.
Creemos DataLoader para nuestros conjuntos de entrenamiento y prueba.
from torch.utils.data import DataLoader
# Configurar el hiperparámetro de tamaño de lote
BATCH_SIZE = 32
# Convierta conjuntos de datos en iterables (lotes)
train_dataloader = DataLoader(train_data, # dataset to turn into iterable
batch_size=BATCH_SIZE, # how many samples per batch?
shuffle=True # shuffle data every epoch?
)
test_dataloader = DataLoader(test_data,
batch_size=BATCH_SIZE,
shuffle=False # don't necessarily have to shuffle the testing data
)
# Veamos lo que hemos creado.
print(f"Dataloaders: {train_dataloader, test_dataloader}")
print(f"Length of train dataloader: {len(train_dataloader)} batches of {BATCH_SIZE}")
print(f"Length of test dataloader: {len(test_dataloader)} batches of {BATCH_SIZE}")
# Mira lo que hay dentro del cargador de datos de entrenamiento
train_features_batch, train_labels_batch = next(iter(train_dataloader))
train_features_batch.shape, train_labels_batch.shape
Y podemos ver que los datos permanecen sin cambios al verificar una sola muestra.
# Mostrar una muestra
torch.manual_seed(42)
random_idx = torch.randint(0, len(train_features_batch), size=[1]).item()
img, label = train_features_batch[random_idx], train_labels_batch[random_idx]
plt.imshow(img.squeeze(), cmap="gray")
plt.title(class_names[label])
plt.axis("Off");
print(f"Image size: {img.shape}")
print(f"Label: {label}, label size: {label.shape}")
3. Modelo 0: construir un modelo de referencia¶
¡Datos cargados y preparados!
Es hora de crear un modelo de referencia subclasificando nn.Module.
Un modelo de referencia es uno de los modelos más simples que puedas imaginar.
Utiliza la línea de base como punto de partida e intenta mejorarla con modelos posteriores más complicados.
Nuestra línea base constará de dos capas nn.Linear().
Hemos hecho esto en una sección anterior, pero habrá una pequeña diferencia.
Debido a que estamos trabajando con datos de imágenes, usaremos una capa diferente para comenzar.
Y esa es la capa nn.Flatten().
nn.Flatten() comprime las dimensiones de un tensor en un solo vector.
Esto es más fácil de entender cuando lo ves.
# Crear una capa aplanada
flatten_model = nn.Flatten() # all nn modules function as a model (can do a forward pass)
# Obtenga una sola muestra
x = train_features_batch[0]
# Aplanar la muestra
output = flatten_model(x) # perform forward pass
# Imprime lo que pasó
print(f"Shape before flattening: {x.shape} -> [color_channels, height, width]")
print(f"Shape after flattening: {output.shape} -> [color_channels, height*width]")
# Intente descomentar a continuación y vea qué sucede
# imprimir(x)
# imprimir (salida)
La capa nn.Flatten() tomó nuestra forma de [color_channels, height, width] a [color_channels, height*width].
¿Por qué hacer esto?
Porque ahora hemos convertido nuestros datos de píxeles de las dimensiones de alto y ancho en un vector de características largo.
Y a las capas nn.Linear() les gusta que sus entradas estén en forma de vectores de características.
Creemos nuestro primer modelo usando nn.Flatten() como primera capa.
from torch import nn
class FashionMNISTModelV0(nn.Module):
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Flatten(), # neural networks like their inputs in vector form
nn.Linear(in_features=input_shape, out_features=hidden_units), # in_features = number of features in a data sample (784 pixels)
nn.Linear(in_features=hidden_units, out_features=output_shape)
)
def forward(self, x):
return self.layer_stack(x)
¡Maravilloso!
Tenemos una clase de modelo de referencia que podemos usar, ahora creemos una instancia de un modelo.
Necesitaremos establecer los siguientes parámetros:
input_shape=784: esta es la cantidad de funciones que tienes en el modelo; en nuestro caso, es una por cada píxel de la imagen de destino (28 píxeles de alto por 28 píxeles de ancho = 784 funciones).hidden_units=10- número de unidades/neuronas en las capas ocultas, este número puede ser el que quieras, pero para mantener el modelo pequeño comenzaremos con10.output_shape=len(class_names): dado que estamos trabajando con un problema de clasificación de clases múltiples, necesitamos una neurona de salida por clase en nuestro conjunto de datos.
Creemos una instancia de nuestro modelo y enviémosla a la CPU por ahora (pronto ejecutaremos una pequeña prueba para ejecutar model_0 en la CPU frente a un modelo similar en la GPU).
torch.manual_seed(42)
# Necesidad de configurar el modelo con parámetros de entrada
model_0 = FashionMNISTModelV0(input_shape=784, # one for every pixel (28x28)
hidden_units=10, # how many units in the hiden layer
output_shape=len(class_names) # one for every class
)
model_0.to("cpu") # keep model on CPU to begin with
3.1 Pérdida de configuración, optimizador y métricas de evaluación¶
Dado que estamos trabajando en un problema de clasificación, introduzcamos nuestro [script helper_functions.py] (https://github.com/mrdbourke/pytorch-deep-learning/blob/main/helper_functions.py) y posteriormente el accuracy_fn() lo definimos en [cuaderno 02] (https://www.learnpytorch.io/02_pytorch_classification/).
Nota: En lugar de importar y utilizar nuestra propia función de precisión o métrica(s) de evaluación, puede importar varias métricas de evaluación desde el paquete TorchMetrics.
import requests
from pathlib import Path
# Descargue funciones auxiliares del repositorio de Learn PyTorch (si aún no las ha descargado)
if Path("helper_functions.py").is_file():
print("helper_functions.py already exists, skipping download")
else:
print("Downloading helper_functions.py")
# Note: you need the "raw" GitHub URL for this to work
request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/helper_functions.py")
with open("helper_functions.py", "wb") as f:
f.write(request.content)
# Métrica de precisión de importación
from helper_functions import accuracy_fn # Note: could also use torchmetrics.Accuracy(task = 'multiclass', num_classes=len(class_names)).to(device)
# Función de pérdida de configuración y optimizador.
loss_fn = nn.CrossEntropyLoss() # this is also called "criterion"/"cost function" in some places
optimizer = torch.optim.SGD(params=model_0.parameters(), lr=0.1)
3.2 Creando una función para cronometrar nuestros experimentos¶
¡Función de pérdida y optimizador listos!
Es hora de empezar a entrenar un modelo.
Pero ¿qué tal si hacemos un pequeño experimento mientras entrenamos?
Quiero decir, creemos una función de sincronización para medir el tiempo que le toma a nuestro modelo entrenarse en la CPU en comparación con usar una GPU.
Entrenaremos este modelo en la CPU pero el siguiente en la GPU y veremos qué sucede.
Nuestra función de sincronización importará la función timeit.default_timer() del [módulo timeit](https ://docs.python.org/3/library/timeit.html).
from timeit import default_timer as timer
def print_train_time(start: float, end: float, device: torch.device = None):
"""Prints difference between start and end time.
Args:
start (float): Start time of computation (preferred in timeit format).
end (float): End time of computation.
device ([type], optional): Device that compute is running on. Defaults to None.
Returns:
float: time between start and end in seconds (higher is longer).
"""
total_time = end - start
print(f"Train time on {device}: {total_time:.3f} seconds")
return total_time
3.3 Crear un bucle de entrenamiento y entrenar un modelo en lotes de datos¶
¡Hermoso!
Parece que tenemos todas las piezas del rompecabezas listas para funcionar: un temporizador, una función de pérdida, un optimizador, un modelo y, lo más importante, algunos datos.
Ahora creemos un bucle de entrenamiento y un bucle de prueba para entrenar y evaluar nuestro modelo.
Usaremos los mismos pasos que en los cuadernos anteriores, aunque como nuestros datos ahora están en forma de lotes, agregaremos otro bucle para recorrer nuestros lotes de datos.
Nuestros lotes de datos están contenidos en nuestros DataLoaders, train_dataloader y test_dataloader para las divisiones de datos de entrenamiento y prueba respectivamente.
Un lote son muestras BATCH_SIZE de X (características) e y (etiquetas), ya que estamos usando BATCH_SIZE=32, nuestros lotes tienen 32 muestras de imágenes y objetivos.
Y dado que estamos calculando lotes de datos, nuestras métricas de pérdida y evaluación se calcularán por lote en lugar de hacerlo en todo el conjunto de datos.
Esto significa que tendremos que dividir nuestros valores de pérdida y precisión por la cantidad de lotes en el cargador de datos respectivo de cada conjunto de datos.
Repasémoslo:
- Recorre épocas.
- Recorra los lotes de entrenamiento, realice los pasos de entrenamiento, calcule la pérdida del tren por lote.
- Recorra los lotes de prueba, realice los pasos de prueba, calcule la pérdida de prueba por lote.
- Imprime lo que está pasando.
- Calcula el tiempo (por diversión).
Unos cuantos pasos, pero...
...en caso de duda, codifíquelo.
# Importar tqdm para la barra de progreso
from tqdm.auto import tqdm
# Establecer la semilla y poner en marcha el cronómetro
torch.manual_seed(42)
train_time_start_on_cpu = timer()
# Establece el número de épocas (lo mantendremos pequeño para tiempos de entrenamiento más rápidos)
epochs = 3
# Crear un ciclo de entrenamiento y prueba
for epoch in tqdm(range(epochs)):
print(f"Epoch: {epoch}\n-------")
### Training
train_loss = 0
# Add a loop to loop through training batches
for batch, (X, y) in enumerate(train_dataloader):
model_0.train()
# 1. Forward pass
y_pred = model_0(X)
# 2. Calculate loss (per batch)
loss = loss_fn(y_pred, y)
train_loss += loss # accumulatively add up the loss per epoch
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Optimizer step
optimizer.step()
# Print out how many samples have been seen
if batch % 400 == 0:
print(f"Looked at {batch * len(X)}/{len(train_dataloader.dataset)} samples")
# Divide total train loss by length of train dataloader (average loss per batch per epoch)
train_loss /= len(train_dataloader)
### Testing
# Setup variables for accumulatively adding up loss and accuracy
test_loss, test_acc = 0, 0
model_0.eval()
with torch.inference_mode():
for X, y in test_dataloader:
# 1. Forward pass
test_pred = model_0(X)
# 2. Calculate loss (accumatively)
test_loss += loss_fn(test_pred, y) # accumulatively add up the loss per epoch
# 3. Calculate accuracy (preds need to be same as y_true)
test_acc += accuracy_fn(y_true=y, y_pred=test_pred.argmax(dim=1))
# Calculations on test metrics need to happen inside torch.inference_mode()
# Divide total test loss by length of test dataloader (per batch)
test_loss /= len(test_dataloader)
# Divide total accuracy by length of test dataloader (per batch)
test_acc /= len(test_dataloader)
## Print out what's happening
print(f"\nTrain loss: {train_loss:.5f} | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%\n")
# Calcular el tiempo de entrenamiento.
train_time_end_on_cpu = timer()
total_train_time_model_0 = print_train_time(start=train_time_start_on_cpu,
end=train_time_end_on_cpu,
device=str(next(model_0.parameters()).device))
¡Lindo! Parece que a nuestro modelo de referencia le fue bastante bien.
Tampoco tomó mucho tiempo entrenar, incluso solo en la CPU. Me pregunto si se acelerará en la GPU.
Escribamos un código para evaluar nuestro modelo.
4. Haga predicciones y obtenga resultados del Modelo 0¶
Dado que vamos a construir algunos modelos, es una buena idea escribir código para evaluarlos todos de manera similar.
Es decir, creemos una función que admita un modelo entrenado, un DataLoader, una función de pérdida y una función de precisión.
La función utilizará el modelo para hacer predicciones sobre los datos en el DataLoader y luego podremos evaluar esas predicciones usando la función de pérdida y la función de precisión.
torch.manual_seed(42)
def eval_model(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
accuracy_fn):
"""Returns a dictionary containing the results of model predicting on data_loader.
Args:
model (torch.nn.Module): A PyTorch model capable of making predictions on data_loader.
data_loader (torch.utils.data.DataLoader): The target dataset to predict on.
loss_fn (torch.nn.Module): The loss function of model.
accuracy_fn: An accuracy function to compare the models predictions to the truth labels.
Returns:
(dict): Results of model making predictions on data_loader.
"""
loss, acc = 0, 0
model.eval()
with torch.inference_mode():
for X, y in data_loader:
# Make predictions with the model
y_pred = model(X)
# Accumulate the loss and accuracy values per batch
loss += loss_fn(y_pred, y)
acc += accuracy_fn(y_true=y,
y_pred=y_pred.argmax(dim=1)) # For accuracy, need the prediction labels (logits -> pred_prob -> pred_labels)
# Scale loss and acc to find the average loss/acc per batch
loss /= len(data_loader)
acc /= len(data_loader)
return {"model_name": model.__class__.__name__, # only works when model was created with a class
"model_loss": loss.item(),
"model_acc": acc}
# Calcular los resultados del modelo 0 en el conjunto de datos de prueba
model_0_results = eval_model(model=model_0, data_loader=test_dataloader,
loss_fn=loss_fn, accuracy_fn=accuracy_fn
)
model_0_results
¡Luciendo bien!
Podemos utilizar este diccionario para comparar los resultados del modelo de referencia con otros modelos más adelante.
5. Configurar código independiente del dispositivo (para usar una GPU, si la hay)¶
Hemos visto cuánto tiempo lleva entrenar mi modelo PyTorch en 60.000 muestras en la CPU.
Nota: El tiempo de entrenamiento del modelo depende del hardware utilizado. Generalmente, más procesadores significan un entrenamiento más rápido y los modelos más pequeños en conjuntos de datos más pequeños a menudo se entrenarán más rápido que los modelos y conjuntos de datos grandes.
Ahora configuremos algo de código independiente del dispositivo para que nuestros modelos y datos se ejecuten en GPU si está disponible.
Si está ejecutando esta computadora portátil en Google Colab y aún no tiene una GPU encendida, ahora es el momento de encender una a través de Runtime -> Cambiar tipo de tiempo de ejecución -> Acelerador de hardware -> GPU. Si hace esto, es probable que su tiempo de ejecución se reinicie y tendrá que ejecutar todas las celdas anteriores yendo a "Tiempo de ejecución -> Ejecutar antes".
# Configurar código independiente del dispositivo
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
device
¡Hermoso!
Construyamos otro modelo.
6. Modelo 1: construcción de un modelo mejor con no linealidad¶
Aprendimos sobre [el poder de la no linealidad en el cuaderno 02] (https://www.learnpytorch.io/02_pytorch_classification/#6-the-missing-piece-non-linearity).
Viendo los datos con los que hemos estado trabajando, ¿crees que necesitan funciones no lineales?
Y recuerda, lineal significa recto y no lineal significa no recto.
Vamos a averiguar.
Lo haremos recreando un modelo similar al anterior, excepto que esta vez colocaremos funciones no lineales (nn.ReLU()) entre cada capa lineal.
# Crear un modelo con capas lineales y no lineales.
class FashionMNISTModelV1(nn.Module):
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Flatten(), # flatten inputs into single vector
nn.Linear(in_features=input_shape, out_features=hidden_units),
nn.ReLU(),
nn.Linear(in_features=hidden_units, out_features=output_shape),
nn.ReLU()
)
def forward(self, x: torch.Tensor):
return self.layer_stack(x)
Eso se ve bien.
Ahora vamos a crear una instancia con la misma configuración que usamos antes.
Necesitaremos input_shape=784 (igual al número de características de nuestros datos de imagen), hidden_units=10 (comenzando poco a poco y lo mismo que nuestro modelo de referencia) y output_shape=len(class_names) (una salida unidad por clase).
Nota: Observe cómo mantuvimos la mayoría de las configuraciones de nuestro modelo iguales excepto por un cambio: agregar capas no lineales. Esta es una práctica estándar para ejecutar una serie de experimentos de aprendizaje automático, cambiar una cosa y ver qué sucede, luego hacerlo una y otra vez.
torch.manual_seed(42)
model_1 = FashionMNISTModelV1(input_shape=784, # number of input features
hidden_units=10,
output_shape=len(class_names) # number of output classes desired
).to(device) # send model to GPU if it's available
next(model_1.parameters()).device # check model device
6.1 Pérdida de configuración, optimizador y métricas de evaluación¶
Como de costumbre, configuraremos una función de pérdida, un optimizador y una métrica de evaluación (podríamos hacer múltiples métricas de evaluación, pero por ahora nos limitaremos a la precisión).
from helper_functions import accuracy_fn
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model_1.parameters(),
lr=0.1)
6.2 Funcionalización de bucles de entrenamiento y prueba¶
Hasta ahora hemos estado escribiendo bucles de entrenamiento y prueba una y otra vez.
Escribámoslos nuevamente pero esta vez los pondremos en funciones para que puedan ser llamados una y otra vez.
Y debido a que ahora estamos usando código independiente del dispositivo, nos aseguraremos de llamar a .to(device) en nuestros tensores de función (X) y objetivo (y).
Para el ciclo de entrenamiento crearemos una función llamada train_step() que toma un modelo, un DataLoader, una función de pérdida y un optimizador.
El ciclo de prueba será similar pero se llamará test_step() y aceptará un modelo, un DataLoader, una función de pérdida y una función de evaluación.
Nota: Dado que estas son funciones, puedes personalizarlas como quieras. Lo que estamos creando aquí pueden considerarse funciones básicas de entrenamiento y prueba para nuestro caso de uso de clasificación específico.
def train_step(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
optimizer: torch.optim.Optimizer,
accuracy_fn,
device: torch.device = device):
train_loss, train_acc = 0, 0
model.to(device)
for batch, (X, y) in enumerate(data_loader):
# Send data to GPU
X, y = X.to(device), y.to(device)
# 1. Forward pass
y_pred = model(X)
# 2. Calculate loss
loss = loss_fn(y_pred, y)
train_loss += loss
train_acc += accuracy_fn(y_true=y,
y_pred=y_pred.argmax(dim=1)) # Go from logits -> pred labels
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Optimizer step
optimizer.step()
# Calculate loss and accuracy per epoch and print out what's happening
train_loss /= len(data_loader)
train_acc /= len(data_loader)
print(f"Train loss: {train_loss:.5f} | Train accuracy: {train_acc:.2f}%")
def test_step(data_loader: torch.utils.data.DataLoader,
model: torch.nn.Module,
loss_fn: torch.nn.Module,
accuracy_fn,
device: torch.device = device):
test_loss, test_acc = 0, 0
model.to(device)
model.eval() # put model in eval mode
# Turn on inference context manager
with torch.inference_mode():
for X, y in data_loader:
# Send data to GPU
X, y = X.to(device), y.to(device)
# 1. Forward pass
test_pred = model(X)
# 2. Calculate loss and accuracy
test_loss += loss_fn(test_pred, y)
test_acc += accuracy_fn(y_true=y,
y_pred=test_pred.argmax(dim=1) # Go from logits -> pred labels
)
# Adjust metrics and print out
test_loss /= len(data_loader)
test_acc /= len(data_loader)
print(f"Test loss: {test_loss:.5f} | Test accuracy: {test_acc:.2f}%\n")
¡Guau!
Ahora que tenemos algunas funciones para entrenar y probar nuestro modelo, ejecutémoslas.
Lo haremos dentro de otro bucle para cada época.
De esa manera, para cada época vamos a realizar un paso de entrenamiento y de prueba.
Nota: Puede personalizar la frecuencia con la que realiza un paso de prueba. A veces la gente los hace cada cinco o diez épocas o, en nuestro caso, cada época.
También cronometremos las cosas para ver cuánto tiempo tarda nuestro código en ejecutarse en la GPU.
torch.manual_seed(42)
# Medir el tiempo
from timeit import default_timer as timer
train_time_start_on_gpu = timer()
epochs = 3
for epoch in tqdm(range(epochs)):
print(f"Epoch: {epoch}\n---------")
train_step(data_loader=train_dataloader,
model=model_1,
loss_fn=loss_fn,
optimizer=optimizer,
accuracy_fn=accuracy_fn
)
test_step(data_loader=test_dataloader,
model=model_1,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn
)
train_time_end_on_gpu = timer()
total_train_time_model_1 = print_train_time(start=train_time_start_on_gpu,
end=train_time_end_on_gpu,
device=device)
¡Excelente!
¿Nuestro modelo se entrenó pero el tiempo de entrenamiento tomó más tiempo?
Nota: El tiempo de entrenamiento en CUDA versus CPU dependerá en gran medida de la calidad de la CPU/GPU que estés usando. Siga leyendo para obtener una respuesta más explicada.
Pregunta: "Usé una GPU pero mi modelo no se entrenó más rápido, ¿a qué se debe?"
Respuesta: Bueno, una razón podría ser que su conjunto de datos y su modelo son tan pequeños (como el conjunto de datos y el modelo con el que estamos trabajando) que los beneficios de usar una GPU se ven superados por el tiempo que realmente lleva la transferencia. los datos allí.
Existe un pequeño cuello de botella entre la copia de datos de la memoria de la CPU (predeterminada) a la memoria de la GPU.
Entonces, para modelos y conjuntos de datos más pequeños, la CPU podría ser el lugar óptimo para calcular.
Pero para conjuntos de datos y modelos más grandes, la velocidad de computación que la GPU puede ofrecer generalmente supera con creces el costo de llevar los datos allí.
Sin embargo, esto depende en gran medida del hardware que estás utilizando. Con la práctica, te acostumbrarás a cuál es el mejor lugar para entrenar a tus modelos.
Evaluemos nuestro model_1 entrenado usando nuestra función eval_model() y veamos cómo fue.
torch.manual_seed(42)
# Nota: Esto generará un error debido a que `eval_model()` no utiliza código independiente del dispositivo.
model_1_results = eval_model(model=model_1,
data_loader=test_dataloader,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn)
model_1_results
¡Oh, no!
Parece que nuestra función eval_model() falla con:
RuntimeError: Se esperaba que todos los tensores estuvieran en el mismo dispositivo, pero encontré al menos dos dispositivos, cuda:0 y cpu. (al verificar el argumento mat1 en el método wrapper_addmm)
Es porque hemos configurado nuestros datos y modelo para usar código independiente del dispositivo, pero no nuestra función de evaluación.
¿Qué tal si solucionamos eso pasando un parámetro de dispositivo de destino a nuestra función eval_model()?
Luego intentaremos calcular los resultados nuevamente.
# Mover valores al dispositivo
torch.manual_seed(42)
def eval_model(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
accuracy_fn,
device: torch.device = device):
"""Evaluates a given model on a given dataset.
Args:
model (torch.nn.Module): A PyTorch model capable of making predictions on data_loader.
data_loader (torch.utils.data.DataLoader): The target dataset to predict on.
loss_fn (torch.nn.Module): The loss function of model.
accuracy_fn: An accuracy function to compare the models predictions to the truth labels.
device (str, optional): Target device to compute on. Defaults to device.
Returns:
(dict): Results of model making predictions on data_loader.
"""
loss, acc = 0, 0
model.eval()
with torch.inference_mode():
for X, y in data_loader:
# Send data to the target device
X, y = X.to(device), y.to(device)
y_pred = model(X)
loss += loss_fn(y_pred, y)
acc += accuracy_fn(y_true=y, y_pred=y_pred.argmax(dim=1))
# Scale loss and acc
loss /= len(data_loader)
acc /= len(data_loader)
return {"model_name": model.__class__.__name__, # only works when model was created with a class
"model_loss": loss.item(),
"model_acc": acc}
# Calcule los resultados del modelo 1 con código independiente del dispositivo
model_1_results = eval_model(model=model_1, data_loader=test_dataloader,
loss_fn=loss_fn, accuracy_fn=accuracy_fn,
device=device
)
model_1_results
# Verificar resultados de referencia
model_0_results
Vaya, en este caso, parece que agregar no linealidades a nuestro modelo hizo que funcionara peor que la línea base.
Eso es algo a tener en cuenta en el aprendizaje automático: a veces lo que pensaba que debería funcionar no funciona.
Y luego lo que pensabas que podría no funcionar, funciona.
Es en parte ciencia, en parte arte.
Por lo que parece, parece que nuestro modelo se está sobreajustando en los datos de entrenamiento.
El sobreajuste significa que nuestro modelo está aprendiendo bien los datos de entrenamiento, pero esos patrones no se generalizan a los datos de prueba.
Dos de los principales para solucionar el sobreajuste incluyen:
- Usar un modelo más pequeño o diferente (algunos modelos se ajustan mejor a ciertos tipos de datos que otros).
- Usar un conjunto de datos más grande (cuantos más datos, más posibilidades tiene un modelo de aprender patrones generalizables).
Hay más, pero lo dejaré como un desafío para que lo explores.
Intente buscar en línea "formas de evitar el sobreajuste en el aprendizaje automático" y vea qué aparece.
Mientras tanto, echemos un vistazo al número 1: usar un modelo diferente.
7. Modelo 2: Construcción de una red neuronal convolucional (CNN)¶
Muy bien, es hora de dar un paso más.
Es hora de crear una [red neuronal convolucional] (https://en.wikipedia.org/wiki/Convolutional_neural_network) (CNN o ConvNet).
Las CNN son conocidas por sus capacidades para encontrar patrones en datos visuales.
Y dado que estamos tratando con datos visuales, veamos si el uso de un modelo CNN puede mejorar nuestra línea de base.
El modelo de CNN que vamos a utilizar se conoce como TinyVGG del sitio web [CNN Explicador] (https://poloclub.github.io/cnn-explainer/).
Sigue la estructura típica de una red neuronal convolucional:
Capa de entrada -> [Capa convolucional -> capa de activación -> capa de agrupación] -> Capa de salida
Donde el contenido de [Capa convolucional -> capa de activación -> capa de agrupación] se puede ampliar y repetir varias veces, según los requisitos.
¿Qué modelo debo usar?¶
Pregunta: Espera, dices que las CNN son buenas para imágenes, ¿hay algún otro tipo de modelo que deba tener en cuenta?
Buena pregunta.
Esta tabla es una buena guía general sobre qué modelo utilizar (aunque hay excepciones).
| Tipo de problema | Modelo a utilizar (generalmente) | Ejemplo de código |
|---|---|---|
| Datos estructurados (hojas de cálculo Excel, datos de filas y columnas) | Modelos mejorados con gradiente, bosques aleatorios, XGBoost | sklearn.ensemble, [biblioteca XGBoost](https://xgboost.readthedocs.io/en/ estable/) |
| Datos no estructurados (imágenes, audio, idioma) | Redes Neuronales Convolucionales, Transformadores | torchvision.models, Transformadores HuggingFace |
Nota: La tabla anterior es solo como referencia; el modelo que termine usando dependerá en gran medida del problema en el que esté trabajando y de las limitaciones que tenga (cantidad de datos, requisitos de latencia).
Basta de hablar de modelos, ahora construyamos una CNN que replique el modelo en el [sitio web de CNN Explicador] (https://poloclub.github.io/cnn-explainer/).
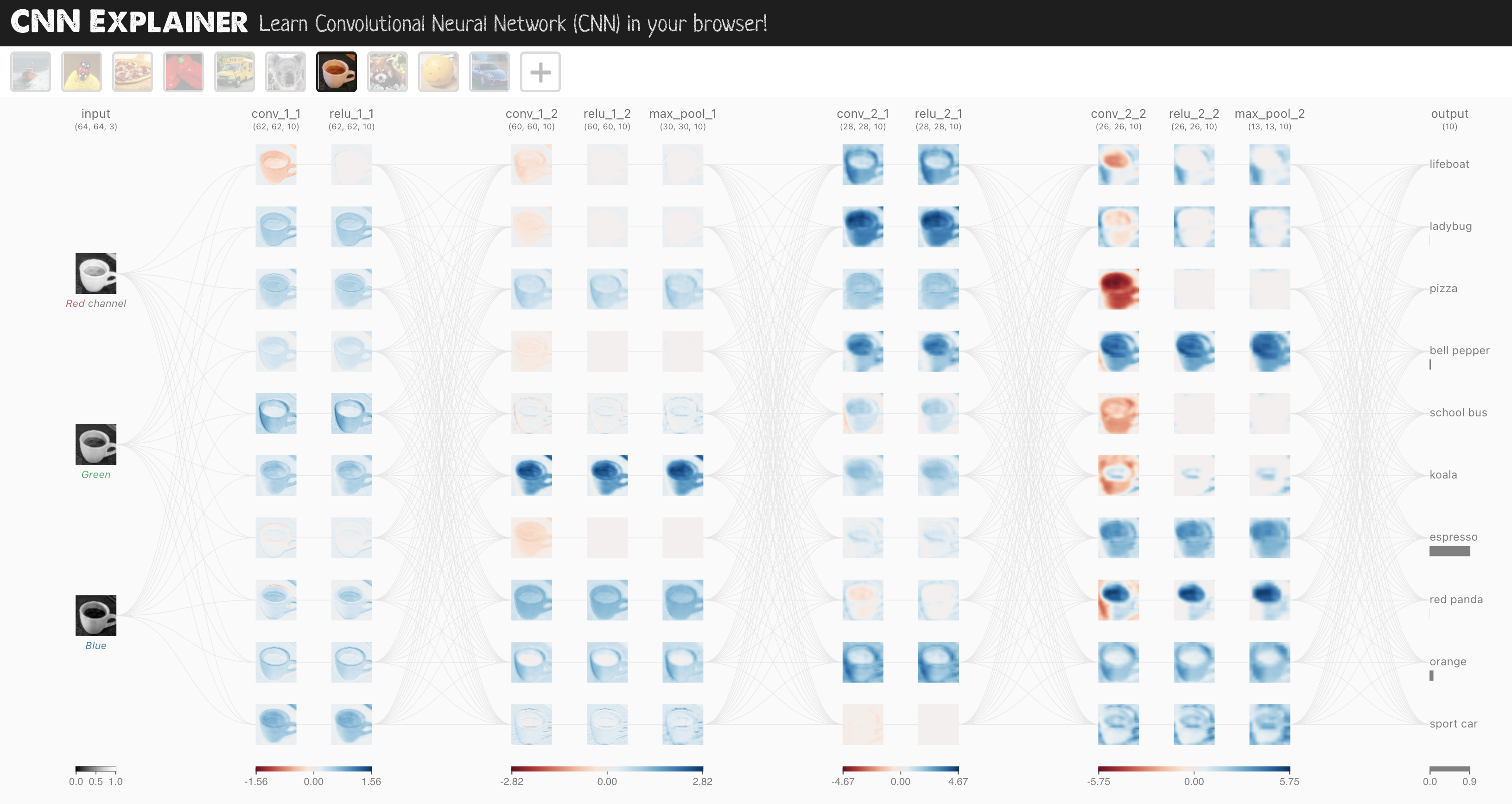
Para hacerlo, aprovecharemos nn.Conv2d() y nn.MaxPool2d() capas de torch.nn.
# Crear una red neuronal convolucional
class FashionMNISTModelV2(nn.Module):
"""
Model architecture copying TinyVGG from:
https://poloclub.github.io/cnn-explainer/
"""
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.block_1 = nn.Sequential(
nn.Conv2d(in_channels=input_shape,
out_channels=hidden_units,
kernel_size=3, # how big is the square that's going over the image?
stride=1, # default
padding=1),# options = "valid" (no padding) or "same" (output has same shape as input) or int for specific number
nn.ReLU(),
nn.Conv2d(in_channels=hidden_units,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,
stride=2) # default stride value is same as kernel_size
)
self.block_2 = nn.Sequential(
nn.Conv2d(hidden_units, hidden_units, 3, padding=1),
nn.ReLU(),
nn.Conv2d(hidden_units, hidden_units, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
# Where did this in_features shape come from?
# It's because each layer of our network compresses and changes the shape of our inputs data.
nn.Linear(in_features=hidden_units*7*7,
out_features=output_shape)
)
def forward(self, x: torch.Tensor):
x = self.block_1(x)
# print(x.shape)
x = self.block_2(x)
# print(x.shape)
x = self.classifier(x)
# print(x.shape)
return x
torch.manual_seed(42)
model_2 = FashionMNISTModelV2(input_shape=1,
hidden_units=10,
output_shape=len(class_names)).to(device)
model_2
¡Lindo!
¡Nuestro modelo más grande hasta el momento!
Lo que hemos hecho es una práctica común en el aprendizaje automático.
Encuentre una arquitectura modelo en algún lugar y replíquela con código.
7.1 Paso a paso por nn.Conv2d()¶
Podríamos comenzar a usar nuestro modelo anterior y ver qué sucede, pero primero veamos las dos nuevas capas que hemos agregado:
nn.Conv2d(), también conocida como capa convolucional.nn.MaxPool2d(), también conocida como capa de agrupación máxima.
Pregunta: ¿Qué significa "2d" en
nn.Conv2d()?El 2d es para datos bidimensionales. Como en, nuestras imágenes tienen dos dimensiones: alto y ancho. Sí, hay una dimensión del canal de color, pero cada una de las dimensiones del canal de color también tiene dos dimensiones: alto y ancho.
Para otros datos dimensionales (como 1D para texto o 3D para objetos 3D) también están
nn.Conv1d()ynn.Conv3d().
Para probar las capas, creemos algunos datos de juguetes similares a los datos utilizados en CNN Explicador.
torch.manual_seed(42)
# Cree un lote de muestra de números aleatorios con el mismo tamaño que el lote de imágenes
images = torch.randn(size=(32, 3, 64, 64)) # [batch_size, color_channels, height, width]
test_image = images[0] # get a single image for testing
print(f"Image batch shape: {images.shape} -> [batch_size, color_channels, height, width]")
print(f"Single image shape: {test_image.shape} -> [color_channels, height, width]")
print(f"Single image pixel values:\n{test_image}")
Creemos un ejemplo nn.Conv2d() con varios parámetros:
in_channels(int) - Número de canales en la imagen de entrada.out_channels(int) - Número de canales producidos por la convolución.kernel_size(int o tupla): tamaño del kernel/filtro convolutivo.stride(int o tuple, opcional): qué tan grande es el paso que da el núcleo convolutivo a la vez. Predeterminado: 1.padding(int, tuple, str): relleno agregado a los cuatro lados de la entrada. Predeterminado: 0.
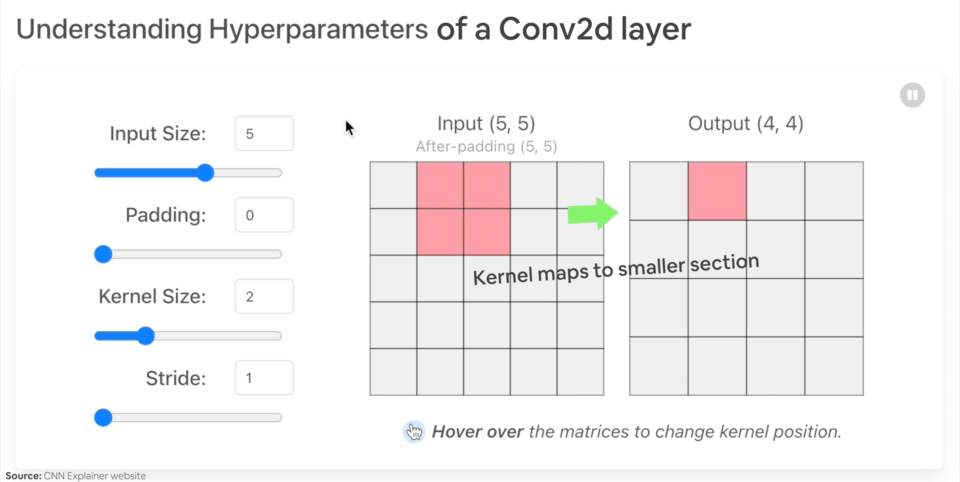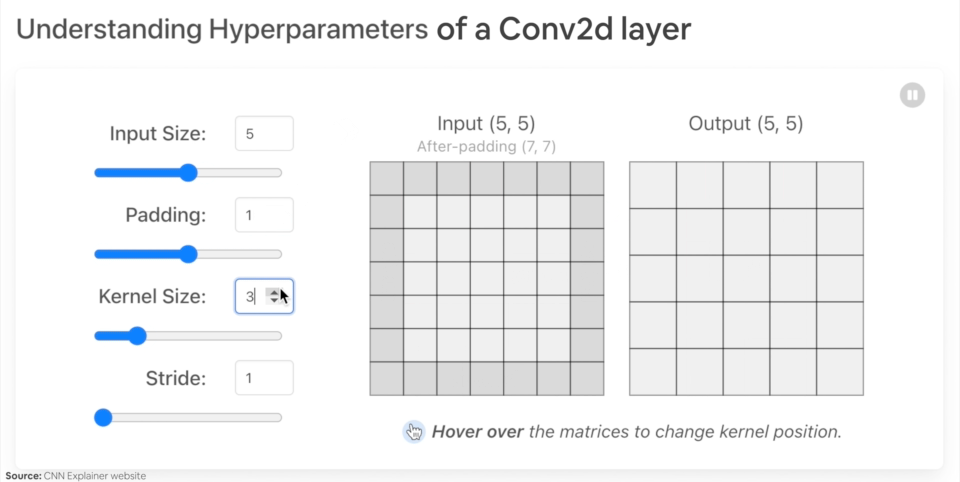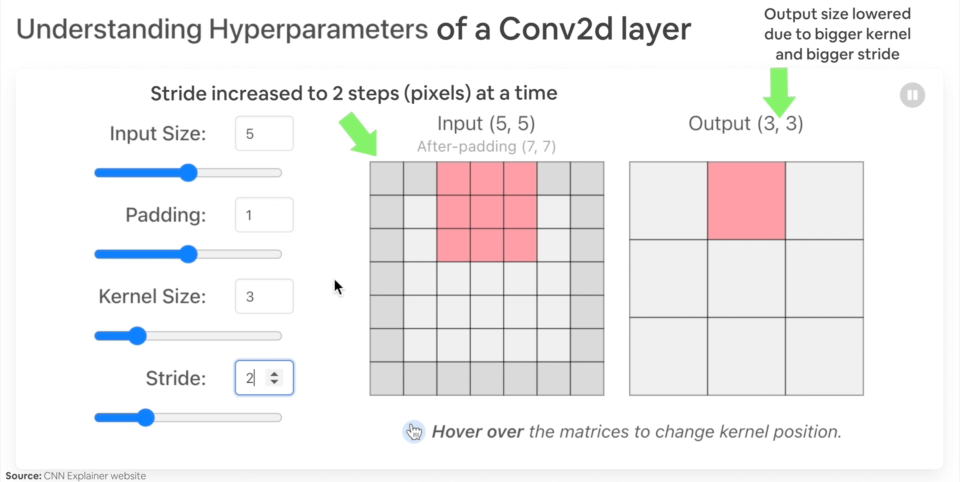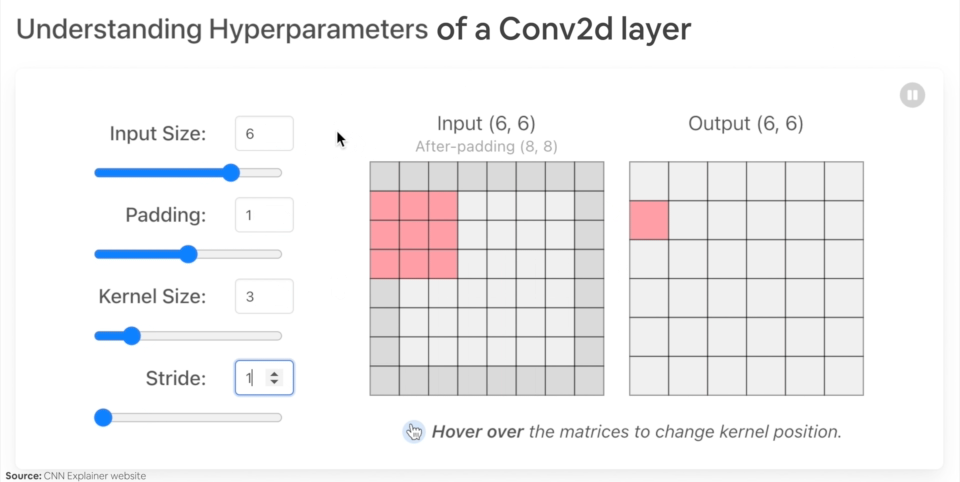
Ejemplo de lo que sucede cuando cambias los hiperparámetros de una capa nn.Conv2d().
torch.manual_seed(42)
# Crea una capa convolucional con las mismas dimensiones que TinyVGG
# (intente cambiar cualquiera de los parámetros y vea qué sucede)
conv_layer = nn.Conv2d(in_channels=3,
out_channels=10,
kernel_size=3,
stride=1,
padding=0) # also try using "valid" or "same" here
# Pasar los datos a través de la capa convolucional.
conv_layer(test_image) # Note: If running PyTorch <1.11.0, this will error because of shape issues (nn.Conv.2d() expects a 4d tensor as input)
Si intentamos pasar una sola imagen, obtenemos un error de falta de coincidencia de forma:
RuntimeError: Se esperaba una entrada de 4 dimensiones para un peso de 4 dimensiones [10, 3, 3, 3], pero en su lugar obtuve una entrada de 3 dimensiones de tamaño [3, 64, 64]Nota: Si está ejecutando PyTorch 1.11.0+, este error no ocurrirá.
Esto se debe a que nuestra capa nn.Conv2d() espera un tensor de 4 dimensiones como entrada con tamaño (N, C, H, W) o [batch_size, color_channels, height, width].
En este momento, nuestra imagen única test_image solo tiene la forma [color_channels, height, width] o [3, 64, 64].
Podemos solucionar este problema para una sola imagen usando test_image.unsqueeze(dim=0) para agregar una dimensión adicional para N.
# Agregue una dimensión adicional a la imagen de prueba
test_image.unsqueeze(dim=0).shape
# Pase la imagen de prueba con dimensión adicional a través de conv_layer
conv_layer(test_image.unsqueeze(dim=0)).shape
Hmm, observe lo que sucede con nuestra forma (la misma forma que la primera capa de TinyVGG en [CNN Explicador] (https://poloclub.github.io/cnn-explainer/)), obtenemos diferentes tamaños de canal, así como diferentes tamaños de píxeles.
¿Qué pasa si cambiamos los valores de conv_layer?
torch.manual_seed(42)
# Crea una nueva conv_layer con diferentes valores (intenta configurarlos como quieras)
conv_layer_2 = nn.Conv2d(in_channels=3, # same number of color channels as our input image
out_channels=10,
kernel_size=(5, 5), # kernel is usually a square so a tuple also works
stride=2,
padding=0)
# Pase una sola imagen a través del nuevo conv_layer_2 (esto llama al método forward() de nn.Conv2d() en la entrada)
conv_layer_2(test_image.unsqueeze(dim=0)).shape
Vaya, tenemos otro cambio de forma.
Ahora nuestra imagen tiene la forma [1, 10, 30, 30] (será diferente si usa valores diferentes) o [batch_size=1, color_channels=10, height=30, width=30].
¿Que está pasando aqui?
Detrás de escena, nuestro nn.Conv2d() está comprimiendo la información almacenada en la imagen.
Para ello, realiza operaciones en la entrada (nuestra imagen de prueba) con sus parámetros internos.
El objetivo de esto es similar al de todas las demás redes neuronales que hemos estado construyendo.
Los datos entran y las capas intentan actualizar sus parámetros internos (patrones) para reducir la función de pérdida gracias a la ayuda del optimizador.
La única diferencia es cómo las diferentes capas calculan sus actualizaciones de parámetros o, en términos de PyTorch, la operación presente en el método forward() de la capa.
Si revisamos nuestro conv_layer_2.state_dict() encontraremos una configuración de peso y sesgo similar a la que hemos visto antes.
# Consulte los parámetros internos de conv_layer_2
print(conv_layer_2.state_dict())
¡Mira eso! Un montón de números aleatorios para un tensor de peso y sesgo.
Las formas de estos son manipuladas por las entradas que le pasamos a nn.Conv2d() cuando lo configuramos.
Echemos un vistazo.
# Obtenga formas de tensores de peso y sesgo dentro de conv_layer_2
print(f"conv_layer_2 weight shape: \n{conv_layer_2.weight.shape} -> [out_channels=10, in_channels=3, kernel_size=5, kernel_size=5]")
print(f"\nconv_layer_2 bias shape: \n{conv_layer_2.bias.shape} -> [out_channels=10]")
Pregunta: ¿Qué debemos configurar los parámetros de nuestras capas
nn.Conv2d()?Esa es buena. Pero al igual que muchas otras cosas en el aprendizaje automático, los valores de estos no están escritos en piedra (y recuerden, debido a que estos valores son los que podemos establecer nosotros mismos, se los conoce como "hiperparámetros").
La mejor manera de averiguarlo es probar diferentes valores y ver cómo afectan el rendimiento de su modelo.
O mejor aún, busque un ejemplo funcional sobre un problema similar al suyo (como lo hemos hecho con TinyVGG) y cópielo.
Estamos trabajando con una capa diferente a la que hemos visto antes.
Pero la premisa sigue siendo la misma: empezar con números aleatorios y actualizarlos para representar mejor los datos.
7.2 Paso a paso por nn.MaxPool2d()¶
Ahora veamos qué sucede cuando movemos datos a través de nn.MaxPool2d().
# Imprima la forma de la imagen original sin y con dimensión sin comprimir
print(f"Test image original shape: {test_image.shape}")
print(f"Test image with unsqueezed dimension: {test_image.unsqueeze(dim=0).shape}")
# Cree una capa de muestra nn.MaxPoo2d()
max_pool_layer = nn.MaxPool2d(kernel_size=2)
# Pasar datos solo a través de conv_layer
test_image_through_conv = conv_layer(test_image.unsqueeze(dim=0))
print(f"Shape after going through conv_layer(): {test_image_through_conv.shape}")
# Pasar datos a través de la capa de grupo máximo
test_image_through_conv_and_max_pool = max_pool_layer(test_image_through_conv)
print(f"Shape after going through conv_layer() and max_pool_layer(): {test_image_through_conv_and_max_pool.shape}")
Observe el cambio en las formas de lo que sucede dentro y fuera de una capa nn.MaxPool2d().
El kernel_size de la capa nn.MaxPool2d() afectará el tamaño de la forma de salida.
En nuestro caso, la forma se reduce a la mitad de una imagen de "62x62" a una imagen de "31x31".
Veamos cómo funciona con un tensor más pequeño.
torch.manual_seed(42)
# Crea un tensor aleatorio con un número de dimensiones similar a nuestras imágenes.
random_tensor = torch.randn(size=(1, 1, 2, 2))
print(f"Random tensor:\n{random_tensor}")
print(f"Random tensor shape: {random_tensor.shape}")
# Crear una capa de grupo máxima
max_pool_layer = nn.MaxPool2d(kernel_size=2) # see what happens when you change the kernel_size value
# Pase el tensor aleatorio a través de la capa de grupo máxima
max_pool_tensor = max_pool_layer(random_tensor)
print(f"\nMax pool tensor:\n{max_pool_tensor} <- this is the maximum value from random_tensor")
print(f"Max pool tensor shape: {max_pool_tensor.shape}")
Observe las dos dimensiones finales entre random_tensor y max_pool_tensor, van de [2, 2] a [1, 1].
En esencia, se reducen a la mitad.
Y el cambio sería diferente para diferentes valores de kernel_size para nn.MaxPool2d().
Observe también que el valor sobrante en max_pool_tensor es el valor máximo de random_tensor.
¿Que esta pasando aqui?
Ésta es otra pieza importante del rompecabezas de las redes neuronales.
Esencialmente, cada capa de una red neuronal intenta comprimir datos desde un espacio de dimensiones superiores a un espacio de dimensiones inferiores.
En otras palabras, tome muchos números (datos sin procesar) y aprenda patrones en esos números, patrones que sean predictivos y al mismo tiempo sean más pequeños en tamaño que los valores originales.
Desde una perspectiva de inteligencia artificial, se podría considerar el objetivo completo de una red neuronal de comprimir información.

Esto significa que, desde el punto de vista de una red neuronal, la inteligencia es compresión.
Esta es la idea del uso de una capa nn.MaxPool2d(): tomar el valor máximo de una parte de un tensor y ignorar el resto.
En esencia, reducir la dimensionalidad de un tensor y al mismo tiempo conservar una (con suerte) parte significativa de la información.
Es la misma historia para una capa nn.Conv2d().
Excepto que en lugar de simplemente tomar el máximo, nn.Conv2d() realiza una operación convolucional en los datos (vea esto en acción en la página web de CNN Explicador).
Ejercicio: ¿Qué crees que hace la capa
nn.AvgPool2d()? Intente hacer un tensor aleatorio como hicimos arriba y páselo. Verifique las formas de entrada y salida, así como los valores de entrada y salida.
Extracurricular: Busque "redes neuronales convolucionales más comunes", ¿qué arquitecturas encuentra? ¿Alguno de ellos está contenido en la biblioteca
torchvision.models? ¿Qué crees que podrías hacer con estos?
7.3 Configurar una función de pérdida y un optimizador para model_2¶
Hemos recorrido suficientes capas en nuestra primera CNN.
Pero recuerde, si algo aún no está claro, intente empezar poco a poco.
Elija una sola capa de un modelo, pase algunos datos a través de ella y vea qué sucede.
¡Ahora es el momento de seguir adelante y ponerse a entrenar!
Configuremos una función de pérdida y un optimizador.
Usaremos las funciones como antes, nn.CrossEntropyLoss() como función de pérdida (ya que estamos trabajando con datos de clasificación de múltiples clases).
Y torch.optim.SGD() como optimizador para optimizar model_2.parameters() con una tasa de aprendizaje de 0.1.
# Pérdida de configuración y optimizador.
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model_2.parameters(),
lr=0.1)
7.4 Entrenamiento y prueba model_2 usando nuestras funciones de entrenamiento y prueba¶
¡Pérdida y optimizador listos!
Es hora de entrenar y probar.
Usaremos nuestras funciones train_step() y test_step() que creamos antes.
También mediremos el tiempo para compararlo con nuestros otros modelos.
torch.manual_seed(42)
# Medir el tiempo
from timeit import default_timer as timer
train_time_start_model_2 = timer()
# Modelo de entrenamiento y prueba.
epochs = 3
for epoch in tqdm(range(epochs)):
print(f"Epoch: {epoch}\n---------")
train_step(data_loader=train_dataloader,
model=model_2,
loss_fn=loss_fn,
optimizer=optimizer,
accuracy_fn=accuracy_fn,
device=device
)
test_step(data_loader=test_dataloader,
model=model_2,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn,
device=device
)
train_time_end_model_2 = timer()
total_train_time_model_2 = print_train_time(start=train_time_start_model_2,
end=train_time_end_model_2,
device=device)
¡Guau! Parece que las capas convolucional y de agrupación máxima ayudaron a mejorar un poco el rendimiento.
Evaluemos los resultados de model_2 con nuestra función eval_model().
# Obtener resultados del modelo_2
model_2_results = eval_model(
model=model_2,
data_loader=test_dataloader,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn
)
model_2_results
8. Compare los resultados del modelo y el tiempo de entrenamiento¶
Hemos entrenado tres modelos diferentes.
model_0: nuestro modelo de referencia con dos capasnn.Linear().model_1: la misma configuración que nuestro modelo de referencia, excepto con capasnn.ReLU()entre las capasnn.Linear().model_2: nuestro primer modelo de CNN que imita la arquitectura TinyVGG en el sitio web CNN Explicador.
Esta es una práctica habitual en el aprendizaje automático.
Construya múltiples modelos y realice múltiples experimentos de entrenamiento para ver cuál funciona mejor.
Combinemos los diccionarios de resultados de nuestros modelos en un DataFrame y averigüémoslo.
import pandas as pd
compare_results = pd.DataFrame([model_0_results, model_1_results, model_2_results])
compare_results
¡Lindo!
También podemos agregar los valores del tiempo de entrenamiento.
# Añadir tiempos de entrenamiento a la comparación de resultados
compare_results["training_time"] = [total_train_time_model_0,
total_train_time_model_1,
total_train_time_model_2]
compare_results
Parece que nuestro modelo CNN (FashionMNISTModelV2) tuvo el mejor rendimiento (pérdida más baja, mayor precisión) pero tuvo el tiempo de entrenamiento más largo.
Y nuestro modelo de referencia (FashionMNISTModelV0) funcionó mejor que model_1 (FashionMNISTModelV1).
Compensación rendimiento-velocidad¶
Algo a tener en cuenta en el aprendizaje automático es la compensación rendimiento-velocidad.
Generalmente, se obtiene un mejor rendimiento con un modelo más grande y complejo (como hicimos con model_2).
Sin embargo, este aumento del rendimiento a menudo se produce sacrificando la velocidad de entrenamiento y la velocidad de inferencia.
Nota: Los tiempos de capacitación que obtenga dependerán en gran medida del hardware que utilice.
Generalmente, cuantos más núcleos de CPU tenga, más rápido se entrenarán sus modelos en la CPU. Y similar para las GPU.
El hardware más nuevo (en términos de antigüedad) también suele entrenar modelos más rápido debido a la incorporación de avances tecnológicos.
¿Qué tal si nos volvemos visuales?
# Visualice los resultados de nuestro modelo.
compare_results.set_index("model_name")["model_acc"].plot(kind="barh")
plt.xlabel("accuracy (%)")
plt.ylabel("model");
9. Realice y evalúe predicciones aleatorias con el mejor modelo.¶
Muy bien, hemos comparado nuestros modelos entre sí, evaluemos más a fondo nuestro modelo de mejor rendimiento, "model_2".
Para hacerlo, creemos una función make_predictions() donde podemos pasar el modelo y algunos datos para que prediga.
def make_predictions(model: torch.nn.Module, data: list, device: torch.device = device):
pred_probs = []
model.eval()
with torch.inference_mode():
for sample in data:
# Prepare sample
sample = torch.unsqueeze(sample, dim=0).to(device) # Add an extra dimension and send sample to device
# Forward pass (model outputs raw logit)
pred_logit = model(sample)
# Get prediction probability (logit -> prediction probability)
pred_prob = torch.softmax(pred_logit.squeeze(), dim=0) # note: perform softmax on the "logits" dimension, not "batch" dimension (in this case we have a batch size of 1, so can perform on dim=0)
# Get pred_prob off GPU for further calculations
pred_probs.append(pred_prob.cpu())
# Stack the pred_probs to turn list into a tensor
return torch.stack(pred_probs)
import random
random.seed(42)
test_samples = []
test_labels = []
for sample, label in random.sample(list(test_data), k=9):
test_samples.append(sample)
test_labels.append(label)
# Ver la forma y la etiqueta de la primera muestra de prueba
print(f"Test sample image shape: {test_samples[0].shape}\nTest sample label: {test_labels[0]} ({class_names[test_labels[0]]})")
# Haga predicciones sobre muestras de prueba con el modelo 2
pred_probs= make_predictions(model=model_2,
data=test_samples)
# Ver la lista de las dos primeras probabilidades de predicción
pred_probs[:2]
Y ahora podemos usar nuestra función make_predictions() para predecir en test_samples.
# Haga predicciones sobre muestras de prueba con el modelo 2
pred_probs= make_predictions(model=model_2,
data=test_samples)
# Ver la lista de las dos primeras probabilidades de predicción
pred_probs[:2]
¡Excelente!
Y ahora podemos pasar de probabilidades de predicción a etiquetas de predicción tomando el torch.argmax() de la salida de la función de activación torch.softmax().
# Convierta las probabilidades de predicción en etiquetas de predicción tomando argmax()
pred_classes = pred_probs.argmax(dim=1)
pred_classes
# ¿Nuestras predicciones tienen la misma forma que nuestras etiquetas de prueba?
test_labels, pred_classes
Ahora nuestras clases previstas tienen el mismo formato que nuestras etiquetas de prueba, podemos comparar.
Dado que estamos tratando con datos de imágenes, seamos fieles al lema del explorador de datos.
"¡Visualiza, visualiza, visualiza!"
# Predicciones de la trama
plt.figure(figsize=(9, 9))
nrows = 3
ncols = 3
for i, sample in enumerate(test_samples):
# Create a subplot
plt.subplot(nrows, ncols, i+1)
# Plot the target image
plt.imshow(sample.squeeze(), cmap="gray")
# Find the prediction label (in text form, e.g. "Sandal")
pred_label = class_names[pred_classes[i]]
# Get the truth label (in text form, e.g. "T-shirt")
truth_label = class_names[test_labels[i]]
# Create the title text of the plot
title_text = f"Pred: {pred_label} | Truth: {truth_label}"
# Check for equality and change title colour accordingly
if pred_label == truth_label:
plt.title(title_text, fontsize=10, c="g") # green text if correct
else:
plt.title(title_text, fontsize=10, c="r") # red text if wrong
plt.axis(False);
Bueno, bueno, bueno, ¿no se ve bien?
¡Nada mal para un par de docenas de líneas de código PyTorch!
10. Hacer una matriz de confusión para una evaluación de predicción adicional¶
Hay muchas métricas de evaluación diferentes que podemos usar para problemas de clasificación.
Uno de los más visuales es una matriz de confusión.
Una matriz de confusión le muestra dónde se confundió su modelo de clasificación entre predicciones y etiquetas verdaderas.
Para crear una matriz de confusión, seguiremos tres pasos:
- Haga predicciones con nuestro modelo entrenado,
model_2(una matriz de confusión compara las predicciones con etiquetas verdaderas). - Haga una matriz de confusión usando
torchmetrics.ConfusionMatrix. - Trace la matriz de confusión usando
mlxtend.plotting.plot_confusion_matrix().
Comencemos haciendo predicciones con nuestro modelo entrenado.
# Importar tqdm para la barra de progreso
from tqdm.auto import tqdm
# 1.Hacer predicciones con un modelo entrenado.
y_preds = []
model_2.eval()
with torch.inference_mode():
for X, y in tqdm(test_dataloader, desc="Making predictions"):
# Send data and targets to target device
X, y = X.to(device), y.to(device)
# Do the forward pass
y_logit = model_2(X)
# Turn predictions from logits -> prediction probabilities -> predictions labels
y_pred = torch.softmax(y_logit, dim=1).argmax(dim=1) # note: perform softmax on the "logits" dimension, not "batch" dimension (in this case we have a batch size of 32, so can perform on dim=1)
# Put predictions on CPU for evaluation
y_preds.append(y_pred.cpu())
# Concatenar lista de predicciones en un tensor
y_pred_tensor = torch.cat(y_preds)
¡Maravilloso!
Ahora que tenemos predicciones, veamos los pasos 2 y 3:
2. Haga una matriz de confusión usando torchmetrics.ConfusionMatrix.
3. Trace la matriz de confusión usando mlxtend.plotting.plot_confusion_matrix().
Primero necesitaremos asegurarnos de tener instalados torchmetrics y mlxtend (estas dos bibliotecas nos ayudarán a crear y visualizar una matriz de confusión).
Nota: Si está utilizando Google Colab, la versión predeterminada de
mlxtendinstalada es 0.14.0 (a partir de marzo de 2022); sin embargo, para los parámetros de la funciónplot_confusion_matrix()Como uso, necesitamos 0.19.0 o superior.
# Vea si existe torchmetrics, si no, instálelo
try:
import torchmetrics, mlxtend
print(f"mlxtend version: {mlxtend.__version__}")
assert int(mlxtend.__version__.split(".")[1]) >= 19, "mlxtend verison should be 0.19.0 or higher"
except:
!pip install -q torchmetrics -U mlxtend # <- Note: If you're using Google Colab, this may require restarting the runtime
import torchmetrics, mlxtend
print(f"mlxtend version: {mlxtend.__version__}")
Para trazar la matriz de confusión, debemos asegurarnos de tener una versión mlxtend de 0.19.0 o superior.
# Importar versión actualizada de mlxtend
import mlxtend
print(mlxtend.__version__)
assert int(mlxtend.__version__.split(".")[1]) >= 19 # should be version 0.19.0 or higher
torchmetrics y mlxtend instalados, ¡hagamos una matriz de confusión!
Primero crearemos una instancia torchmetrics.ConfusionMatrix diciéndole con cuántas clases estamos tratando configurando num_classes=len(class_names).
Luego crearemos una matriz de confusión (en formato tensorial) pasando a nuestra instancia las predicciones de nuestro modelo (preds=y_pred_tensor) y los objetivos (target=test_data.targets).
Finalmente podemos trazar nuestra matriz de configuración usando la función plot_confusion_matrix() de mlxtend.plotting.
from torchmetrics import ConfusionMatrix
from mlxtend.plotting import plot_confusion_matrix
# 2. Configure una instancia de matriz de confusión y compare las predicciones con los objetivos.
confmat = ConfusionMatrix(num_classes=len(class_names), task='multiclass')
confmat_tensor = confmat(preds=y_pred_tensor,
target=test_data.targets)
# 3. Traza la matriz de confusión
fig, ax = plot_confusion_matrix(
conf_mat=confmat_tensor.numpy(), # matplotlib likes working with NumPy
class_names=class_names, # turn the row and column labels into class names
figsize=(10, 7)
);
¡Guau! ¿No se ve bien?
Podemos ver que nuestro modelo funciona bastante bien ya que la mayoría de los cuadrados oscuros están en la diagonal desde la parte superior izquierda hasta la inferior derecha (y el modelo ideal solo tendrá valores en estos cuadrados y 0 en el resto).
El modelo se "confunde" más en clases que son similares, por ejemplo, prediciendo "Pullover" para imágenes que en realidad están etiquetadas como "Camisa".
Y lo mismo para predecir "Camisa" para clases que en realidad están etiquetadas como "Camiseta/top".
Este tipo de información suele ser más útil que una única métrica de precisión porque indica al usuario dónde un modelo está haciendo las cosas mal.
También da pistas de por qué el modelo puede estar haciendo ciertas cosas mal.
Es comprensible que el modelo a veces prediga "Camisa" para imágenes etiquetadas como "Camiseta/top".
Podemos utilizar este tipo de información para inspeccionar más a fondo nuestros modelos y datos y ver cómo podrían mejorarse.
Ejercicio: Utilice el
model_2entrenado para hacer predicciones en el conjunto de datos de prueba FashionMNIST. Luego, traza algunas predicciones en las que el modelo se equivocó junto con cuál debería haber sido la etiqueta de la imagen. Después de visualizar estas predicciones, ¿crees que se trata más de un error de modelado o de un error de datos? Por ejemplo, ¿podría funcionar mejor el modelo o las etiquetas de los datos están demasiado cerca entre sí (por ejemplo, una etiqueta de "Camisa" está demasiado cerca de "Camiseta/top")?
11. Guarde y cargue el modelo con mejor rendimiento¶
Terminemos esta sección guardando y cargando en nuestro modelo de mejor rendimiento.
Recuerde del [cuaderno 01] (https://www.learnpytorch.io/01_pytorch_workflow/#5-served-and-loading-a-pytorch-model) que podemos guardar y cargar un modelo de PyTorch usando una combinación de:
torch.save: una función para guardar un modelo PyTorch completo o elstate_dict()de un modelo.torch.load: una función para cargar en un objeto PyTorch guardado.torch.nn.Module.load_state_dict()- una función para cargar unstate_dict()guardado en una instancia de modelo existente.
Puede ver más de estos tres en la [documentación de modelos de carga y guardado de PyTorch] (https://pytorch.org/tutorials/beginner/ Saving_loading_models.html).
Por ahora, guardemos el state_dict() de nuestro model_2, luego volvamos a cargarlo y evaluémoslo para asegurarnos de que el guardado y la carga se realizaron correctamente.
from pathlib import Path
# Cree el directorio de modelos (si aún no existe), consulte: https://docs.python.org/3/library/pathlib.html#pathlib.Path.mkdir
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, # create parent directories if needed
exist_ok=True # if models directory already exists, don't error
)
# Crear ruta para guardar el modelo
MODEL_NAME = "03_pytorch_computer_vision_model_2.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
# Guarde el dictado del estado del modelo
print(f"Saving model to: {MODEL_SAVE_PATH}")
torch.save(obj=model_2.state_dict(), # only saving the state_dict() only saves the learned parameters
f=MODEL_SAVE_PATH)
Ahora que tenemos un modelo guardado state_dict() podemos volver a cargarlo usando una combinación de load_state_dict() y torch.load().
Como estamos usando load_state_dict(), necesitaremos crear una nueva instancia de FashionMNISTModelV2() con los mismos parámetros de entrada que nuestro modelo guardado state_dict().
# Cree una nueva instancia de FashionMNISTModelV2 (la misma clase que nuestro state_dict() guardado)
# Nota: al cargar el modelo se producirá un error si las formas aquí no son las mismas que las de la versión guardada.
loaded_model_2 = FashionMNISTModelV2(input_shape=1,
hidden_units=10, # try changing this to 128 and seeing what happens
output_shape=10)
# Cargar en el state_dict() guardado
loaded_model_2.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
# Enviar modelo a GPU
loaded_model_2 = loaded_model_2.to(device)
Y ahora que tenemos un modelo cargado, podemos evaluarlo con eval_model() para asegurarnos de que sus parámetros funcionen de manera similar a model_2 antes de guardarlo.
# Evaluar modelo cargado
torch.manual_seed(42)
loaded_model_2_results = eval_model(
model=loaded_model_2,
data_loader=test_dataloader,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn
)
loaded_model_2_results
¿Estos resultados tienen el mismo aspecto que model_2_results?
model_2_results
Podemos averiguar si dos tensores están cerca uno del otro usando torch.isclose() y pasando un nivel de tolerancia de cercanía a través de los parámetros atol (tolerancia absoluta) y rtol (tolerancia relativa).
Si los resultados de nuestro modelo son similares, la salida de torch.isclose() debería ser verdadera.
# Comprueba si los resultados están cerca uno del otro (si están muy lejos puede haber un error)
torch.isclose(torch.tensor(model_2_results["model_loss"]),
torch.tensor(loaded_model_2_results["model_loss"]),
atol=1e-08, # absolute tolerance
rtol=0.0001) # relative tolerance
Ejercicios¶
Todos los ejercicios se centran en practicar el código de las secciones anteriores.
Debería poder completarlos haciendo referencia a cada sección o siguiendo los recursos vinculados.
Todos los ejercicios deben completarse utilizando código independiente del dispositivo.
Recursos:
- Cuaderno de plantilla de ejercicios para 03
- Cuaderno de soluciones de ejemplo para 03 (pruebe los ejercicios antes de mirar esto)
- ¿Cuáles son las 3 áreas de la industria donde se utiliza actualmente la visión por computadora?
- Busque "qué es el sobreajuste en el aprendizaje automático" y escriba una oración sobre lo que encuentre.
- Busca "formas de prevenir el sobreajuste en el aprendizaje automático", escribe 3 de las cosas que encuentres y una oración sobre cada una. Nota: hay muchos de estos, así que no te preocupes demasiado por todos, simplemente elige 3 y comienza con ellos.
- Dedique 20 minutos a leer y hacer clic en el [sitio web de CNN Explicador] (https://poloclub.github.io/cnn-explainer/).
- Cargue su propia imagen de ejemplo usando el botón "cargar" y vea qué sucede en cada capa de una CNN a medida que su imagen la atraviesa.
- Cargue el tren
torchvision.datasets.MNIST()y pruebe los conjuntos de datos. - Visualice al menos 5 muestras diferentes del conjunto de datos de entrenamiento MNIST.
- Convierta el tren MNIST y los conjuntos de datos de prueba en cargadores de datos usando
torch.utils.data.DataLoader, establezcabatch_size=32. - Recrea el
model_2usado en este cuaderno (el mismo modelo del [sitio web de CNN Explicador] (https://poloclub.github.io/cnn-explainer/), también conocido como TinyVGG) capaz de ajustarse al conjunto de datos MNIST. . - Entrene el modelo que creó en el ejercicio 8. en CPU y GPU y vea cuánto tiempo lleva cada uno.
- Haga predicciones utilizando su modelo entrenado y visualice al menos 5 de ellas comparando la predicción con la etiqueta objetivo.
- Traza una matriz de confusión comparando las predicciones de tu modelo con las etiquetas de verdad.
- Cree un tensor aleatorio de forma
[1, 3, 64, 64]y páselo a través de una capann.Conv2d()con varias configuraciones de hiperparámetros (pueden ser cualquier configuración que elija), ¿qué nota? ¿Si el parámetrokernel_sizesube y baja? - Utilice un modelo similar al
model_2entrenado de este cuaderno para hacer predicciones en la prueba [torchvision.datasets.FashionMNIST](https://pytorch.org/vision/main/generated/torchvision.datasets.FashionMNIST .html) conjunto de datos.- Luego, traza algunas predicciones en las que el modelo se equivocó junto con cuál debería haber sido la etiqueta de la imagen.
- Después de visualizar estas predicciones, ¿crees que se trata más de un error de modelado o de un error de datos?
- Como en, ¿podría funcionar mejor el modelo o las etiquetas de los datos están demasiado cerca entre sí (por ejemplo, una etiqueta de "Camisa" está demasiado cerca de "Camiseta/top")?
Extracurricular¶
- Ver: conferencia Introducción del MIT a la visión informática profunda. Esto le dará una gran intuición detrás de las redes neuronales convolucionales.
- Dedique 10 minutos a hacer clic en las diferentes opciones de la [biblioteca de visión de PyTorch] (https://pytorch.org/vision/stable/index.html), ¿qué diferentes módulos están disponibles?
- Busque "redes neuronales convolucionales más comunes", ¿qué arquitecturas encuentra? ¿Alguno de ellos está contenido en la biblioteca
torchvision.models? ¿Qué crees que podrías hacer con estos? - Para obtener una gran cantidad de modelos de visión por computadora de PyTorch previamente entrenados, así como muchas extensiones diferentes de las funcionalidades de visión por computadora de PyTorch, consulte la [biblioteca de modelos de imágenes de PyTorch
timm] (https://github.com/rwightman/pytorch-image-models /) (Modelos de imágenes de antorcha) de Ross Wightman.