07. Seguimiento del experimento de PyTorch¶
Nota: Este cuaderno utiliza la nueva [API de soporte multipeso de
torchvision(disponible entorchvisionv0.13+)](https://pytorch.org/blog/introtaining-torchvision-new -api-soporte-multi-peso/).
Hemos entrenado a unos cuantos modelos en el camino hacia la creación de FoodVision Mini (un modelo de clasificación de imágenes para clasificar imágenes de pizza, bistec o sushi).
Y hasta ahora los hemos rastreado a través de diccionarios de Python.
O simplemente compararlos según las impresiones métricas durante el entrenamiento.
¿Qué pasaría si quisieras ejecutar una docena (o más) de modelos diferentes a la vez?
Seguramente hay una mejor manera...
Hay.
Seguimiento del experimento.
Y dado que el seguimiento de experimentos es tan importante e integral para el aprendizaje automático, puede considerar este cuaderno como su primer proyecto importante.
Bienvenido al Proyecto Milestone 1: Seguimiento del mini experimento de FoodVision.
Responderemos la pregunta: ¿cómo hago un seguimiento de mis experimentos de aprendizaje automático?
¿Qué es el seguimiento de experimentos?¶
El aprendizaje automático y el aprendizaje profundo son muy experimentales.
Tendrás que ponerte tu boina de artista/gorro de chef para cocinar muchos modelos diferentes.
Y hay que ponerse la bata de científico para seguir los resultados de diversas combinaciones de datos, arquitecturas de modelos y regímenes de entrenamiento.
Ahí es donde entra en juego el seguimiento de experimentos.
Si está ejecutando muchos experimentos diferentes, el seguimiento de experimentos le ayudará a descubrir qué funciona y qué no.
¿Por qué realizar un seguimiento de los experimentos?¶
Si sólo está ejecutando un puñado de modelos (como lo hemos hecho hasta ahora), podría estar bien simplemente realizar un seguimiento de sus resultados en impresiones y algunos diccionarios.
Sin embargo, a medida que la cantidad de experimentos que realiza comienza a aumentar, esta forma ingenua de seguimiento podría salirse de control.
Entonces, si sigues el lema de los profesionales del aprendizaje automático de ¡experimenta, experimenta, experimenta!, querrás una forma de rastrearlos.
Después de crear algunos modelos y realizar un seguimiento de sus resultados, comenzarás a notar lo rápido que se puede salir de control.
Diferentes formas de realizar un seguimiento de los experimentos de aprendizaje automático¶
Hay tantas formas diferentes de realizar un seguimiento de los experimentos de aprendizaje automático como experimentos para ejecutar.
Esta tabla cubre algunos.
| Método | Configuración | Ventajas | Desventajas | Costo |
|---|---|---|---|---|
| Diccionarios Python, archivos CSV, impresiones | Ninguno | Fácil de configurar, se ejecuta en Python puro | Es difícil realizar un seguimiento de un gran número de experimentos | Gratis |
| TensorBoard | Mínimo, instale tensorboard |
Las extensiones integradas en PyTorch, ampliamente reconocidas y utilizadas, se escalan fácilmente. | La experiencia del usuario no es tan agradable como la de otras opciones. | Gratis |
| Seguimiento de experimentos de pesos y sesgos | Mínimo, instale wandb, cree una cuenta |
Increíble experiencia de usuario, hacer públicos los experimentos, rastrear casi cualquier cosa. | Requiere recursos externos fuera de PyTorch. | Gratis para uso personal |
| MLFlow | Mínimo, instale mlflow e inicie el seguimiento |
Gestión del ciclo de vida de MLOps totalmente de código abierto, muchas integraciones. | Es un poco más difícil configurar un servidor de seguimiento remoto que otros servicios. | Gratis |

Varios lugares y técnicas que puede utilizar para realizar un seguimiento de sus experimentos de aprendizaje automático. Nota: Hay varias otras opciones similares a Weights & Biases y opciones de código abierto similares a MLflow, pero las omití por brevedad. Puede encontrar más información buscando "seguimiento de experimentos de aprendizaje automático".
Qué vamos a cubrir¶
Realizaremos varios experimentos de modelado diferentes con varios niveles de datos, tamaño del modelo y tiempo de entrenamiento para intentar mejorar FoodVision Mini.
Y debido a su estrecha integración con PyTorch y su uso generalizado, este cuaderno se centra en el uso de TensorBoard para realizar un seguimiento de nuestros experimentos.
Sin embargo, los principios que vamos a cubrir son similares en todas las demás herramientas para el seguimiento de experimentos.
| Tema | Contenido |
|---|---|
| 0. Obteniendo configuración | Hemos escrito bastante código útil en las últimas secciones, descarguémoslo y asegurémonos de poder usarlo nuevamente. |
| 1. Obtener datos | Obtengamos el conjunto de datos de clasificación de imágenes de pizza, bistec y sushi que hemos estado usando para intentar mejorar los resultados de nuestro modelo FoodVision Mini. |
| 2. Crear conjuntos de datos y cargadores de datos | Usaremos el script data_setup.py que escribimos en el capítulo 05. PyTorch se vuelve modular para configurar nuestros DataLoaders. |
| 3. Obtenga y personalice un modelo previamente entrenado | Al igual que en la última sección, 06. PyTorch Transfer Learning, descargaremos un modelo previamente entrenado de torchvision.models y lo personalizaremos según nuestro propio problema. |
| 4. Modelo de tren y resultados de vía | Veamos cómo es entrenar y rastrear los resultados del entrenamiento de un solo modelo usando TensorBoard. |
| 5. Vea los resultados de nuestro modelo en TensorBoard | Anteriormente visualizamos las curvas de pérdida de nuestro modelo con una función auxiliar, ahora veamos cómo se ven en TensorBoard. |
| 6. Creando una función auxiliar para rastrear experimentos | Si vamos a seguir el lema del practicante de aprendizaje automático de ¡experimentar, experimentar, experimentar!, lo mejor será que creemos una función que nos ayude a guardar los resultados de nuestro experimento de modelado. |
| 7. Configuración de una serie de experimentos de modelado | En lugar de ejecutar experimentos uno por uno, ¿qué tal si escribimos código para ejecutar varios experimentos a la vez, con diferentes modelos, diferentes cantidades de datos y diferentes tiempos de entrenamiento? |
| 8. Ver experimentos de modelado en TensorBoard | En esta etapa habremos realizado ocho experimentos de modelado de una sola vez, bastante para realizar un seguimiento; veamos cómo se ven sus resultados en TensorBoard. |
| 9. Cargue el mejor modelo y haga predicciones con él | El objetivo del seguimiento del experimento es descubrir qué modelo funciona mejor, carguemos el modelo con mejor rendimiento y hagamos algunas predicciones con él para ¡visualizar, visualizar, visualizar!. |
¿Dónde puedes obtener ayuda?¶
Todos los materiales de este curso están disponibles en GitHub.
Si tiene problemas, puede hacer una pregunta en el curso [página de debates de GitHub] (https://github.com/mrdbourke/pytorch-deep-learning/discussions).
Y, por supuesto, está la documentación de PyTorch y los foros de desarrolladores de PyTorch, un lugar muy útil para todo lo relacionado con PyTorch.
0. Configuración¶
Comencemos descargando todos los módulos que necesitaremos para esta sección.
Para ahorrarnos escribir código adicional, aprovecharemos algunos de los scripts de Python (como data_setup.py y engine.py) que creamos en la sección 05. PyTorch se vuelve modular.
Específicamente, vamos a descargar el directorio going_modular del repositorio pytorch-deep-learning (si aún no lo tenemos).
También obtendremos el paquete torchinfo si no está disponible.
torchinfo nos ayudará más adelante a brindarnos resúmenes visuales de nuestro(s) modelo(s).
Y dado que estamos usando una versión más nueva del paquete torchvision (v0.13 a partir de junio de 2022), nos aseguraremos de tener las últimas versiones.
# Para que este portátil se ejecute con API actualizadas, necesitamos torch 1.12+ y torchvision 0.13+.
try:
import torch
import torchvision
assert int(torch.__version__.split(".")[1]) >= 12, "torch version should be 1.12+"
assert int(torchvision.__version__.split(".")[1]) >= 13, "torchvision version should be 0.13+"
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
except:
print(f"[INFO] torch/torchvision versions not as required, installing nightly versions.")
!pip3 install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
import torch
import torchvision
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
Nota: Si está utilizando Google Colab, es posible que deba reiniciar su tiempo de ejecución después de ejecutar la celda anterior. Después de reiniciar, puede ejecutar la celda nuevamente y verificar que tiene las versiones correctas de
torch(0.12+) ytorchvision(0.13+).
# Continuar con las importaciones regulares
import matplotlib.pyplot as plt
import torch
import torchvision
from torch import nn
from torchvision import transforms
# Intente obtener torchinfo, instálelo si no funciona
try:
from torchinfo import summary
except:
print("[INFO] Couldn't find torchinfo... installing it.")
!pip install -q torchinfo
from torchinfo import summary
# Intente importar el directorio going_modular, descárguelo de GitHub si no funciona
try:
from going_modular.going_modular import data_setup, engine
except:
# Get the going_modular scripts
print("[INFO] Couldn't find going_modular scripts... downloading them from GitHub.")
!git clone https://github.com/mrdbourke/pytorch-deep-learning
!mv pytorch-deep-learning/going_modular .
!rm -rf pytorch-deep-learning
from going_modular.going_modular import data_setup, engine
Ahora configuremos el código independiente del dispositivo.
Nota: Si estás usando Google Colab y aún no tienes una GPU activada, ahora es el momento de activar una a través de
Runtime -> Cambiar tipo de tiempo de ejecución -> Acelerador de hardware -> GPU.
device = "cuda" if torch.cuda.is_available() else "cpu"
device
Crear una función auxiliar para establecer semillas¶
Dado que hemos estado configurando muchas semillas aleatorias en las secciones anteriores, ¿qué tal si las funcionalizamos?
Creemos una función para "establecer las semillas" llamada set_seeds().
Nota: Recuerde que una semilla aleatoria es una forma de darle sabor a la aleatoriedad generada por una computadora. No es necesario configurarlos siempre cuando se ejecuta código de aprendizaje automático; sin embargo, ayudan a garantizar que haya un elemento de reproducibilidad (los números que obtengo con mi código son similares a los números que obtienes con tu código). Fuera de un entorno educativo o experimental, generalmente no se requieren semillas aleatorias.
# Establecer semillas
def set_seeds(seed: int=42):
"""Sets random sets for torch operations.
Args:
seed (int, optional): Random seed to set. Defaults to 42.
"""
# Set the seed for general torch operations
torch.manual_seed(seed)
# Set the seed for CUDA torch operations (ones that happen on the GPU)
torch.cuda.manual_seed(seed)
1. Obtener datos¶
Como siempre, antes de que podamos ejecutar experimentos de aprendizaje automático, necesitaremos un conjunto de datos.
Continuaremos intentando mejorar los resultados que hemos obtenido con FoodVision Mini.
En el apartado anterior, 06. PyTorch Transfer Learning, vimos lo poderoso que puede ser el uso de un modelo previamente entrenado y el aprendizaje por transferencia al clasificar imágenes de pizza, bistec y sushi.
Entonces, ¿qué tal si realizamos algunos experimentos e intentamos mejorar aún más nuestros resultados?
Para hacerlo, usaremos un código similar al de la sección anterior para descargar pizza_steak_sushi.zip (si los datos aún no existen) excepto que esta vez se ha funcionalizado.
Esto nos permitirá volver a utilizarlo más adelante.
import os
import zipfile
from pathlib import Path
import requests
def download_data(source: str,
destination: str,
remove_source: bool = True) -> Path:
"""Downloads a zipped dataset from source and unzips to destination.
Args:
source (str): A link to a zipped file containing data.
destination (str): A target directory to unzip data to.
remove_source (bool): Whether to remove the source after downloading and extracting.
Returns:
pathlib.Path to downloaded data.
Example usage:
download_data(source="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip",
destination="pizza_steak_sushi")
"""
# Setup path to data folder
data_path = Path("data/")
image_path = data_path / destination
# If the image folder doesn't exist, download it and prepare it...
if image_path.is_dir():
print(f"[INFO] {image_path} directory exists, skipping download.")
else:
print(f"[INFO] Did not find {image_path} directory, creating one...")
image_path.mkdir(parents=True, exist_ok=True)
# Download pizza, steak, sushi data
target_file = Path(source).name
with open(data_path / target_file, "wb") as f:
request = requests.get(source)
print(f"[INFO] Downloading {target_file} from {source}...")
f.write(request.content)
# Unzip pizza, steak, sushi data
with zipfile.ZipFile(data_path / target_file, "r") as zip_ref:
print(f"[INFO] Unzipping {target_file} data...")
zip_ref.extractall(image_path)
# Remove .zip file
if remove_source:
os.remove(data_path / target_file)
return image_path
image_path = download_data(source="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip",
destination="pizza_steak_sushi")
image_path
¡Excelente! Parece que tenemos nuestras imágenes de pizza, bistec y sushi en formato de clasificación de imágenes estándar listas para usar.
2. Crear conjuntos de datos y cargadores de datos¶
Ahora que tenemos algunos datos, convirtámoslos en PyTorch DataLoaders.
Podemos hacerlo usando la función create_dataloaders() que creamos en 05. PyTorch se vuelve modular, parte 2.
Y dado que usaremos aprendizaje por transferencia y modelos específicamente entrenados previamente de torchvision.models, crearemos una transformación para preparar nuestras imágenes correctamente. .
Para transformar nuestras imágenes en tensores, podemos usar:
- Transformaciones creadas manualmente usando
torchvision.transforms. - Transformaciones creadas automáticamente usando
torchvision.models.MODEL_NAME.MODEL_WEIGHTS.DEFAULT.transforms().- Donde
MODEL_NAMEes una arquitectura específica detorchvision.models,MODEL_WEIGHTSes un conjunto específico de pesos previamente entrenados yDEFAULTsignifica los "mejores pesos disponibles".
- Donde
Vimos un ejemplo de cada uno de estos en [06. Sección 2 del aprendizaje por transferencia de PyTorch] (https://www.learnpytorch.io/06_pytorch_transfer_learning/#2-create-datasets-and-dataloaders).
Veamos primero un ejemplo de creación manual de una canalización torchvision.transforms (crear una canalización de transformaciones de esta manera brinda la mayor personalización, pero puede resultar potencialmente en una degradación del rendimiento si las transformaciones no coinciden con el modelo previamente entrenado).
La principal transformación manual de la que debemos estar seguros es que todas nuestras imágenes estén normalizadas en formato ImageNet (esto se debe a que los torchvision.models previamente entrenados están todos preentrenados en [ImageNet] (https://www.image-net.org /)).
Podemos hacer esto con:
pitón
normalizar = transforma.Normalizar(media=[0.485, 0.456, 0.406],
estándar=[0,229, 0,224, 0,225])
2.1 Crear cargadores de datos utilizando transformaciones creadas manualmente¶
# Directorios de configuración
train_dir = image_path / "train"
test_dir = image_path / "test"
# Configurar los niveles de normalización de ImageNet (convierte todas las imágenes en una distribución similar a la de ImageNet)
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# Crear canalización de transformación manualmente
manual_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
normalize
])
print(f"Manually created transforms: {manual_transforms}")
# Crear cargadores de datos
train_dataloader, test_dataloader, class_names = data_setup.create_dataloaders(
train_dir=train_dir,
test_dir=test_dir,
transform=manual_transforms, # use manually created transforms
batch_size=32
)
train_dataloader, test_dataloader, class_names
2.2 Crear cargadores de datos utilizando transformaciones creadas automáticamente¶
¡Datos transformados y DataLoaders creados!
Veamos ahora cómo se ve el mismo proceso de transformación, pero esta vez mediante transformaciones automáticas.
Podemos hacer esto creando primero una instancia de un conjunto de pesos previamente entrenados (por ejemplo, weights = torchvision.models.EfficientNet_B0_Weights.DEFAULT) que nos gustaría usar y llamando al método transforms().
# Directorios de configuración
train_dir = image_path / "train"
test_dir = image_path / "test"
# Configure pesas previamente entrenadas (muchas de ellas disponibles en torchvision.models)
weights = torchvision.models.EfficientNet_B0_Weights.DEFAULT
# Obtener transformaciones a partir de pesos (estas son las transformaciones que se utilizaron para obtener los pesos)
automatic_transforms = weights.transforms()
print(f"Automatically created transforms: {automatic_transforms}")
# Crear cargadores de datos
train_dataloader, test_dataloader, class_names = data_setup.create_dataloaders(
train_dir=train_dir,
test_dir=test_dir,
transform=automatic_transforms, # use automatic created transforms
batch_size=32
)
train_dataloader, test_dataloader, class_names
3. Obtener un modelo previamente entrenado, congelar las capas base y cambiar el cabezal clasificador¶
Antes de ejecutar y realizar un seguimiento de varios experimentos de modelado, veamos cómo es ejecutar y realizar un seguimiento de uno solo.
Y como nuestros datos están listos, lo siguiente que necesitaremos es un modelo.
Descarguemos los pesos previamente entrenados para un modelo torchvision.models.ficientnet_b0() y preparémoslo para usarlo con nuestros propios datos.
# Nota: Así es como se crearía un modelo previamente entrenado en torchvision > 0.13; quedará obsoleto en versiones futuras.
# modelo = torchvision.models.ficientnet_b0(preentrenado=True).to(dispositivo) # ANTIGUO
# Descargue los pesos previamente entrenados para EfficientNet_B0
weights = torchvision.models.EfficientNet_B0_Weights.DEFAULT # NEW in torchvision 0.13, "DEFAULT" means "best weights available"
# Configure el modelo con los pesos previamente entrenados y envíelo al dispositivo de destino.
model = torchvision.models.efficientnet_b0(weights=weights).to(device)
# Ver el resultado del modelo.
# modelo
¡Maravilloso!
Ahora que tenemos un modelo previamente entrenado, convirtámoslo en un modelo de extracción de características.
En esencia, congelaremos las capas base del modelo (las usaremos para extraer características de nuestras imágenes de entrada) y cambiaremos el encabezado del clasificador (capa de salida) para adaptarlo a la cantidad de clases con las que estamos trabajando. (tenemos 3 clases: pizza, bistec, sushi).
Nota: La idea de crear un modelo de extracción de características (lo que estamos haciendo aquí) se cubrió con más profundidad en [06. Sección 3.2 de PyTorch Transfer Learning: Configuración de un modelo previamente entrenado] (https://www.learnpytorch.io/06_pytorch_transfer_learning/#32-setting-up-a-pretrained-model).
# Congele todas las capas base estableciendo el atributo require_grad en Falso
for param in model.features.parameters():
param.requires_grad = False
# Dado que estamos creando una nueva capa con pesos aleatorios (torch.nn.Linear),
# vamos a poner las semillas
set_seeds()
# Actualice el cabezal clasificador para adaptarlo a nuestro problema.
model.classifier = torch.nn.Sequential(
nn.Dropout(p=0.2, inplace=True),
nn.Linear(in_features=1280,
out_features=len(class_names),
bias=True).to(device))
Capas base congeladas, cabezal clasificador cambiado, obtengamos un resumen de nuestro modelo con torchinfo.summary().
from torchinfo import summary
# # Obtener un resumen del modelo (descomentar para obtener un resultado completo)
# resumen (modelo,
# input_size=(32, 3, 224, 224), # asegúrese de que sea "input_size", no "input_shape" (batch_size, color_channels, alto, ancho)
# detallado = 0,
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"]
# )
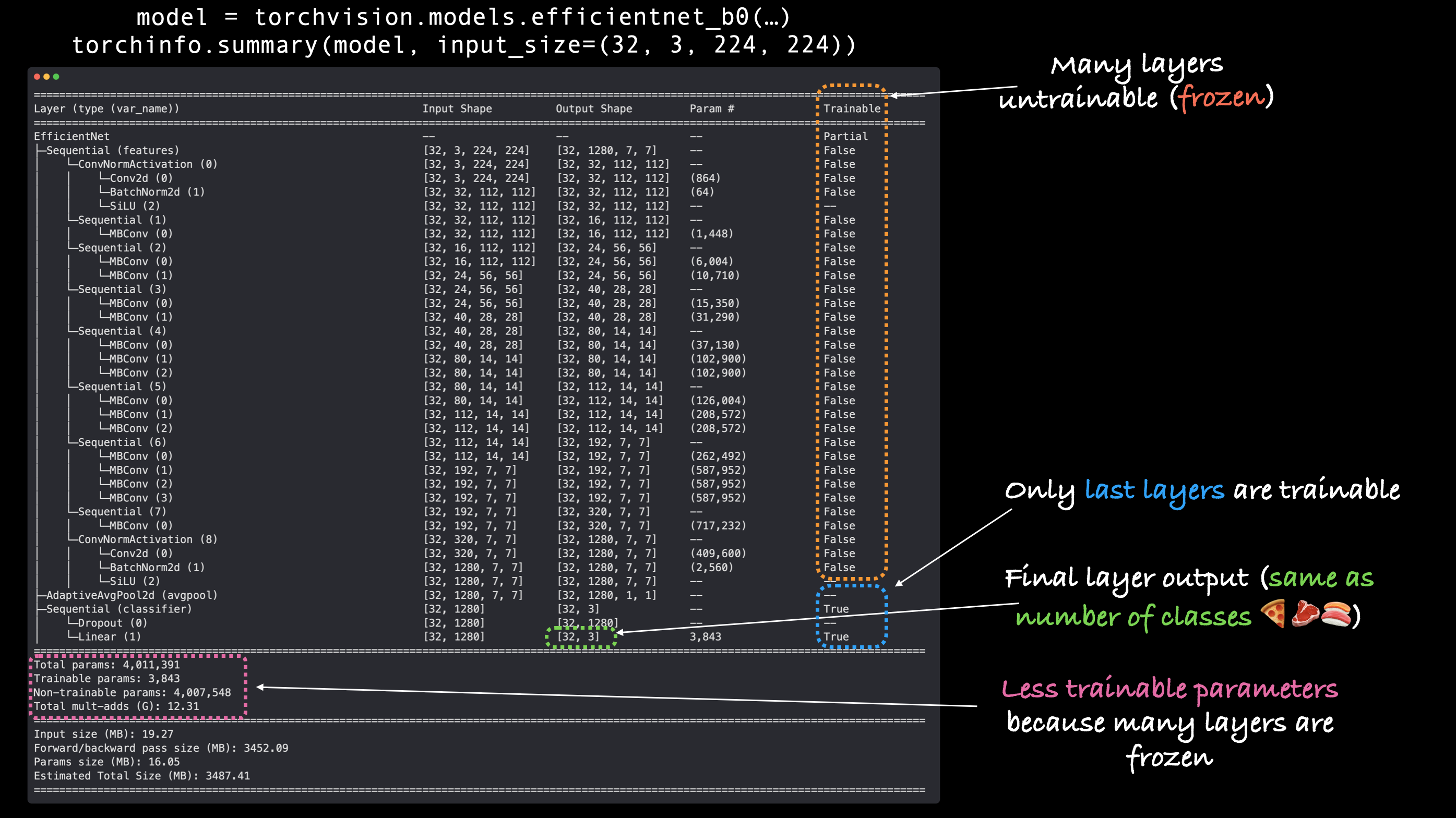
Salida de torchinfo.summary() con nuestro modelo de extractor de características EffNetB0, observe cómo las capas base están congeladas (no entrenables) y las capas de salida se personalizan según nuestro propio problema.
4. Entrenar el modelo y realizar un seguimiento de los resultados.¶
¡Modelo listo para funcionar!
Preparémonos para entrenarlo creando una función de pérdida y un optimizador.
Como estamos trabajando con varias clases, usaremos torch.nn.CrossEntropyLoss() como pérdida función.
Y nos quedaremos con torch.optim.Adam() con una tasa de aprendizaje de 0,001 para el optimizador.
# Definir pérdida y optimizador
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
Ajuste la función train() para realizar un seguimiento de los resultados con SummaryWriter()¶
¡Hermoso!
Todas las piezas de nuestro código de formación están empezando a encajar.
Agreguemos ahora la pieza final para realizar un seguimiento de nuestros experimentos.
Anteriormente, hemos realizado un seguimiento de nuestros experimentos de modelado utilizando varios diccionarios de Python (uno para cada modelo).
Pero puedes imaginar que esto podría salirse de control si estuviéramos realizando algo más que unos pocos experimentos.
¡No te preocupes, hay una mejor opción!
Podemos usar la clase torch.utils.tensorboard.SummaryWriter() de PyTorch para guardar varias partes del progreso del entrenamiento de nuestro modelo en un archivo.
De forma predeterminada, la clase SummaryWriter() guarda diversa información sobre nuestro modelo en un archivo establecido por el parámetro log_dir.
La ubicación predeterminada para log_dir está en runs/CURRENT_DATETIME_HOSTNAME, donde HOSTNAME es el nombre de su computadora.
Pero, por supuesto, puedes cambiar dónde se realiza el seguimiento de tus experimentos (el nombre del archivo es tan personalizable como quieras).
Las salidas de SummaryWriter() se guardan en [formato TensorBoard] (https://www.tensorflow.org/tensorboard/).
TensorBoard es parte de la biblioteca de aprendizaje profundo de TensorFlow y es una excelente manera de visualizar diferentes partes de su modelo.
Para comenzar a rastrear nuestros experimentos de modelado, creemos una instancia predeterminada SummaryWriter().
from torch.utils.tensorboard import SummaryWriter
# Crea un escritor con todas las configuraciones predeterminadas
writer = SummaryWriter()
Ahora, para usar el escritor, podríamos escribir un nuevo bucle de entrenamiento o podríamos ajustar la función train() existente que creamos en 05. PyTorch Going Modular sección 4.
Tomemos la última opción.
Obtendremos la función train() de engine.py y ajustaremos utilizar "escritor".
Específicamente, agregaremos la capacidad de nuestra función train() para registrar el entrenamiento de nuestro modelo y probar los valores de pérdida y precisión.
Podemos hacer esto con writer.add_scalars(main_tag, tag_scalar_dict), donde:
main_tag(cadena): el nombre de los escalares que se rastrean (por ejemplo, "Precisión")tag_scalar_dict(dict): un diccionario de los valores que se están rastreando (por ejemplo,{"train_loss": 0.3454})Nota: El método se llama
add_scalars()porque nuestros valores de pérdida y precisión son generalmente escalares (valores únicos).
Una vez que hayamos terminado de rastrear los valores, llamaremos a writer.close() para decirle al writer que deje de buscar valores para rastrear.
Para comenzar a modificar train() también importaremos train_step() y test_step() desde [engine.py](https://github.com/mrdbourke/pytorch-deep-learning/blob /main/going_modular/going_modular/engine.py).
Nota: Puede realizar un seguimiento de la información sobre su modelo casi en cualquier parte de su código. Pero muy a menudo se realizará un seguimiento de los experimentos mientras se entrena un modelo (dentro de un ciclo de entrenamiento/prueba).
La clase
torch.utils.tensorboard.SummaryWriter()también tiene muchos métodos diferentes para rastrear diferentes cosas sobre su modelo/datos, como [add_graph()](https://pytorch.org/docs/stable /tensorboard.html#torch.utils.tensorboard.writer.SummaryWriter.add_graph) que rastrea el gráfico de cálculo de su modelo. Para obtener más opciones, consulte la documentaciónSummaryWriter().
from typing import Dict, List
from tqdm.auto import tqdm
from going_modular.going_modular.engine import train_step, test_step
# Importar función train() desde:
# https://github.com/mrdbourke/pytorch-deep-learning/blob/main/going_modular/going_modular/engine.py
def train(model: torch.nn.Module,
train_dataloader: torch.utils.data.DataLoader,
test_dataloader: torch.utils.data.DataLoader,
optimizer: torch.optim.Optimizer,
loss_fn: torch.nn.Module,
epochs: int,
device: torch.device) -> Dict[str, List]:
"""Trains and tests a PyTorch model.
Passes a target PyTorch models through train_step() and test_step()
functions for a number of epochs, training and testing the model
in the same epoch loop.
Calculates, prints and stores evaluation metrics throughout.
Args:
model: A PyTorch model to be trained and tested.
train_dataloader: A DataLoader instance for the model to be trained on.
test_dataloader: A DataLoader instance for the model to be tested on.
optimizer: A PyTorch optimizer to help minimize the loss function.
loss_fn: A PyTorch loss function to calculate loss on both datasets.
epochs: An integer indicating how many epochs to train for.
device: A target device to compute on (e.g. "cuda" or "cpu").
Returns:
A dictionary of training and testing loss as well as training and
testing accuracy metrics. Each metric has a value in a list for
each epoch.
In the form: {train_loss: [...],
train_acc: [...],
test_loss: [...],
test_acc: [...]}
For example if training for epochs=2:
{train_loss: [2.0616, 1.0537],
train_acc: [0.3945, 0.3945],
test_loss: [1.2641, 1.5706],
test_acc: [0.3400, 0.2973]}
"""
# Create empty results dictionary
results = {"train_loss": [],
"train_acc": [],
"test_loss": [],
"test_acc": []
}
# Loop through training and testing steps for a number of epochs
for epoch in tqdm(range(epochs)):
train_loss, train_acc = train_step(model=model,
dataloader=train_dataloader,
loss_fn=loss_fn,
optimizer=optimizer,
device=device)
test_loss, test_acc = test_step(model=model,
dataloader=test_dataloader,
loss_fn=loss_fn,
device=device)
# Print out what's happening
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.4f} | "
f"train_acc: {train_acc:.4f} | "
f"test_loss: {test_loss:.4f} | "
f"test_acc: {test_acc:.4f}"
)
# Update results dictionary
results["train_loss"].append(train_loss)
results["train_acc"].append(train_acc)
results["test_loss"].append(test_loss)
results["test_acc"].append(test_acc)
### New: Experiment tracking ###
# Add loss results to SummaryWriter
writer.add_scalars(main_tag="Loss",
tag_scalar_dict={"train_loss": train_loss,
"test_loss": test_loss},
global_step=epoch)
# Add accuracy results to SummaryWriter
writer.add_scalars(main_tag="Accuracy",
tag_scalar_dict={"train_acc": train_acc,
"test_acc": test_acc},
global_step=epoch)
# Track the PyTorch model architecture
writer.add_graph(model=model,
# Pass in an example input
input_to_model=torch.randn(32, 3, 224, 224).to(device))
# Close the writer
writer.close()
### End new ###
# Return the filled results at the end of the epochs
return results
¡Guau!
Nuestra función train() ahora está actualizada para usar una instancia SummaryWriter() para rastrear los resultados de nuestro modelo.
¿Qué tal si lo probamos durante 5 épocas?
# modelo de tren
# Nota: No usar Engine.train() ya que el script original no está actualizado para usar Writer.
set_seeds()
results = train(model=model,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=5,
device=device)
Nota: Es posible que observe que los resultados aquí son ligeramente diferentes a los que obtuvo nuestro modelo en 06. Aprendizaje por transferencia de PyTorch. La diferencia proviene del uso de
engine.train()y nuestra funcióntrain()modificada. ¿Puedes adivinar por qué? La documentación de PyTorch sobre aleatoriedad puede ayudar más.
Al ejecutar la celda de arriba obtenemos resultados similares a los que obtuvimos en 06. PyTorch Transfer Learning sección 4: Entrenar modelo pero la diferencia está detrás de escena, nuestra instancia writer ha creado un directorio runs/ que almacena los resultados de nuestro modelo.
Por ejemplo, la ubicación para guardar podría verse así:
carreras/Jun21_00-46-03_daniels_macbook_pro
Donde el formato predeterminado es runs/CURRENT_DATETIME_HOSTNAME.
Los comprobaremos en un segundo, pero solo como recordatorio, anteriormente estábamos rastreando los resultados de nuestro modelo en un diccionario.
# Mira los resultados del modelo.
results
Hmmm, podríamos formatear esto para que sea una buena trama, pero ¿te imaginas hacer un seguimiento de varios de estos diccionarios?
Tiene que haber una mejor manera...
5. Ver los resultados de nuestro modelo en TensorBoard¶
La clase SummaryWriter() almacena los resultados de nuestro modelo en un directorio llamado runs/ en formato TensorBoard de forma predeterminada.
TensorBoard es un programa de visualización creado por el equipo de TensorFlow para ver e inspeccionar información sobre modelos y datos.
¿Sabes lo que significa?
Es hora de seguir el lema del visualizador de datos y ¡visualizar, visualizar, visualizar!
Puedes ver TensorBoard de varias maneras:
| Entorno de código | Cómo ver TensorBoard | Recurso |
|---|---|---|
| VS Code (cuadernos o scripts de Python) | Presione SHIFT + CMD + P para abrir la paleta de comandos y busque el comando "Python: Iniciar TensorBoard". |
Guía de código VS en TensorBoard y PyTorch |
| Cuadernos Jupyter y Colab | Asegúrese de que [TensorBoard esté instalado] (https://pypi.org/project/tensorboard/), cárguelo con %load_ext tensorboard y luego vea los resultados con %tensorboard --logdir DIR_WITH_LOGS. |
torch.utils.tensorboard y Comenzar con TensorBoard |
También puedes subir tus experimentos a tensorboard.dev para compartirlos públicamente con otros.
Al ejecutar el siguiente código en Google Colab o Jupyter Notebook se iniciará una sesión interactiva de TensorBoard para ver los archivos de TensorBoard en el directorio runs/.
pitón
%load_ext tensorboard # línea mágica para cargar TensorBoard
%tensorboard --logdir ejecuta # ejecuta la sesión de TensorBoard con el directorio "ejecuta/"
# Código de ejemplo para ejecutar en Jupyter o Google Colab Notebook (descoméntalo para probarlo)
# %load_ext tensorboard
# % tensorboard --logdir se ejecuta
Si todo salió correctamente, deberías ver algo como lo siguiente:
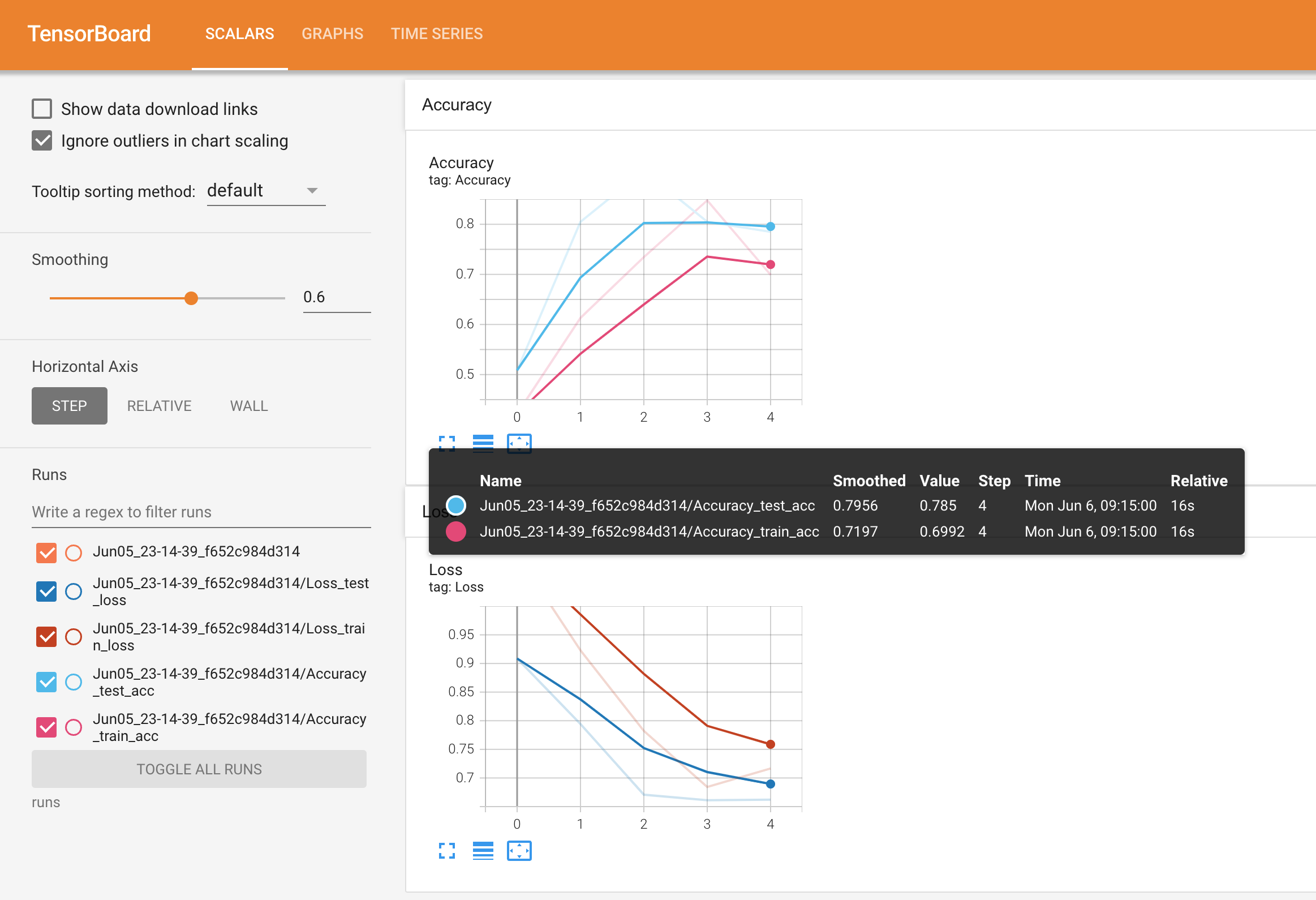
Ver los resultados de un único experimento de modelado para determinar la precisión y la pérdida en TensorBoard.
Nota: Para obtener más información sobre cómo ejecutar TensorBoard en notebooks o en otras ubicaciones, consulte lo siguiente:
- Guía de uso de TensorBoard en Notebooks de TensorFlow
- Comience con TensorBoard.dev (útil para cargar sus registros de TensorBoard en un enlace para compartir)
6. Cree una función auxiliar para crear instancias SummaryWriter()¶
La clase SummaryWriter() registra diversa información en un directorio especificado por el parámetro log_dir.
¿Qué tal si creamos una función auxiliar para crear un directorio personalizado por experimento?
En esencia, cada experimento tiene su propio directorio de registros.
Por ejemplo, digamos que nos gustaría realizar un seguimiento de cosas como:
- Fecha/marca de tiempo del experimento: ¿cuándo tuvo lugar el experimento?
- Nombre del experimento: ¿hay algo que nos gustaría llamar al experimento?
- Nombre del modelo: ¿qué modelo se utilizó?
- Extra: ¿se debe realizar un seguimiento de algo más?
Puedes rastrear casi cualquier cosa aquí y ser tan creativo como quieras, pero esto debería ser suficiente para comenzar.
Creemos una función auxiliar llamada create_writer() que produzca un seguimiento de instancia SummaryWriter() a un log_dir personalizado.
Idealmente, nos gustaría que log_dir fuera algo como:
ejecuta/AAAA-MM-DD/nombre_experimento/nombre_modelo/extra
Donde "AAAA-MM-DD" es la fecha en que se ejecutó el experimento (también puede agregar la hora si lo desea).
def create_writer(experiment_name: str,
model_name: str,
extra: str=None) -> torch.utils.tensorboard.writer.SummaryWriter():
"""Creates a torch.utils.tensorboard.writer.SummaryWriter() instance saving to a specific log_dir.
log_dir is a combination of runs/timestamp/experiment_name/model_name/extra.
Where timestamp is the current date in YYYY-MM-DD format.
Args:
experiment_name (str): Name of experiment.
model_name (str): Name of model.
extra (str, optional): Anything extra to add to the directory. Defaults to None.
Returns:
torch.utils.tensorboard.writer.SummaryWriter(): Instance of a writer saving to log_dir.
Example usage:
# Create a writer saving to "runs/2022-06-04/data_10_percent/effnetb2/5_epochs/"
writer = create_writer(experiment_name="data_10_percent",
model_name="effnetb2",
extra="5_epochs")
# The above is the same as:
writer = SummaryWriter(log_dir="runs/2022-06-04/data_10_percent/effnetb2/5_epochs/")
"""
from datetime import datetime
import os
# Get timestamp of current date (all experiments on certain day live in same folder)
timestamp = datetime.now().strftime("%Y-%m-%d") # returns current date in YYYY-MM-DD format
if extra:
# Create log directory path
log_dir = os.path.join("runs", timestamp, experiment_name, model_name, extra)
else:
log_dir = os.path.join("runs", timestamp, experiment_name, model_name)
print(f"[INFO] Created SummaryWriter, saving to: {log_dir}...")
return SummaryWriter(log_dir=log_dir)
¡Hermoso!
Ahora que tenemos una función create_writer(), probémosla.
# Crear un escritor de ejemplo
example_writer = create_writer(experiment_name="data_10_percent",
model_name="effnetb0",
extra="5_epochs")
Viendo bien, ahora tenemos una manera de registrar y rastrear nuestros diversos experimentos.
6.1 Actualice la función train() para incluir un parámetro writer¶
Nuestra función create_writer() funciona fantástico.
¿Qué tal si le damos a nuestra función train() la capacidad de aceptar un parámetro writer para que actualicemos activamente la instancia SummaryWriter() que estamos usando cada vez que llamamos a train()?
Por ejemplo, digamos que estamos ejecutando una serie de experimentos, llamando a "train()" varias veces para múltiples modelos diferentes, sería bueno si cada experimento usara un "escritor" diferente.
Un "escritor" por experimento = un directorio de registros por experimento.
Para ajustar la función train() agregaremos un parámetro writer a la función y luego agregaremos algo de código para ver si hay un writer y, de ser así, rastrearemos nuestra información allí.
from typing import Dict, List
from tqdm.auto import tqdm
# Agregar parámetro de escritor a entrenar()
def train(model: torch.nn.Module,
train_dataloader: torch.utils.data.DataLoader,
test_dataloader: torch.utils.data.DataLoader,
optimizer: torch.optim.Optimizer,
loss_fn: torch.nn.Module,
epochs: int,
device: torch.device,
writer: torch.utils.tensorboard.writer.SummaryWriter # new parameter to take in a writer
) -> Dict[str, List]:
"""Trains and tests a PyTorch model.
Passes a target PyTorch models through train_step() and test_step()
functions for a number of epochs, training and testing the model
in the same epoch loop.
Calculates, prints and stores evaluation metrics throughout.
Stores metrics to specified writer log_dir if present.
Args:
model: A PyTorch model to be trained and tested.
train_dataloader: A DataLoader instance for the model to be trained on.
test_dataloader: A DataLoader instance for the model to be tested on.
optimizer: A PyTorch optimizer to help minimize the loss function.
loss_fn: A PyTorch loss function to calculate loss on both datasets.
epochs: An integer indicating how many epochs to train for.
device: A target device to compute on (e.g. "cuda" or "cpu").
writer: A SummaryWriter() instance to log model results to.
Returns:
A dictionary of training and testing loss as well as training and
testing accuracy metrics. Each metric has a value in a list for
each epoch.
In the form: {train_loss: [...],
train_acc: [...],
test_loss: [...],
test_acc: [...]}
For example if training for epochs=2:
{train_loss: [2.0616, 1.0537],
train_acc: [0.3945, 0.3945],
test_loss: [1.2641, 1.5706],
test_acc: [0.3400, 0.2973]}
"""
# Create empty results dictionary
results = {"train_loss": [],
"train_acc": [],
"test_loss": [],
"test_acc": []
}
# Loop through training and testing steps for a number of epochs
for epoch in tqdm(range(epochs)):
train_loss, train_acc = train_step(model=model,
dataloader=train_dataloader,
loss_fn=loss_fn,
optimizer=optimizer,
device=device)
test_loss, test_acc = test_step(model=model,
dataloader=test_dataloader,
loss_fn=loss_fn,
device=device)
# Print out what's happening
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.4f} | "
f"train_acc: {train_acc:.4f} | "
f"test_loss: {test_loss:.4f} | "
f"test_acc: {test_acc:.4f}"
)
# Update results dictionary
results["train_loss"].append(train_loss)
results["train_acc"].append(train_acc)
results["test_loss"].append(test_loss)
results["test_acc"].append(test_acc)
### New: Use the writer parameter to track experiments ###
# See if there's a writer, if so, log to it
if writer:
# Add results to SummaryWriter
writer.add_scalars(main_tag="Loss",
tag_scalar_dict={"train_loss": train_loss,
"test_loss": test_loss},
global_step=epoch)
writer.add_scalars(main_tag="Accuracy",
tag_scalar_dict={"train_acc": train_acc,
"test_acc": test_acc},
global_step=epoch)
# Close the writer
writer.close()
else:
pass
### End new ###
# Return the filled results at the end of the epochs
return results
7. Configuración de una serie de experimentos de modelado.¶
Es para dar un paso más en las cosas.
Anteriormente hemos realizado varios experimentos e inspeccionado los resultados uno por uno.
Pero, ¿qué pasaría si pudiéramos realizar varios experimentos y luego inspeccionar todos los resultados juntos?
¿Te unes?
Vamos, vámonos.
7.1 ¿Qué tipo de experimentos debería realizar?¶
Esa es la pregunta del millón en el aprendizaje automático.
Porque realmente no hay límite para los experimentos que puedes realizar.
Esta libertad es la razón por la que el aprendizaje automático es tan emocionante y aterrador al mismo tiempo.
Aquí es donde tendrás que ponerte tu bata de científico y recordar el lema de los profesionales del aprendizaje automático: ¡experimenta, experimenta, experimenta!
Cada hiperparámetro constituye un punto de partida para un experimento diferente:
- Cambiar el número de épocas.
- Cambiar el número de capas/unidades ocultas.
- Cambiar la cantidad de datos.
- Cambiar la tasa de aprendizaje.
- Pruebe diferentes tipos de aumento de datos.
- Elija una arquitectura de modelo diferente.
Con práctica y realizando muchos experimentos diferentes, comenzarás a desarrollar una intuición de lo que podría ayudar a tu modelo.
Digo podría a propósito porque no hay garantías.
Pero en general, a la luz de The Bitter Lesson (lo he mencionado dos veces porque es un ensayo importante en el mundo de la IA), En general, cuanto más grande sea su modelo (más parámetros que se pueden aprender) y más datos tenga (más oportunidades de aprender), mejor será el rendimiento.
Sin embargo, cuando se acerque por primera vez a un problema de aprendizaje automático: comience poco a poco y, si algo funciona, amplíelo.
Su primer lote de experimentos no debería tardar más de unos segundos o unos minutos en ejecutarse.
Cuanto más rápido puedas experimentar, más rápido podrás descubrir lo que no funciona y, a su vez, más rápido podrás descubrir lo que sí funciona.
7.2 ¿Qué experimentos vamos a realizar?¶
Nuestro objetivo es mejorar el modelo que impulsa FoodVision Mini sin que crezca demasiado.
En esencia, nuestro modelo ideal logra un alto nivel de precisión del conjunto de pruebas (más del 90 %), pero no lleva demasiado tiempo entrenar/realizar inferencias (hacer predicciones).
Tenemos muchas opciones, pero ¿qué tal si mantenemos las cosas simples?
Probemos una combinación de:
- Una cantidad de datos diferente (10 % de pizza, bistec y sushi frente a 20 %)
- Un modelo diferente (
torchvision.models.ficientnet_b0vs.torchvision. modelos.eficientenet_b2) - Un tiempo de entrenamiento diferente (5 épocas frente a 10 épocas)
Desglosándolos obtenemos:
| Número de experimento | Conjunto de datos de entrenamiento | Modelo (preentrenado en ImageNet) | Número de épocas |
|---|---|---|---|
| 1 | Pizza, bistec, sushi 10% por ciento | EfficientNetB0 | 5 |
| 2 | Pizza, bistec, sushi 10% por ciento | EfficientNetB2 | 5 |
| 3 | Pizza, bistec, sushi 10% por ciento | EfficientNetB0 | 10 |
| 4 | Pizza, bistec, sushi 10% por ciento | EfficientNetB2 | 10 |
| 5 | Pizza, bistec, sushi 20% por ciento | EfficientNetB0 | 5 |
| 6 | Pizza, bistec, sushi 20% por ciento | EfficientNetB2 | 5 |
| 7 | Pizza, bistec, sushi 20% por ciento | EfficientNetB0 | 10 |
| 8 | Pizza, bistec, sushi 20% por ciento | EfficientNetB2 | 10 |
Observe cómo poco a poco estamos ampliando las cosas.
Con cada experimento aumentamos lentamente la cantidad de datos, el tamaño del modelo y la duración del entrenamiento.
Al final, el experimento 8 utilizará el doble de datos, el doble del tamaño del modelo y el doble de duración del entrenamiento en comparación con el experimento 1.
Nota: Quiero dejar claro que realmente no hay límite para la cantidad de experimentos que puedes ejecutar. Lo que hemos diseñado aquí es sólo un subconjunto muy pequeño de opciones. Sin embargo, no puedes probar todo así que es mejor probar algunas cosas para empezar y luego seguir las que funcionan mejor.
Y como recordatorio, los conjuntos de datos que estamos usando son un subconjunto del conjunto de datos Food101 (3 clases, pizza, bistec, sushi, en lugar de 101) y 10% y 20% de las imágenes en lugar de 100%. Si nuestros experimentos funcionan, podríamos comenzar a ejecutar más con más datos (aunque esto llevará más tiempo calcularlo). Puede ver cómo se crearon los conjuntos de datos a través del [cuaderno
04_custom_data_creation.ipynb] (https://github.com/mrdbourke/pytorch-deep-learning/blob/main/extras/04_custom_data_creation.ipynb).
7.3 Descargar diferentes conjuntos de datos¶
Antes de comenzar a ejecutar nuestra serie de experimentos, debemos asegurarnos de que nuestros conjuntos de datos estén listos.
Necesitaremos dos formas de conjunto de entrenamiento:
- Un conjunto de entrenamiento con 10% de los datos de imágenes de pizza, bistec y sushi de Food101 (ya hemos creado esto arriba, pero lo haremos nuevamente para que esté completo).
- Un conjunto de entrenamiento con 20% de los datos de imágenes de pizza, bistec y sushi de Food101.
Para mantener la coherencia, todos los experimentos utilizarán el mismo conjunto de datos de prueba (el de la división de datos del 10%).
Comenzaremos descargando los diversos conjuntos de datos que necesitamos usando la función download_data() que creamos anteriormente.
Ambos conjuntos de datos están disponibles en el curso GitHub:
# Descargue datos de entrenamiento del 10 por ciento y del 20 por ciento (si es necesario)
data_10_percent_path = download_data(source="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip",
destination="pizza_steak_sushi")
data_20_percent_path = download_data(source="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi_20_percent.zip",
destination="pizza_steak_sushi_20_percent")
¡Datos descargados!
Ahora configuremos las rutas de archivo de los datos que usaremos para los diferentes experimentos.
Crearemos diferentes rutas de directorio de entrenamiento, pero solo necesitaremos una ruta de directorio de prueba, ya que todos los experimentos utilizarán el mismo conjunto de datos de prueba (el conjunto de datos de prueba de pizza, bistec y sushi 10%).
# Configurar rutas del directorio de capacitación
train_dir_10_percent = data_10_percent_path / "train"
train_dir_20_percent = data_20_percent_path / "train"
# Configure las rutas del directorio de prueba (nota: use el mismo conjunto de datos de prueba para ambos para comparar los resultados)
test_dir = data_10_percent_path / "test"
# Consulta los directorios
print(f"Training directory 10%: {train_dir_10_percent}")
print(f"Training directory 20%: {train_dir_20_percent}")
print(f"Testing directory: {test_dir}")
7.4 Transformar conjuntos de datos y crear cargadores de datos¶
A continuación, crearemos una serie de transformaciones para preparar nuestras imágenes para nuestro(s) modelo(s).
Para mantener la coherencia, crearemos manualmente una transformación (tal como lo hicimos anteriormente) y usaremos la misma transformación en todos los conjuntos de datos.
La transformación:
- Cambie el tamaño de todas las imágenes (comenzaremos con 224, 224 pero esto podría cambiarse).
- Conviértelos en tensores con valores entre 0 y 1.
- Normalícelos de manera que sus distribuciones estén alineadas con el conjunto de datos de ImageNet (hacemos esto porque nuestros modelos de
torchvision.modelshan sido entrenados previamente en ImageNet).
from torchvision import transforms
# Cree una transformación para normalizar la distribución de datos para que esté en línea con ImageNet
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], # values per colour channel [red, green, blue]
std=[0.229, 0.224, 0.225]) # values per colour channel [red, green, blue]
# Compose se transforma en una canalización
simple_transform = transforms.Compose([
transforms.Resize((224, 224)), # 1. Resize the images
transforms.ToTensor(), # 2. Turn the images into tensors with values between 0 & 1
normalize # 3. Normalize the images so their distributions match the ImageNet dataset
])
¡Transfórmate listo!
Ahora creemos nuestros DataLoaders usando la función create_dataloaders() de data_setup.py que creamos en 05. PyTorch Going Modular sección 2.
Crearemos los DataLoaders con un tamaño de lote de 32.
Para todos nuestros experimentos usaremos el mismo test_dataloader (para mantener las comparaciones consistentes).
BATCH_SIZE = 32
# Cree un 10% de capacitación y pruebe DataLoaders
train_dataloader_10_percent, test_dataloader, class_names = data_setup.create_dataloaders(train_dir=train_dir_10_percent,
test_dir=test_dir,
transform=simple_transform,
batch_size=BATCH_SIZE
)
# Cree un 20 % de datos de prueba y entrenamiento DataLoders
train_dataloader_20_percent, test_dataloader, class_names = data_setup.create_dataloaders(train_dir=train_dir_20_percent,
test_dir=test_dir,
transform=simple_transform,
batch_size=BATCH_SIZE
)
# Encuentre la cantidad de muestras/lotes por cargador de datos (usando el mismo test_dataloader para ambos experimentos)
print(f"Number of batches of size {BATCH_SIZE} in 10 percent training data: {len(train_dataloader_10_percent)}")
print(f"Number of batches of size {BATCH_SIZE} in 20 percent training data: {len(train_dataloader_20_percent)}")
print(f"Number of batches of size {BATCH_SIZE} in testing data: {len(train_dataloader_10_percent)} (all experiments will use the same test set)")
print(f"Number of classes: {len(class_names)}, class names: {class_names}")
7.5 Crear modelos de extracción de características¶
Es hora de empezar a construir nuestros modelos.
Vamos a crear dos modelos de extractor de funciones:
torchvision.models.ficientnet_b0()columna vertebral previamente entrenada + cabezal clasificador personalizado (EffNetB0 para abreviar).torchvision.models.ficientnet_b2()columna vertebral previamente entrenada + cabezal clasificador personalizado (EffNetB2 para abreviar).
Para hacer esto, congelaremos las capas base (las capas de características) y actualizaremos los cabezales clasificadores del modelo (capas de salida) para adaptarnos a nuestro problema tal como lo hicimos en [06. Sección 3.4 de aprendizaje por transferencia de PyTorch] (https://www.learnpytorch.io/06_pytorch_transfer_learning/#34-freezing-the-base-model-and-changing-the-output-layer-to-suit-our-needs).
Vimos en el capítulo anterior que el parámetro in_features para el cabezal clasificador de EffNetB0 es 1280 (la columna vertebral convierte la imagen de entrada en un vector de características de tamaño 1280).
Dado que EffNetB2 tiene un número diferente de capas y parámetros, necesitaremos adaptarlo en consecuencia.
Nota: Siempre que utilices un modelo diferente, una de las primeras cosas que debes inspeccionar son las formas de entrada y salida. De esa manera sabrá cómo tendrá que preparar sus datos de entrada/actualizar el modelo para tener la forma de salida correcta.
Podemos encontrar las formas de entrada y salida de EffNetB2 usando torchinfo.summary() y pasando input_size=(32, 3, 224, 224) El parámetro ((32, 3, 224, 224) es equivalente a (batch_size, color_channels, height, width), es decir, pasamos un ejemplo de lo que sería un solo lote de datos a nuestro modelo).
Nota: Muchos modelos modernos pueden manejar imágenes de entrada de diferentes tamaños gracias a [
torch.nn.AdaptiveAvgPool2d()](https://pytorch.org/docs/stable/generated/torch.nn.AdaptiveAvgPool2d .html), esta capa ajusta de forma adaptativa eloutput_sizede una entrada determinada según sea necesario. Puede probar esto pasando imágenes de entrada de diferentes tamaños atorchinfo.summary()o a sus propios modelos usando la capa.
Para encontrar la forma de entrada requerida para la capa final de EffNetB2, hagamos lo siguiente:
- Cree una instancia de
torchvision.models.ficientnet_b2(pretrained=True). - Vea las diversas formas de entrada y salida ejecutando
torchinfo.summary(). - Imprima el número de
in_featuresinspeccionandostate_dict()de la parte del clasificador de EffNetB2 e imprimiendo la longitud de la matriz de peso.- Nota: También puedes simplemente inspeccionar la salida de
effnetb2.classifier.
- Nota: También puedes simplemente inspeccionar la salida de
import torchvision
from torchinfo import summary
# 1. Cree una instancia de EffNetB2 con pesos previamente entrenados.
effnetb2_weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT # "DEFAULT" means best available weights
effnetb2 = torchvision.models.efficientnet_b2(weights=effnetb2_weights)
# # 2. Obtenga un resumen del EffNetB2 estándar de torchvision.models (descomente el comentario para obtener un resultado completo)
# resumen (modelo = effnetb2,
# input_size=(32, 3, 224, 224), # asegúrese de que sea "input_size", no "input_shape"
# # col_names=["input_size"], # descomentar para resultados más pequeños
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"]
# )
# 3. Obtenga el número de características internas de la capa clasificadora EfficientNetB2.
print(f"Number of in_features to final layer of EfficientNetB2: {len(effnetb2.classifier.state_dict()['1.weight'][0])}")
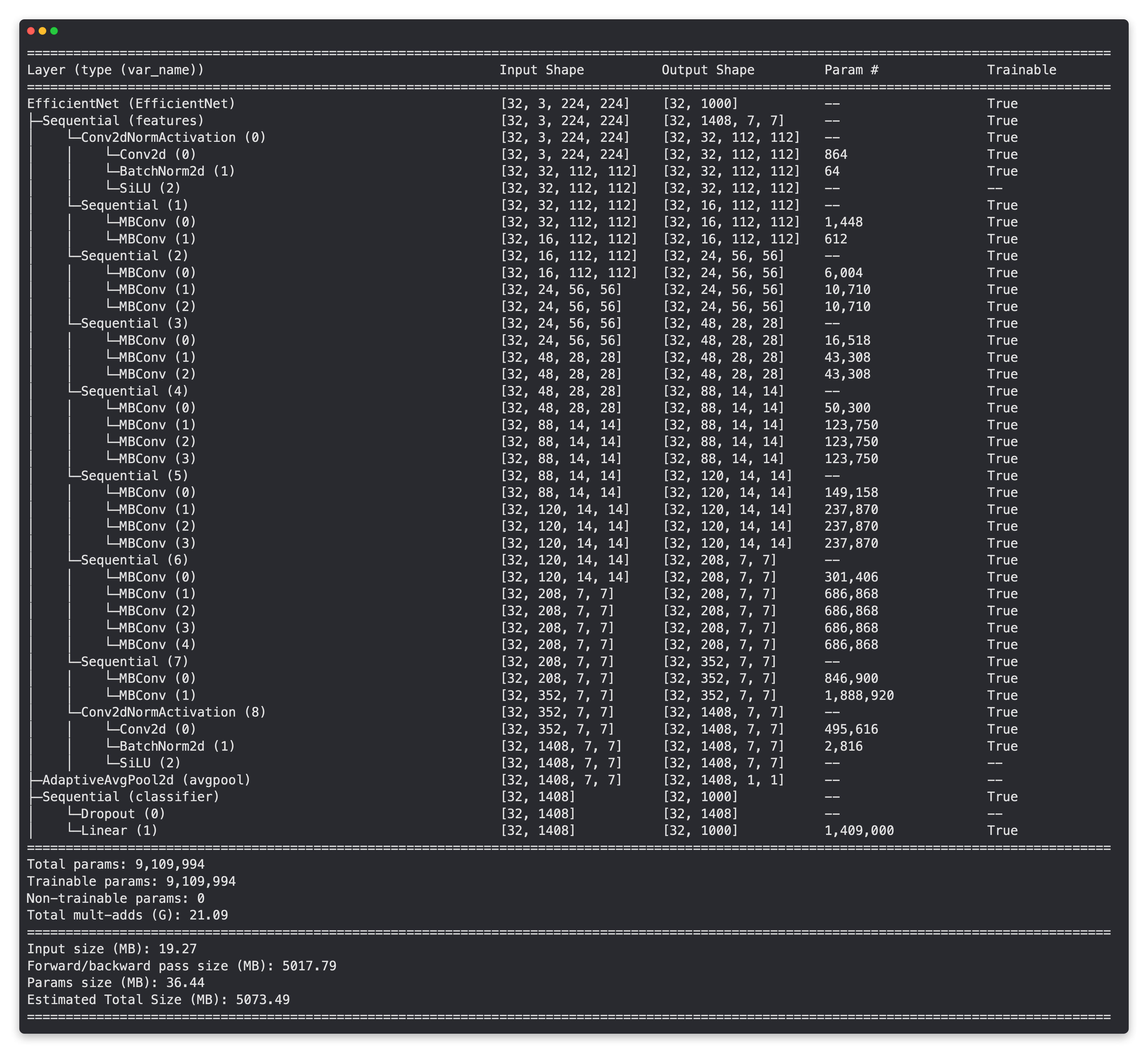
Resumen del modelo de extracción de características de EffNetB2 con todas las capas descongeladas (entrenables) y el cabezal clasificador predeterminado del preentrenamiento de ImageNet.
Ahora que sabemos la cantidad requerida de in_features para el modelo EffNetB2, creemos un par de funciones auxiliares para configurar nuestros modelos de extracción de características EffNetB0 y EffNetB2.
Queremos que estas funciones:
- Obtenga el modelo base de
torchvision.models - Congele las capas base en el modelo (establezca
requires_grad=False) - Establezca las semillas aleatorias (no necesitamos hacer esto, pero como estamos ejecutando una serie de experimentos e inicializando una nueva capa con pesos aleatorios, queremos que la aleatoriedad sea similar para cada experimento)
- Cambiar el cabezal clasificador (para adaptarlo a nuestro problema)
- Asigne un nombre al modelo (por ejemplo, "effnetb0" para EffNetB0)
import torchvision
from torch import nn
# Obtenga funciones numéricas (una para cada clase de pizza, bistec y sushi)
OUT_FEATURES = len(class_names)
# Cree un extractor de funciones EffNetB0
def create_effnetb0():
# 1. Get the base mdoel with pretrained weights and send to target device
weights = torchvision.models.EfficientNet_B0_Weights.DEFAULT
model = torchvision.models.efficientnet_b0(weights=weights).to(device)
# 2. Freeze the base model layers
for param in model.features.parameters():
param.requires_grad = False
# 3. Set the seeds
set_seeds()
# 4. Change the classifier head
model.classifier = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=1280, out_features=OUT_FEATURES)
).to(device)
# 5. Give the model a name
model.name = "effnetb0"
print(f"[INFO] Created new {model.name} model.")
return model
# Cree un extractor de funciones EffNetB2
def create_effnetb2():
# 1. Get the base model with pretrained weights and send to target device
weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
model = torchvision.models.efficientnet_b2(weights=weights).to(device)
# 2. Freeze the base model layers
for param in model.features.parameters():
param.requires_grad = False
# 3. Set the seeds
set_seeds()
# 4. Change the classifier head
model.classifier = nn.Sequential(
nn.Dropout(p=0.3),
nn.Linear(in_features=1408, out_features=OUT_FEATURES)
).to(device)
# 5. Give the model a name
model.name = "effnetb2"
print(f"[INFO] Created new {model.name} model.")
return model
¡Esas son algunas funciones bonitas!
Probemoslos creando una instancia de EffNetB0 y EffNetB2 y revisando su resumen().
effnetb0 = create_effnetb0()
# Obtenga un resumen de salida de las capas en nuestro modelo de extracción de características EffNetB0 (descomente el comentario para ver el resultado completo)
# resumen (modelo = effnetb0,
# input_size=(32, 3, 224, 224), # asegúrese de que sea "input_size", no "input_shape"
# # col_names=["input_size"], # descomentar para resultados más pequeños
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"]
# )
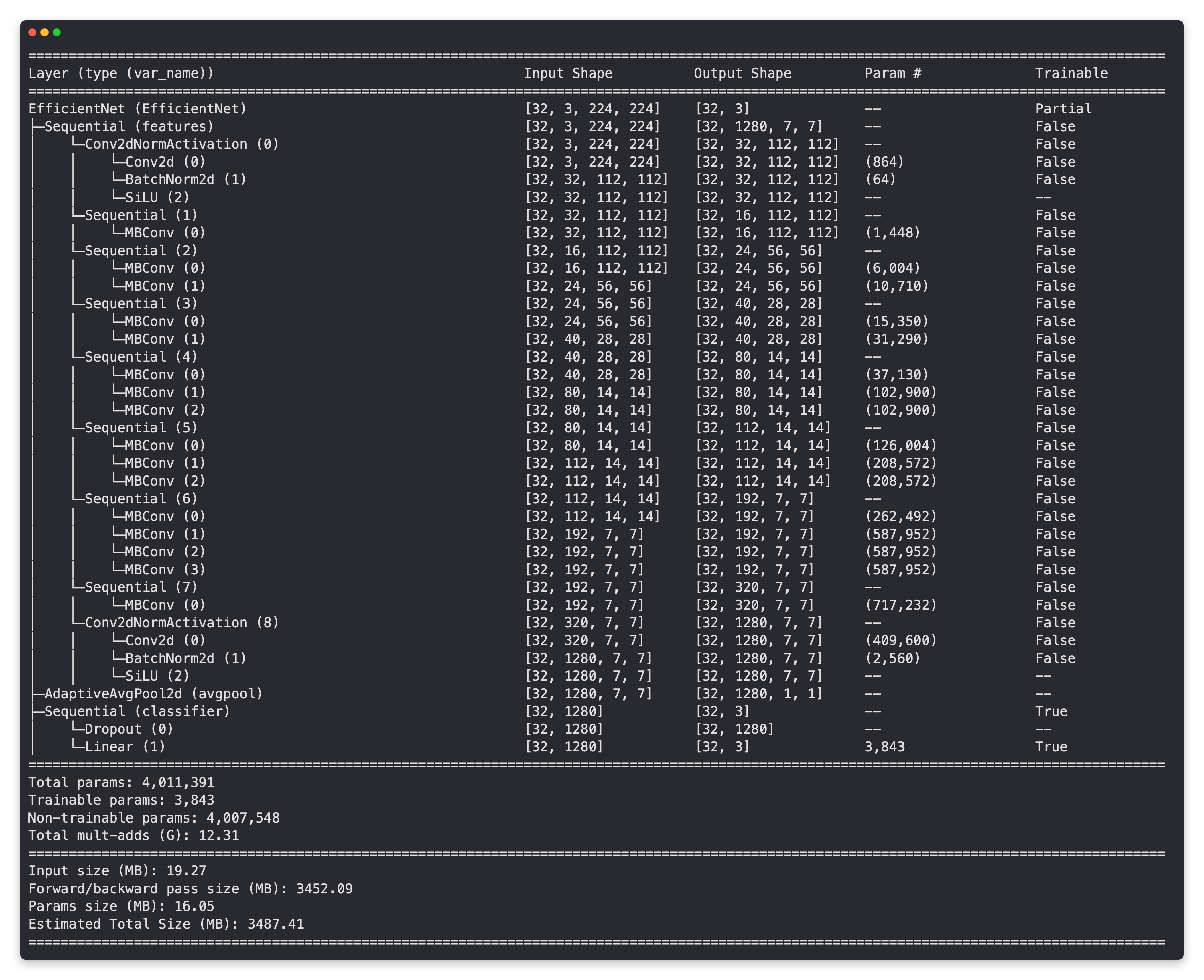
Resumen del modelo EffNetB0 con capas base congeladas (no entrenables) y cabezal clasificador actualizado (adecuado para clasificación de imágenes de pizza, bistec y sushi).
effnetb2 = create_effnetb2()
# Obtenga un resumen de salida de las capas en nuestro modelo de extracción de características EffNetB2 (elimine el comentario para ver la salida completa)
# resumen (modelo = effnetb2,
# input_size=(32, 3, 224, 224), # asegúrese de que sea "input_size", no "input_shape"
# # col_names=["input_size"], # descomentar para resultados más pequeños
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"]
# )
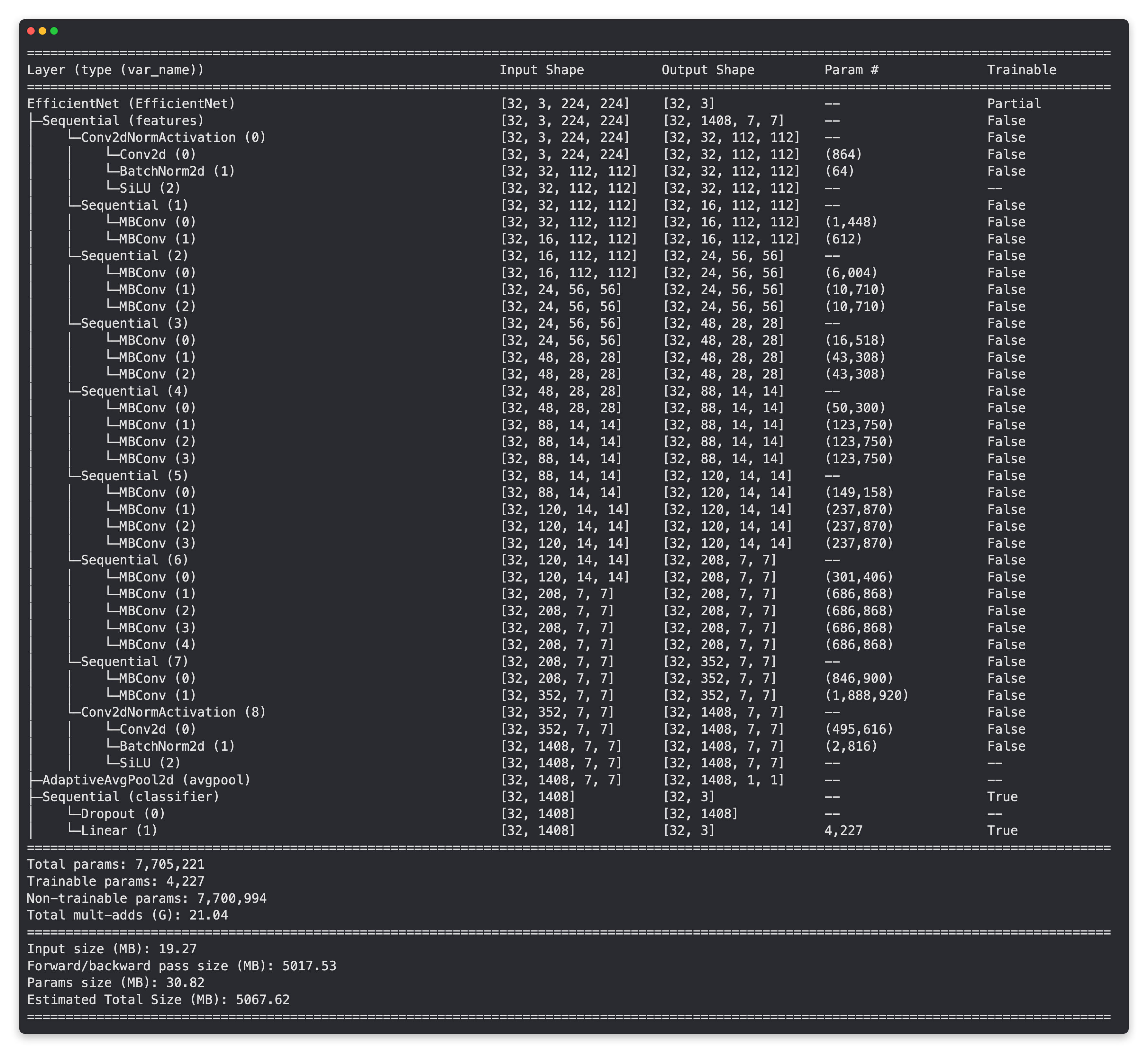
Resumen del modelo EffNetB2 con capas base congeladas (no entrenables) y cabezal clasificador actualizado (adecuado para clasificación de imágenes de pizza, bistec y sushi).
Al observar los resultados de los resúmenes, parece que la columna vertebral de EffNetB2 tiene casi el doble de parámetros que EffNetB0.
| Modelo | Parámetros totales (antes de congelar/cambiar cabezal) | Parámetros totales (después de congelar/cambiar cabezal) | Parámetros totales entrenables (después de congelar/cambiar el cabezal) |
|---|---|---|---|
| EfficientNetB0 | 5.288.548 | 4.011.391 | 3.843 |
| EfficientNetB2 | 9.109.994 | 7.705.221 | 4.227 |
Esto le da a la columna vertebral del modelo EffNetB2 más oportunidades para formar una representación de nuestros datos de pizza, bistec y sushi.
Sin embargo, los parámetros entrenables para cada modelo (los cabezales clasificadores) no son muy diferentes.
¿Estos parámetros adicionales conducirán a mejores resultados?
Tendremos que esperar y ver...
Nota: Con el ánimo de experimentar, realmente podrías probar casi cualquier modelo de
torchvision.modelsde manera similar a lo que estamos haciendo aquí. Solo elegí EffNetB0 y EffNetB2 como ejemplos. Quizás quieras incluir algo comotorchvision.models.convnext_tiny()otorchvision.models.convnext_small()en la mezcla.
7.6 Crear experimentos y configurar código de entrenamiento¶
Hemos preparado nuestros datos y nuestros modelos, ¡ha llegado el momento de configurar algunos experimentos!
Comenzaremos creando dos listas y un diccionario:
- Una lista del número de épocas que nos gustaría probar (
[5, 10]) - Una lista de los modelos que nos gustaría probar (
["effnetb0", "effnetb2"]) - Un diccionario de los diferentes DataLoaders de entrenamiento
# 1. Crear lista de épocas
num_epochs = [5, 10]
# 2. Crear lista de modelos (es necesario crear un nuevo modelo para cada experimento)
models = ["effnetb0", "effnetb2"]
# 3. Cree un diccionario de cargadores de datos para varios cargadores de datos.
train_dataloaders = {"data_10_percent": train_dataloader_10_percent,
"data_20_percent": train_dataloader_20_percent}
¡Listas y diccionario creados!
Ahora podemos escribir código para recorrer cada una de las diferentes opciones y probar cada una de las diferentes combinaciones.
También guardaremos el modelo al final de cada experimento para que luego podamos volver a cargarlo en el mejor modelo y usarlo para hacer predicciones.
Específicamente, sigamos los siguientes pasos:
- Establezca las semillas aleatorias (para que los resultados de nuestro experimento sean reproducibles; en la práctica, puede ejecutar el mismo experimento en ~3 semillas diferentes y promediar los resultados).
- Mantenga un registro de los diferentes números de experimentos (esto es principalmente para impresiones bonitas).
- Recorra los elementos del diccionario
train_dataloaderspara cada uno de los diferentes DataLoaders de entrenamiento. - Recorra la lista de números de época.
- Recorra la lista de diferentes nombres de modelos.
- Cree impresiones de información para el experimento en ejecución actual (para que sepamos qué está sucediendo).
- Verifique qué modelo es el modelo objetivo y cree una nueva instancia de EffNetB0 o EffNetB2 (creamos una nueva instancia de modelo en cada experimento para que todos los modelos comiencen desde el mismo punto de vista).
- Cree una nueva función de pérdida (
torch.nn.CrossEntropyLoss()) y un optimizador (torch.optim.Adam(params=model.parameters(), lr=0.001)) para cada nuevo experimento. - Entrene el modelo con la función
train()modificada pasando los detalles apropiados al parámetrowriter. - Guarde el modelo entrenado con un nombre de archivo apropiado en el archivo
save_model()de [utils.py](https://github.com/mrdbourke/pytorch-deep-learning/blob/main/going_modular/ Going_modular/utils.py).
También podemos usar la magia %%time para ver cuánto tiempo toman todos nuestros experimentos juntos en una sola celda de Jupyter/Google Colab.
¡Vamos a hacerlo!
%%time
from going_modular.going_modular.utils import save_model
# 1. Establece las semillas aleatorias
set_seeds(seed=42)
# 2. Realice un seguimiento de los números de los experimentos
experiment_number = 0
# 3. Recorra cada DataLoader
for dataloader_name, train_dataloader in train_dataloaders.items():
# 4. Loop through each number of epochs
for epochs in num_epochs:
# 5. Loop through each model name and create a new model based on the name
for model_name in models:
# 6. Create information print outs
experiment_number += 1
print(f"[INFO] Experiment number: {experiment_number}")
print(f"[INFO] Model: {model_name}")
print(f"[INFO] DataLoader: {dataloader_name}")
print(f"[INFO] Number of epochs: {epochs}")
# 7. Select the model
if model_name == "effnetb0":
model = create_effnetb0() # creates a new model each time (important because we want each experiment to start from scratch)
else:
model = create_effnetb2() # creates a new model each time (important because we want each experiment to start from scratch)
# 8. Create a new loss and optimizer for every model
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001)
# 9. Train target model with target dataloaders and track experiments
train(model=model,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=epochs,
device=device,
writer=create_writer(experiment_name=dataloader_name,
model_name=model_name,
extra=f"{epochs}_epochs"))
# 10. Save the model to file so we can get back the best model
save_filepath = f"07_{model_name}_{dataloader_name}_{epochs}_epochs.pth"
save_model(model=model,
target_dir="models",
model_name=save_filepath)
print("-"*50 + "\n")
8. Ver experimentos en TensorBoard¶
¡Ho, ho!
¡Míranos ir!
¿Entrenar ocho modelos de una sola vez?
¡Eso sí que está a la altura del lema!
¡Experimenta, experimenta, experimenta!
¿Qué tal si comprobamos los resultados en TensorBoard?
# Visualización de TensorBoard en Jupyter y Google Colab Notebooks (elimine el comentario para ver la instancia completa de TensorBoard)
# %load_ext tensorboard
# % tensorboard --logdir se ejecuta
Al ejecutar la celda de arriba deberíamos obtener un resultado similar al siguiente.
Nota: Dependiendo de las semillas aleatorias que usaste/el hardware que usaste, existe la posibilidad de que tus números no sean exactamente los mismos que los que aparecen aquí. Esto está bien. Se debe a la aleatoriedad inherente del aprendizaje profundo. Lo que más importa es la tendencia. Hacia dónde se dirigen tus números. Si están muy desviados, tal vez haya algún problema y sea mejor volver atrás y verificar el código. Pero si están ligeramente desviados (digamos un par de decimales más o menos), está bien.
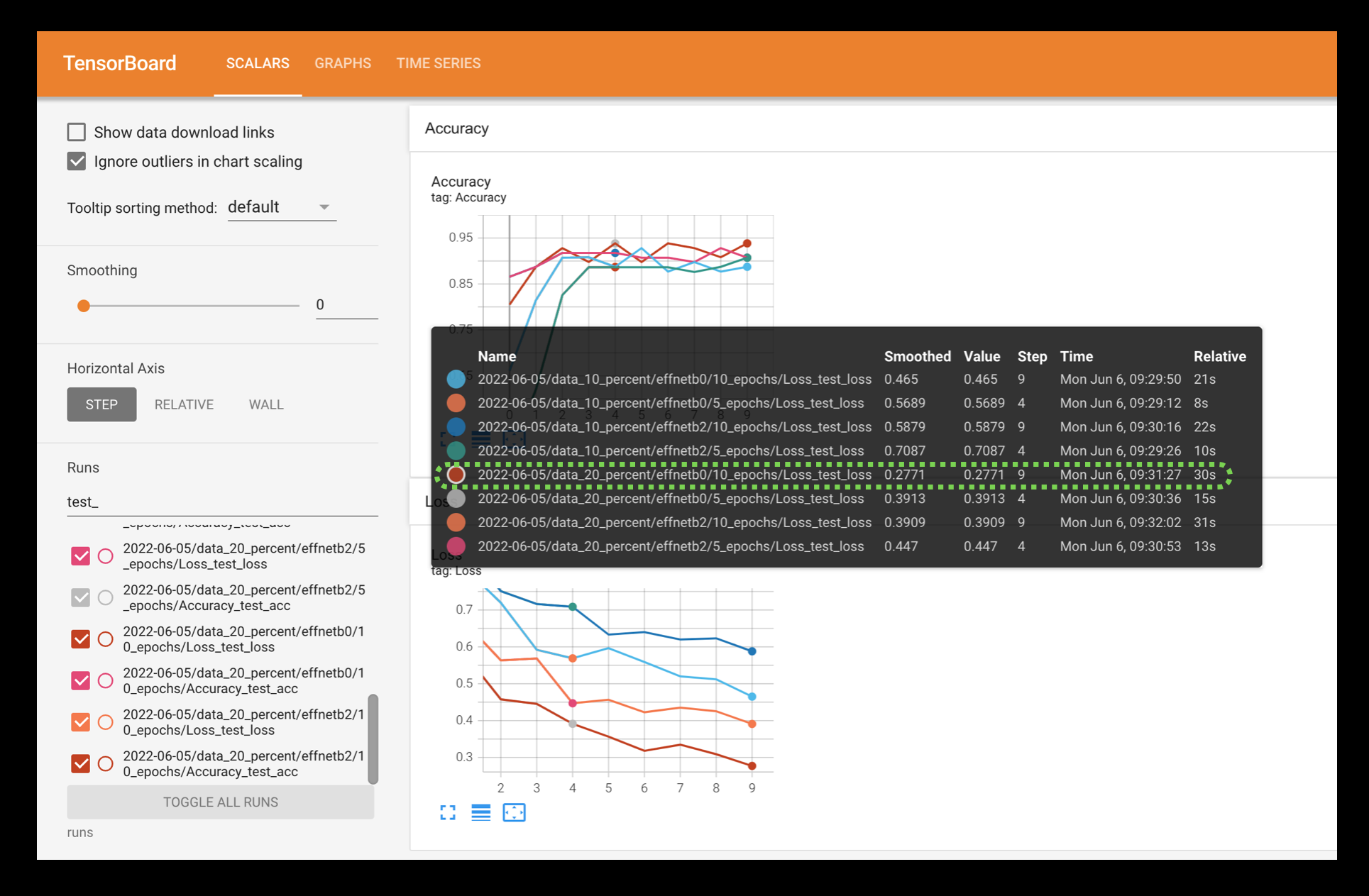
Al visualizar los valores de pérdida de prueba para los diferentes experimentos de modelado en TensorBoard, se puede ver que el modelo EffNetB0 entrenado durante 10 épocas y con el 20% de los datos logra la pérdida más baja. Esto se mantiene con la tendencia general de los experimentos de que: más datos, un modelo más grande y un tiempo de entrenamiento más largo es generalmente mejor.
También puede cargar los resultados de su experimento de TensorBoard en tensorboard.dev para alojarlos públicamente de forma gratuita.
Por ejemplo, ejecutando código similar al siguiente:
# # Sube los resultados a TensorBoard.dev (descomenta para probarlo)
# !tensorboard dev upload --logdir se ejecuta \
# --name "07. Seguimiento de experimentos de PyTorch: resultados del modelo FoodVision Mini" \
# --description "Comparación de resultados de diferentes tamaños de modelo, cantidad de datos de entrenamiento y tiempo de entrenamiento".
Al ejecutar la celda anterior, los experimentos de este cuaderno se pueden ver públicamente en: https://tensorboard.dev/experiment/VySxUYY7Rje0xREYvCvZXA/
Nota: Tenga en cuenta que todo lo que cargue en tensorboard.dev estará disponible públicamente para que cualquiera lo vea. Entonces, si carga sus experimentos, tenga cuidado de que no contengan información confidencial.
9. Cargue el mejor modelo y haga predicciones con él.¶
Al observar los registros de TensorBoard para nuestros ocho experimentos, parece que el experimento número ocho logró los mejores resultados generales (mayor precisión de prueba, segunda pérdida de prueba más baja).
Este es el experimento que utilizó:
- EffNetB2 (duplica los parámetros de EffNetB0)
- 20% de datos de entrenamiento de pizza, bistec y sushi (el doble de los datos de entrenamiento originales)
- 10 épocas (el doble del tiempo de entrenamiento original)
En esencia, nuestro modelo más grande logró los mejores resultados.
Aunque no es que estos resultados fueran mucho mejores que los de otros modelos.
El mismo modelo con los mismos datos logró resultados similares en la mitad del tiempo de entrenamiento (experimento número 6).
Esto sugiere que potencialmente las partes más influyentes de nuestros experimentos fueron la cantidad de parámetros y la cantidad de datos.
Al inspeccionar más a fondo los resultados, parece que, en general, un modelo con más parámetros (EffNetB2) y más datos (20% de datos de entrenamiento de pizza, bistec y sushi) funciona mejor (menor pérdida de prueba y mayor precisión de la prueba).
Se podrían realizar más experimentos para probar esto más a fondo, pero por ahora, importemos nuestro modelo de mejor rendimiento del experimento ocho (guardado en: models/07_effnetb2_data_20_percent_10_epochs.pth, puede [descargar este modelo del curso GitHub](https:// github.com/mrdbourke/pytorch-deep-learning/blob/main/models/07_effnetb2_data_20_percent_10_epochs.pth)) y realice algunas evaluaciones cualitativas.
En otras palabras, ¡visualicemos, visualicemos, visualicemos!*
Podemos importar el mejor modelo guardado creando una nueva instancia de EffNetB2 usando la función create_effnetb2() y luego cargar el state_dict() guardado con torch.load().
# Configure la mejor ruta de archivo del modelo
best_model_path = "models/07_effnetb2_data_20_percent_10_epochs.pth"
# Crear una nueva instancia de EffNetB2 (para cargar el state_dict() guardado en)
best_model = create_effnetb2()
# Cargue el mejor modelo guardado state_dict()
best_model.load_state_dict(torch.load(best_model_path))
¡El mejor modelo cargado!
Mientras estamos aquí, revisemos su tamaño de archivo.
Esta es una consideración importante más adelante al implementar el modelo (incorporarlo a una aplicación).
Si el modelo es demasiado grande, puede resultar difícil implementarlo.
# Verifique el tamaño del archivo del modelo
from pathlib import Path
# Obtenga el tamaño del modelo en bytes y luego conviértalo a megabytes
effnetb2_model_size = Path(best_model_path).stat().st_size // (1024*1024)
print(f"EfficientNetB2 feature extractor model size: {effnetb2_model_size} MB")
Parece que nuestro mejor modelo hasta ahora tiene un tamaño de 29 MB. Tendremos esto en cuenta si quisiéramos implementarlo más adelante.
Es hora de hacer y visualizar algunas predicciones.
Creamos una función pred_and_plot_image() para usar un modelo entrenado para hacer predicciones sobre una imagen en [06. Sección 6 del aprendizaje por transferencia de PyTorch] (https://www.learnpytorch.io/06_pytorch_transfer_learning/#6-make-predictions-on-images-from-the-test-set).
Y podemos reutilizar esta función importándola desde going_modular.going_modular.predictions.py (Puse la función pred_and_plot_image() en un script para poder reutilizarla).
Entonces, para hacer predicciones sobre varias imágenes que el modelo no ha visto antes, primero obtendremos una lista de todas las rutas de archivos de imágenes del conjunto de datos de prueba de 20% de pizza, bistec y sushi y luego seleccionaremos aleatoriamente un subconjunto de estas rutas de archivos. para pasar a nuestra función pred_and_plot_image().
# Función de importación para hacer predicciones sobre imágenes y trazarlas.
# Consulte la función creada anteriormente en la sección: https://www.learnpytorch.io/06_pytorch_transfer_learning/#6-make-predictions-on-images-from-the-test-set
from going_modular.going_modular.predictions import pred_and_plot_image
# Obtenga una lista aleatoria de 3 imágenes del 20 % del conjunto de prueba
import random
num_images_to_plot = 3
test_image_path_list = list(Path(data_20_percent_path / "test").glob("*/*.jpg")) # get all test image paths from 20% dataset
test_image_path_sample = random.sample(population=test_image_path_list,
k=num_images_to_plot) # randomly select k number of images
# Iterar a través de rutas de imágenes de prueba aleatorias, hacer predicciones sobre ellas y trazarlas
for image_path in test_image_path_sample:
pred_and_plot_image(model=best_model,
image_path=image_path,
class_names=class_names,
image_size=(224, 224))
¡Lindo!
Al ejecutar la celda de arriba varias veces, podemos ver que nuestro modelo funciona bastante bien y, a menudo, tiene mayores probabilidades de predicción que los modelos anteriores que hemos creado.
Esto sugiere que el modelo tiene más confianza en las decisiones que toma.
9.1 Predecir en una imagen personalizada con el mejor modelo¶
Hacer predicciones sobre el conjunto de datos de prueba es genial, pero la verdadera magia del aprendizaje automático es hacer predicciones sobre sus propias imágenes personalizadas.
Entonces, importemos la confiable imagen del papá de la pizza (una foto de mi papá frente a una pizza) que hemos estado usando durante las últimas secciones y ver cómo funciona nuestro modelo en ella.
{kind=link}
# Descargar imagen personalizada
import requests
# Configurar ruta de imagen personalizada
custom_image_path = Path("data/04-pizza-dad.jpeg")
# Descarga la imagen si aún no existe
if not custom_image_path.is_file():
with open(custom_image_path, "wb") as f:
# When downloading from GitHub, need to use the "raw" file link
request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/images/04-pizza-dad.jpeg")
print(f"Downloading {custom_image_path}...")
f.write(request.content)
else:
print(f"{custom_image_path} already exists, skipping download.")
# Predecir en imagen personalizada
pred_and_plot_image(model=model,
image_path=custom_image_path,
class_names=class_names)
¡Guau!
¡Dos pulgares otra vez!
Nuestro mejor modelo predice "pizza" correctamente y esta vez con una probabilidad de predicción aún mayor (0,978) que el primer modelo de extracción de características que entrenamos y utilizamos en [06. Sección 6.1 de aprendizaje por transferencia de PyTorch] (https://www.learnpytorch.io/06_pytorch_transfer_learning/#61-making-predictions-on-a-custom-image).
Esto nuevamente sugiere que nuestro mejor modelo actual (el extractor de características EffNetB2 entrenado en el 20% de los datos de entrenamiento de pizza, bistec y sushi y durante 10 épocas) ha aprendido patrones para que tenga más confianza en su decisión de predecir la pizza.
Me pregunto qué podría mejorar aún más el rendimiento de nuestro modelo.
Te lo dejaré como un desafío para que investigues.
Principales conclusiones¶
Ahora hemos completado el círculo en el flujo de trabajo de PyTorch introducido en [01. Fundamentos del flujo de trabajo de PyTorch] (https://www.learnpytorch.io/01_pytorch_workflow/), preparamos los datos, creamos y elegimos un modelo previamente entrenado, utilizamos nuestras diversas funciones auxiliares para entrenar y evaluar el modelo. y en este cuaderno hemos mejorado nuestro modelo FoodVision Mini ejecutando y rastreando una serie de experimentos.
Deberías estar orgulloso de ti mismo, ¡esto no es poca cosa!
Las ideas principales que debes extraer de este Proyecto Hito 1 son:
- El lema del profesional del aprendizaje automático: ¡experimenta, experimenta, experimenta! (aunque ya hemos estado haciendo mucho de esto).
- Al principio, mantenga sus experimentos pequeños para que pueda trabajar rápido; sus primeros experimentos no deberían tardar más de unos segundos o unos minutos en ejecutarse.
- Cuantos más experimentos hagas, más rápido podrás descubrir qué no funciona.
- Aumente la escala cuando encuentre algo que funcione. Por ejemplo, dado que hemos encontrado un modelo con un rendimiento bastante bueno con EffNetB2 como extractor de funciones, tal vez ahora le gustaría ver qué sucede cuando lo amplía a todo el [conjunto de datos de Food101](https://pytorch.org /vision/main/generated/torchvision.datasets.Food101.html) de
torchvision.datasets. - El seguimiento programático de sus experimentos requiere algunos pasos para configurarlo, pero a la larga vale la pena para que pueda descubrir qué funciona y qué no.
- Existen muchos rastreadores de experimentos de aprendizaje automático diferentes, así que explore algunos y pruébelos.
Ejercicios¶
Nota: Estos ejercicios requieren el uso de
torchvisionv0.13+ (lanzado en julio de 2022); las versiones anteriores pueden funcionar, pero probablemente tendrán errores.
Todos los ejercicios se centran en practicar el código anterior.
Debería poder completarlos haciendo referencia a cada sección o siguiendo los recursos vinculados.
Todos los ejercicios deben completarse utilizando código independiente del dispositivo.
Recursos:
- Cuaderno de plantilla de ejercicios para 07
- Cuaderno de soluciones de ejemplo para 07 (pruebe los ejercicios antes de mirar esto)
- Vea un [video tutorial de las soluciones en YouTube] en vivo (https://youtu.be/cO_r2FYcAjU) (errores y todo)
- Elija un modelo más grande de
torchvision.modelspara agregarlo a la lista de experimentos (por ejemplo, EffNetB3 o superior).- ¿Cómo funciona en comparación con nuestros modelos existentes?
- Introduzca el aumento de datos en la lista de experimentos que utilizan conjuntos de datos de prueba y entrenamiento de pizza, bistec y sushi al 20%. ¿Esto cambia algo?
- Por ejemplo, podría tener un DataLoader de entrenamiento que utilice aumento de datos (por ejemplo,
train_dataloader_20_percent_augytrain_dataloader_20_percent_no_aug) y luego comparar los resultados de dos tipos de modelos iguales entrenando en estos dos DataLoaders. - Nota: Es posible que necesite modificar la función
create_dataloaders()para poder realizar una transformación para los datos de entrenamiento y los datos de prueba (porque no necesita realizar un aumento de datos en los datos de prueba) . Ver [04. Sección 6 de conjuntos de datos personalizados de PyTorch] (https://www.learnpytorch.io/04_pytorch_custom_datasets/#6-other-forms-of-transforms-data-augmentation) para ver ejemplos de uso del aumento de datos o el siguiente script para ver un ejemplo:
- Por ejemplo, podría tener un DataLoader de entrenamiento que utilice aumento de datos (por ejemplo,
pitón
# Nota: Una transformación de aumento de datos como esta solo debe realizarse en datos de entrenamiento
train_transform_data_aug = transforma.Compose([
transforma.Resize((224, 224)),
transforma.TrivialAugmentWide(),
transforma.ToTensor(),
normalizar
])
# Función auxiliar para ver imágenes en un DataLoader (funciona con transformaciones de aumento de datos o no)
def view_dataloader_images(cargador de datos, n=10):
si norte > 10:
print(f"Tener n mayor que 10 creará gráficos desordenados, reduciéndolos a 10.")
norte = 10
imgs, etiquetas = siguiente (iter (cargador de datos))
plt.figura(tamaño de figura=(16, 8))
para i en el rango (n):
# Escala mínima máxima de la imagen para fines de visualización
targ_image = imágenes[i]
sample_min, sample_max = targ_image.min(), targ_image.max()
sample_scaled = (targ_image - sample_min)/(sample_max - sample_min)
# Trazar imágenes con información de ejes apropiada
plt.subtrama(1, 10, i+1)
plt.imshow(sample_scaled.permute(1, 2, 0)) # cambiar el tamaño para los requisitos de Matplotlib
plt.title(nombres_clase[etiquetas[i]])
eje.plt(Falso)
# Tenemos que actualizar `create_dataloaders()` para manejar diferentes aumentos
importar sistema operativo
desde torch.utils.data importar DataLoader
desde conjuntos de datos de importación de torchvision
NUM_WORKERS = os.cpu_count() # usa el número máximo de CPU para que los trabajadores carguen datos
# Nota: esta es una versión actualizada de data_setup.create_dataloaders para manejar
# diferentes transformaciones de tren y prueba.
def crear_cargadores de datos (
tren_dir,
dir_prueba,
train_transform, # agrega parámetro para la transformación del tren (transformaciones en el conjunto de datos del tren)
test_transform, # agrega parámetro para la transformación de prueba (transformaciones en el conjunto de datos de prueba)
tamaño_lote=32, num_trabajadores=NUM_TRABAJADORES
):
# Utilice ImageFolder para crear conjuntos de datos
train_data = conjuntos de datos.ImageFolder(train_dir, transform=train_transform)
test_data = conjuntos de datos.ImageFolder(test_dir, transform=test_transform)
# Obtener nombres de clases
nombres_clase = datos_tren.clases
# Convertir imágenes en cargadores de datos
train_dataloader = Cargador de datos(
datos_tren,
tamaño_lote = tamaño_lote,
barajar = Verdadero,
num_trabajadores=num_trabajadores,
pin_memory=Verdadero,
)
test_dataloader = Cargador de datos(
datos de prueba,
tamaño_lote = tamaño_lote,
barajar = Verdadero,
num_trabajadores=num_trabajadores,
pin_memory=Verdadero,
)
devolver train_dataloader, test_dataloader, class_names
- Amplíe el conjunto de datos para convertir FoodVision Mini en FoodVision Big utilizando todo el [conjunto de datos Food101 de
torchvision.models](https://pytorch.org/vision/stable/generated/torchvision.datasets.Food101.html#torchvision .conjuntos de datos.Food101)- Podría tomar el modelo de mejor rendimiento de sus diversos experimentos o incluso el extractor de funciones EffNetB2 que creamos en este cuaderno y ver cómo se adapta durante 5 épocas en todo Food101.
- Si prueba más de un modelo, sería bueno realizar un seguimiento de los resultados del modelo.
- Si carga el conjunto de datos Food101 desde
torchvision.models, deberá crear PyTorch DataLoaders para usarlo en el entrenamiento. - Nota: Debido a la mayor cantidad de datos en Food101 en comparación con nuestro conjunto de datos de pizza, bistec y sushi, este modelo tardará más en entrenarse.
Extracurricular¶
- Lea la publicación del blog The Bitter Lesson de Richard Sutton para tener una idea de cuántos de los últimos avances en IA provienen de una mayor escala (conjuntos de datos más grandes). y modelos más grandes) y métodos más generales (menos meticulosamente elaborados).
- Consulte el tutorial de código/YouTube de PyTorch para TensorBoard durante 20 minutos y vea cómo se compara con el código que hemos escrito en este computadora portátil.
- Quizás quieras ver y reorganizar los registros de TensorBoard de tu modelo con un DataFrame (para que puedas ordenar los resultados por menor pérdida o mayor precisión), hay una guía para esto [en la documentación de TensorBoard] (https://www.tensorflow .org/tensorboard/dataframe_api).
- Si desea usar VSCode para el desarrollo usando scripts o cuadernos (VSCode ahora puede usar Jupyter Notebooks de forma nativa), puede configurar TensorBoard directamente dentro de VSCode usando la [Guía de desarrollo de PyTorch en VSCode] (https://code.visualstudio.com/ documentos/datascience/pytorch-support).
- Para ir más allá con el seguimiento de experimentos y ver cómo se está desempeñando su modelo PyTorch desde una perspectiva de velocidad (¿hay algún cuello de botella que podría mejorarse para acelerar el entrenamiento?), consulte la [documentación de PyTorch para el generador de perfiles de PyTorch](https:// pytorch.org/blog/introduciendo-pytorch-profiler-the-new-and-improved-rendimiento-herramienta/).
- Made With ML es un excelente recurso para todo lo relacionado con el aprendizaje automático de Goku Mohandas y su guía sobre seguimiento de experimentos contiene una fantástica introducción al seguimiento del aprendizaje automático. experimentos con MLflow.