04. Conjuntos de datos personalizados de PyTorch¶
En el último cuaderno, [cuaderno 03] (https://www.learnpytorch.io/03_pytorch_computer_vision/), analizamos cómo crear modelos de visión por computadora en un conjunto de datos integrado en PyTorch (FashionMNIST).
Los pasos que tomamos son similares en muchos problemas diferentes del aprendizaje automático.
Encuentre un conjunto de datos, convierta el conjunto de datos en números, cree un modelo (o encuentre un modelo existente) para encontrar patrones en esos números que puedan usarse para la predicción.
PyTorch tiene muchos conjuntos de datos integrados que se utilizan para una gran cantidad de puntos de referencia de aprendizaje automático; sin embargo, a menudo querrás usar tu propio conjunto de datos personalizado.
¿Qué es un conjunto de datos personalizado?¶
Un conjunto de datos personalizado es una colección de datos relacionados con un problema específico en el que estás trabajando.
En esencia, un conjunto de datos personalizado puede estar compuesto por casi cualquier cosa.
Por ejemplo, si estuviéramos creando una aplicación de clasificación de imágenes de alimentos como Nutrify, nuestro conjunto de datos personalizado podrían ser imágenes de alimentos.
O si intentáramos crear un modelo para clasificar si una reseña basada en texto en un sitio web fue positiva o negativa, nuestro conjunto de datos personalizado podría ser ejemplos de reseñas de clientes existentes y sus calificaciones.
O si intentáramos crear una aplicación de clasificación de sonido, nuestro conjunto de datos personalizado podría ser muestras de sonido junto con sus etiquetas de muestra.
O si intentáramos crear un sistema de recomendación para los clientes que compran cosas en nuestro sitio web, nuestro conjunto de datos personalizado podría ser ejemplos de productos que otras personas han comprado.

PyTorch incluye muchas funciones existentes para cargar en varios conjuntos de datos personalizados en TorchVision, [TorchText](https://pytorch.org /text/stable/index.html), TorchAudio y TorchRec bibliotecas de dominio.
Pero a veces estas funciones existentes pueden no ser suficientes.
En ese caso, siempre podemos crear una subclase de torch.utils.data.Dataset y personalizarla a nuestro gusto.
Qué vamos a cubrir¶
Aplicaremos el flujo de trabajo de PyTorch que cubrimos en el [cuaderno 01] (https://www.learnpytorch.io/01_pytorch_workflow/) y el [cuaderno 02] (https://www.learnpytorch.io/02_pytorch_classification/) a un problema de visión por computadora.
Pero en lugar de utilizar un conjunto de datos PyTorch incorporado, usaremos nuestro propio conjunto de datos de imágenes de pizza, bistec y sushi.
El objetivo será cargar estas imágenes y luego construir un modelo para entrenarlas y predecirlas.
Qué vamos a construir. Usaremos torchvision.datasets así como nuestra propia clase Dataset personalizada para cargar imágenes de alimentos y luego construiremos un modelo de visión por computadora PyTorch para, con suerte, poder clasificarlas.
Específicamente, cubriremos:
| Tema | Contenido |
|---|---|
| 0. Importación de PyTorch y configuración de código independiente del dispositivo | Carguemos PyTorch y luego sigamos las mejores prácticas para configurar nuestro código para que sea independiente del dispositivo. |
| 1. Obtener datos | Usaremos nuestro propio conjunto de datos personalizado de imágenes de pizza, bistec y sushi. |
| 2. Conviértete en uno con los datos (preparación de datos) | Al comienzo de cualquier problema nuevo de aprendizaje automático, es fundamental comprender los datos con los que se está trabajando. Aquí tomaremos algunos pasos para determinar qué datos tenemos. |
| 3. Transformación de datos | A menudo, los datos que obtienes no estarán 100% listos para usar con un modelo de aprendizaje automático. Aquí veremos algunos pasos que podemos seguir para transformar nuestras imágenes para que estén listas para ser usado con un modelo. |
4. Cargando datos con ImageFolder (opción 1) |
PyTorch tiene muchas funciones de carga de datos integradas para tipos de datos comunes. ImageFolder es útil si nuestras imágenes están en formato de clasificación de imágenes estándar. |
5. Cargando datos de imagen con un Conjunto de datos personalizado |
¿Qué pasaría si PyTorch no tuviera una función incorporada para cargar datos? Aquí es donde podemos crear nuestra propia subclase personalizada de torch.utils.data.Dataset. |
| 6. Otras formas de transformaciones (aumento de datos) | El aumento de datos es una técnica común para ampliar la diversidad de sus datos de entrenamiento. Aquí exploraremos algunas de las funciones de aumento de datos integradas de torchvision. |
| 7. Modelo 0: TinyVGG sin aumento de datos | En esta etapa, tendremos nuestros datos listos, construyamos un modelo capaz de ajustarlos. También crearemos algunas funciones de entrenamiento y prueba para entrenar y evaluar nuestro modelo. |
| 8. Explorando curvas de pérdidas | Las curvas de pérdida son una excelente manera de ver cómo su modelo se entrena o mejora con el tiempo. También son una buena manera de ver si su modelo está bajo ajuste o sobreajuste. |
| 9. Modelo 1: TinyVGG con aumento de datos | Hasta ahora, hemos probado un modelo sin, ¿qué tal si probamos uno con aumento de datos? |
| 10. Comparar resultados de modelos | Comparemos las curvas de pérdida de nuestros diferentes modelos y veamos cuál funcionó mejor y analicemos algunas opciones para mejorar el rendimiento. |
| 11. Hacer una predicción en una imagen personalizada | Nuestro modelo está entrenado en un conjunto de datos de imágenes de pizza, bistec y sushi. En esta sección cubriremos cómo usar nuestro modelo entrenado para predecir en una imagen fuera de nuestro conjunto de datos existente. |
¿Dónde puedes conseguir ayuda?¶
Todos los materiales de este curso en vivo en GitHub.
Si tiene problemas, también puede hacer una pregunta en el curso página de debates de GitHub.
Y, por supuesto, está la documentación de PyTorch y los foros de desarrolladores de PyTorch, un lugar muy útil para todo lo relacionado con PyTorch.
0. Importación de PyTorch y configuración de código independiente del dispositivo¶
import torch
from torch import nn
# Nota: este portátil requiere antorcha >= 1.10.0
torch.__version__
Y ahora sigamos las mejores prácticas y configuremos el código independiente del dispositivo.
Nota: Si estás usando Google Colab y aún no tienes una GPU activada, ahora es el momento de activar una a través de
Runtime -> Cambiar tipo de tiempo de ejecución -> Acelerador de hardware -> GPU. Si hace esto, es probable que su tiempo de ejecución se reinicie y tendrá que ejecutar todas las celdas anteriores yendo a "Tiempo de ejecución -> Ejecutar antes".
# Configurar código independiente del dispositivo
device = "cuda" if torch.cuda.is_available() else "cpu"
device
1. Obtener datos¶
Lo primero es lo primero que necesitamos algunos datos.
Y como todo buen programa de cocina, ya nos tienen preparados algunos datos.
Vamos a empezar poco a poco.
Porque todavía no buscamos entrenar el modelo más grande ni utilizar el conjunto de datos más grande.
El aprendizaje automático es un proceso iterativo: comience poco a poco, haga que algo funcione y aumente cuando sea necesario.
Los datos que usaremos son un subconjunto del [conjunto de datos Food101] (https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/).
Food101 es un popular punto de referencia de visión por computadora, ya que contiene 1000 imágenes de 101 tipos diferentes de alimentos, con un total de 101 000 imágenes (75 750 de tren y 25 250 de prueba).
¿Puedes pensar en 101 alimentos diferentes?
¿Se te ocurre un programa informático para clasificar 101 alimentos?
Puedo.
¡Un modelo de aprendizaje automático!
Específicamente, un modelo de visión por computadora de PyTorch como el que cubrimos en el [cuaderno 03] (https://www.learnpytorch.io/03_pytorch_computer_vision/).
Sin embargo, en lugar de 101 clases de comida, comenzaremos con 3: pizza, bistec y sushi.
Y en lugar de 1000 imágenes por clase, comenzaremos con un 10% aleatorio (comience poco a poco, aumente cuando sea necesario).
Si desea ver de dónde provienen los datos, consulte los siguientes recursos:
- Original [conjunto de datos de Food101 y sitio web en papel] (https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/).
torchvision.datasets.Food101: la versión de los datos que descargué para este cuaderno.extras/04_custom_data_creation.ipynb: un cuaderno que usé para formatear el conjunto de datos de Food101 para usarlo este cuaderno.data/pizza_steak_sushi.zip: el archivo zip de imágenes de pizza, bistec y sushi de Food101 , creado con el cuaderno vinculado anteriormente.
Escribamos un código para descargar los datos formateados de GitHub.
Nota: El conjunto de datos que vamos a utilizar ha sido formateado previamente para el uso que nos gustaría utilizar. Sin embargo, a menudo tendrás que formatear tus propios conjuntos de datos para cualquier problema en el que estés trabajando. Esta es una práctica habitual en el mundo del aprendizaje automático.
import requests
import zipfile
from pathlib import Path
# Ruta de configuración a la carpeta de datos
data_path = Path("data/")
image_path = data_path / "pizza_steak_sushi"
# Si la carpeta de imágenes no existe, descárgala y prepárala...
if image_path.is_dir():
print(f"{image_path} directory exists.")
else:
print(f"Did not find {image_path} directory, creating one...")
image_path.mkdir(parents=True, exist_ok=True)
# Download pizza, steak, sushi data
with open(data_path / "pizza_steak_sushi.zip", "wb") as f:
request = requests.get("https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip")
print("Downloading pizza, steak, sushi data...")
f.write(request.content)
# Unzip pizza, steak, sushi data
with zipfile.ZipFile(data_path / "pizza_steak_sushi.zip", "r") as zip_ref:
print("Unzipping pizza, steak, sushi data...")
zip_ref.extractall(image_path)
2. Conviértete en uno con los datos (preparación de datos)¶
¡Conjunto de datos descargado!
Es hora de volverse uno con ello.
Este es otro paso importante antes de construir un modelo.
Como dijo Abraham Lossfunction...

La preparación de datos es primordial. Antes de construir un modelo, vuélvete uno con los datos. Pregunte: ¿Qué estoy tratando de hacer aquí? Fuente: @mrdbourke Twitter.
¿Qué es inspeccionar los datos y volverse uno con ellos?
Antes de comenzar un proyecto o construir cualquier tipo de modelo, es importante saber con qué datos estás trabajando.
En nuestro caso, tenemos imágenes de pizza, bistec y sushi en formato de clasificación de imágenes estándar.
El formato de clasificación de imágenes contiene clases separadas de imágenes en directorios separados titulados con un nombre de clase particular.
Por ejemplo, todas las imágenes de pizza están contenidas en el directorio pizza/.
Este formato es popular en muchos puntos de referencia de clasificación de imágenes diferentes, incluido ImageNet (de los conjuntos de datos de puntos de referencia de visión por computadora más populares).
Puede ver un ejemplo del formato de almacenamiento a continuación, los números de las imágenes son arbitrarios.
pizza_steak_sushi/ <- carpeta del conjunto de datos general
tren/ <- imágenes de entrenamiento
pizza/ <- nombre de clase como nombre de carpeta
imagen01.jpeg
imagen02.jpeg
...
bife/
imagen24.jpeg
imagen25.jpeg
...
Sushi/
imagen37.jpeg
...
prueba/ <- imágenes de prueba
pizza/
imagen101.jpeg
imagen102.jpeg
...
bife/
imagen154.jpeg
imagen155.jpeg
...
Sushi/
imagen167.jpeg
...
El objetivo será tomar esta estructura de almacenamiento de datos y convertirla en un conjunto de datos utilizable con PyTorch.
Nota: La estructura de los datos con los que trabaja variará según el problema en el que esté trabajando. Pero la premisa sigue siendo: volverse uno con los datos y luego encontrar la manera de convertirlos en un conjunto de datos compatible con PyTorch.
Podemos inspeccionar lo que hay en nuestro directorio de datos escribiendo una pequeña función auxiliar para recorrer cada uno de los subdirectorios y contar los archivos presentes.
Para hacerlo, usaremos la [os.walk()] incorporada de Python (https://docs.python.org/3/library/os.html#os.walk).
import os
def walk_through_dir(dir_path):
"""
Walks through dir_path returning its contents.
Args:
dir_path (str or pathlib.Path): target directory
Returns:
A print out of:
number of subdiretories in dir_path
number of images (files) in each subdirectory
name of each subdirectory
"""
for dirpath, dirnames, filenames in os.walk(dir_path):
print(f"There are {len(dirnames)} directories and {len(filenames)} images in '{dirpath}'.")
walk_through_dir(image_path)
¡Excelente!
Parece que tenemos alrededor de 75 imágenes por clase de capacitación y 25 imágenes por clase de prueba.
Eso debería ser suficiente para empezar.
Recuerde, estas imágenes son subconjuntos del conjunto de datos original de Food101.
Puede ver cómo se crearon en el [cuaderno de creación de datos] (https://github.com/mrdbourke/pytorch-deep-learning/blob/main/extras/04_custom_data_creation.ipynb).
Mientras estamos en eso, configuremos nuestras rutas de capacitación y prueba.
# Configurar rutas de tren y pruebas.
train_dir = image_path / "train"
test_dir = image_path / "test"
train_dir, test_dir
2.1 Visualizar una imagen¶
Bien, hemos visto cómo se formatea nuestra estructura de directorios.
Ahora, siguiendo el espíritu del explorador de datos, es hora de ¡visualizar, visualizar, visualizar!
Escribamos un código para:
- Obtenga todas las rutas de las imágenes usando
pathlib.Path.glob()para encontrar todas las archivos que terminan en.jpg. - Elija una ruta de imagen aleatoria usando
random.choice()de Python. - Obtenga el nombre de la clase de imagen usando
pathlib.Path.parent.stem. - Y como estamos trabajando con imágenes, abriremos la ruta de la imagen aleatoria usando [
PIL.Image.open()](https://pillow.readthedocs.io/en/stable/reference/Image. html#PIL.Image.open) (PIL significa Biblioteca de imágenes de Python). - Luego mostraremos la imagen e imprimiremos algunos metadatos.
import random
from PIL import Image
# Establecer semilla
random.seed(42) # <- try changing this and see what happens
# 1. Obtenga todas las rutas de las imágenes (* significa "cualquier combinación")
image_path_list = list(image_path.glob("*/*/*.jpg"))
# 2. Obtener ruta de imagen aleatoria
random_image_path = random.choice(image_path_list)
# 3. Obtener la clase de imagen a partir del nombre de la ruta (la clase de imagen es el nombre del directorio donde está almacenada la imagen)
image_class = random_image_path.parent.stem
# 4. Abrir imagen
img = Image.open(random_image_path)
# 5. Imprimir metadatos
print(f"Random image path: {random_image_path}")
print(f"Image class: {image_class}")
print(f"Image height: {img.height}")
print(f"Image width: {img.width}")
img
Podemos hacer lo mismo con matplotlib.pyplot.imshow(), excepto que tenemos que convertir la imagen. a una matriz NumPy primero.
import numpy as np
import matplotlib.pyplot as plt
# Convertir la imagen en una matriz
img_as_array = np.asarray(img)
# Trazar la imagen con matplotlib
plt.figure(figsize=(10, 7))
plt.imshow(img_as_array)
plt.title(f"Image class: {image_class} | Image shape: {img_as_array.shape} -> [height, width, color_channels]")
plt.axis(False);
3. Transformar datos¶
Ahora, ¿qué pasaría si quisiéramos cargar los datos de nuestra imagen en PyTorch?
Antes de que podamos usar nuestros datos de imagen con PyTorch, necesitamos:
- Convertirlo en tensores (representaciones numéricas de nuestras imágenes).
- Conviértalo en
torch.utils.data.Datasety posteriormente entorch.utils.data.DataLoader; los llamaremosDatasetyDataLoaderpara abreviar.
Hay varios tipos diferentes de conjuntos de datos y cargadores de conjuntos de datos prediseñados para PyTorch, según el problema en el que esté trabajando.
| Espacio problemático | Conjuntos de datos y funciones prediseñados |
|---|---|
| Visión | torchvision.datasets |
| Audio | torchaudio.datasets |
| Texto | torchtext.datasets |
| Sistema de recomendación | torchrec.datasets |
Dado que estamos trabajando con un problema de visión, veremos torchvision.datasets para nuestras funciones de carga de datos, así como [torchvision.transforms](https://pytorch.org/vision/stable/transforms .html) para preparar nuestros datos.
Importemos algunas bibliotecas base.
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
3.1 Transformando datos con torchvision.transforms¶
Tenemos carpetas de imágenes, pero antes de poder usarlas con PyTorch, necesitamos convertirlas en tensores.
Una de las formas en que podemos hacer esto es usando el módulo torchvision.transforms.
torchvision.transforms contiene muchos métodos prediseñados para formatear imágenes, convertirlas en tensores e incluso manipularlas para aumento de datos (la práctica de alterar datos para dificultar el aprendizaje de un modelo, veremos esto más adelante) propósitos.
Para adquirir experiencia con torchvision.transforms, escribamos una serie de pasos de transformación que:
- Cambie el tamaño de las imágenes usando
transforms.Resize()(de aproximadamente 512x512 a 64x64 , la misma forma que las imágenes en el [sitio web de CNN Explicador] (https://poloclub.github.io/cnn-explainer/)). - Voltee nuestras imágenes aleatoriamente en horizontal usando
transforms.RandomHorizontalFlip()(esto podría considerarse una forma de aumento de datos porque cambiará artificialmente los datos de nuestra imagen). - Convierta nuestras imágenes de una imagen PIL a un tensor de PyTorch usando [
transforms.ToTensor()](https://pytorch.org/vision/stable/generated/torchvision.transforms.ToTensor.html#torchvision.transforms. A Tensor).
Podemos compilar todos estos pasos usando torchvision.transforms.Compose().
# Escribir transformación para imagen
data_transform = transforms.Compose([
# Resize the images to 64x64
transforms.Resize(size=(64, 64)),
# Flip the images randomly on the horizontal
transforms.RandomHorizontalFlip(p=0.5), # p = probability of flip, 0.5 = 50% chance
# Turn the image into a torch.Tensor
transforms.ToTensor() # this also converts all pixel values from 0 to 255 to be between 0.0 and 1.0
])
Ahora que tenemos una composición de transformaciones, escribamos una función para probarlas en varias imágenes.
def plot_transformed_images(image_paths, transform, n=3, seed=42):
"""Plots a series of random images from image_paths.
Will open n image paths from image_paths, transform them
with transform and plot them side by side.
Args:
image_paths (list): List of target image paths.
transform (PyTorch Transforms): Transforms to apply to images.
n (int, optional): Number of images to plot. Defaults to 3.
seed (int, optional): Random seed for the random generator. Defaults to 42.
"""
random.seed(seed)
random_image_paths = random.sample(image_paths, k=n)
for image_path in random_image_paths:
with Image.open(image_path) as f:
fig, ax = plt.subplots(1, 2)
ax[0].imshow(f)
ax[0].set_title(f"Original \nSize: {f.size}")
ax[0].axis("off")
# Transform and plot image
# Note: permute() will change shape of image to suit matplotlib
# (PyTorch default is [C, H, W] but Matplotlib is [H, W, C])
transformed_image = transform(f).permute(1, 2, 0)
ax[1].imshow(transformed_image)
ax[1].set_title(f"Transformed \nSize: {transformed_image.shape}")
ax[1].axis("off")
fig.suptitle(f"Class: {image_path.parent.stem}", fontsize=16)
plot_transformed_images(image_path_list,
transform=data_transform,
n=3)
¡Lindo!
Ahora tenemos una manera de convertir nuestras imágenes en tensores usando torchvision.transforms.
También manipulamos su tamaño y orientación si es necesario (algunos modelos prefieren imágenes de diferentes tamaños y formas).
Generalmente, cuanto mayor sea la forma de la imagen, más información podrá recuperar un modelo.
Por ejemplo, una imagen de tamaño [256, 256, 3] tendrá 16 veces más píxeles que una imagen de tamaño [64, 64, 3] ((256*256*3)/(64*64* 3)=16).
Sin embargo, la desventaja es que más píxeles requieren más cálculos.
Ejercicio: Intente comentar una de las transformaciones en
data_transformy ejecute la función de trazadoplot_transformed_images()nuevamente, ¿qué sucede?
4. Opción 1: cargar datos de imagen usando ImageFolder¶
Muy bien, es hora de convertir nuestros datos de imagen en un "Conjunto de datos" capaz de usarse con PyTorch.
Dado que nuestros datos están en formato de clasificación de imágenes estándar, podemos usar la clase [torchvision.datasets.ImageFolder](https://pytorch.org/vision/stable/generated/torchvision.datasets.ImageFolder.html#torchvision.datasets .Carpeta de imágenes).
Donde podemos pasarle la ruta del archivo de un directorio de imágenes de destino, así como una serie de transformaciones que nos gustaría realizar en nuestras imágenes.
Probémoslo en nuestras carpetas de datos train_dir y test_dir pasando transform=data_transform para convertir nuestras imágenes en tensores.
# Utilice ImageFolder para crear conjuntos de datos
from torchvision import datasets
train_data = datasets.ImageFolder(root=train_dir, # target folder of images
transform=data_transform, # transforms to perform on data (images)
target_transform=None) # transforms to perform on labels (if necessary)
test_data = datasets.ImageFolder(root=test_dir,
transform=data_transform)
print(f"Train data:\n{train_data}\nTest data:\n{test_data}")
¡Hermoso!
Parece que PyTorch ha registrado nuestro "Conjunto de datos".
Inspeccionémoslos revisando los atributos classes y class_to_idx, así como la duración de nuestros conjuntos de entrenamiento y prueba.
# Obtener nombres de clases como una lista
class_names = train_data.classes
class_names
# También puede obtener nombres de clases como un dictado.
class_dict = train_data.class_to_idx
class_dict
# Comprueba las longitudes
len(train_data), len(test_data)
¡Lindo! Parece que podremos usarlos como referencia para más adelante.
¿Qué tal nuestras imágenes y etiquetas?
¿Como se ven?
Podemos indexar nuestros train_data y test_data Dataset para encontrar muestras y sus etiquetas de destino.
img, label = train_data[0][0], train_data[0][1]
print(f"Image tensor:\n{img}")
print(f"Image shape: {img.shape}")
print(f"Image datatype: {img.dtype}")
print(f"Image label: {label}")
print(f"Label datatype: {type(label)}")
Nuestras imágenes ahora tienen la forma de un tensor (con forma [3, 64, 64]) y las etiquetas tienen la forma de un número entero relacionado con una clase específica (como lo indica el atributo class_to_idx).
¿Qué tal si trazamos un tensor de imagen única usando matplotlib?
Primero tendremos que permutar (reorganizar el orden de sus dimensiones) para que sea compatible.
En este momento, las dimensiones de nuestra imagen están en el formato CHW (canales de color, alto, ancho) pero matplotlib prefiere HWC (alto, ancho, canales de color).
# Reorganizar el orden de las dimensiones.
img_permute = img.permute(1, 2, 0)
# Imprime diferentes formas (antes y después de la permutación)
print(f"Original shape: {img.shape} -> [color_channels, height, width]")
print(f"Image permute shape: {img_permute.shape} -> [height, width, color_channels]")
# Trazar la imagen
plt.figure(figsize=(10, 7))
plt.imshow(img.permute(1, 2, 0))
plt.axis("off")
plt.title(class_names[label], fontsize=14);
Observe que la imagen ahora está más pixelada (menos calidad).
Esto se debe a que se cambió su tamaño de "512x512" a "64x64" píxeles.
La intuición aquí es que si crees que la imagen es más difícil de reconocer lo que está sucediendo, es probable que al modelo también le resulte más difícil entenderlo.
4.1 Convertir imágenes cargadas en DataLoader's¶
Tenemos nuestras imágenes como Dataset de PyTorch, pero ahora convirtámoslas en DataLoader.
Lo haremos usando torch.utils.data.DataLoader.
Convertir nuestro "Conjunto de datos" en "Cargador de datos" los hace iterables para que un modelo pueda aprender las relaciones entre muestras y objetivos (características y etiquetas).
Para simplificar las cosas, usaremos batch_size=1 y num_workers=1.
¿Qué es "num_workers"?
Buena pregunta.
Define cuántos subprocesos se crearán para cargar sus datos.
Piénselo así: cuanto mayor sea el valor establecido en num_workers, más potencia de cálculo utilizará PyTorch para cargar sus datos.
Personalmente, normalmente lo configuro en el número total de CPU en mi máquina a través de os.cpu_count() de Python.
Esto garantiza que el DataLoader reclute tantos núcleos como sea posible para cargar datos.
Nota: Hay más parámetros con los que puede familiarizarse usando
torch.utils.data.DataLoaderen la [documentación de PyTorch](https://pytorch.org/docs/stable/data.html#torch .utils.data.DataLoader).
# Convierta conjuntos de datos de entrenamiento y prueba en cargadores de datos
from torch.utils.data import DataLoader
train_dataloader = DataLoader(dataset=train_data,
batch_size=1, # how many samples per batch?
num_workers=1, # how many subprocesses to use for data loading? (higher = more)
shuffle=True) # shuffle the data?
test_dataloader = DataLoader(dataset=test_data,
batch_size=1,
num_workers=1,
shuffle=False) # don't usually need to shuffle testing data
train_dataloader, test_dataloader
¡Maravilloso!
Ahora nuestros datos son iterables.
Probémoslo y comprobemos las formas.
img, label = next(iter(train_dataloader))
# El tamaño del lote ahora será 1, intente cambiar el parámetro de tamaño de lote anterior y vea qué sucede
print(f"Image shape: {img.shape} -> [batch_size, color_channels, height, width]")
print(f"Label shape: {label.shape}")
Ahora podríamos usar estos DataLoader con un bucle de entrenamiento y prueba para entrenar un modelo.
Pero antes de hacerlo, veamos otra opción para cargar imágenes (o casi cualquier otro tipo de datos).
5. Opción 2: cargar datos de imagen con un conjunto de datos personalizado¶
¿Qué pasaría si no existiera un creador de conjunto de datos prediseñado como torchvision.datasets.ImageFolder()?
¿O no existía uno para su problema específico?
Bueno, podrías construir el tuyo propio.
Pero espera, ¿cuáles son los pros y los contras de crear tu propia forma personalizada de cargar "conjuntos de datos"?
| Ventajas de crear un "conjunto de datos" personalizado | Desventajas de crear un conjunto de datos personalizado |
|---|---|
| Puede crear un "conjunto de datos" a partir de casi cualquier cosa. | Aunque podrías crear un Conjunto de datos a partir de casi cualquier cosa, eso no significa que vaya a funcionar. |
| No se limita a las funciones de "conjunto de datos" prediseñadas de PyTorch. | El uso de un "conjunto de datos" personalizado a menudo resulta en escribir más código, lo que podría ser propenso a errores o problemas de rendimiento. |
Para ver esto en acción, trabajemos para replicar torchvision.datasets.ImageFolder() subclasificando torch.utils.data.Dataset (la clase base para todos los Dataset en PyTorch).
Comenzaremos importando los módulos que necesitamos:
- El
osde Python para tratar con directorios (nuestros datos se almacenan en directorios). pathlibde Python para tratar con rutas de archivos (cada una de nuestras imágenes tiene una ruta de archivo única).antorchapara todo lo relacionado con PyTorch.- Clase
Imagende PIL para cargar imágenes. torch.utils.data.Datasetpara subclasificar y crear nuestro propioDatasetpersonalizado.torchvision.transformspara convertir nuestras imágenes en tensores.- Varios tipos del módulo
typingde Python para agregar sugerencias de tipo a nuestro código.
Nota: Puede personalizar los siguientes pasos para su propio conjunto de datos. La premisa sigue siendo: escriba código para cargar sus datos en el formato que desee.
import os
import pathlib
import torch
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
from typing import Tuple, Dict, List
¿Recuerda cómo nuestras instancias de torchvision.datasets.ImageFolder() nos permitieron usar los atributos classes y class_to_idx?
# Instancia de torchvision.datasets.ImageFolder()
train_data.classes, train_data.class_to_idx
5.1 Creando una función auxiliar para obtener nombres de clases¶
Escribamos una función auxiliar capaz de crear una lista de nombres de clases y un diccionario de nombres de clases y sus índices dada una ruta de directorio.
Para hacerlo, haremos:
- Obtenga los nombres de las clases usando
os.scandir()para recorrer un directorio de destino (idealmente el directorio está en formato de clasificación de imágenes estándar). - Genera un error si no se encuentran los nombres de las clases (si esto sucede, es posible que haya algún problema con la estructura del directorio).
- Convierta los nombres de las clases en un diccionario de etiquetas numéricas, una para cada clase.
Veamos un pequeño ejemplo del paso 1 antes de escribir la función completa.
# Ruta de configuración para el directorio de destino
target_directory = train_dir
print(f"Target directory: {target_directory}")
# Obtenga los nombres de las clases del directorio de destino
class_names_found = sorted([entry.name for entry in list(os.scandir(image_path / "train"))])
print(f"Class names found: {class_names_found}")
¡Excelente!
¿Qué tal si lo convertimos en una función completa?
# Crear función para buscar clases en el directorio de destino
def find_classes(directory: str) -> Tuple[List[str], Dict[str, int]]:
"""Finds the class folder names in a target directory.
Assumes target directory is in standard image classification format.
Args:
directory (str): target directory to load classnames from.
Returns:
Tuple[List[str], Dict[str, int]]: (list_of_class_names, dict(class_name: idx...))
Example:
find_classes("food_images/train")
>>> (["class_1", "class_2"], {"class_1": 0, ...})
"""
# 1. Get the class names by scanning the target directory
classes = sorted(entry.name for entry in os.scandir(directory) if entry.is_dir())
# 2. Raise an error if class names not found
if not classes:
raise FileNotFoundError(f"Couldn't find any classes in {directory}.")
# 3. Create a dictionary of index labels (computers prefer numerical rather than string labels)
class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
return classes, class_to_idx
¡Luciendo bien!
Ahora probemos nuestra función find_classes().
find_classes(train_dir)
¡Guau! ¡Luciendo bien!
5.2 Crear un Conjunto de datos personalizado para replicar ImageFolder¶
Ahora estamos listos para crear nuestro propio "conjunto de datos" personalizado.
Construiremos uno para replicar la funcionalidad de torchvision.datasets.ImageFolder().
Esta será una buena práctica y, además, revelará algunos de los pasos necesarios para crear su propio "conjunto de datos" personalizado.
Será bastante código... ¡pero nada que no podamos manejar!
Vamos a desglosarlo:
- Subclase
torch.utils.data.Dataset. - Inicialice nuestra subclase con un parámetro
targ_dir(el directorio de datos de destino) y un parámetrotransform(para que tengamos la opción de transformar nuestros datos si es necesario). - Cree varios atributos para
paths(las rutas de nuestras imágenes de destino),transform(las transformaciones que nos gustaría usar, esta puede serNinguna),classesyclass_to_idx(de nuestrofind_classes ()función). - Cree una función para cargar imágenes desde un archivo y devolverlas, esto podría ser usando
PILotorchvision.io(para entrada/salida de datos de visión). - Sobrescriba el método
__len__detorch.utils.data.Datasetpara devolver el número de muestras en elDataset. Esto se recomienda pero no es obligatorio. Esto es para que puedas llamar alen (Conjunto de datos). - Sobrescriba el método
__getitem__detorch.utils.data.Datasetpara devolver una única muestra delDataset; esto es obligatorio.
¡Vamos a hacerlo!
# Escriba una clase de conjunto de datos personalizada (hereda de torch.utils.data.Dataset)
from torch.utils.data import Dataset
# 1. Subclase torch.utils.data.Dataset
class ImageFolderCustom(Dataset):
# 2. Initialize with a targ_dir and transform (optional) parameter
def __init__(self, targ_dir: str, transform=None) -> None:
# 3. Create class attributes
# Get all image paths
self.paths = list(pathlib.Path(targ_dir).glob("*/*.jpg")) # note: you'd have to update this if you've got .png's or .jpeg's
# Setup transforms
self.transform = transform
# Create classes and class_to_idx attributes
self.classes, self.class_to_idx = find_classes(targ_dir)
# 4. Make function to load images
def load_image(self, index: int) -> Image.Image:
"Opens an image via a path and returns it."
image_path = self.paths[index]
return Image.open(image_path)
# 5. Overwrite the __len__() method (optional but recommended for subclasses of torch.utils.data.Dataset)
def __len__(self) -> int:
"Returns the total number of samples."
return len(self.paths)
# 6. Overwrite the __getitem__() method (required for subclasses of torch.utils.data.Dataset)
def __getitem__(self, index: int) -> Tuple[torch.Tensor, int]:
"Returns one sample of data, data and label (X, y)."
img = self.load_image(index)
class_name = self.paths[index].parent.name # expects path in data_folder/class_name/image.jpeg
class_idx = self.class_to_idx[class_name]
# Transform if necessary
if self.transform:
return self.transform(img), class_idx # return data, label (X, y)
else:
return img, class_idx # return data, label (X, y)
¡Guau! Un montón de código para cargar en nuestras imágenes.
Esta es una de las desventajas de crear su propio "conjunto de datos" personalizado.
Sin embargo, ahora que lo hemos escrito una vez, podemos moverlo a un archivo .py como data_loader.py junto con algunas otras funciones de datos útiles y reutilizarlo más adelante.
Antes de probar nuestra nueva clase ImageFolderCustom, creemos algunas transformaciones para preparar nuestras imágenes.
# Aumentar los datos del tren
train_transforms = transforms.Compose([
transforms.Resize((64, 64)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor()
])
# No aumente los datos de prueba, solo remodele
test_transforms = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor()
])
¡Ahora llega la hora de la verdad!
Convirtamos nuestras imágenes de entrenamiento (contenidas en train_dir) y nuestras imágenes de prueba (contenidas en test_dir) en Dataset usando nuestra propia clase ImageFolderCustom.
train_data_custom = ImageFolderCustom(targ_dir=train_dir,
transform=train_transforms)
test_data_custom = ImageFolderCustom(targ_dir=test_dir,
transform=test_transforms)
train_data_custom, test_data_custom
Hmm... no hay errores, ¿funcionó?
Intentemos llamar a len() en nuestro nuevo Dataset y busquemos los atributos classes y class_to_idx.
len(train_data_custom), len(test_data_custom)
train_data_custom.classes
train_data_custom.class_to_idx
len(test_data_custom) == len(test_data) y len(test_data_custom) == len(test_data) ¡¡¡Sí!!!
Parece que funcionó.
También podríamos verificar la igualdad con el Dataset creado por la clase torchvision.datasets.ImageFolder().
# Verifique la igualdad entre nuestro conjunto de datos personalizado y el conjunto de datos ImageFolder
print((len(train_data_custom) == len(train_data)) & (len(test_data_custom) == len(test_data)))
print(train_data_custom.classes == train_data.classes)
print(train_data_custom.class_to_idx == train_data.class_to_idx)
¡Ho, ho!
¡Míranos ir!
¡Tres "verdaderos"!
No hay nada mejor que eso.
¿Qué tal si lo llevamos a un nivel superior y trazamos algunas imágenes aleatorias para probar nuestra anulación __getitem__?
5.3 Crear una función para mostrar imágenes aleatorias¶
¡Sabes que hora es!
Es hora de ponernos el sombrero de explorador de datos y ¡visualizar, visualizar, visualizar!
Creemos una función auxiliar llamada display_random_images() que nos ayuda a visualizar imágenes en nuestro `Conjunto de datos'.
Específicamente:
- Tome un
Conjunto de datosy una serie de otros parámetros comoclases(los nombres de nuestras clases de destino), la cantidad de imágenes para mostrar (n) y una semilla aleatoria. - Para evitar que la visualización se salga de control, limitaremos "n" a 10 imágenes.
- Establezca la semilla aleatoria para parcelas reproducibles (si se establece "semilla").
- Obtenga una lista de índices de muestra aleatorios (podemos usar
random.sample()de Python para esto) para trazar. - Configure un gráfico
matplotlib. - Recorra los índices de muestra aleatorios que se encuentran en el paso 4 y grábelos con
matplotlib. - Asegúrese de que las imágenes de muestra tengan la forma "HWC" (alto, ancho, canales de color) para que podamos trazarlas.
# 1. Incorpore un conjunto de datos y una lista de nombres de clases.
def display_random_images(dataset: torch.utils.data.dataset.Dataset,
classes: List[str] = None,
n: int = 10,
display_shape: bool = True,
seed: int = None):
# 2. Adjust display if n too high
if n > 10:
n = 10
display_shape = False
print(f"For display purposes, n shouldn't be larger than 10, setting to 10 and removing shape display.")
# 3. Set random seed
if seed:
random.seed(seed)
# 4. Get random sample indexes
random_samples_idx = random.sample(range(len(dataset)), k=n)
# 5. Setup plot
plt.figure(figsize=(16, 8))
# 6. Loop through samples and display random samples
for i, targ_sample in enumerate(random_samples_idx):
targ_image, targ_label = dataset[targ_sample][0], dataset[targ_sample][1]
# 7. Adjust image tensor shape for plotting: [color_channels, height, width] -> [color_channels, height, width]
targ_image_adjust = targ_image.permute(1, 2, 0)
# Plot adjusted samples
plt.subplot(1, n, i+1)
plt.imshow(targ_image_adjust)
plt.axis("off")
if classes:
title = f"class: {classes[targ_label]}"
if display_shape:
title = title + f"\nshape: {targ_image_adjust.shape}"
plt.title(title)
¡Qué función tan atractiva!
Probémoslo primero con el Dataset que creamos con torchvision.datasets.ImageFolder().
# Mostrar imágenes aleatorias del conjunto de datos creado por ImageFolder
display_random_images(train_data,
n=5,
classes=class_names,
seed=None)
Y ahora con el Dataset que creamos con nuestro propio ImageFolderCustom.
# Mostrar imágenes aleatorias del conjunto de datos ImageFolderCustom
display_random_images(train_data_custom,
n=12,
classes=class_names,
seed=None) # Try setting the seed for reproducible images
¡¡¡Lindo!!!
Parece que nuestro ImageFolderCustom está funcionando tal como nos gustaría.
5.4 Convierta imágenes cargadas personalizadas en DataLoader¶
Tenemos una manera de convertir nuestras imágenes sin procesar en Dataset (características asignadas a etiquetas o X asignadas a y) a través de nuestra clase ImageFolderCustom.
Ahora, ¿cómo podríamos convertir nuestro "Conjunto de datos" personalizado en un "Cargador de datos"?
Si adivinaste usando torch.utils.data.DataLoader(), ¡estarías en lo cierto!
Debido a que la subclase de nuestro Dataset personalizado torch.utils.data.Dataset, podemos usarla directamente con torch.utils.data.DataLoader().
Y podemos hacerlo usando pasos muy similares a los anteriores, excepto que esta vez usaremos nuestro Conjunto de datos personalizado.
# Convierta el tren y pruebe conjuntos de datos personalizados en DataLoader
from torch.utils.data import DataLoader
train_dataloader_custom = DataLoader(dataset=train_data_custom, # use custom created train Dataset
batch_size=1, # how many samples per batch?
num_workers=0, # how many subprocesses to use for data loading? (higher = more)
shuffle=True) # shuffle the data?
test_dataloader_custom = DataLoader(dataset=test_data_custom, # use custom created test Dataset
batch_size=1,
num_workers=0,
shuffle=False) # don't usually need to shuffle testing data
train_dataloader_custom, test_dataloader_custom
¿Las formas de las muestras son iguales?
# Obtener imagen y etiqueta de DataLoader personalizado
img_custom, label_custom = next(iter(train_dataloader_custom))
# El tamaño del lote ahora será 1, intente cambiar el parámetro de tamaño de lote anterior y vea qué sucede
print(f"Image shape: {img_custom.shape} -> [batch_size, color_channels, height, width]")
print(f"Label shape: {label_custom.shape}")
¡Seguro lo hacen!
Ahora analicemos otras formas de transformaciones de datos.
6. Otras formas de transformaciones (aumento de datos)¶
Ya hemos visto un par de transformaciones en nuestros datos, pero hay muchas más.
Puede verlos todos en la [documentación torchvision.transforms] (https://pytorch.org/vision/stable/transforms.html).
El propósito de las transformaciones es alterar sus imágenes de alguna manera.
Eso puede convertir sus imágenes en un tensor (como hemos visto antes).
O recortarlo o borrar aleatoriamente una parte o rotarla aleatoriamente.
Realizar este tipo de transformaciones a menudo se denomina aumento de datos.
Aumento de datos es el proceso de alterar tus datos de tal manera que artificialmente aumentes la diversidad de tu conjunto de entrenamiento.
Se espera que entrenar un modelo con este conjunto de datos artificialmente alterado dé como resultado un modelo que sea capaz de realizar una mejor generalización (los patrones que aprende son más sólidos para futuros ejemplos no vistos).
Puede ver muchos ejemplos diferentes de aumento de datos realizado en imágenes usando torchvision.transforms en el [ejemplo de ilustración de transformaciones] de PyTorch (https://pytorch.org/vision/stable/auto_examples/plot_transforms.html#ilustracion-of-transforms ).
Pero probemos uno nosotros mismos.
El aprendizaje automático consiste en aprovechar el poder de la aleatoriedad y las investigaciones muestran que las transformaciones aleatorias (como transforms.RandAugment() y transforms.TrivialAugmentWide()) generalmente funcionan mejor que las transformaciones seleccionadas cuidadosamente.
La idea detrás de TrivialAugment es... bueno, trivial.
Tiene un conjunto de transformaciones y elige aleatoriamente una cantidad de ellas para realizarlas en una imagen y en una magnitud aleatoria entre un rango determinado (una magnitud más alta significa más intensidad).
El equipo de PyTorch incluso [usó TrivialAugment para entrenar sus últimos modelos de visión de última generación](https://pytorch.org/blog/how-to-train-state-of-the-art-models-using -torchvision-latest-primitives/#break-down-of-key-accuracy-improvements).
![aumento de datos de aumento trivial que se utiliza para la capacitación de vanguardia de PyTorch] (https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/images/04-trivial-augment-being-using-in -PyTorch-resize.png)
TrivialAugment fue uno de los ingredientes utilizados en una reciente actualización de capacitación de última generación para varios modelos de visión de PyTorch.
¿Qué tal si lo probamos en algunas de nuestras propias imágenes?
El parámetro principal al que prestar atención en transforms.TrivialAugmentWide() es num_magnitude_bins=31.
Define qué parte de un rango se seleccionará un valor de intensidad para aplicar una determinada transformación, siendo "0" ningún rango y "31" siendo el rango máximo (la mayor probabilidad de obtener la mayor intensidad).
Podemos incorporar transforms.TrivialAugmentWide() en transforms.Compose().
from torchvision import transforms
train_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.TrivialAugmentWide(num_magnitude_bins=31), # how intense
transforms.ToTensor() # use ToTensor() last to get everything between 0 & 1
])
# No es necesario realizar un aumento en los datos de prueba.
test_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
Nota: Generalmente no se realizan aumentos de datos en el conjunto de prueba. La idea del aumento de datos es aumentar artificialmente la diversidad del conjunto de entrenamiento para predecir mejor en el conjunto de prueba.
Sin embargo, debe asegurarse de que las imágenes de su conjunto de prueba se transformen en tensores. También dimensionamos las imágenes de prueba al mismo tamaño que nuestras imágenes de entrenamiento; sin embargo, se puede realizar inferencia en imágenes de diferentes tamaños si es necesario (aunque esto puede alterar el rendimiento).
Hermoso, ahora tenemos una transformación de entrenamiento (con aumento de datos) y una transformación de prueba (sin aumento de datos).
¡Probemos nuestro aumento de datos!
# Obtener todas las rutas de imágenes
image_path_list = list(image_path.glob("*/*/*.jpg"))
# Trazar imágenes aleatorias
plot_transformed_images(
image_paths=image_path_list,
transform=train_transforms,
n=3,
seed=None
)
Intente ejecutar la celda de arriba varias veces y vea cómo la imagen original cambia a medida que pasa por la transformación.
7. Modelo 0: TinyVGG sin aumento de datos¶
Muy bien, hemos visto cómo convertir nuestros datos de imágenes en carpetas a tensores transformados.
Ahora construyamos un modelo de visión por computadora para ver si podemos clasificar si una imagen es de pizza, bistec o sushi.
Para comenzar, comenzaremos con una transformación simple, solo cambiaremos el tamaño de las imágenes a "(64, 64)" y las convertiremos en tensores.
7.1 Creando transformaciones y cargando datos para el Modelo 0¶
# Crear transformación simple
simple_transform = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor(),
])
Excelente, ahora tenemos una transformación simple:
- Cargue los datos, convirtiendo primero cada una de nuestras carpetas de entrenamiento y prueba en un
Conjunto de datoscontorchvision.datasets.ImageFolder() - Luego, en un
DataLoaderusandotorch.utils.data.DataLoader().- Configuraremos
batch_size=32ynum_workersen tantas CPU como sea posible en nuestra máquina (esto dependerá de qué máquina esté usando).
- Configuraremos
# 1. Cargar y transformar datos
from torchvision import datasets
train_data_simple = datasets.ImageFolder(root=train_dir, transform=simple_transform)
test_data_simple = datasets.ImageFolder(root=test_dir, transform=simple_transform)
# 2. Convierta datos en DataLoaders
import os
from torch.utils.data import DataLoader
# Configurar el tamaño del lote y el número de trabajadores
BATCH_SIZE = 32
NUM_WORKERS = os.cpu_count()
print(f"Creating DataLoader's with batch size {BATCH_SIZE} and {NUM_WORKERS} workers.")
# Crear cargador de datos
train_dataloader_simple = DataLoader(train_data_simple,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS)
test_dataloader_simple = DataLoader(test_data_simple,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS)
train_dataloader_simple, test_dataloader_simple
¡Se ha creado DataLoader!
Construyamos un modelo.
7.2 Crear clase de modelo TinyVGG¶
En [cuaderno 03] (https://www.learnpytorch.io/03_pytorch_computer_vision/#7-model-2-building-a-convolutional-neural-network-cnn), utilizamos el modelo TinyVGG del [sitio web de CNN Explicador] (https://poloclub.github.io/cnn-explainer/).
Recreemos el mismo modelo, excepto que esta vez usaremos imágenes en color en lugar de escala de grises (in_channels=3 en lugar de in_channels=1 para píxeles RGB).
class TinyVGG(nn.Module):
"""
Model architecture copying TinyVGG from:
https://poloclub.github.io/cnn-explainer/
"""
def __init__(self, input_shape: int, hidden_units: int, output_shape: int) -> None:
super().__init__()
self.conv_block_1 = nn.Sequential(
nn.Conv2d(in_channels=input_shape,
out_channels=hidden_units,
kernel_size=3, # how big is the square that's going over the image?
stride=1, # default
padding=1), # options = "valid" (no padding) or "same" (output has same shape as input) or int for specific number
nn.ReLU(),
nn.Conv2d(in_channels=hidden_units,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,
stride=2) # default stride value is same as kernel_size
)
self.conv_block_2 = nn.Sequential(
nn.Conv2d(hidden_units, hidden_units, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(hidden_units, hidden_units, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
# Where did this in_features shape come from?
# It's because each layer of our network compresses and changes the shape of our inputs data.
nn.Linear(in_features=hidden_units*16*16,
out_features=output_shape)
)
def forward(self, x: torch.Tensor):
x = self.conv_block_1(x)
# print(x.shape)
x = self.conv_block_2(x)
# print(x.shape)
x = self.classifier(x)
# print(x.shape)
return x
# return self.classifier(self.conv_block_2(self.conv_block_1(x))) # <- leverage the benefits of operator fusion
torch.manual_seed(42)
model_0 = TinyVGG(input_shape=3, # number of color channels (3 for RGB)
hidden_units=10,
output_shape=len(train_data.classes)).to(device)
model_0
Nota: Una de las formas de acelerar la computación de los modelos de aprendizaje profundo en una GPU es aprovechar la fusión de operadores.
Esto significa que en el método
forward()de nuestro modelo anterior, en lugar de llamar a un bloque de capa y reasignarxcada vez, llamamos a cada bloque en sucesión (consulte la última línea del métodoforward()en el modelo anterior como ejemplo).Esto ahorra el tiempo dedicado a reasignar
x(memoria pesada) y se centra únicamente en calcular enx.Consulte Cómo hacer que el aprendizaje profundo funcione mejor desde los primeros principios de Horace He para conocer más formas de acelerar los modelos de aprendizaje automático.
¡Ese sí que es un modelo bonito!
¿Qué tal si lo probamos con un pase hacia adelante en una sola imagen?
7.3 Pruebe un pase hacia adelante en una sola imagen (para probar el modelo)¶
Una buena forma de probar un modelo es hacer un pase directo a un solo dato.
También es una forma práctica de probar las formas de entrada y salida de nuestras diferentes capas.
Para hacer un pase hacia adelante en una sola imagen, hagamos lo siguiente:
- Obtenga un lote de imágenes y etiquetas del
DataLoader. - Obtenga una sola imagen del lote y "descomprima()" la imagen para que tenga un tamaño de lote de "1" (para que su forma se ajuste al modelo).
- Realice una inferencia en una sola imagen (asegurándose de enviar la imagen al "dispositivo" de destino).
- Imprima lo que está sucediendo y convierta los logits de salida sin procesar del modelo en probabilidades de predicción con
torch.softmax()(ya que estamos trabajando con datos de múltiples clases) y convierta las probabilidades de predicción en etiquetas de predicción contorch.argmax( ).
# 1. Obtenga un lote de imágenes y etiquetas del DataLoader
img_batch, label_batch = next(iter(train_dataloader_simple))
# 2. Obtenga una sola imagen del lote y descomprima la imagen para que su forma se ajuste al modelo.
img_single, label_single = img_batch[0].unsqueeze(dim=0), label_batch[0]
print(f"Single image shape: {img_single.shape}\n")
# 3. Realice un pase hacia adelante en una sola imagen.
model_0.eval()
with torch.inference_mode():
pred = model_0(img_single.to(device))
# 4. Imprima lo que está sucediendo y convierta los logits del modelo -> problemas pred -> etiqueta pred
print(f"Output logits:\n{pred}\n")
print(f"Output prediction probabilities:\n{torch.softmax(pred, dim=1)}\n")
print(f"Output prediction label:\n{torch.argmax(torch.softmax(pred, dim=1), dim=1)}\n")
print(f"Actual label:\n{label_single}")
Maravilloso, parece que nuestro modelo está generando lo que esperábamos.
Puede ejecutar la celda de arriba varias veces y cada vez se predecirá una imagen diferente.
Y probablemente notará que las predicciones a menudo son erróneas.
Esto es de esperarse porque el modelo aún no ha sido entrenado y esencialmente se trata de adivinar usando pesos aleatorios.
7.4 Utilice torchinfo para tener una idea de las formas que atraviesan nuestro modelo.¶
Imprimir nuestro modelo con print(model) nos da una idea de lo que está pasando con nuestro modelo.
Y podemos imprimir las formas de nuestros datos a través del método forward().
Sin embargo, una forma útil de obtener información de nuestro modelo es usar torchinfo.
torchinfo viene con un método summary() que toma un modelo de PyTorch así como un input_shape y devuelve lo que sucede cuando un tensor se mueve a través de su modelo.
Nota: Si estás utilizando Google Colab, necesitarás instalar
torchinfo.
# Instale torchinfo si no está disponible, impórtelo si lo está
try:
import torchinfo
except:
!pip install torchinfo
import torchinfo
from torchinfo import summary
summary(model_0, input_size=[1, 3, 64, 64]) # do a test pass through of an example input size
¡Lindo!
La salida de torchinfo.summary() nos brinda una gran cantidad de información sobre nuestro modelo.
Como "parámetros totales", el número total de parámetros en nuestro modelo, el "tamaño total estimado (MB)", que es el tamaño de nuestro modelo.
También puede ver el cambio en las formas de entrada y salida a medida que los datos de un determinado input_size se mueven a través de nuestro modelo.
En este momento, nuestros números de parámetros y el tamaño total del modelo son bajos.
Esto porque estamos comenzando con un modelo pequeño.
Y si necesitamos aumentar su tamaño más adelante, podemos hacerlo.
7.5 Crear funciones de tren y bucle de prueba¶
Tenemos datos y tenemos un modelo.
Ahora creemos algunas funciones de bucle de prueba y entrenamiento para entrenar nuestro modelo con los datos de entrenamiento y evaluar nuestro modelo con los datos de prueba.
Y para asegurarnos de que podamos volver a utilizar estos bucles de entrenamiento y prueba, los pondremos en funcionamiento.
En concreto vamos a realizar tres funciones:
train_step(): toma un modelo, unDataLoader, una función de pérdida y un optimizador y entrena el modelo en elDataLoader.test_step(): toma un modelo, unDataLoadery una función de pérdida y evalúa el modelo en elDataLoader.train(): realiza 1. y 2. juntos durante un número determinado de épocas y devuelve un diccionario de resultados.
Nota: También cubrimos los pasos de un bucle de optimización de PyTorch en cuaderno 01. como la [Canción de bucle de optimización de PyTorch no oficial] (https://youtu.be/Nutpusq_AFw) y hemos creado funciones similares en el [cuaderno 03] (https://www.learnpytorch.io/03_pytorch_computer_vision/#62-functionizing- bucles de entrenamiento y prueba).
Comencemos construyendo train_step().
Debido a que estamos tratando con lotes en el DataLoader, acumularemos los valores de precisión y pérdida del modelo durante el entrenamiento (sumándolos para cada lote) y luego los ajustaremos al final antes de devolverlos.
def train_step(model: torch.nn.Module,
dataloader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
optimizer: torch.optim.Optimizer):
# Put model in train mode
model.train()
# Setup train loss and train accuracy values
train_loss, train_acc = 0, 0
# Loop through data loader data batches
for batch, (X, y) in enumerate(dataloader):
# Send data to target device
X, y = X.to(device), y.to(device)
# 1. Forward pass
y_pred = model(X)
# 2. Calculate and accumulate loss
loss = loss_fn(y_pred, y)
train_loss += loss.item()
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Optimizer step
optimizer.step()
# Calculate and accumulate accuracy metric across all batches
y_pred_class = torch.argmax(torch.softmax(y_pred, dim=1), dim=1)
train_acc += (y_pred_class == y).sum().item()/len(y_pred)
# Adjust metrics to get average loss and accuracy per batch
train_loss = train_loss / len(dataloader)
train_acc = train_acc / len(dataloader)
return train_loss, train_acc
¡Guau! Función train_step() realizada.
Ahora hagamos lo mismo con la función test_step().
La principal diferencia aquí será que test_step() no aceptará un optimizador y, por lo tanto, no realizará un descenso de gradiente.
Pero como haremos inferencias, nos aseguraremos de activar el administrador de contexto torch.inference_mode() para hacer predicciones.
def test_step(model: torch.nn.Module,
dataloader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module):
# Put model in eval mode
model.eval()
# Setup test loss and test accuracy values
test_loss, test_acc = 0, 0
# Turn on inference context manager
with torch.inference_mode():
# Loop through DataLoader batches
for batch, (X, y) in enumerate(dataloader):
# Send data to target device
X, y = X.to(device), y.to(device)
# 1. Forward pass
test_pred_logits = model(X)
# 2. Calculate and accumulate loss
loss = loss_fn(test_pred_logits, y)
test_loss += loss.item()
# Calculate and accumulate accuracy
test_pred_labels = test_pred_logits.argmax(dim=1)
test_acc += ((test_pred_labels == y).sum().item()/len(test_pred_labels))
# Adjust metrics to get average loss and accuracy per batch
test_loss = test_loss / len(dataloader)
test_acc = test_acc / len(dataloader)
return test_loss, test_acc
¡Excelente!
7.6 Creando una función train() para combinar train_step() y test_step()¶
Ahora necesitamos una manera de juntar nuestras funciones train_step() y test_step().
Para hacerlo, los empaquetaremos en una función train().
Esta función entrenará el modelo y lo evaluará.
Específicamente:
- Tome un modelo, un
DataLoaderpara conjuntos de entrenamiento y prueba, un optimizador, una función de pérdida y cuántas épocas realizar cada paso de entrenamiento y prueba. - Cree un diccionario de resultados vacío para los valores
train_loss,train_acc,test_lossytest_acc(podemos llenarlo a medida que avanza el entrenamiento). - Recorra las funciones de los pasos de prueba y entrenamiento durante varias épocas.
- Imprime lo que sucede al final de cada época.
- Actualice el diccionario de resultados vacío con las métricas actualizadas en cada época.
- Devuelva el relleno
Para realizar un seguimiento de la cantidad de épocas por las que hemos pasado, importemos tqdm desde tqdm.auto (tqdm es uno de los más populares Las bibliotecas de barra de progreso para Python y tqdm.auto deciden automáticamente qué tipo de barra de progreso es mejor para su entorno informático, por ejemplo, Jupyter Notebook frente a script de Python).
from tqdm.auto import tqdm
# 1. Considere varios parámetros necesarios para los pasos de capacitación y prueba.
def train(model: torch.nn.Module,
train_dataloader: torch.utils.data.DataLoader,
test_dataloader: torch.utils.data.DataLoader,
optimizer: torch.optim.Optimizer,
loss_fn: torch.nn.Module = nn.CrossEntropyLoss(),
epochs: int = 5):
# 2. Create empty results dictionary
results = {"train_loss": [],
"train_acc": [],
"test_loss": [],
"test_acc": []
}
# 3. Loop through training and testing steps for a number of epochs
for epoch in tqdm(range(epochs)):
train_loss, train_acc = train_step(model=model,
dataloader=train_dataloader,
loss_fn=loss_fn,
optimizer=optimizer)
test_loss, test_acc = test_step(model=model,
dataloader=test_dataloader,
loss_fn=loss_fn)
# 4. Print out what's happening
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.4f} | "
f"train_acc: {train_acc:.4f} | "
f"test_loss: {test_loss:.4f} | "
f"test_acc: {test_acc:.4f}"
)
# 5. Update results dictionary
results["train_loss"].append(train_loss)
results["train_acc"].append(train_acc)
results["test_loss"].append(test_loss)
results["test_acc"].append(test_acc)
# 6. Return the filled results at the end of the epochs
return results
7.7 Entrenar y evaluar el modelo 0¶
Muy bien, muy bien, tenemos todos los ingredientes que necesitamos para entrenar y evaluar nuestro modelo.
¡Es hora de juntar nuestro modelo TinyVGG, las funciones DataLoader y train() para ver si podemos construir un modelo capaz de discernir entre pizza, bistec y sushi!
Recreemos model_0 (no es necesario, pero lo haremos para completarlo) y luego llamemos a nuestra función train() pasando los parámetros necesarios.
Para que nuestros experimentos sean rápidos, entrenaremos nuestro modelo durante 5 épocas (aunque puedes aumentar esto si lo deseas).
En cuanto a un optimizador y una función de pérdida, usaremos torch.nn.CrossEntropyLoss() (ya que estamos trabajando con datos de clasificación de clases múltiples) y torch.optim.Adam( ) con una tasa de aprendizaje de 1e-3 respectivamente.
Para ver cuánto tardan las cosas, importaremos el método timeit.default_timer() de Python para calcular el tiempo de entrenamiento. .
# Establecer semillas aleatorias
torch.manual_seed(42)
torch.cuda.manual_seed(42)
# Establecer número de épocas
NUM_EPOCHS = 5
# Recrea una instancia de TinyVGG
model_0 = TinyVGG(input_shape=3, # number of color channels (3 for RGB)
hidden_units=10,
output_shape=len(train_data.classes)).to(device)
# Función de pérdida de configuración y optimizador.
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model_0.parameters(), lr=0.001)
# iniciar el cronómetro
from timeit import default_timer as timer
start_time = timer()
# Modelo de tren_0
model_0_results = train(model=model_0,
train_dataloader=train_dataloader_simple,
test_dataloader=test_dataloader_simple,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=NUM_EPOCHS)
# Finalice el cronómetro e imprima cuánto tiempo tardó
end_time = timer()
print(f"Total training time: {end_time-start_time:.3f} seconds")
Mmm...
Parece que nuestro modelo funcionó bastante mal.
Pero por ahora está bien, seguiremos perseverando.
¿Cuáles son algunas formas en las que podrías mejorarlo?
Nota: Consulte la sección [Mejorar un modelo (desde la perspectiva del modelo) en el cuaderno 02](https://www.learnpytorch.io/02_pytorch_classification/#5-improving-a-model-from -a-model-perspective) para obtener ideas sobre cómo mejorar nuestro modelo TinyVGG.
7.8 Trazar las curvas de pérdidas del Modelo 0¶
Según las impresiones de nuestro entrenamiento model_0, no parecía que le fuera muy bien.
Pero podemos evaluarlo mejor trazando las curvas de pérdida del modelo.
Las curvas de pérdida muestran los resultados del modelo a lo largo del tiempo.
Y son una excelente manera de ver cómo se desempeña su modelo en diferentes conjuntos de datos (por ejemplo, entrenamiento y prueba).
Creemos una función para trazar los valores en nuestro diccionario model_0_results.
# Verifique las claves model_0_results
model_0_results.keys()
Necesitaremos extraer cada una de estas claves y convertirlas en una trama.
def plot_loss_curves(results: Dict[str, List[float]]):
"""Plots training curves of a results dictionary.
Args:
results (dict): dictionary containing list of values, e.g.
{"train_loss": [...],
"train_acc": [...],
"test_loss": [...],
"test_acc": [...]}
"""
# Get the loss values of the results dictionary (training and test)
loss = results['train_loss']
test_loss = results['test_loss']
# Get the accuracy values of the results dictionary (training and test)
accuracy = results['train_acc']
test_accuracy = results['test_acc']
# Figure out how many epochs there were
epochs = range(len(results['train_loss']))
# Setup a plot
plt.figure(figsize=(15, 7))
# Plot loss
plt.subplot(1, 2, 1)
plt.plot(epochs, loss, label='train_loss')
plt.plot(epochs, test_loss, label='test_loss')
plt.title('Loss')
plt.xlabel('Epochs')
plt.legend()
# Plot accuracy
plt.subplot(1, 2, 2)
plt.plot(epochs, accuracy, label='train_accuracy')
plt.plot(epochs, test_accuracy, label='test_accuracy')
plt.title('Accuracy')
plt.xlabel('Epochs')
plt.legend();
Bien, probemos nuestra función plot_loss_curves().
plot_loss_curves(model_0_results)
Vaya.
Parece que las cosas están por todos lados...
Pero lo sabíamos porque los resultados impresos de nuestro modelo durante el entrenamiento no eran muy prometedores.
Podría intentar entrenar el modelo durante más tiempo y ver qué sucede cuando traza una curva de pérdidas en un horizonte temporal más largo.
8. ¿Cómo debería ser una curva de pérdidas ideal?¶
Observar las curvas de pérdida de prueba y entrenamiento es una excelente manera de ver si su modelo está sobreajustado.
Un modelo de sobreajuste es aquel que funciona mejor (a menudo por un margen considerable) en el conjunto de entrenamiento que en el conjunto de validación/prueba.
Si su pérdida de entrenamiento es mucho menor que su pérdida de prueba, su modelo está sobreajustado.
Es decir, se aprenden demasiado bien los patrones en el entrenamiento y esos patrones no se generalizan a los datos de prueba.
El otro lado es cuando tu pérdida de entrenamiento y pruebas no es tan baja como te gustaría, esto se considera insuficiencia.
La posición ideal para una curva de pérdida de entrenamiento y prueba es que se alineen estrechamente entre sí.
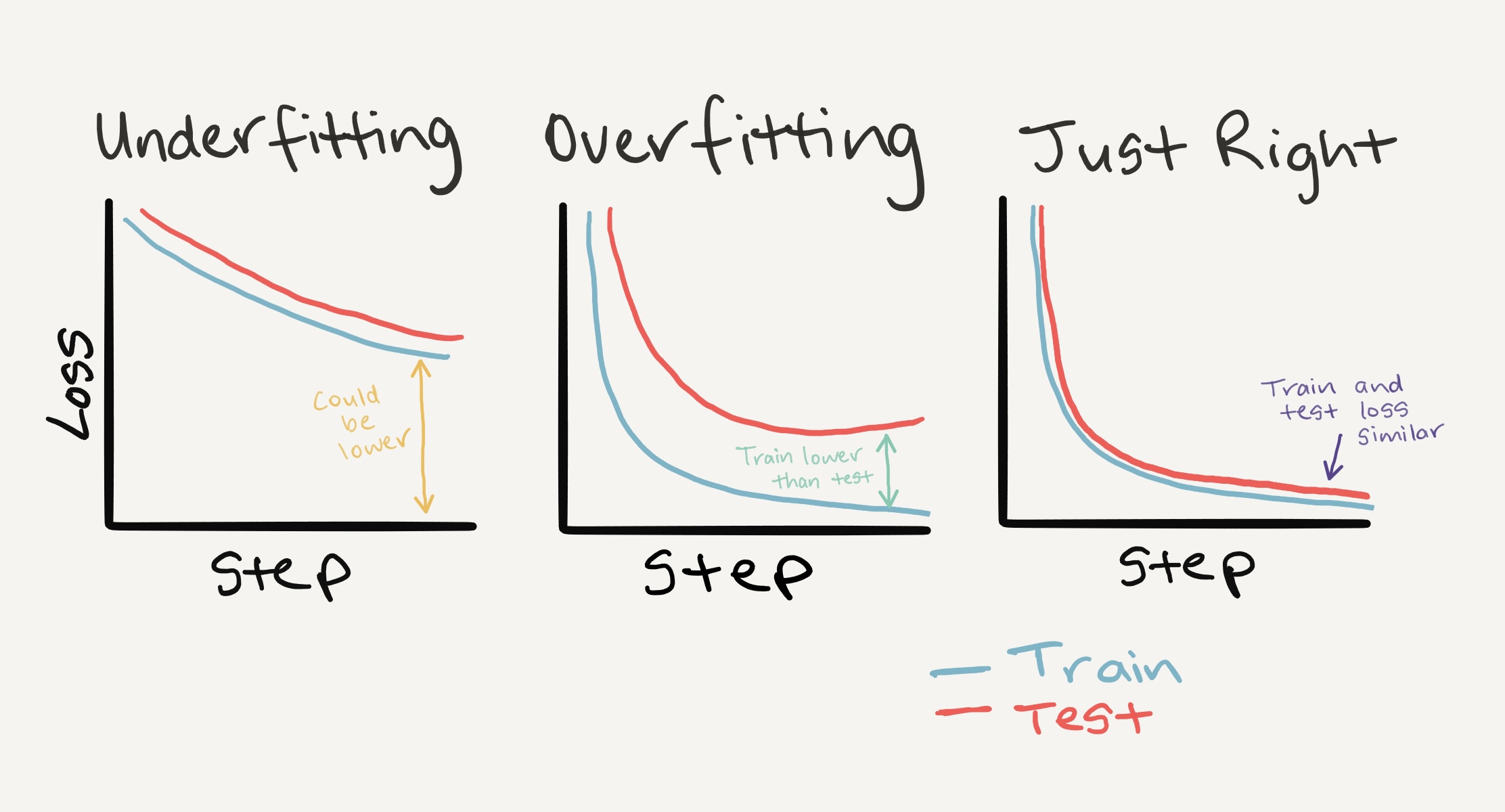
Izquierda: si tus curvas de pérdida de entrenamiento y pruebas no son tan bajas como te gustaría, esto se considera insuficiencia. *Medio: Cuando su pérdida de prueba/validación es mayor que su pérdida de entrenamiento, esto se considera sobreajuste. Derecha: El escenario ideal es cuando las curvas de pérdida de entrenamiento y prueba se alinean con el tiempo. Esto significa que su modelo se está generalizando bien. Hay más combinaciones y diferentes cosas que las curvas de pérdida pueden hacer; para obtener más información sobre esto, consulte la [guía de interpretación de curvas de pérdida] de Google (https://developers.google.com/machine-learning/testing-debugging/metrics/interpretic).*
8.1 Cómo lidiar con el sobreajuste¶
Dado que el principal problema con el sobreajuste es que su modelo se ajusta demasiado bien a los datos de entrenamiento, querrá utilizar técnicas para "controlarlo".
Una técnica común para prevenir el sobreajuste se conoce como regularización.
Me gusta pensar en esto como "hacer que nuestros modelos sean más regulares", es decir, capaces de ajustar más tipos de datos.
Analicemos algunos métodos para evitar el sobreajuste.
| Método para evitar el sobreajuste | ¿Qué es? |
|---|---|
| Obtener más datos | Tener más datos le da al modelo más oportunidades de aprender patrones, patrones que pueden ser más generalizables a nuevos ejemplos. |
| Simplifica tu modelo | Si el modelo actual ya está sobreajustando los datos de entrenamiento, puede ser un modelo demasiado complicado. Esto significa que está aprendiendo demasiado bien los patrones de los datos y no puede generalizar bien a datos invisibles. Una forma de simplificar un modelo es reducir la cantidad de capas que utiliza o reducir la cantidad de unidades ocultas en cada capa. |
| Usar aumento de datos | Aumento de datos manipula los datos de entrenamiento de una manera que al modelo le resulta más difícil aprender, ya que agrega artificialmente más variedad. a los datos. Si un modelo es capaz de aprender patrones en datos aumentados, es posible que pueda generalizar mejor a datos invisibles. |
| Usar aprendizaje por transferencia | Transferir aprendizaje implica aprovechar los patrones (también llamados pesos previamente entrenados) que un modelo ha aprendido a usar como base para su propia tarea. En nuestro caso, podríamos usar un modelo de visión por computadora previamente entrenado en una gran variedad de imágenes y luego modificarlo ligeramente para que esté más especializado en imágenes de alimentos. |
| Usar capas de abandono | Las capas de abandono eliminan aleatoriamente las conexiones entre capas ocultas en las redes neuronales, lo que simplifica efectivamente un modelo pero también mejora las conexiones restantes. Consulte torch.nn.Dropout() para obtener más información. |
| Usar disminución de la tasa de aprendizaje | La idea aquí es disminuir lentamente la tasa de aprendizaje a medida que se entrena un modelo. Esto es similar a alcanzar una moneda en el respaldo de un sofá. Cuanto más te acercas, más pequeños son tus pasos. Lo mismo ocurre con la tasa de aprendizaje: cuanto más te acerques a convergencia, más pequeñas querrás que sean tus actualizaciones de peso. . |
| Utilice la parada anticipada | Detención temprana detiene el entrenamiento del modelo antes de que comience a sobreajustarse. Por ejemplo, digamos que la pérdida del modelo ha dejado de disminuir durante las últimas 10 épocas (este número es arbitrario), es posible que desee detener el entrenamiento del modelo aquí e ir con los pesos del modelo que tuvieron la pérdida más baja (10 épocas anteriores). |
Existen más métodos para abordar el sobreajuste, pero estos son algunos de los principales.
A medida que comience a construir modelos cada vez más profundos, descubrirá que debido a que los aprendizajes profundos son tan buenos para aprender patrones en los datos, lidiar con el sobreajuste es uno de los principales problemas del aprendizaje profundo.
8.2 Cómo lidiar con el desajuste¶
Cuando un modelo es underfitting, se considera que tiene un poder predictivo deficiente en los conjuntos de entrenamiento y prueba.
En esencia, un modelo insuficiente no logrará reducir los valores de pérdida al nivel deseado.
En este momento, al observar nuestras curvas de pérdida actuales, consideré que nuestro modelo "TinyVGG", "model_0", no se ajustaba a los datos.
La idea principal detrás de lidiar con el desajuste es aumentar el poder predictivo de su modelo.
Hay varias formas de hacer esto.
| Método para evitar el desajuste | ¿Qué es? |
|---|---|
| Agregue más capas/unidades a su modelo | Si su modelo no se ajusta lo suficiente, es posible que no tenga la capacidad suficiente para aprender los patrones/pesos/representaciones requeridos de los datos para que sean predictivos. Una forma de agregar más poder predictivo a su modelo es aumentar la cantidad de capas/unidades ocultas dentro de esas capas. |
| Ajustar la tasa de aprendizaje | Quizás la tasa de aprendizaje de su modelo sea demasiado alta para empezar. Y está tratando de actualizar demasiado sus pesos en cada época, y a su vez no aprende nada. En este caso, puede reducir la tasa de aprendizaje y ver qué sucede. |
| Usar aprendizaje por transferencia | El aprendizaje por transferencia es capaz de prevenir el sobreajuste y el desajuste. Implica utilizar los patrones de un modelo que ya funcionaba y ajustarlos a su propio problema. |
| Entrena por más tiempo | A veces, un modelo simplemente necesita más tiempo para aprender las representaciones de datos. Si descubre que en sus experimentos más pequeños su modelo no está aprendiendo nada, tal vez dejarlo entrenar durante más épocas pueda dar como resultado un mejor rendimiento. |
| Utilice menos regularización | Quizás su modelo no se ajuste lo suficiente porque está tratando de evitar un ajuste excesivo. Reprimir las técnicas de regularización puede ayudar a que su modelo se ajuste mejor a los datos. |
8.3 El equilibrio entre sobreajuste y desajuste¶
Ninguno de los métodos discutidos anteriormente son soluciones mágicas, es decir, no siempre funcionan.
Y prevenir el sobreajuste y el desajuste es posiblemente el área más activa de la investigación sobre el aprendizaje automático.
Dado que todo el mundo quiere que sus modelos se ajusten mejor (menos subajuste), pero no tan bien, no generalizan bien ni funcionan en el mundo real (menos sobreajuste).
Existe una delgada línea entre el sobreajuste y el desajuste.
Porque demasiado de cada uno puede causar el otro.
El aprendizaje por transferencia es quizás una de las técnicas más poderosas cuando se trata de lidiar con el sobreajuste y el desajuste de sus propios problemas.
En lugar de elaborar manualmente diferentes técnicas de sobreajuste y desajuste, el aprendizaje por transferencia le permite tomar un modelo que ya funciona en un espacio problemático similar al suyo (por ejemplo, uno de paperswithcode.com/sota o Modelos de Hugging Face) y aplíquelo a su propio conjunto de datos.
Veremos el poder del aprendizaje por transferencia en un cuaderno posterior.
9. Modelo 1: TinyVGG con aumento de datos¶
¡Es hora de probar otro modelo!
Esta vez, carguemos los datos y usemos aumento de datos para ver si mejora nuestros resultados de alguna manera.
Primero, componeremos una transformación de entrenamiento para incluir transforms.TrivialAugmentWide(), además de cambiar el tamaño y convertir nuestras imágenes en tensores.
Haremos lo mismo para una transformación de prueba excepto sin el aumento de datos.
9.1 Crear transformación con aumento de datos¶
# Crea transformación de entrenamiento con TrivialAugment
train_transform_trivial_augment = transforms.Compose([
transforms.Resize((64, 64)),
transforms.TrivialAugmentWide(num_magnitude_bins=31),
transforms.ToTensor()
])
# Crear transformación de prueba (sin aumento de datos)
test_transform = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor()
])
¡Maravilloso!
Ahora convirtamos nuestras imágenes en Dataset usando torchvision.datasets.ImageFolder() y luego en DataLoader con torch.utils.data.DataLoader().
9.2 Crear y probar Dataset y DataLoader¶
Nos aseguraremos de que el Dataset del tren use train_transform_trivial_augment y el Dataset de prueba use test_transform.
# Convierta carpetas de imágenes en conjuntos de datos
train_data_augmented = datasets.ImageFolder(train_dir, transform=train_transform_trivial_augment)
test_data_simple = datasets.ImageFolder(test_dir, transform=test_transform)
train_data_augmented, test_data_simple
Y crearemos DataLoader con batch_size=32 y con num_workers configurados según el número de CPU disponibles en nuestra máquina (podemos obtener esto usando os.cpu_count() de Python).
# Convierta conjuntos de datos en DataLoader
import os
BATCH_SIZE = 32
NUM_WORKERS = os.cpu_count()
torch.manual_seed(42)
train_dataloader_augmented = DataLoader(train_data_augmented,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS)
test_dataloader_simple = DataLoader(test_data_simple,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS)
train_dataloader_augmented, test_dataloader
9.3 Construir y entrenar el Modelo 1¶
¡Datos cargados!
Ahora, para construir nuestro próximo modelo, model_1, podemos reutilizar nuestra clase TinyVGG de antes.
Nos aseguraremos de enviarlo al dispositivo de destino.
# Cree model_1 y envíelo al dispositivo de destino
torch.manual_seed(42)
model_1 = TinyVGG(
input_shape=3,
hidden_units=10,
output_shape=len(train_data_augmented.classes)).to(device)
model_1
¡Modelo listo!
¡Es hora de entrenar!
Como ya tenemos funciones para el bucle de entrenamiento (train_step()) y el bucle de prueba (test_step()) y una función para juntarlos en train(), reutilicémoslas.
Usaremos la misma configuración que model_0 con solo variar el parámetro train_dataloader:
- Entrena durante 5 épocas.
- Utilice
train_dataloader=train_dataloader_augmentedcomo datos de entrenamiento entrain(). - Utilice
torch.nn.CrossEntropyLoss()como función de pérdida (ya que estamos trabajando con clasificación de clases múltiples). - Utilice
torch.optim.Adam()conlr=0.001como tasa de aprendizaje como optimizador.
# Establecer semillas aleatorias
torch.manual_seed(42)
torch.cuda.manual_seed(42)
# Establecer número de épocas
NUM_EPOCHS = 5
# Función de pérdida de configuración y optimizador.
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model_1.parameters(), lr=0.001)
# iniciar el cronómetro
from timeit import default_timer as timer
start_time = timer()
# Modelo de tren_1
model_1_results = train(model=model_1,
train_dataloader=train_dataloader_augmented,
test_dataloader=test_dataloader_simple,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=NUM_EPOCHS)
# Finalice el cronómetro e imprima cuánto tiempo tardó
end_time = timer()
print(f"Total training time: {end_time-start_time:.3f} seconds")
Mmm...
No parece que nuestro modelo haya vuelto a funcionar muy bien.
Veamos sus curvas de pérdidas.
9.4 Trazar las curvas de pérdidas del Modelo 1¶
Como tenemos los resultados de model_1 guardados en un diccionario de resultados, model_1_results, podemos trazarlos usando plot_loss_curves().
plot_loss_curves(model_1_results)
Guau...
Estos tampoco tienen muy buena pinta...
¿Nuestro modelo está insuficiente o sobreajustado?
¿O ambos?
Idealmente nos gustaría que tuviera mayor precisión y menor pérdida, ¿verdad?
¿Cuáles son algunos métodos que podría intentar utilizar para lograrlos?
10. Comparar los resultados del modelo¶
Aunque nuestros modelos funcionan bastante mal, aún podemos escribir código para compararlos.
Primero convirtamos los resultados de nuestro modelo en pandas DataFrames.
import pandas as pd
model_0_df = pd.DataFrame(model_0_results)
model_1_df = pd.DataFrame(model_1_results)
model_0_df
Y ahora podemos escribir un código de trazado usando matplotlib para visualizar los resultados de model_0 y model_1 juntos.
# Configurar una trama
plt.figure(figsize=(15, 10))
# Obtener número de épocas
epochs = range(len(model_0_df))
# Trama de pérdida del tren
plt.subplot(2, 2, 1)
plt.plot(epochs, model_0_df["train_loss"], label="Model 0")
plt.plot(epochs, model_1_df["train_loss"], label="Model 1")
plt.title("Train Loss")
plt.xlabel("Epochs")
plt.legend()
# Pérdida de prueba de trama
plt.subplot(2, 2, 2)
plt.plot(epochs, model_0_df["test_loss"], label="Model 0")
plt.plot(epochs, model_1_df["test_loss"], label="Model 1")
plt.title("Test Loss")
plt.xlabel("Epochs")
plt.legend()
# Trazar la precisión del tren
plt.subplot(2, 2, 3)
plt.plot(epochs, model_0_df["train_acc"], label="Model 0")
plt.plot(epochs, model_1_df["train_acc"], label="Model 1")
plt.title("Train Accuracy")
plt.xlabel("Epochs")
plt.legend()
# Precisión de la prueba de trazado
plt.subplot(2, 2, 4)
plt.plot(epochs, model_0_df["test_acc"], label="Model 0")
plt.plot(epochs, model_1_df["test_acc"], label="Model 1")
plt.title("Test Accuracy")
plt.xlabel("Epochs")
plt.legend();
Parece que nuestros modelos tuvieron un desempeño igualmente pobre y fueron algo esporádicos (las métricas suben y bajan bruscamente).
Si construyeras "model_2", ¿qué harías diferente para intentar mejorar el rendimiento?
11. Haz una predicción sobre una imagen personalizada.¶
Si ha entrenado un modelo en un determinado conjunto de datos, es probable que desee hacer una predicción con sus propios datos personalizados.
En nuestro caso, dado que hemos entrenado un modelo con imágenes de pizza, bistec y sushi, ¿cómo podríamos usar nuestro modelo para hacer una predicción sobre una de nuestras propias imágenes?
Para hacerlo, podemos cargar una imagen y luego preprocesarla de una manera que coincida con el tipo de datos con los que se entrenó nuestro modelo.
En otras palabras, tendremos que convertir nuestra propia imagen personalizada en un tensor y asegurarnos de que esté en el tipo de datos correcto antes de pasarla a nuestro modelo.
Comencemos descargando una imagen personalizada.
Dado que nuestro modelo predice si una imagen contiene pizza, bistec o sushi, descarguemos una foto de [mi papá dando el visto bueno a una pizza grande de Learn PyTorch for Deep Learning GitHub](https://github.com/mrdbourke/ pytorch-deep-learning/blob/main/images/04-pizza-dad.jpeg).
Descargamos la imagen usando el módulo solicitudes de Python.
Nota: Si estás usando Google Colab, también puedes cargar una imagen a la sesión actual yendo al menú del lado izquierdo -> Archivos -> Cargar en el almacenamiento de la sesión. Sin embargo, tenga cuidado, esta imagen se eliminará cuando finalice su sesión de Google Colab.
# Descargar imagen personalizada
import requests
# Configurar ruta de imagen personalizada
custom_image_path = data_path / "04-pizza-dad.jpeg"
# Descarga la imagen si aún no existe
if not custom_image_path.is_file():
with open(custom_image_path, "wb") as f:
# When downloading from GitHub, need to use the "raw" file link
request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/images/04-pizza-dad.jpeg")
print(f"Downloading {custom_image_path}...")
f.write(request.content)
else:
print(f"{custom_image_path} already exists, skipping download.")
11.1 Cargando una imagen personalizada con PyTorch¶
¡Excelente!
Parece que tenemos una imagen personalizada descargada y lista para usar en data/04-pizza-dad.jpeg.
Es hora de cargarlo.
torchvision de PyTorch tiene varios métodos de entrada y salida ("IO" o "io" para abreviar) para leer y escribir imágenes y videos en [torchvision.io](https://pytorch.org/vision/stable/io .html).
Como queremos cargar una imagen, usaremos [torchvision.io.read_image()](https://pytorch.org/vision/stable/generated/torchvision.io.read_image.html#torchvision.io .read_image).
Este método leerá una imagen JPEG o PNG y la convertirá en un torch.Tensor tridimensional RGB o en escala de grises con valores del tipo de datos uint8 en el rango [0, 255].
Probémoslo.
import torchvision
# Leer en imagen personalizada
custom_image_uint8 = torchvision.io.read_image(str(custom_image_path))
# Imprimir datos de imagen
print(f"Custom image tensor:\n{custom_image_uint8}\n")
print(f"Custom image shape: {custom_image_uint8.shape}\n")
print(f"Custom image dtype: {custom_image_uint8.dtype}")
¡Lindo! Parece que nuestra imagen está en formato tensorial; sin embargo, ¿este formato de imagen es compatible con nuestro modelo?
Nuestro tensor custom_image es del tipo de datos torch.uint8 y sus valores están entre [0, 255].
Pero nuestro modelo toma tensores de imagen del tipo de datos torch.float32 y con valores entre [0, 1].
Entonces, antes de usar nuestra imagen personalizada con nuestro modelo, tendremos que convertirla al mismo formato que los datos con los que se entrena nuestro modelo.
Si no hacemos esto, nuestro modelo generará un error.
# Intente hacer una predicción sobre la imagen en formato uint8 (esto generará un error)
model_1.eval()
with torch.inference_mode():
model_1(custom_image_uint8.to(device))
Si intentamos hacer una predicción sobre una imagen en un tipo de datos diferente al que se entrenó nuestro modelo, obtenemos un error como el siguiente:
RuntimeError: El tipo de entrada (torch.cuda.ByteTensor) y el tipo de peso (torch.cuda.FloatTensor) deben ser los mismos
Arreglemos este problema convirtiendo nuestra imagen personalizada al mismo tipo de datos en el que se entrenó nuestro modelo (torch.float32).
# Cargue una imagen personalizada y convierta los valores del tensor a float32
custom_image = torchvision.io.read_image(str(custom_image_path)).type(torch.float32)
# Divida los valores de píxeles de la imagen por 255 para obtenerlos entre [0, 1]
custom_image = custom_image / 255.
# Imprimir datos de imagen
print(f"Custom image tensor:\n{custom_image}\n")
print(f"Custom image shape: {custom_image.shape}\n")
print(f"Custom image dtype: {custom_image.dtype}")
11.2 Predicción de imágenes personalizadas con un modelo PyTorch entrenado¶
Hermoso, parece que nuestros datos de imagen ahora están en el mismo formato en el que se entrenó nuestro modelo.
Excepto por una cosa...
Es "forma".
Nuestro modelo fue entrenado en imágenes con forma "[3, 64, 64]", mientras que nuestra imagen personalizada actualmente es "[3, 4032, 3024]".
¿Cómo podemos asegurarnos de que nuestra imagen personalizada tenga la misma forma que las imágenes en las que se entrenó nuestro modelo?
¿Hay algún torchvision.transforms que pueda ayudar?
Antes de responder esa pregunta, tracemos la imagen con matplotlib para asegurarnos de que se vea bien. Recuerde que tendremos que permutar las dimensiones de CHW a HWC para adaptarlas a los requisitos de matplotlib.
# Trazar imagen personalizada
plt.imshow(custom_image.permute(1, 2, 0)) # need to permute image dimensions from CHW -> HWC otherwise matplotlib will error
plt.title(f"Image shape: {custom_image.shape}")
plt.axis(False);
¡Dos pulgares arriba!
Ahora bien, ¿cómo podríamos hacer que nuestra imagen tenga el mismo tamaño que las imágenes en las que se entrenó nuestro modelo?
Una forma de hacerlo es con torchvision.transforms.Resize().
Compongamos una canalización de transformación para hacerlo.
# Crear canal de transformación para cambiar el tamaño de la imagen
custom_image_transform = transforms.Compose([
transforms.Resize((64, 64)),
])
# Transformar imagen de destino
custom_image_transformed = custom_image_transform(custom_image)
# Imprime la forma original y la nueva forma.
print(f"Original shape: {custom_image.shape}")
print(f"New shape: {custom_image_transformed.shape}")
¡Guau!
Finalmente hagamos una predicción sobre nuestra propia imagen personalizada.
model_1.eval()
with torch.inference_mode():
custom_image_pred = model_1(custom_image_transformed)
Oh Dios mío...
A pesar de nuestros preparativos, nuestra imagen y modelo personalizados están en diferentes dispositivos.
Y obtenemos el error:
RuntimeError: Se esperaba que todos los tensores estuvieran en el mismo dispositivo, pero encontré al menos dos dispositivos, cpu y cuda:0. (al comprobar el peso del argumento en el método wrapper___slow_conv2d_forward)
Arreglemos eso poniendo nuestra custom_image_transformed en el dispositivo de destino.
model_1.eval()
with torch.inference_mode():
custom_image_pred = model_1(custom_image_transformed.to(device))
¿Ahora que?
Parece que estamos recibiendo un error de forma.
¿Por qué podría ser esto?
Convertimos nuestra imagen personalizada para que tenga el mismo tamaño que las imágenes en las que se entrenó nuestro modelo...
Oh espera...
Hay una dimensión que nos olvidamos.
El tamaño del lote.
Nuestro modelo espera tensores de imagen con una dimensión de tamaño de lote al inicio ("NCHW" donde "N" es el tamaño de lote).
Excepto que nuestra imagen personalizada actualmente es solo "CHW".
Podemos agregar una dimensión de tamaño de lote usando torch.unsqueeze(dim=0) para agregar una dimensión adicional a nuestra imagen y finalmente hacer una predicción.
Básicamente, le indicaremos a nuestro modelo que prediga en una sola imagen (una imagen con un batch_size de 1).
model_1.eval()
with torch.inference_mode():
# Add an extra dimension to image
custom_image_transformed_with_batch_size = custom_image_transformed.unsqueeze(dim=0)
# Print out different shapes
print(f"Custom image transformed shape: {custom_image_transformed.shape}")
print(f"Unsqueezed custom image shape: {custom_image_transformed_with_batch_size.shape}")
# Make a prediction on image with an extra dimension
custom_image_pred = model_1(custom_image_transformed.unsqueeze(dim=0).to(device))
¡¡¡Sí!!!
¡Parece que funcionó!
Nota: Lo que acabamos de analizar son tres de los problemas clásicos y más comunes de aprendizaje profundo y PyTorch:
- Tipos de datos incorrectos: nuestro modelo espera
torch.float32donde nuestra imagen personalizada original erauint8.- Dispositivo incorrecto: nuestro modelo estaba en el "dispositivo" de destino (en nuestro caso, la GPU), mientras que nuestros datos de destino aún no se habían movido al "dispositivo" de destino.
- Formas incorrectas: nuestro modelo esperaba una imagen de entrada con la forma
[N, C, H, W]o[batch_size, color_channels, height, width]mientras que nuestro tensor de imagen personalizado tenía la forma[canales_color, alto, ancho].Tenga en cuenta que estos errores no son solo para predecir en imágenes personalizadas.
Estarán presentes en casi todos los tipos de datos (texto, audio, datos estructurados) y problemas con los que trabaje.
Ahora echemos un vistazo a las predicciones de nuestro modelo.
custom_image_pred
Muy bien, estos todavía están en forma logit (las salidas sin procesar de un modelo se llaman logits).
Convirtámoslos de logits -> probabilidades de predicción -> etiquetas de predicción.
# Imprima logs de predicción
print(f"Prediction logits: {custom_image_pred}")
# Convertir logits -> probabilidades de predicción (usando torch.softmax() para clasificación de clases múltiples)
custom_image_pred_probs = torch.softmax(custom_image_pred, dim=1)
print(f"Prediction probabilities: {custom_image_pred_probs}")
# Convertir probabilidades de predicción -> etiquetas de predicción
custom_image_pred_label = torch.argmax(custom_image_pred_probs, dim=1)
print(f"Prediction label: {custom_image_pred_label}")
¡Está bien!
Luciendo bien.
Pero, por supuesto, nuestra etiqueta de predicción todavía está en forma de índice/tensor.
Podemos convertirlo en una predicción de nombre de clase de cadena indexando en la lista class_names.
# Encuentra la etiqueta prevista
custom_image_pred_class = class_names[custom_image_pred_label.cpu()] # put pred label to CPU, otherwise will error
custom_image_pred_class
Guau.
Parece que el modelo hace la predicción correcta, a pesar de que tuvo un desempeño deficiente según nuestras métricas de evaluación.
Nota: El modelo en su forma actual predecirá "pizza", "filete" o "sushi" sin importar la imagen que se le dé. Si quisieras que tu modelo predijera en una clase diferente, tendrías que entrenarlo para hacerlo.
Pero si verificamos custom_image_pred_probs, notaremos que el modelo otorga casi el mismo peso (los valores son similares) a cada clase.
# Los valores de las probabilidades de predicción son bastante similares.
custom_image_pred_probs
Tener probabilidades de predicción tan similares podría significar un par de cosas:
- El modelo intenta predecir las tres clases al mismo tiempo (puede haber una imagen que contenga pizza, bistec y sushi).
- El modelo no sabe realmente lo que quiere predecir y, a su vez, simplemente asigna valores similares a cada una de las clases.
Nuestro caso es el número 2, dado que nuestro modelo está mal entrenado, básicamente se trata de adivinar la predicción.
11.3 Armar la predicción de imágenes personalizadas: construir una función¶
Realizar todos los pasos anteriores cada vez que desee hacer una predicción sobre una imagen personalizada rápidamente se volvería tedioso.
Así que juntémoslos todos en una función que podamos usar fácilmente una y otra vez.
Específicamente, hagamos una función que:
- Toma una ruta de imagen de destino y la convierte al tipo de datos correcto para nuestro modelo (
torch.float32). - Se asegura de que los valores de píxeles de la imagen de destino estén en el rango
[0, 1]. - Transforma la imagen de destino si es necesario.
- Se asegura de que el modelo esté en el dispositivo de destino.
- Realiza una predicción sobre la imagen de destino con un modelo entrenado (asegurándose de que la imagen tenga el tamaño correcto y esté en el mismo dispositivo que el modelo).
- Convierte los logits de salida del modelo en probabilidades de predicción.
- Convierte las probabilidades de predicción en etiquetas de predicción.
- Traza la imagen de destino junto con la predicción del modelo y la probabilidad de predicción.
¡Unos pocos pasos, pero lo tenemos!
def pred_and_plot_image(model: torch.nn.Module,
image_path: str,
class_names: List[str] = None,
transform=None,
device: torch.device = device):
"""Makes a prediction on a target image and plots the image with its prediction."""
# 1. Load in image and convert the tensor values to float32
target_image = torchvision.io.read_image(str(image_path)).type(torch.float32)
# 2. Divide the image pixel values by 255 to get them between [0, 1]
target_image = target_image / 255.
# 3. Transform if necessary
if transform:
target_image = transform(target_image)
# 4. Make sure the model is on the target device
model.to(device)
# 5. Turn on model evaluation mode and inference mode
model.eval()
with torch.inference_mode():
# Add an extra dimension to the image
target_image = target_image.unsqueeze(dim=0)
# Make a prediction on image with an extra dimension and send it to the target device
target_image_pred = model(target_image.to(device))
# 6. Convert logits -> prediction probabilities (using torch.softmax() for multi-class classification)
target_image_pred_probs = torch.softmax(target_image_pred, dim=1)
# 7. Convert prediction probabilities -> prediction labels
target_image_pred_label = torch.argmax(target_image_pred_probs, dim=1)
# 8. Plot the image alongside the prediction and prediction probability
plt.imshow(target_image.squeeze().permute(1, 2, 0)) # make sure it's the right size for matplotlib
if class_names:
title = f"Pred: {class_names[target_image_pred_label.cpu()]} | Prob: {target_image_pred_probs.max().cpu():.3f}"
else:
title = f"Pred: {target_image_pred_label} | Prob: {target_image_pred_probs.max().cpu():.3f}"
plt.title(title)
plt.axis(False);
Qué función tan bonita, probémosla.
# Pred en nuestra imagen personalizada
pred_and_plot_image(model=model_1,
image_path=custom_image_path,
class_names=class_names,
transform=custom_image_transform,
device=device)
¡Dos pulgares arriba otra vez!
Parece que nuestro modelo acertó en la predicción con solo adivinar.
Sin embargo, este no será siempre el caso con otras imágenes...
La imagen también está pixelada porque cambiamos su tamaño a "[64, 64]" usando "custom_image_transform".
Ejercicio: Intenta hacer una predicción con una de tus propias imágenes de pizza, bistec o sushi y observa qué sucede.
Principales conclusiones¶
Hemos cubierto bastante en este módulo.
Resumámoslo con algunos puntos.
- PyTorch tiene muchas funciones integradas para manejar todo tipo de datos, desde visión hasta texto, audio y sistemas de recomendación.
- Si las funciones de carga de datos integradas de PyTorch no se adaptan a sus necesidades, puede escribir código para crear sus propios conjuntos de datos personalizados subclasificando
torch.utils.data.Dataset. torch.utils.data.DataLoader' en PyTorch ayuda a convertir suDataseten iterables que se pueden usar al entrenar y probar un modelo.- Gran parte del aprendizaje automático trata del equilibrio entre sobreajuste y desajuste (anteriormente analizamos diferentes métodos para cada uno, por lo que un buen ejercicio sería investigar más y escribir código para probar las diferentes técnicas). ).
- Es posible predecir sus propios datos personalizados con un modelo entrenado, siempre y cuando formatee los datos en un formato similar al formato en el que se entrenó el modelo. Asegúrese de ocuparse de los tres grandes errores de PyTorch y de aprendizaje profundo:
- Tipos de datos incorrectos: su modelo esperaba
torch.float32cuando sus datos sontorch.uint8. - Formas de datos incorrectas: su modelo esperaba
[batch_size, color_channels, height, width]cuando sus datos son[color_channels, height, width]. - Dispositivos incorrectos: su modelo está en la GPU pero sus datos están en la CPU.
- Tipos de datos incorrectos: su modelo esperaba
Ejercicios¶
Todos los ejercicios se centran en practicar el código de las secciones anteriores.
Debería poder completarlos haciendo referencia a cada sección o siguiendo los recursos vinculados.
Todos los ejercicios deben completarse utilizando código independiente del dispositivo.
Recursos:
- Cuaderno de plantilla de ejercicios para 04
- Cuaderno de soluciones de ejemplo para 04 (pruebe los ejercicios antes de mirar esto)
- Nuestros modelos tienen un rendimiento deficiente (no se ajustan bien a los datos). ¿Cuáles son 3 métodos para prevenir el desajuste? Escríbelas y explica cada una con una frase.
- Recrea las funciones de carga de datos que creamos en las secciones 1, 2, 3 y 4. Deberías tener el
DataLoaderpreparado y probado listo para usar. - Recrea el
model_0que construimos en la sección 7. - Cree funciones de entrenamiento y prueba para
model_0. - Intenta entrenar el modelo que hiciste en el ejercicio 3 durante 5, 20 y 50 épocas, ¿qué pasa con los resultados?
- Utilice
torch.optim.Adam()con una tasa de aprendizaje de 0,001 como optimizador.
- Utilice
- Duplica la cantidad de unidades ocultas en tu modelo y entrénalo durante 20 épocas, ¿qué pasa con los resultados?
- Duplica los datos que estás usando con tu modelo y entrénalo durante 20 épocas, ¿qué pasa con los resultados?
- Nota: Puede utilizar el cuaderno de creación de datos personalizado para ampliar su conjunto de datos de Food101 .
- También puede encontrar el conjunto de datos de datos dobles ya formateados (subconjunto del 20% en lugar del 10%) en GitHub, deberá escribir el código de descarga como en el ejercicio 2 para incluirlo en este cuaderno.
- Haz una predicción sobre tu propia imagen personalizada de pizza/filete/sushi (incluso puedes descargar una de Internet) y comparte tu predicción.
- ¿El modelo que entrenó en el ejercicio 7 lo hace bien?
- Si no, ¿qué crees que podrías hacer para mejorarlo?
Extracurricular¶
- Para practicar su conocimiento de los
DatasetyDataLoaderde PyTorch a través de PyTorch [cuaderno tutorial de conjuntos de datos y cargadores de datos] (https://pytorch.org/tutorials/beginner/basics/data_tutorial.html). - Dedique 10 minutos a leer la [documentación de PyTorch
torchvision.transforms] (https://pytorch.org/vision/stable/transforms.html).- Puede ver demostraciones de transformaciones en acción en el tutorial de ilustraciones de transformaciones.
- Dedique 10 minutos a leer la [documentación
torchvision.datasets] de PyTorch (https://pytorch.org/vision/stable/datasets.html).- ¿Cuáles son algunos conjuntos de datos que le llaman la atención?
- ¿Cómo podrías intentar construir un modelo sobre estos?
- TorchData está actualmente en versión beta (a partir de abril de 2022), será una forma futura de cargar datos en PyTorch, pero puedes comenzar a Échale un vistazo ahora.
- Para acelerar los modelos de aprendizaje profundo, puede hacer algunos trucos para mejorar la computación, la memoria y los cálculos generales. Para obtener más información, lea la publicación [Cómo hacer que el aprendizaje profundo sea mejor desde los primeros principios](https://horace.io/brrr_intro .html) de Horace He.