08. Replicación de papel PyTorch¶
Bienvenido al Proyecto Milestone 2: ¡Replicación de papel PyTorch!
En este proyecto, replicaremos un trabajo de investigación sobre aprendizaje automático y crearemos un Vision Transformer (ViT) desde cero usando PyTorch.
Luego veremos cómo funciona ViT, una arquitectura de visión por computadora de última generación, en nuestro problema FoodVision Mini.
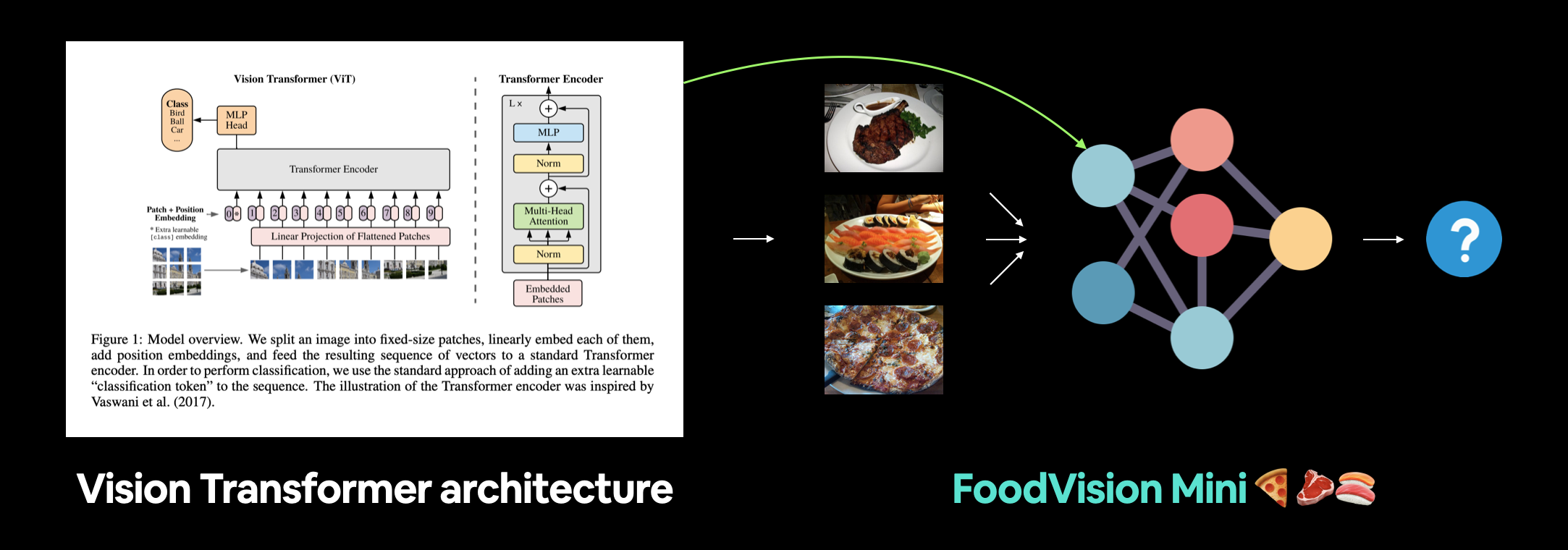
Para Milestone Project 2 nos centraremos en recrear la arquitectura de visión por computadora Vision Transformer (ViT) y aplicarla a nuestro problema FoodVision Mini para clasificar diferentes imágenes de pizza, bistec y sushi.
¿Qué se replica en papel?¶
No es ningún secreto que el aprendizaje automático avanza rápidamente.
Muchos de estos avances se publican en artículos de investigación sobre aprendizaje automático.
Y el objetivo de la replicación en papel es replicar estos avances con código para que puedas utilizar las técnicas para tu propio problema.
Por ejemplo, digamos que se lanza una nueva arquitectura de modelo que funciona mejor que cualquier otra arquitectura anterior en varios puntos de referencia, ¿no sería bueno probar esa arquitectura en sus propios problemas?

La replicación de documentos de aprendizaje automático implica convertir un documento de aprendizaje automático compuesto de imágenes/diagramas, matemáticas y texto en código utilizable y, en nuestro caso, en código PyTorch utilizable. Diagrama, ecuaciones matemáticas y texto del artículo ViT.
¿Qué es un trabajo de investigación sobre aprendizaje automático?¶
Un artículo de investigación sobre aprendizaje automático es un artículo científico que detalla los hallazgos de un grupo de investigación en un área específica.
El contenido de un trabajo de investigación sobre aprendizaje automático puede variar de un artículo a otro, pero generalmente sigue la estructura:
| Sección | Contenido |
|---|---|
| Resumen | Una descripción general/resumen de los principales hallazgos/contribuciones del artículo. |
| Introducción | Cuál es el problema principal del artículo y detalles de los métodos anteriores utilizados para intentar resolverlo. |
| Método | ¿Cómo llevaron a cabo los investigadores su investigación? Por ejemplo, ¿qué modelos, fuentes de datos y configuraciones de capacitación se utilizaron? |
| Resultados | ¿Cuáles son los resultados del artículo? Si se utilizó un nuevo tipo de modelo o configuración de entrenamiento, ¿cómo se compararon los resultados de los hallazgos con trabajos anteriores? (Aquí es donde el seguimiento de experimentos resulta útil) |
| Conclusión | ¿Cuáles son las limitaciones de los métodos sugeridos? ¿Cuáles son algunos de los próximos pasos para la comunidad de investigación? |
| Referencias | ¿Qué recursos/otros artículos examinaron los investigadores para construir su propio cuerpo de trabajo? |
| Apéndice | ¿Hay algún recurso/hallazgo adicional para analizar que no se haya incluido en ninguna de las secciones anteriores? |
¿Por qué replicar un trabajo de investigación sobre aprendizaje automático?¶
Un trabajo de investigación sobre aprendizaje automático suele ser una presentación de meses de trabajo y experimentos realizados por algunos de los mejores equipos de aprendizaje automático del mundo condensados en unas pocas páginas de texto.
Y si estos experimentos conducen a mejores resultados en un área relacionada con el problema en el que estás trabajando, sería bueno comprobarlos.
Además, replicar el trabajo de otros es una manera fantástica de practicar tus habilidades.

George Hotz es fundador de comma.ai, una empresa de vehículos autónomos y transmite en vivo codificación de aprendizaje automático en Twitch y esos videos se publican completos en YouTube. Saqué esta cita de una de sus transmisiones en vivo. La "٭" es para señalar que la ingeniería de aprendizaje automático a menudo implica pasos adicionales de preprocesamiento de datos y hacer que sus modelos estén disponibles para que otros los utilicen (implementación).
Cuando empiece a intentar replicar trabajos de investigación, probablemente se sentirá abrumado.
Eso es normal.
Los equipos de investigación pasan semanas, meses y, a veces, años creando estos trabajos, por lo que tiene sentido si te lleva algún tiempo incluso leerlos y mucho menos reproducirlos.
Replicar la investigación es un problema muy difícil, bibliotecas y herramientas de aprendizaje automático fenomenales como HuggingFace, [Modelos de imágenes PyTorch](https://github.com/rwightman/pytorch-image -models) (biblioteca timm) y fast.ai nacieron para hacer que la investigación sobre aprendizaje automático sea más accesible.
¿Dónde puede encontrar ejemplos de código para artículos de investigación sobre aprendizaje automático?¶
Una de las primeras cosas que notará cuando se trata de investigación sobre aprendizaje automático es que hay mucha.
Así que cuidado, tratar de estar al tanto es como intentar dejar atrás una rueda de hámster.
Siga sus intereses, elija algunas cosas que le llamen la atención.
Dicho esto, hay varios lugares para encontrar y leer artículos (y códigos) de investigación sobre aprendizaje automático:
| Recurso | ¿Qué es? |
|---|---|
| arXiv | Se pronuncia "archivo", arXiv es un recurso abierto y gratuito para leer artículos técnicos sobre todo, desde física hasta ciencias de la computación (incluido el aprendizaje automático). |
| AK Twitter | La cuenta de Twitter de AK publica aspectos destacados de las investigaciones sobre aprendizaje automático, a menudo con demostraciones en vivo casi todos los días. No entiendo 9/10 publicaciones, pero me resulta divertido explorarlas de vez en cuando. |
| Documentos con código | Una colección seleccionada de artículos de aprendizaje automático destacados, activos y de tendencia, muchos de los cuales incluyen recursos de código adjuntos. También incluye una colección de conjuntos de datos comunes de aprendizaje automático, puntos de referencia y modelos actuales de última generación. |
repositorio GitHub vit-pytorch de lucidrains |
Menos un lugar para encontrar artículos de investigación y más un ejemplo de cómo se ve la replicación de artículos con código a mayor escala y con un enfoque específico. El repositorio vit-pytorch es una colección de arquitecturas modelo Vision Transformer de varios artículos de investigación replicadas con código PyTorch (gran parte de la inspiración para este cuaderno se obtuvo de este repositorio). |
Nota: Esta lista está lejos de ser exhaustiva. Sólo enumero algunos lugares, los que uso con más frecuencia personalmente. Así que cuidado con el sesgo. Sin embargo, he notado que incluso esta breve lista a menudo satisface parcialmente mis necesidades de saber lo que sucede en el campo. Un poco más y podría volverme loco.
Qué vamos a cubrir¶
En lugar de hablar de replicar un artículo, vamos a ponernos manos a la obra y realmente replicar un artículo.
El proceso para replicar todos los artículos será ligeramente diferente, pero al ver cómo es hacer uno, tendremos el impulso para hacer más.
Más específicamente, vamos a replicar el artículo de investigación sobre aprendizaje automático Una imagen vale 16x16 palabras: transformadores para el reconocimiento de imágenes a escala (artículo ViT) con PyTorch.
La arquitectura de la red neuronal Transformer se introdujo originalmente en el artículo de investigación sobre aprendizaje automático [La atención es todo lo que necesita] (https://arxiv.org/abs/1706.03762).
Y la arquitectura Transformer original fue diseñada para funcionar en secuencias de texto unidimensionales (1D).
Generalmente se considera que una arquitectura transformadora es cualquier red neuronal que utiliza el mecanismo de atención) como su capa de aprendizaje principal. Similar a cómo una red neuronal convolucional (CNN) utiliza convoluciones como su capa de aprendizaje principal.
Como sugiere el nombre, la arquitectura Vision Transformer (ViT) fue diseñada para adaptar la arquitectura Transformer original a los problemas de visión (la clasificación es la primera y muchas otras le han seguido).
El Vision Transformer original ha pasado por varias iteraciones en los últimos años; sin embargo, nos centraremos en replicar el original, también conocido como el "Vision Transformer vainilla". Porque si puedes recrear el original, puedes adaptarte a los demás.
Nos centraremos en construir la arquitectura ViT según el artículo original de ViT y aplicarla a FoodVision Mini.
| Tema | Contenido |
|---|---|
| 0. Obteniendo configuración | Hemos escrito bastante código útil en las últimas secciones, descarguémoslo y asegurémonos de poder usarlo nuevamente. |
| 1. Obtener datos | Obtengamos el conjunto de datos de clasificación de imágenes de pizza, bistec y sushi que hemos estado usando y construyamos un Vision Transformer para intentar mejorar los resultados del modelo FoodVision Mini. |
| 2. Crear conjuntos de datos y cargadores de datos | Usaremos el script data_setup.py que escribimos en el capítulo 05. PyTorch se vuelve modular para configurar nuestros DataLoaders. |
| 3. Replicación del artículo de ViT: descripción general | Replicar un trabajo de investigación sobre aprendizaje automático puede ser un desafío justo, así que antes de comenzar, dividamos el trabajo de ViT en partes más pequeñas, para que podamos replicar el papel pedazo por pedazo. |
| 4. Ecuación 1: La incrustación de parches | La arquitectura ViT se compone de cuatro ecuaciones principales, siendo la primera la incorporación de parches y posiciones. O convertir una imagen en una secuencia de parches que se pueden aprender. |
| 5. Ecuación 2: Atención de múltiples cabezales (MSA) | El mecanismo de autoatención/autoatención de múltiples cabezales (MSA) está en el corazón de cada arquitectura Transformer, incluida la arquitectura ViT. Creemos un bloque MSA utilizando las capas integradas de PyTorch. |
| 6. Ecuación 3: Perceptrón multicapa (MLP) | La arquitectura ViT utiliza un perceptrón multicapa como parte de su codificador Transformer y para su capa de salida. Comencemos creando un MLP para Transformer Encoder. |
| 7. Creación del codificador transformador | Un codificador de transformador generalmente se compone de capas alternas de MSA (ecuación 2) y MLP (ecuación 3) unidas entre sí mediante conexiones residuales. Creemos uno apilando las capas que creamos en las secciones 5 y 6 una encima de la otra. |
| 8. Juntándolo todo para crear ViT | Tenemos todas las piezas del rompecabezas para crear la arquitectura ViT. Juntémoslas en una sola clase que podamos llamar modelo. |
| 9. Configurando el código de entrenamiento para nuestro modelo ViT | El entrenamiento de nuestra implementación ViT personalizada es similar a todos los demás modelos que hemos entrenado anteriormente. Y gracias a nuestra función train() en engine.py podemos empezar a entrenar con unas pocas líneas de código. |
10. Usando un ViT previamente entrenado de torchvision.models |
Entrenar un modelo grande como ViT suele requerir una buena cantidad de datos. Dado que solo estamos trabajando con una pequeña cantidad de imágenes de pizza, bistec y sushi, veamos si podemos aprovechar el poder del aprendizaje por transferencia para mejorar nuestro rendimiento. |
| 11. Haga predicciones en una imagen personalizada | La magia del aprendizaje automático es verlo funcionar con sus propios datos, así que tomemos nuestro modelo de mejor rendimiento y pongamos a prueba FoodVision Mini en la infame imagen pizza-dad (una foto de mi padre comiendo pizza). |
Nota: A pesar de que nos centraremos en replicar el artículo de ViT, evite atascarse demasiado en un artículo en particular, ya que a menudo aparecerán métodos nuevos y mejores rápidamente, por lo que la habilidad debe ser permanecer curioso mientras desarrolla las habilidades fundamentales para convertir las matemáticas y las palabras de una página en código funcional.
Terminología¶
Habrá unas cuantas siglas a lo largo de este cuaderno.
A la luz de esto, aquí hay algunas definiciones:
- ViT: significa Vision Transformer (la principal arquitectura de red neuronal en la que nos centraremos en replicar).
- Artículo de ViT: abreviatura del artículo de investigación original sobre aprendizaje automático que presentó la arquitectura ViT, [Una imagen vale 16x16 palabras: transformadores para el reconocimiento de imágenes a escala](https://arxiv.org/abs /2010.11929), cada vez que se menciona artículo ViT, puede estar seguro de que hace referencia a este artículo.
¿Dónde puedes obtener ayuda?¶
Todos los materiales de este curso están disponibles en GitHub.
Si tiene problemas, puede hacer una pregunta en el curso [página de debates de GitHub] (https://github.com/mrdbourke/pytorch-deep-learning/discussions).
Y, por supuesto, está la documentación de PyTorch y los foros de desarrolladores de PyTorch, un lugar muy útil para todo lo relacionado con PyTorch.
0. Configuración¶
Como lo hicimos anteriormente, asegurémonos de tener todos los módulos que necesitaremos para esta sección.
Importaremos los scripts de Python (como data_setup.py y engine.py) que creamos en 05. PyTorch se vuelve modular.
Para hacerlo, descargaremos el directorio going_modular del repositorio pytorch-deep-learning (si aún no lo tienes).
También obtendremos el paquete torchinfo si no está disponible.
torchinfo nos ayudará más adelante a darnos una representación visual de nuestro modelo.
Y dado que más adelante usaremos el paquete torchvision v0.13 (disponible a partir de julio de 2022), nos aseguraremos de tener las últimas versiones.
# Para que este portátil se ejecute con API actualizadas, necesitamos torch 1.12+ y torchvision 0.13+.
try:
import torch
import torchvision
assert int(torch.__version__.split(".")[1]) >= 12 or int(torch.__version__.split(".")[0]) == 2, "torch version should be 1.12+"
assert int(torchvision.__version__.split(".")[1]) >= 13, "torchvision version should be 0.13+"
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
except:
print(f"[INFO] torch/torchvision versions not as required, installing nightly versions.")
!pip3 install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
import torch
import torchvision
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
Nota: Si está utilizando Google Colab y la celda de arriba comienza a instalar varios paquetes de software, es posible que deba reiniciar su tiempo de ejecución después de ejecutar la celda de arriba. Después de reiniciar, puede ejecutar la celda nuevamente y verificar que tenga las versiones correctas de
torchytorchvision.
Ahora continuaremos con las importaciones regulares, configurando el código independiente del dispositivo y esta vez también obtendremos [helper_functions.py](https://github.com/mrdbourke/pytorch-deep-learning/blob/ main/helper_functions.py) script de GitHub.
El script helper_functions.py contiene varias funciones que creamos en secciones anteriores:
set_seeds()para configurar las semillas aleatorias (creadas en 07. Sección 0 de seguimiento de experimentos de PyTorch).download_data()para descargar una fuente de datos mediante un enlace (creado en [07. Sección 1 de seguimiento de experimentos de PyTorch] (https://www.learnpytorch.io/07_pytorch_experiment_tracking/#1-get-data)).plot_loss_curves()para inspeccionar los resultados del entrenamiento de nuestro modelo (creado en [04. PyTorch Custom Datasets sección 7.8](https://www.learnpytorch.io/04_pytorch_custom_datasets/#78-plot-the-loss-curves-of- modelo-0))
Nota: Puede ser una mejor idea que muchas de las funciones en el script
helper_functions.pyse fusionen engoing_modular/going_modular/utils.py, tal vez sea una extensión que le gustaría probar .
# Continuar con las importaciones regulares
import matplotlib.pyplot as plt
import torch
import torchvision
from torch import nn
from torchvision import transforms
# Intente obtener torchinfo, instálelo si no funciona
try:
from torchinfo import summary
except:
print("[INFO] Couldn't find torchinfo... installing it.")
!pip install -q torchinfo
from torchinfo import summary
# Intente importar el directorio going_modular, descárguelo de GitHub si no funciona
try:
from going_modular.going_modular import data_setup, engine
from helper_functions import download_data, set_seeds, plot_loss_curves
except:
# Get the going_modular scripts
print("[INFO] Couldn't find going_modular or helper_functions scripts... downloading them from GitHub.")
!git clone https://github.com/mrdbourke/pytorch-deep-learning
!mv pytorch-deep-learning/going_modular .
!mv pytorch-deep-learning/helper_functions.py . # get the helper_functions.py script
!rm -rf pytorch-deep-learning
from going_modular.going_modular import data_setup, engine
from helper_functions import download_data, set_seeds, plot_loss_curves
Nota: Si estás usando Google Colab y aún no tienes una GPU activada, ahora es el momento de activar una a través de
Runtime -> Cambiar tipo de tiempo de ejecución -> Acelerador de hardware -> GPU.
device = "cuda" if torch.cuda.is_available() else "cpu"
device
1. Obtener datos¶
Como continuamos con FoodVision Mini, descarguemos el conjunto de datos de imágenes de pizza, bistec y sushi que hemos estado usando.
Para hacerlo podemos usar la función download_data() de helper_functions.py que creamos en [07. Sección 1 de seguimiento de experimentos de PyTorch] (https://www.learnpytorch.io/07_pytorch_experiment_tracking/#1-get-data).
Usaremos el enlace sin formato de GitHub de los datos pizza_steak_sushi.zip y el destino a pizza_steak_sushi.
# Descargue imágenes de pizza, bistec y sushi desde GitHub
image_path = download_data(source="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip",
destination="pizza_steak_sushi")
image_path
¡Hermoso! Datos descargados, configuremos los directorios de capacitación y prueba.
# Configurar rutas de directorio para entrenar y probar imágenes
train_dir = image_path / "train"
test_dir = image_path / "test"
2. Crear conjuntos de datos y cargadores de datos¶
Ahora que tenemos algunos datos, convirtámoslos en DataLoader.
Para hacerlo podemos usar la función create_dataloaders() en data_setup.py .
Primero, crearemos una transformación para preparar nuestras imágenes.
Aquí entrará una de las primeras referencias al artículo de ViT.
En la Tabla 3, la resolución de entrenamiento se menciona como 224 (alto = 224, ancho = 224).
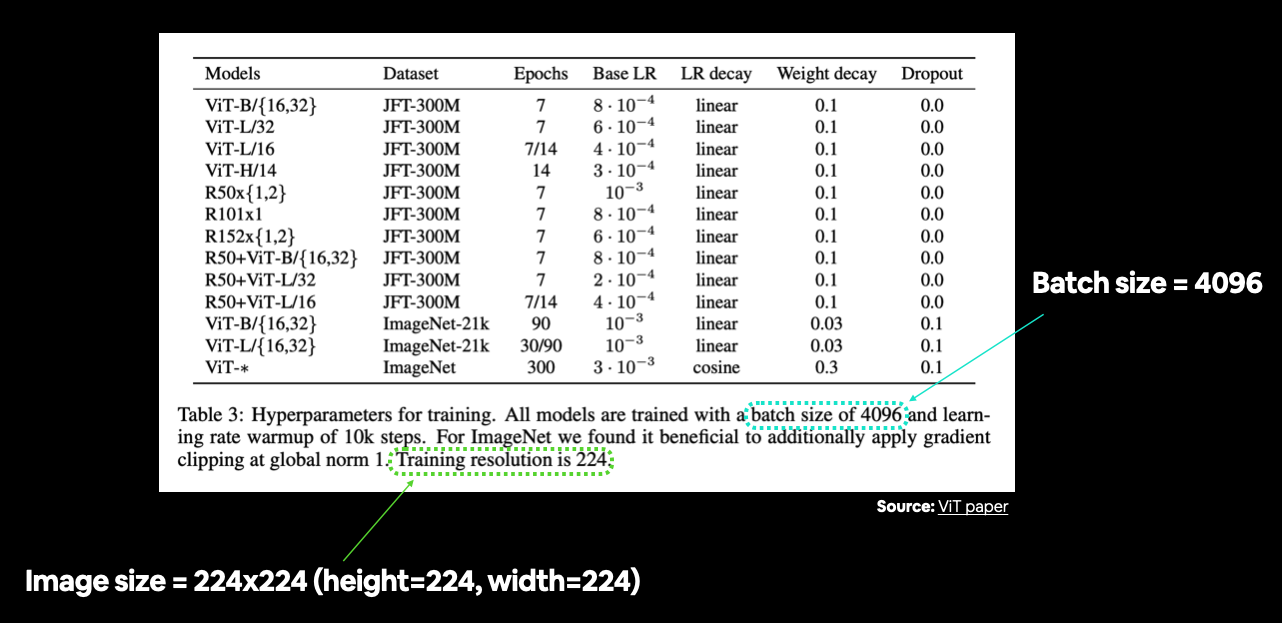
A menudo puede encontrar varias configuraciones de hiperparámetros enumeradas en una tabla. En este caso todavía estamos preparando nuestros datos, por lo que nos preocupan principalmente aspectos como el tamaño de la imagen y el tamaño del lote. Fuente: Tabla 3 en artículo de ViT.
Así que nos aseguraremos de que nuestra transformación cambie el tamaño de nuestras imágenes de manera adecuada.
Y dado que entrenaremos nuestro modelo desde cero (para empezar, no habrá aprendizaje por transferencia), no proporcionaremos una transformación "normalizada" como lo hicimos en [06. Sección 2.1 de aprendizaje por transferencia de PyTorch] (https://www.learnpytorch.io/06_pytorch_transfer_learning/#21-creating-a-transform-for-torchvisionmodels-manual-creation).
2.1 Preparar transformaciones para imágenes¶
# Crear tamaño de imagen (de la Tabla 3 en el artículo de ViT)
IMG_SIZE = 224
# Crear canalización de transformación manualmente
manual_transforms = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.ToTensor(),
])
print(f"Manually created transforms: {manual_transforms}")
2.2 Convertir imágenes en DataLoader's¶
¡Transformaciones creadas!
Ahora creemos nuestro DataLoader.
El documento de ViT establece el uso de un tamaño de lote de 4096, que es 128 veces el tamaño del lote que hemos estado usando (32).
Sin embargo, nos quedaremos con un tamaño de lote de 32.
¿Por qué?
Porque es posible que parte del hardware (incluido el nivel gratuito de Google Colab) no pueda manejar un tamaño de lote de 4096.
Tener un tamaño de lote de 4096 significa que deben caber 4096 imágenes a la vez en la memoria de la GPU.
Esto funciona cuando tienes el hardware para manejarlo, como lo hace a menudo un equipo de investigación de Google, pero cuando estás ejecutando en una sola GPU (como usando Google Colab), es una buena idea asegurarse de que las cosas funcionen primero con un tamaño de lote más pequeño. idea.
Una extensión de este proyecto podría ser probar un valor de tamaño de lote mayor y ver qué sucede.
Nota: Estamos usando el parámetro
pin_memory=Trueen la funcióncreate_dataloaders()para acelerar el cálculo.pin_memory=Trueevita la copia innecesaria de memoria entre la memoria de la CPU y la GPU al "fijar" ejemplos que se han visto antes. Aunque los beneficios de esto probablemente se verán con conjuntos de datos de mayor tamaño (nuestro conjunto de datos FoodVision Mini es bastante pequeño). Sin embargo, establecerpin_memory=Trueno siempre mejora el rendimiento (este es otro de esos escenarios en el aprendizaje automático donde algunas cosas funcionan a veces y no otras veces), así que es mejor experimentar, experimentar , experimento. Consulte la documentación de PyTorchtorch.utils.data.DataLoadero [Cómo hacer que el aprendizaje profundo sea mejor desde los primeros principios] ](https://horace.io/brrr_intro.html) de Horace He para obtener más información.
# Establecer el tamaño del lote
BATCH_SIZE = 32 # this is lower than the ViT paper but it's because we're starting small
# Crear cargadores de datos
train_dataloader, test_dataloader, class_names = data_setup.create_dataloaders(
train_dir=train_dir,
test_dir=test_dir,
transform=manual_transforms, # use manually created transforms
batch_size=BATCH_SIZE
)
train_dataloader, test_dataloader, class_names
2.3 Visualizar una sola imagen¶
Ahora que hemos cargado nuestros datos, ¡visualicemos, visualicemos, visualicemos!
Un paso importante en el artículo de ViT es preparar las imágenes en parches.
Llegaremos a lo que esto significa en la [sección 4](https://www.learnpytorch.io/08_pytorch_paper_replicating/#4-equation-1-split-data-into-patches-and-creating-the-class-position -y-incrustación de parches) pero por ahora, veamos una sola imagen y su etiqueta.
Para hacerlo, obtengamos una sola imagen y etiqueta de un lote de datos e inspeccionemos sus formas.
# Obtener un lote de imágenes
image_batch, label_batch = next(iter(train_dataloader))
# Obtenga una sola imagen del lote
image, label = image_batch[0], label_batch[0]
# Ver las formas del lote
image.shape, label
¡Maravilloso!
Ahora tracemos la imagen y su etiqueta con matplotlib.
# Trazar imagen con matplotlib
plt.imshow(image.permute(1, 2, 0)) # rearrange image dimensions to suit matplotlib [color_channels, height, width] -> [height, width, color_channels]
plt.title(class_names[label])
plt.axis(False);
¡Lindo!
Parece que nuestras imágenes se están importando correctamente, continuemos con la replicación en papel.
3. Replicación del artículo de ViT: descripción general¶
Antes de escribir más código, analicemos lo que estamos haciendo.
Nos gustaría replicar el documento ViT para nuestro propio problema, FoodVision Mini.
Entonces nuestras entradas modelo son: imágenes de pizza, bistec y sushi.
Y nuestros resultados del modelo ideales son: etiquetas previstas de pizza, bistec o sushi.
No es diferente a lo que hemos estado haciendo en las secciones anteriores.
La pregunta es: ¿cómo pasamos de nuestros insumos a los resultados deseados?
3.1 Entradas y salidas, capas y bloques¶
ViT es una arquitectura de red neuronal de aprendizaje profundo.
Y cualquier arquitectura de red neuronal generalmente se compone de capas.
Y una colección de capas a menudo se denomina bloque.
Y apilar muchos bloques es lo que nos da la arquitectura completa.
Una capa toma una entrada (por ejemplo, un tensor de imagen), realiza algún tipo de función en ella (por ejemplo, lo que hay en el método forward() de la capa) y luego devuelve una salida.
Entonces, si una capa única toma una entrada y proporciona una salida, entonces una colección de capas o un bloque también toma una entrada y proporciona una salida.
Hagamos esto concreto:
- Capa: toma una entrada, realiza una función en ella y devuelve una salida.
- Bloque: una colección de capas, toma una entrada, realiza una serie de funciones en ella y devuelve una salida.
- Arquitectura (o modelo): una colección de bloques, toma una entrada, realiza una serie de funciones en ella y devuelve una salida.
Esta ideología es la que vamos a utilizar para replicar el artículo de ViT.
Vamos a tomarlo capa por capa, bloque por bloque, función por función, juntando las piezas del rompecabezas como Lego para obtener la arquitectura general deseada.
La razón por la que hacemos esto es porque mirar un trabajo de investigación completo puede resultar intimidante.
Entonces, para una mejor comprensión, lo desglosaremos, comenzando con las entradas y salidas de una sola capa y avanzando hasta las entradas y salidas de todo el modelo.
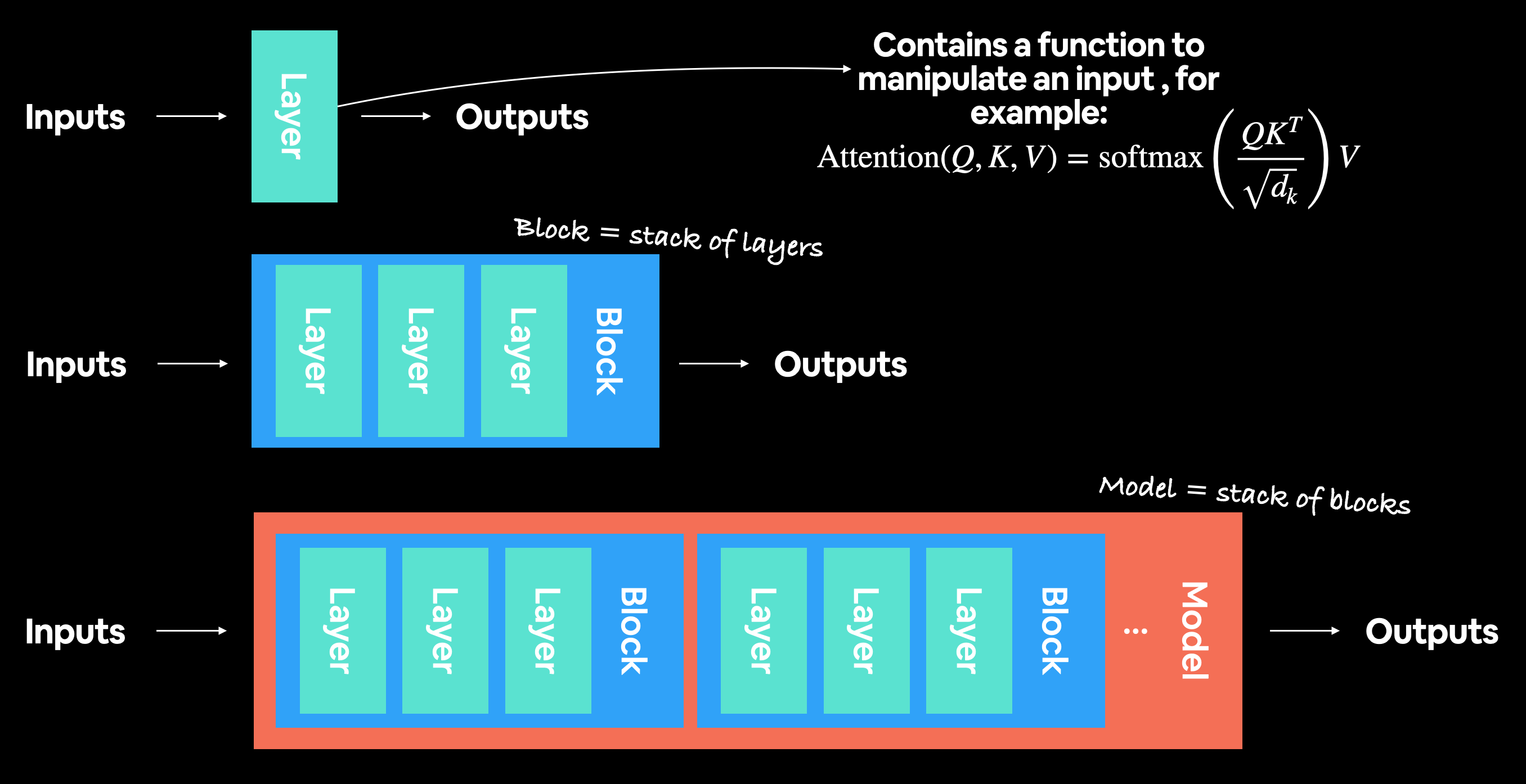
Una arquitectura moderna de aprendizaje profundo suele ser una colección de capas y bloques. Donde las capas toman una entrada (datos como representación numérica) y la manipulan usando algún tipo de función (por ejemplo, la fórmula de autoatención que se muestra arriba, sin embargo, esta función podría ser casi cualquier cosa) y luego la generan. Los bloques generalmente son pilas de capas una encima de otra que hacen algo similar a una sola capa pero varias veces.
3.2 Específico: ¿De qué está hecho ViT?¶
Hay muchos pequeños detalles sobre el modelo ViT esparcidos por todo el artículo.
¡Encontrarlos todos es como una gran búsqueda del tesoro!
Recuerde, un trabajo de investigación suele incluir meses de trabajo comprimidos en unas pocas páginas, por lo que es comprensible que requiera práctica para replicarlo.
Sin embargo, los tres recursos principales que veremos para el diseño arquitectónico son:
- Figura 1: proporciona una descripción general del modelo en un sentido gráfico; casi podrías recrear la arquitectura solo con esta figura.
- Cuatro ecuaciones en la sección 3.1: estas ecuaciones brindan una base un poco más matemática a los bloques de colores en la Figura 1.
- Tabla 1: esta tabla muestra las diversas configuraciones de hiperparámetros (como la cantidad de capas y la cantidad de unidades ocultas) para diferentes variantes del modelo ViT. Nos centraremos en la versión más pequeña, ViT-Base.
3.2.1 Explorando la Figura 1¶
Comencemos repasando la Figura 1 del documento ViT.
Las principales cosas a las que prestaremos atención son:
- Capas: toma una entrada, realiza una operación o función en la entrada y produce una salida.
- Bloques: una colección de capas, que a su vez también toma una entrada y produce una salida.
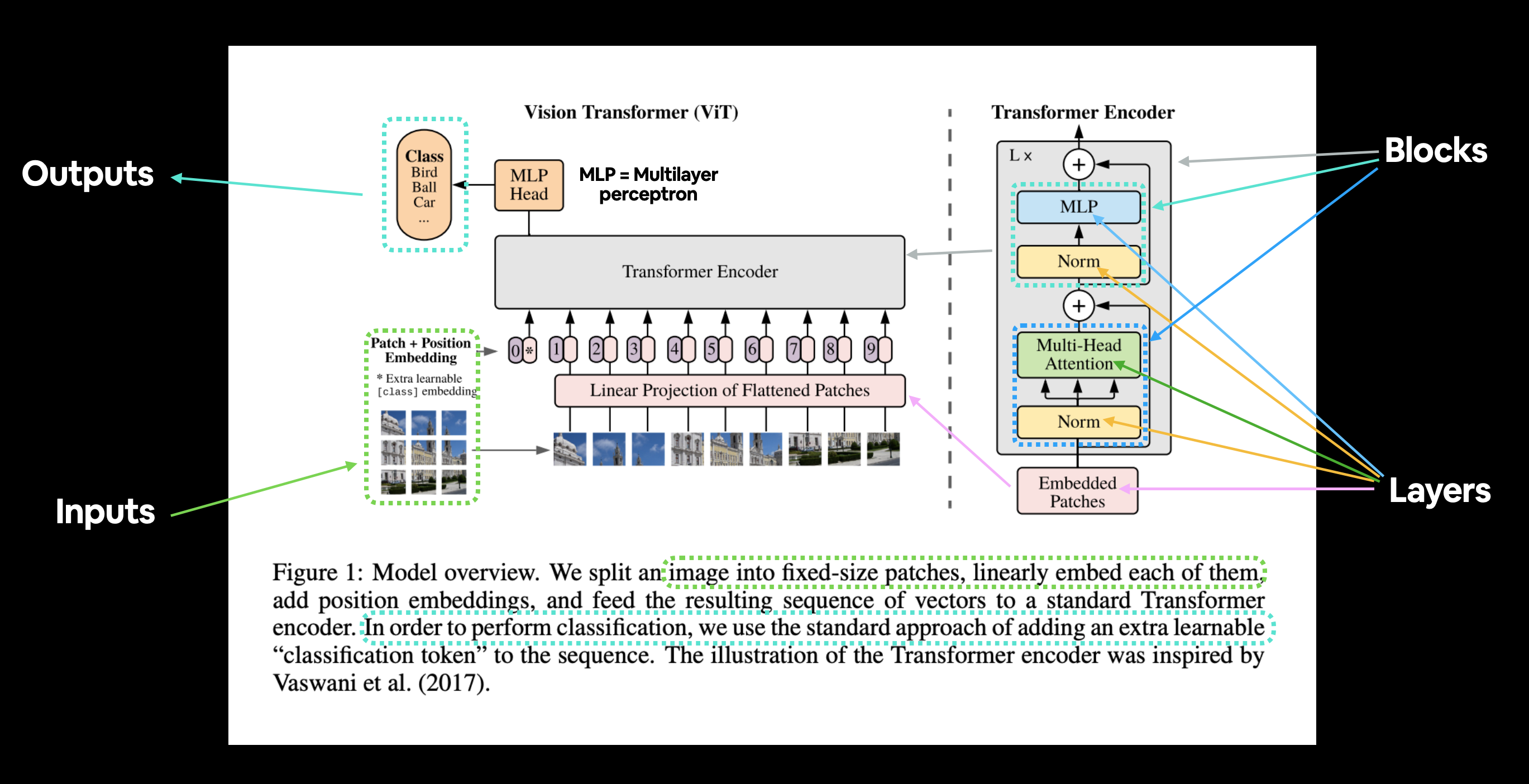
Figura 1 del ViT Paper que muestra las diferentes entradas, salidas, capas y bloques que crean la arquitectura. Nuestro objetivo será replicar cada uno de estos usando el código PyTorch.
La arquitectura ViT se compone de varias etapas:
- Incrustación de parche + posición (entradas): convierte la imagen de entrada en una secuencia de parches de imagen y agrega un número de posición para especificar en qué orden aparece el parche.
- Proyección lineal de parches aplanados (parches incrustados) - Los parches de imagen se convierten en una incrustación, la ventaja de utilizar una incrustación en lugar de solo los valores de la imagen es que una incrustación es una representación aprendible (normalmente en forma de vector) de la imagen que puede mejorar con entrenamiento.
- Norma: es la abreviatura de "Normalización de capas" o "LayerNorm", una técnica para regularizar (reducir el sobreajuste) una red neuronal. Puede usar LayerNorm a través de la capa PyTorch
torch.nn.LayerNorm(). - Atención de múltiples cabezas: esta es una [capa de autoatención de múltiples cabezas] (https://paperswithcode.com/method/multi-head-attention) o "MSA" para abreviar. Puede crear una capa MSA a través de la capa PyTorch
torch.nn.MultiheadAttention(). - MLP (o Perceptrón multicapa) - Un MLP a menudo puede referirse a cualquier colección de capas de avance (o en el caso de PyTorch, una colección de capas con un método
forward()). En el artículo de ViT, los autores se refieren al MLP como "bloque MLP" y contiene dos [torch.nn.Linear()](https://pytorch.org/docs/stable/generated/torch.nn. Linear.html) capas con una activación de no linealidadtorch.nn.GELU()entre ellas (sección 3.1) y una capatorch.nn.Dropout()después de cada una (Apéndice B.1). - Transformer Encoder: Transformer Encoder es una colección de las capas enumeradas anteriormente. Hay dos conexiones de salto dentro del codificador Transformer (los símbolos "+"), lo que significa que las entradas de la capa se envían directamente a las capas inmediatas, así como a las capas posteriores. La arquitectura general de ViT se compone de varios codificadores Transformer apilados uno encima del otro.
- MLP Head: esta es la capa de salida de la arquitectura, convierte las características aprendidas de una entrada en una salida de clase. Dado que estamos trabajando en la clasificación de imágenes, también podría llamarlo "cabeza clasificadora". La estructura del MLP Head es similar al bloque MLP.
Es posible que observe que muchas de las piezas de la arquitectura ViT se pueden crear con capas de PyTorch existentes.
Esto se debe a cómo está diseñado PyTorch, uno de los propósitos principales de PyTorch es crear capas de redes neuronales reutilizables tanto para investigadores como para profesionales del aprendizaje automático.
Pregunta: ¿Por qué no codificar todo desde cero?
Definitivamente podría hacerlo reproduciendo todas las ecuaciones matemáticas del documento con capas de PyTorch personalizadas y eso sin duda sería un ejercicio educativo; sin embargo, generalmente se prefiere el uso de capas de PyTorch preexistentes, ya que las capas preexistentes a menudo se han probado exhaustivamente. y se verifica el rendimiento para garantizar que se ejecuten correcta y rápidamente.
Nota: Nos centraremos en escribir código PyTorch para crear estas capas. Para conocer los antecedentes de lo que hace cada una de estas capas, sugeriría leer el documento ViT en su totalidad o leer los recursos vinculados para cada capa.
Tomemos la Figura 1 y adaptémosla a nuestro problema FoodVision Mini de clasificar imágenes de comida en pizza, bistec o sushi.
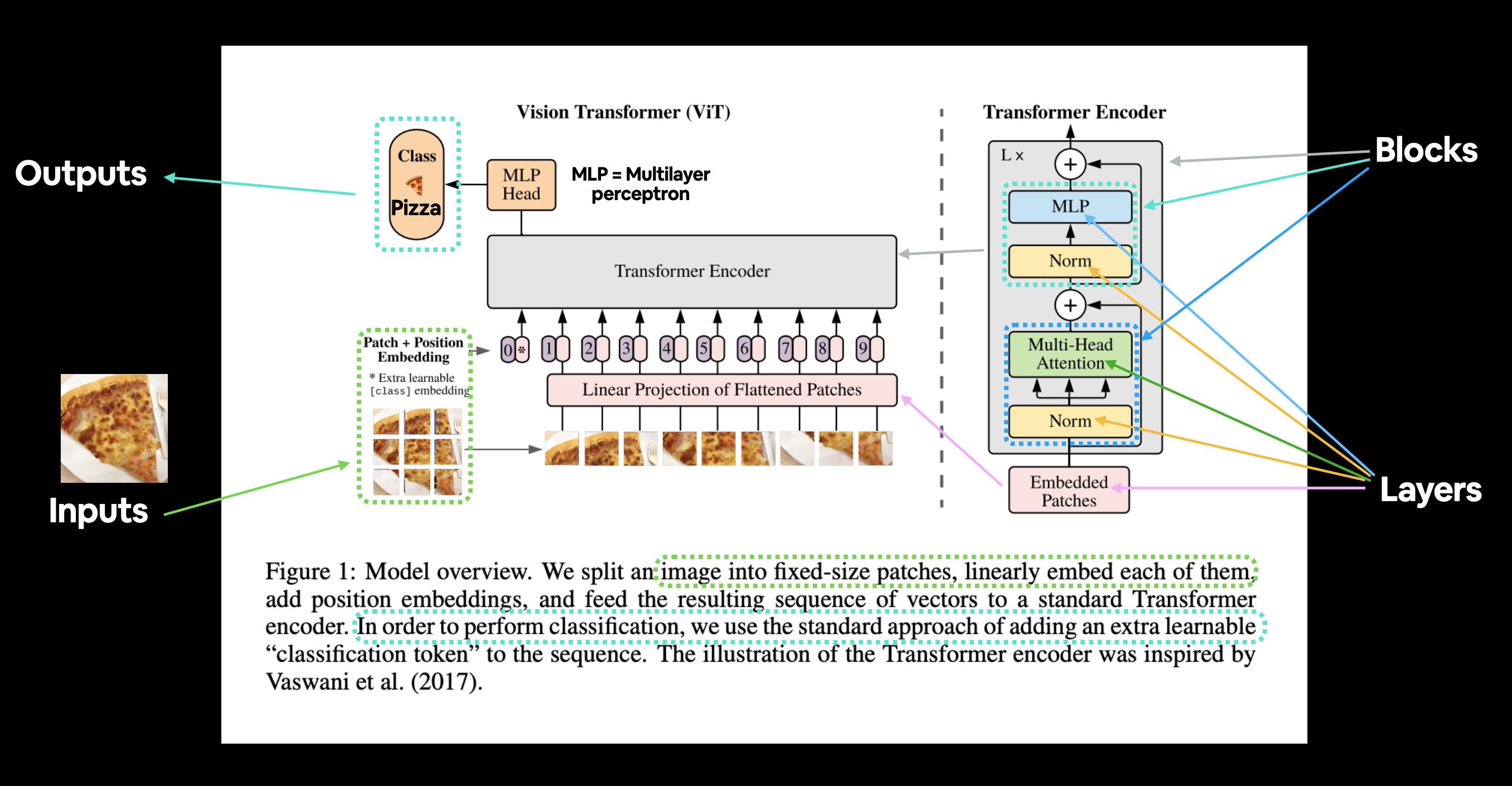
Figura 1 del ViT Paper adaptado para su uso con FoodVision Mini. Entra una imagen de comida (pizza), la imagen se convierte en parches y luego se proyecta en una incrustación. Luego, la incrustación viaja a través de las distintas capas y bloques y (con suerte) se devuelve la clase "pizza".
3.2.2 Explorando las cuatro ecuaciones¶
La siguiente(s) parte(s) principal(es) del artículo de ViT que veremos son las cuatro ecuaciones de la sección 3.1.
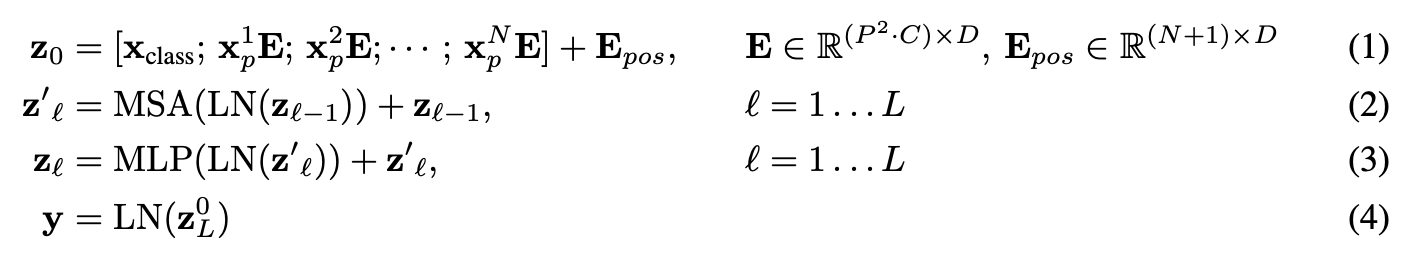
Estas cuatro ecuaciones representan las matemáticas detrás de las cuatro partes principales de la arquitectura ViT.
La Sección 3.1 describe cada uno de estos (parte del texto se ha omitido por motivos de brevedad, el texto en negrita es mío):
| Número de ecuación | Descripción de la sección 3.1 del artículo de ViT |
|---|---|
| 1 | ...El Transformador utiliza un tamaño de vector latente constante $D$ en todas sus capas, por lo que aplanamos los parches y los asignamos a dimensiones $D$ con una proyección lineal entrenable (Ec. 1). Nos referimos al resultado de esta proyección como incrustaciones de parches... Las incrustaciones de posición se agregan a las incrustaciones de parches para retener información posicional. Usamos incrustaciones de posiciones 1D que se pueden aprender... |
| 2 | El codificador Transformer (Vaswani et al., 2017) consta de capas alternas de autoatención multicabezal (MSA, ver Apéndice A) y bloques MLP (Ec. 2, 3). Layernorm (LN) se aplica antes de cada bloque y conexiones residuales después de cada bloque (Wang et al., 2019; Baevski & Auli, 2019). |
| 3 | Igual que la ecuación 2. |
| 4 | De manera similar al token [clase] de BERT, anteponemos una incrustación que se puede aprender a la secuencia de parches incrustados $\left(\mathbf{z}_{0}^{0}=\mathbf{x}_{\text {class }}\right)$, cuyo estado en la salida del codificador Transformer $\left(\mathbf{z}_{L}^{0}\right)$ sirve como representación de la imagen $\mathbf{y} $ (Ecuación 4)... |
Asignemos estas descripciones a la arquitectura ViT en la Figura 1.
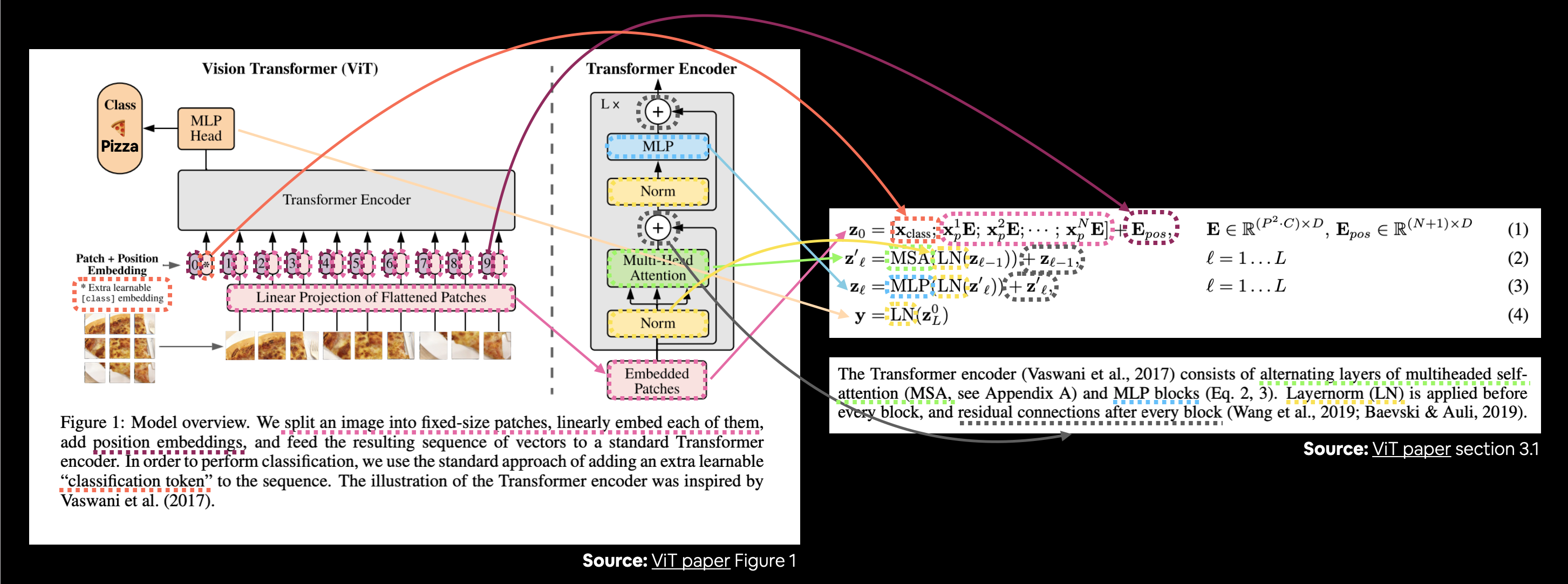
Conectando la Figura 1 del artículo de ViT con las cuatro ecuaciones de la sección 3.1 que describen las matemáticas detrás de cada una de las capas/bloques.
Están sucediendo muchas cosas en la imagen de arriba, pero al seguir las líneas y flechas de colores se revelan los conceptos principales de la arquitectura ViT.
¿Qué tal si desglosamos más cada ecuación (nuestro objetivo será recrearlas con código)?
En todas las ecuaciones (excepto la ecuación 4), "$\mathbf{z}$" es la salida sin procesar de una capa particular:
- $\mathbf{z}_{0}$ es "z cero" (esta es la salida de la capa de incrustación del parche inicial).
- $\mathbf{z}_{\ell}^{\prime}$ es "z de una capa particular prime" (o un valor intermedio de z).
- $\mathbf{z}_{\ell}$ es "z de una capa particular".
Y $\mathbf{y}$ es el resultado general de la arquitectura.
3.2.3 Descripción general de la ecuación 1¶
$$ \begin{alineado} \mathbf{z}_{0} &=\left[\mathbf{x}_{\text {clase }} ; \mathbf{x}_{p}^{1} \mathbf{E} ; \mathbf{x}_{p}^{2} \mathbf{E} ; \cdots ; \mathbf{x}_{p}^{N} \mathbf{E}\right]+\mathbf{E}_{\text {pos }}, & & \mathbf{E} \in \mathbb{R} ^{\left(P^{2} \cdot C\right) \times D}, \mathbf{E}_{\text {pos }} \in \mathbb{R}^{(N+1) \times D} \end{alineado} $$
Esta ecuación trata con el token de clase, la incrustación de parches y la incrustación de posición ($\mathbf{E}$ es para incrustar) de la imagen de entrada.
En forma vectorial, la incrustación podría verse así:
pitón
x_input = [class_token, image_patch_1, image_patch_2, image_patch_3...] + [class_token_position, image_patch_1_position, image_patch_2_position, image_patch_3_position...]
Donde cada uno de los elementos del vector se puede aprender (su requires_grad=True).
3.2.4 Descripción general de la ecuación 2¶
$$ \begin{alineado} \mathbf{z}_{\ell}^{\prime} &=\operatorname{MSA}\left(\operatorname{LN}\left(\mathbf{z}_{\ell-1}\right)\right )+\mathbf{z}_{\ell-1}, & & \ell=1 \ldots L \end{alineado} $$
Esto dice que para cada capa desde $1$ hasta $L$ (el número total de capas), hay una capa de atención de múltiples cabezales (MSA) que envuelve una capa LayerNorm (LN).
La adición al final equivale a sumar la entrada a la salida y formar una [conexión omitida/residual] (https://paperswithcode.com/method/residual-connection).
Llamaremos a esta capa "bloque MSA".
En pseudocódigo, esto podría verse así:
pitón
x_output_MSA_block = MSA_layer(LN_layer(x_input)) + x_input
Observe la conexión de salto al final (agregando la entrada de las capas a la salida de las capas).
3.2.5 Descripción general de la ecuación 3¶
$$ \begin{alineado} \mathbf{z}_{\ell} &=\operatorname{MLP}\left(\operatorname{LN}\left(\mathbf{z}_{\ell}^{\prime}\right)\right)+ \mathbf{z}_{\ell}^{\prime}, & & \ell=1 \ldots L \\ \end{alineado} $$
Esto dice que para cada capa desde $1$ hasta $L$ (el número total de capas), también hay una capa de Perceptrón multicapa (MLP) que envuelve una capa LayerNorm (LN).
La adición al final muestra la presencia de una conexión de salto/residual.
Llamaremos a esta capa "bloque MLP".
En pseudocódigo, esto podría verse así:
pitón
x_output_MLP_block = MLP_layer(LN_layer(x_output_MSA_block)) + x_output_MSA_block
Observe la conexión de salto al final (agregando la entrada de las capas a la salida de las capas).
3.2.6 Descripción general de la ecuación 4¶
$$ \begin{alineado} \mathbf{y} &=\operatorname{LN}\left(\mathbf{z}_{L}^{0}\right) & & \end{alineado} $$
Esto dice que para la última capa $L$, la salida $y$ es el token de índice 0 de $z$ envuelto en una capa LayerNorm (LN).
O en nuestro caso, el índice 0 de x_output_MLP_block:
pitón
y = capa_lineal(capa_LN(x_output_MLP_block[0]))
Por supuesto, hay algunas simplificaciones anteriores, pero nos ocuparemos de ellas cuando comencemos a escribir código PyTorch para cada sección.
Nota: La sección anterior cubre mucha información. Pero no olvides que si algo no tiene sentido, siempre puedes investigarlo más a fondo. Haciendo preguntas como "¿qué es una conexión residual?".
3.2.7 Explorando la Tabla 1¶
La última pieza del rompecabezas de la arquitectura ViT en la que nos centraremos (por ahora) es la Tabla 1.
| Modelo | Capas | Tamaño oculto $D$ | Tamaño MLP | Cabezas | Parámetros |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | 86 millones de dólares |
| ViT-Grande | 24 | 1024 | 4096 | 16 | $307M$ |
| ViT-enorme | 32 | 1280 | 5120 | 16 | $632M$ |
Esta tabla muestra los distintos hiperparámetros de cada una de las arquitecturas ViT.
Puede ver que los números aumentan gradualmente de ViT-Base a ViT-Huge.
Nos centraremos en replicar ViT-Base (comenzaremos poco a poco y ampliaremos cuando sea necesario), pero escribiremos código que pueda ampliarse fácilmente a variantes más grandes.
Desglosando los hiperparámetros:
- Capas - ¿Cuántos bloques de Transformer Encoder hay? (cada uno de estos contendrá un bloque MSA y un bloque MLP)
- Tamaño oculto $D$: esta es la dimensión de incrustación en toda la arquitectura, este será el tamaño del vector en el que se convierte nuestra imagen cuando se parchea e incrusta. Generalmente, cuanto mayor sea la dimensión de incrustación, más información se podrá capturar y mejores resultados. Sin embargo, una mayor integración tiene el costo de más computación.
- Tamaño de MLP - ¿Cuál es la cantidad de unidades ocultas en las capas de MLP?
- Cabezas - ¿Cuántas cabezas hay en las capas de Atención de múltiples cabezas?
- Params - ¿Cuál es el número total de parámetros del modelo? Generalmente, más parámetros conducen a un mejor rendimiento, pero a costa de más procesamiento. Notarás que incluso ViT-Base tiene muchos más parámetros que cualquier otro modelo que hayamos usado hasta ahora.
Usaremos estos valores como configuración de hiperparámetros para nuestra arquitectura ViT.
3.3 Mi flujo de trabajo para replicar artículos¶
Cuando empiezo a trabajar en la replicación de un artículo, sigo los siguientes pasos:
- Lea el documento completo de principio a fin una vez (para tener una idea de los conceptos principales).
- Vuelva a revisar cada sección y vea cómo se alinean entre sí y comience a pensar en cómo podrían convertirse en código (como se muestra arriba).
- Repita el paso 2 hasta que tenga un esquema bastante bueno.
- Utilice mathpix.com (una herramienta muy útil) para convertir cualquier sección del papel en Markdown/LaTeX para guardarlo en cuadernos.
- Replica la versión más simple posible del modelo.
- Si me quedo atascado, busca otros ejemplos.

Convertir las cuatro ecuaciones del documento ViT en LaTeX/markdown editable usando mathpix.com.
Ya hemos realizado los primeros pasos anteriores (y si aún no ha leído el documento completo, le animo a que lo pruebe) pero en lo que nos centraremos a continuación es en el paso 5: replicar el versión más simple posible del modelo.
Por eso comenzamos con ViT-Base.
Replicar la versión más pequeña posible de la arquitectura, hacerla funcionar y luego podremos ampliarla si quisiéramos.
Nota: Si nunca antes ha leído un trabajo de investigación, muchos de los pasos anteriores pueden resultar intimidantes. Pero no te preocupes, como todo, tus habilidades para leer y replicar artículos mejorarán con la práctica. No olvide que un trabajo de investigación suele ser meses de trabajo de muchas personas comprimidos en unas pocas páginas. Así que intentar replicarlo por tu cuenta no es tarea fácil.
4. Ecuación 1: dividir los datos en parches y crear la clase, la posición y la incrustación del parche¶
Recuerdo que uno de mis amigos ingenieros de aprendizaje automático solía decir "se trata de la integración".
Es decir, si puede representar sus datos de una manera buena y fácil de aprender (ya que las incrustaciones son representaciones que se pueden aprender), es probable que un algoritmo de aprendizaje pueda funcionar bien con ellos.
Dicho esto, comencemos por crear las incrustaciones de clases, posiciones y parches para la arquitectura ViT.
Comenzaremos con la incrustación del parche.
Esto significa que convertiremos nuestras imágenes de entrada en una secuencia de parches y luego los incrustaremos.
Recuerde que una incrustación es una representación que se puede aprender de alguna forma y, a menudo, es un vector.
El término aprendeble es importante porque significa que la representación numérica de una imagen de entrada (que ve el modelo) se puede mejorar con el tiempo.
Comenzaremos siguiendo el párrafo inicial de la sección 3.1 del documento de ViT (negrita mía):
El transformador estándar recibe como entrada una secuencia 1D de incrustaciones de tokens. Para manejar imágenes 2D, remodelamos la imagen $\mathbf{x} \in \mathbb{R}^{H \times W \times C}$ en una secuencia de parches 2D aplanados $\mathbf{x}_{p} \in \mathbb{R}^{N \times\left(P^{2} \cdot C\right)}$, donde $(H, W)$ es la resolución de la imagen original, $C$ es la número de canales, $(P, P)$ es la resolución de cada parche de imagen y $N=H W / P^{2}$ es el número resultante de parches, que también sirve como longitud efectiva de la secuencia de entrada para el transformador. . El Transformador utiliza un tamaño de vector latente constante $D$ en todas sus capas, por lo que aplanamos los parches y los asignamos a dimensiones $D$ con una proyección lineal entrenable (Ec. 1). Nos referimos al resultado de esta proyección como incrustaciones de parches.
Y el tamaño, estamos tratando con formas de imágenes, tengamos en cuenta la línea de la Tabla 3 del artículo de ViT:
La resolución del entrenamiento es 224.
Analicemos el texto anterior.
- $D$ es el tamaño de las incrustaciones de parches; en la Tabla 1 se pueden encontrar diferentes valores de $D$ para modelos ViT de varios tamaños.
- La imagen comienza como 2D con tamaño ${H \times W \times C}$.
- $(H, W)$ es la resolución de la imagen original (alto, ancho).
- $C$ es el número de canales.
- La imagen se convierte en una secuencia de parches 2D aplanados con tamaño ${N \times\left(P^{2} \cdot C\right)}$.
- $(P, P)$ es la resolución de cada parche de imagen (tamaño del parche).
- $N=H W / P^{2}$ es el número resultante de parches, que también sirve como longitud de la secuencia de entrada para el Transformer.
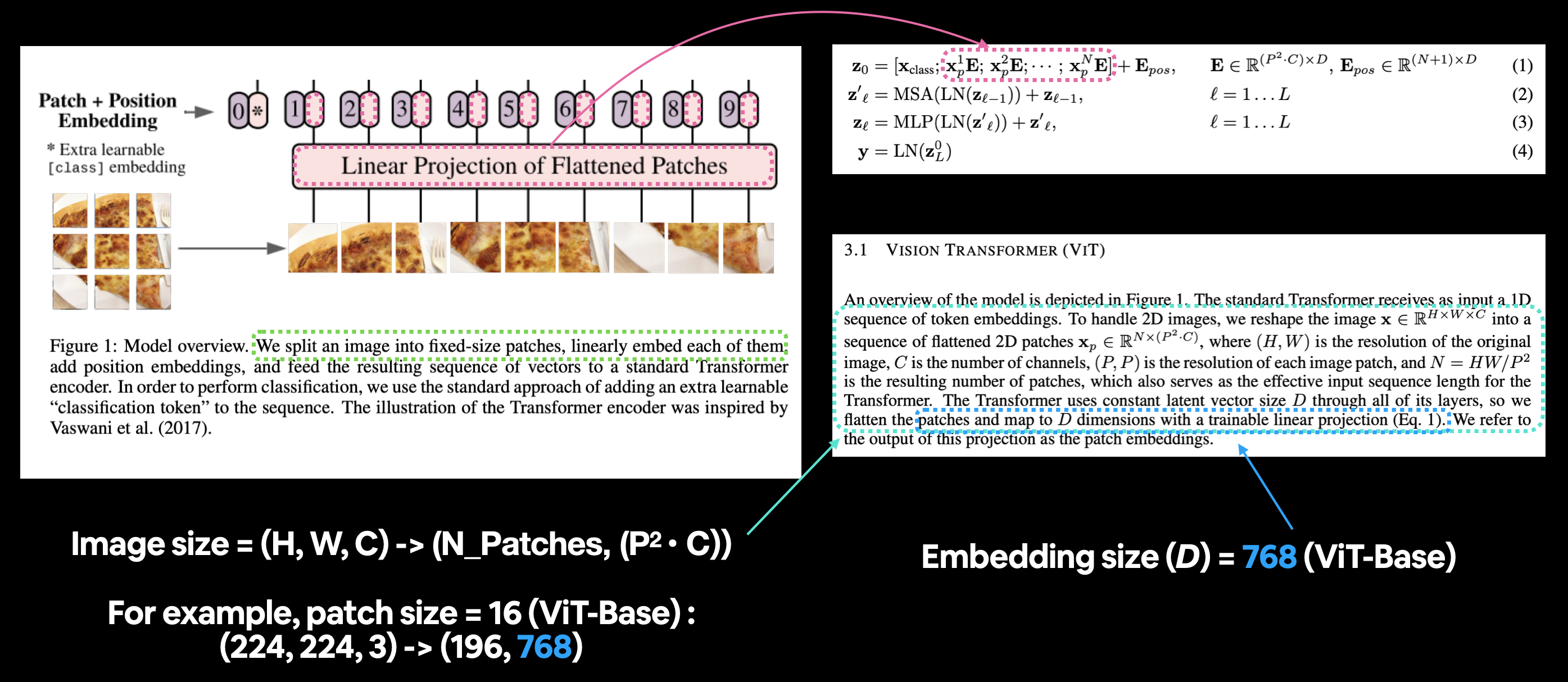
Mapeo del parche y la porción de incrustación de posición de la arquitectura ViT de la Figura 1 a la Ecuación 1. El párrafo inicial de la sección 3.1 describe las diferentes formas de entrada y salida de la capa de incrustación del parche.
4.1 Cálculo manual de formas de entrada y salida de incrustación de parches¶
¿Qué tal si comenzamos calculando estos valores de forma de entrada y salida a mano?
Para hacerlo, creemos algunas variables para imitar cada uno de los términos (como $H$, $W$, etc.) anteriores.
Usaremos un tamaño de parche ($P$) de 16 ya que es la versión de mejor rendimiento que utiliza ViT-Base (consulte la columna "ViT-B/16" de la Tabla 5 en el documento de ViT para obtener más información).
# Crear valores de ejemplo
height = 224 # H ("The training resolution is 224.")
width = 224 # W
color_channels = 3 # C
patch_size = 16 # P
# Calcular N (número de parches)
number_of_patches = int((height * width) / patch_size**2)
print(f"Number of patches (N) with image height (H={height}), width (W={width}) and patch size (P={patch_size}): {number_of_patches}")
Tenemos la cantidad de parches, ¿qué tal si creamos también el tamaño de salida de la imagen?
Mejor aún, repliquemos las formas de entrada y salida de la capa de incrustación del parche.
Recordar:
- Entrada: La imagen comienza como 2D con tamaño ${H \times W \times C}$.
- Salida: La imagen se convierte en una secuencia de parches 2D aplanados con tamaño ${N \times\left(P^{2} \cdot C\right)}$.
# Forma de entrada (este es el tamaño de una sola imagen)
embedding_layer_input_shape = (height, width, color_channels)
# Forma de salida
embedding_layer_output_shape = (number_of_patches, patch_size**2 * color_channels)
print(f"Input shape (single 2D image): {embedding_layer_input_shape}")
print(f"Output shape (single 2D image flattened into patches): {embedding_layer_output_shape}")
¡Formas de entrada y salida adquiridas!
4.2 Convertir una sola imagen en parches¶
Ahora que conocemos las formas ideales de entrada y salida para nuestra capa de incrustación de parche, avancemos hacia su creación.
Lo que estamos haciendo es dividir la arquitectura general en partes más pequeñas, centrándonos en las entradas y salidas de capas individuales.
Entonces, ¿cómo creamos la capa de incrustación del parche?
Llegaremos a eso en breve, primero, ¡visualicemos, visualicemos, visualicemos! cómo se ve convertir una imagen en parches.
Comencemos con nuestra imagen única.
# Ver una sola imagen
plt.imshow(image.permute(1, 2, 0)) # adjust for matplotlib
plt.title(class_names[label])
plt.axis(False);
Queremos convertir esta imagen en parches de sí misma en línea con la Figura 1 del artículo de ViT.
¿Qué tal si comenzamos visualizando simplemente la fila superior de píxeles parcheados?
Podemos hacer esto indexando las diferentes dimensiones de la imagen.
# Cambie la forma de la imagen para que sea compatible con matplotlib (color_channels, alto, ancho) -> (alto, ancho, color_channels)
image_permuted = image.permute(1, 2, 0)
# Índice para trazar la fila superior de píxeles parcheados
patch_size = 16
plt.figure(figsize=(patch_size, patch_size))
plt.imshow(image_permuted[:patch_size, :, :]);
Ahora que tenemos la fila superior, convirtámosla en parches.
Podemos hacer esto repitiendo la cantidad de parches que habría en la fila superior.
# Configure los hiperparámetros y asegúrese de que img_size y patch_size sean compatibles
img_size = 224
patch_size = 16
num_patches = img_size/patch_size
assert img_size % patch_size == 0, "Image size must be divisible by patch size"
print(f"Number of patches per row: {num_patches}\nPatch size: {patch_size} pixels x {patch_size} pixels")
# Crea una serie de subtramas.
fig, axs = plt.subplots(nrows=1,
ncols=img_size // patch_size, # one column for each patch
figsize=(num_patches, num_patches),
sharex=True,
sharey=True)
# Iterar a través del número de parches en la fila superior
for i, patch in enumerate(range(0, img_size, patch_size)):
axs[i].imshow(image_permuted[:patch_size, patch:patch+patch_size, :]); # keep height index constant, alter the width index
axs[i].set_xlabel(i+1) # set the label
axs[i].set_xticks([])
axs[i].set_yticks([])
¡Esos son unos parches muy bonitos!
¿Qué tal si lo hacemos para toda la imagen?
Esta vez recorreremos los índices de alto y ancho y trazaremos cada parche como su propia trama secundaria.
# Configure los hiperparámetros y asegúrese de que img_size y patch_size sean compatibles
img_size = 224
patch_size = 16
num_patches = img_size/patch_size
assert img_size % patch_size == 0, "Image size must be divisible by patch size"
print(f"Number of patches per row: {num_patches}\
\nNumber of patches per column: {num_patches}\
\nTotal patches: {num_patches*num_patches}\
\nPatch size: {patch_size} pixels x {patch_size} pixels")
# Crea una serie de subtramas.
fig, axs = plt.subplots(nrows=img_size // patch_size, # need int not float
ncols=img_size // patch_size,
figsize=(num_patches, num_patches),
sharex=True,
sharey=True)
# Recorrer el alto y el ancho de la imagen
for i, patch_height in enumerate(range(0, img_size, patch_size)): # iterate through height
for j, patch_width in enumerate(range(0, img_size, patch_size)): # iterate through width
# Plot the permuted image patch (image_permuted -> (Height, Width, Color Channels))
axs[i, j].imshow(image_permuted[patch_height:patch_height+patch_size, # iterate through height
patch_width:patch_width+patch_size, # iterate through width
:]) # get all color channels
# Set up label information, remove the ticks for clarity and set labels to outside
axs[i, j].set_ylabel(i+1,
rotation="horizontal",
horizontalalignment="right",
verticalalignment="center")
axs[i, j].set_xlabel(j+1)
axs[i, j].set_xticks([])
axs[i, j].set_yticks([])
axs[i, j].label_outer()
# Establecer un súper título
fig.suptitle(f"{class_names[label]} -> Patchified", fontsize=16)
plt.show()
Imagen parcheada!
Vaya, eso se ve genial.
Ahora, ¿cómo convertimos cada uno de estos parches en una incrustación y los convertimos en una secuencia?
Sugerencia: podemos usar capas de PyTorch. ¿Puedes adivinar cuál?
4.3 Creando parches de imagen con torch.nn.Conv2d()¶
Hemos visto cómo se ve una imagen cuando se convierte en parches, ahora comencemos a replicar las capas de incrustación de parches con PyTorch.
Para visualizar nuestra imagen única, escribimos código para recorrer las diferentes dimensiones de alto y ancho de una sola imagen y trazar parches individuales.
Esta operación es muy similar a la operación convolucional que vimos en 03. Sección 7.1 de PyTorch Computer Vision: paso a paso por nn.Conv2d().
De hecho, los autores del artículo de ViT mencionan en la sección 3.1 que la integración del parche se puede lograr con una red neuronal convolucional (CNN):
Arquitectura híbrida. Como alternativa a los parches de imágenes sin procesar, la secuencia de entrada se puede formar a partir de mapas de características de una CNN (LeCun et al., 1989). En este modelo híbrido, la proyección de incorporación de parches $\mathbf{E}$ (Ec. 1) se aplica a parches extraídos de un mapa de características de CNN. Como caso especial, los parches pueden tener un tamaño espacial $1 \times 1$, lo que significa que la secuencia de entrada se obtiene simplemente aplanando las dimensiones espaciales del mapa de características y proyectándolas a la dimensión del Transformador. La incrustación de entrada de clasificación y la incrustación de posición se agregan como se describe anteriormente.
El "mapa de características" al que se refieren son los pesos/activaciones producidos por una capa convolucional que pasa sobre una imagen determinada.

Al establecer los parámetros kernel_size y stride de una capa torch.nn.Conv2d() iguales al patch_size, podemos obtener efectivamente una capa que divide nuestra imagen en parches y crea una incrustación que se puede aprender (denominada "Proyección lineal" en el artículo de ViT) de cada parche.
¿Recuerda nuestras formas de entrada y salida ideales para la capa de incrustación de parches?
- Entrada: La imagen comienza como 2D con tamaño ${H \times W \times C}$.
- Salida: La imagen se convierte en una secuencia 1D de parches 2D aplanados con tamaño ${N \times\left(P^{2} \cdot C\right)}$.
O para un tamaño de imagen de 224 y un tamaño de parche de 16:
- Entrada (imagen 2D): (224, 224, 3) -> (alto, ancho, canales de color)
- Salida (parches 2D aplanados): (196, 768) -> (número de parches, dimensión de incrustación)
Podemos recrearlos con:
torch.nn.Conv2d()para convertir nuestra imagen en parches de mapas de características de CNN.torch.nn.Flatten()para aplanar las dimensiones espaciales del mapa de características.
Comencemos con la capa torch.nn.Conv2d().
Podemos replicar la creación de parches estableciendo kernel_size y stride iguales a patch_size.
Esto significa que cada núcleo convolucional tendrá el tamaño (patch_size x patch_size) o si patch_size=16, (16 x 16) (el equivalente a un parche completo).
Y cada paso o "zancada" del núcleo convolucional tendrá una longitud de "patch_size" píxeles o "16" píxeles (equivalente a pasar al siguiente parche).
Estableceremos in_channels=3 para el número de canales de color en nuestra imagen y estableceremos out_channels=768, lo mismo que el valor $D$ en la Tabla 1 para ViT-Base (esta es la dimensión de incrustación , cada imagen se incrustará en un vector que se puede aprender de tamaño 768).
from torch import nn
# Establecer el tamaño del parche
patch_size=16
# Cree la capa Conv2d con hiperparámetros del documento ViT
conv2d = nn.Conv2d(in_channels=3, # number of color channels
out_channels=768, # from Table 1: Hidden size D, this is the embedding size
kernel_size=patch_size, # could also use (patch_size, patch_size)
stride=patch_size,
padding=0)
Ahora que tenemos una capa convolucional, veamos qué sucede cuando pasamos una sola imagen a través de ella.
# Ver una sola imagen
plt.imshow(image.permute(1, 2, 0)) # adjust for matplotlib
plt.title(class_names[label])
plt.axis(False);
# Pasar la imagen a través de la capa convolucional.
image_out_of_conv = conv2d(image.unsqueeze(0)) # add a single batch dimension (height, width, color_channels) -> (batch, height, width, color_channels)
print(image_out_of_conv.shape)
Pasar nuestra imagen a través de la capa convolucional la convierte en una serie de 768 (este es el tamaño de incrustación o $D$) mapas de características/activación.
Entonces su forma de salida se puede leer como:
pitón
torch.Size([1, 768, 14, 14]) -> [batch_size, embedding_dim, feature_map_height, feature_map_width]
Visualicemos cinco mapas de características aleatorias y veamos cómo se ven.
# Trazar 5 mapas de características convolucionales aleatorios
import random
random_indexes = random.sample(range(0, 758), k=5) # pick 5 numbers between 0 and the embedding size
print(f"Showing random convolutional feature maps from indexes: {random_indexes}")
# Crear trama
fig, axs = plt.subplots(nrows=1, ncols=5, figsize=(12, 12))
# Trazar mapas de características de imágenes aleatorias
for i, idx in enumerate(random_indexes):
image_conv_feature_map = image_out_of_conv[:, idx, :, :] # index on the output tensor of the convolutional layer
axs[i].imshow(image_conv_feature_map.squeeze().detach().numpy())
axs[i].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[]);
Observe cómo todos los mapas de características representan la imagen original; después de visualizar algunos más, puede comenzar a ver los diferentes contornos principales y algunas características principales.
Lo importante a tener en cuenta es que estas características pueden cambiar con el tiempo a medida que la red neuronal aprende.
Y debido a esto, estos mapas de características pueden considerarse una incrustación que se puede aprender de nuestra imagen.
Veamos uno en forma numérica.
# Obtenga un mapa de características únicas en forma tensorial
single_feature_map = image_out_of_conv[:, 0, :, :]
single_feature_map, single_feature_map.requires_grad
La salida grad_fn de single_feature_map y el atributo requires_grad=True significa que PyTorch está rastreando los gradientes de este mapa de características y se actualizará mediante el descenso de gradiente durante el entrenamiento.
4.4 Aplanando la incrustación del parche con torch.nn.Flatten()¶
Hemos convertido nuestra imagen en incrustaciones de parches, pero todavía están en formato 2D.
¿Cómo logramos que adquieran la forma de salida deseada de la capa de incrustación de parches del modelo ViT?
- Salida deseada (secuencia 1D de parches 2D aplanados): (196, 768) -> (número de parches, dimensión de incrustación) -> ${N \times\left(P^{2} \cdot C\ derecha)}$
Comprobemos la forma actual.
# Forma del tensor actual
print(f"Current tensor shape: {image_out_of_conv.shape} -> [batch, embedding_dim, feature_map_height, feature_map_width]")
Bueno, tenemos la parte 768 ( $(P^{2} \cdot C)$ ) pero aún necesitamos la cantidad de parches ($N$).
Volviendo a leer la sección 3.1 del documento de ViT, dice (negrita mía):
Como caso especial, los parches pueden tener un tamaño espacial $1 \times 1$, lo que significa que la secuencia de entrada se obtiene simplemente aplanando las dimensiones espaciales del mapa de características y proyectándolas a la dimensión del Transformador.
Aplanando las dimensiones espaciales del mapa de características, ¿eh?
¿Qué capa tenemos en PyTorch que se pueda aplanar?
¿Qué tal torch.nn.Flatten()?
Pero no queremos aplanar todo el tensor, sólo queremos aplanar las "dimensiones espaciales del mapa de características".
Que en nuestro caso son las dimensiones feature_map_height y feature_map_width de image_out_of_conv.
Entonces, ¿qué tal si creamos una capa torch.nn.Flatten() para aplanar solo esas dimensiones? ¿Podemos usar los parámetros start_dim y end_dim para configurar eso?
# Crear capa aplanada
flatten = nn.Flatten(start_dim=2, # flatten feature_map_height (dimension 2)
end_dim=3) # flatten feature_map_width (dimension 3)
¡Lindo! ¡Ahora juntemos todo!
Bien:
- Tome una sola imagen.
- Introdúzcalo a través de la capa convolucional (
conv2d) para convertir la imagen en mapas de características 2D (incrustaciones de parches). - Aplana el mapa de características 2D en una sola secuencia.
# 1. Ver una sola imagen
plt.imshow(image.permute(1, 2, 0)) # adjust for matplotlib
plt.title(class_names[label])
plt.axis(False);
print(f"Original image shape: {image.shape}")
# 2. Convierta la imagen en mapas de características
image_out_of_conv = conv2d(image.unsqueeze(0)) # add batch dimension to avoid shape errors
print(f"Image feature map shape: {image_out_of_conv.shape}")
# 3. Aplanar los mapas de características.
image_out_of_conv_flattened = flatten(image_out_of_conv)
print(f"Flattened image feature map shape: {image_out_of_conv_flattened.shape}")
¡Guau! Parece que nuestra forma image_out_of_conv_flattened está muy cerca de nuestra forma de salida deseada:
- Salida deseada (parches 2D aplanados): (196, 768) -> ${N \times\left(P^{2} \cdot C\right)}$
- Forma actual: (1, 768, 196)
La única diferencia es que nuestra forma actual tiene un tamaño de lote y las dimensiones están en un orden diferente al resultado deseado.
¿Cómo podríamos solucionar esto?
Bueno, ¿qué tal si reorganizamos las dimensiones?
Podemos hacerlo con torch.Tensor.permute() tal como lo hacemos cuando reorganizamos los tensores de imágenes para trazarlos con matplotlib.
Intentemos.
# Obtenga incrustaciones de parches de imágenes aplanadas en la forma correcta
image_out_of_conv_flattened_reshaped = image_out_of_conv_flattened.permute(0, 2, 1) # [batch_size, P^2•C, N] -> [batch_size, N, P^2•C]
print(f"Patch embedding sequence shape: {image_out_of_conv_flattened_reshaped.shape} -> [batch_size, num_patches, embedding_size]")
¡¡¡Sí!!!
Ahora hemos hecho coincidir las formas de entrada y salida deseadas para la capa de incrustación de parches de la arquitectura ViT usando un par de capas de PyTorch.
¿Qué tal si visualizamos uno de los mapas de características aplanados?
# Obtenga un único mapa de características aplanado
single_flattened_feature_map = image_out_of_conv_flattened_reshaped[:, :, 0] # index: (batch_size, number_of_patches, embedding_dimension)
# Trazar visualmente el mapa de características aplanado
plt.figure(figsize=(22, 22))
plt.imshow(single_flattened_feature_map.detach().numpy())
plt.title(f"Flattened feature map shape: {single_flattened_feature_map.shape}")
plt.axis(False);
Hmm, el mapa de características aplanado no parece gran cosa visualmente, pero eso no es lo que nos preocupa, esto es lo que será la salida de la capa de incrustación de parches y la entrada al resto de la arquitectura ViT.
Nota: La arquitectura Transformer original fue diseñada para funcionar con texto. La arquitectura Vision Transformer (ViT) tenía el objetivo de utilizar el Transformer original para imágenes. Es por eso que la entrada a la arquitectura ViT se procesa de la forma en que está. Básicamente, tomamos una imagen 2D y la formateamos para que aparezca como una secuencia de texto 1D.
¿Qué tal si vemos el mapa de características aplanado en forma tensorial?
# Vea el mapa de características aplanado como un tensor
single_flattened_feature_map, single_flattened_feature_map.requires_grad, single_flattened_feature_map.shape
¡Hermoso!
Hemos convertido nuestra única imagen 2D en un vector de incrustación 1D que se puede aprender (o "Proyección lineal de parches aplanados" en la Figura 1 del artículo de ViT).
4.5 Convertir la capa de incrustación del parche ViT en un módulo PyTorch¶
Es hora de poner todo lo que hemos hecho para crear el parche incrustado en una sola capa de PyTorch.
Podemos hacerlo subclasificando nn.Module y creando un pequeño "modelo" de PyTorch para realizar todos los pasos anteriores.
Específicamente:
- Cree una clase llamada
PatchEmbeddingque subclasenn.Module(para que pueda usarse como una capa de PyTorch). - Inicialice la clase con los parámetros
in_channels=3,patch_size=16(para ViT-Base) yembedding_dim=768(esto es $D$ para ViT-Base de la Tabla 1). - Cree una capa para convertir una imagen en parches usando
nn.Conv2d()(como en 4.3 anterior). - Cree una capa para aplanar los mapas de características del parche en una sola dimensión (como en 4.4 arriba).
- Defina un método
forward()para tomar una entrada y pasarla a través de las capas creadas en 3 y 4. - Asegúrese de que la forma de salida refleje la forma de salida requerida de la arquitectura ViT (${N \times\left(P^{2} \cdot C\right)}$).
¡Vamos a hacerlo!
# 1. Cree una clase que subclase nn.Module
class PatchEmbedding(nn.Module):
"""Turns a 2D input image into a 1D sequence learnable embedding vector.
Args:
in_channels (int): Number of color channels for the input images. Defaults to 3.
patch_size (int): Size of patches to convert input image into. Defaults to 16.
embedding_dim (int): Size of embedding to turn image into. Defaults to 768.
"""
# 2. Initialize the class with appropriate variables
def __init__(self,
in_channels:int=3,
patch_size:int=16,
embedding_dim:int=768):
super().__init__()
# 3. Create a layer to turn an image into patches
self.patcher = nn.Conv2d(in_channels=in_channels,
out_channels=embedding_dim,
kernel_size=patch_size,
stride=patch_size,
padding=0)
# 4. Create a layer to flatten the patch feature maps into a single dimension
self.flatten = nn.Flatten(start_dim=2, # only flatten the feature map dimensions into a single vector
end_dim=3)
# 5. Define the forward method
def forward(self, x):
# Create assertion to check that inputs are the correct shape
image_resolution = x.shape[-1]
assert image_resolution % patch_size == 0, f"Input image size must be divisble by patch size, image shape: {image_resolution}, patch size: {patch_size}"
# Perform the forward pass
x_patched = self.patcher(x)
x_flattened = self.flatten(x_patched)
# 6. Make sure the output shape has the right order
return x_flattened.permute(0, 2, 1) # adjust so the embedding is on the final dimension [batch_size, P^2•C, N] -> [batch_size, N, P^2•C]
¡Capa PatchEmbedding creada!
Probémoslo en una sola imagen.
set_seeds()
# Crear una instancia de capa de incrustación de parches
patchify = PatchEmbedding(in_channels=3,
patch_size=16,
embedding_dim=768)
# Pasar una sola imagen a través
print(f"Input image shape: {image.unsqueeze(0).shape}")
patch_embedded_image = patchify(image.unsqueeze(0)) # add an extra batch dimension on the 0th index, otherwise will error
print(f"Output patch embedding shape: {patch_embedded_image.shape}")
¡Hermoso!
La forma de salida coincide con las formas de entrada y salida ideales que nos gustaría ver en la capa de incrustación del parche:
- Entrada: La imagen comienza como 2D con tamaño ${H \times W \times C}$.
- Salida: La imagen se convierte en una secuencia 1D de parches 2D aplanados con tamaño ${N \times\left(P^{2} \cdot C\right)}$.
Dónde:
- $(H, W)$ es la resolución de la imagen original.
- $C$ es el número de canales.
- $(P, P)$ es la resolución de cada parche de imagen (tamaño del parche).
- $N=H W / P^{2}$ es el número resultante de parches, que también sirve como longitud efectiva de la secuencia de entrada para el Transformer.
Ahora hemos replicado la incorporación del parche para la ecuación 1, pero no la incorporación del token de clase/posición.
Llegaremos a esto más adelante.
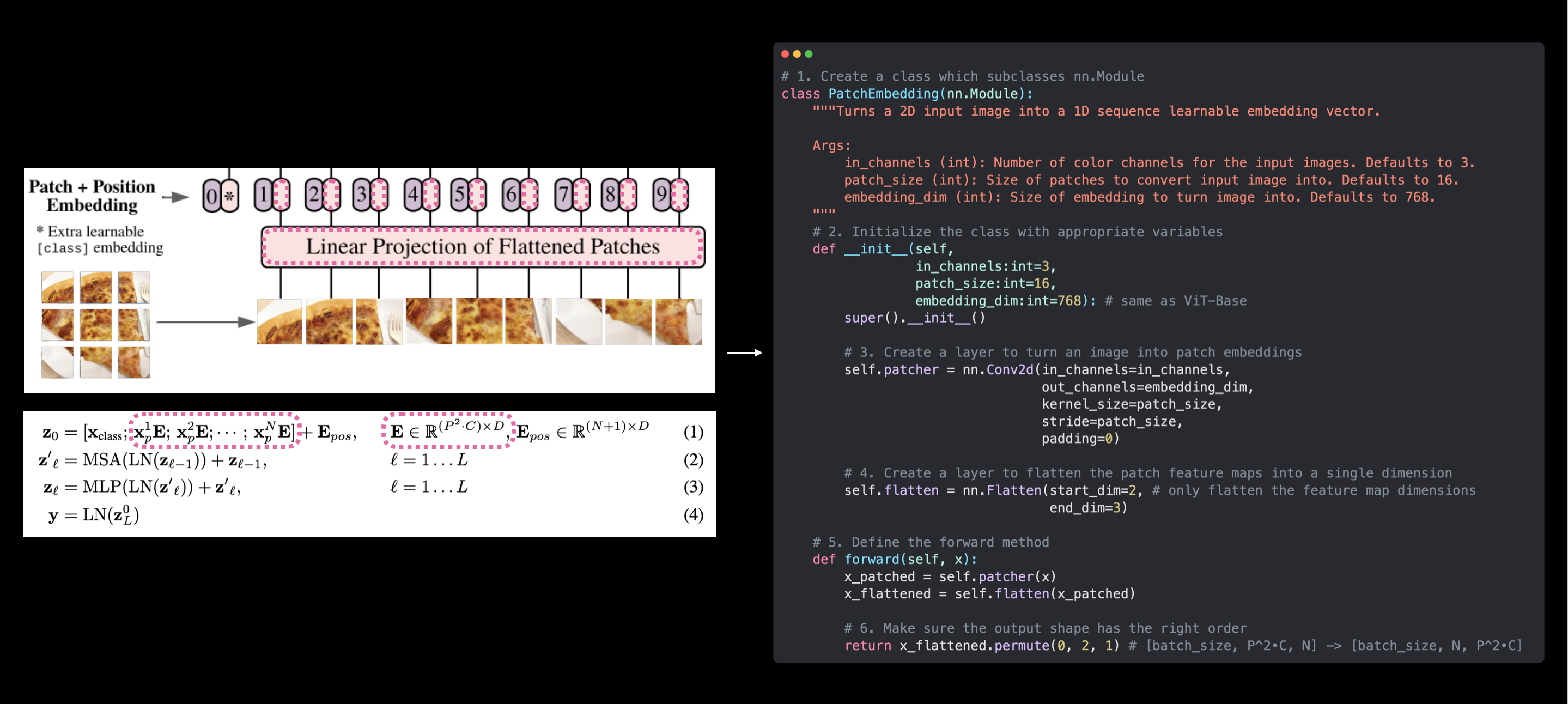
Nuestra clase PatchEmbedding (derecha) replica la incorporación de parches de la arquitectura ViT de la Figura 1 y la Ecuación 1 del artículo de ViT (izquierda). Sin embargo, las incrustaciones de clases y posiciones que se pueden aprender aún no se han creado. Estos llegarán pronto.
Ahora obtengamos un resumen de nuestra capa PatchEmbedding.
# Crear tamaños de entrada aleatorios
random_input_image = (1, 3, 224, 224)
random_input_image_error = (1, 3, 250, 250) # will error because image size is incompatible with patch_size
# # Obtener un resumen de las entradas y salidas de PatchEmbedding (descomentar para obtener el resultado completo)
# resumen(PatchEmbedding(),
# input_size=random_input_image, # intenta cambiar esto por "random_input_image_error"
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"])

4.6 Creando la incrustación del token de clase¶
Bien, ya hemos incorporado el parche de imagen. Es hora de empezar a trabajar en la incorporación del token de clase.
O $\mathbf{x}_\text {class }$ de la ecuación 1.
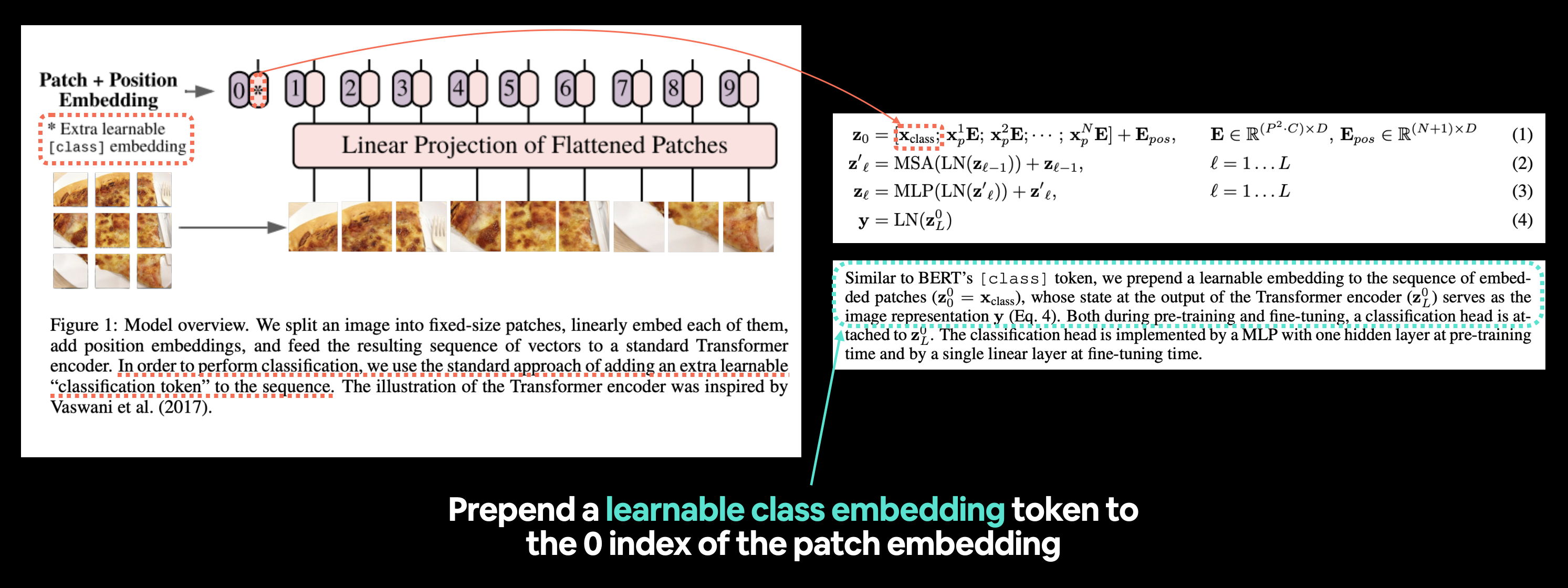
Izquierda: Figura 1 del artículo de ViT con el "token de clasificación" o token de incrustación [clase] que vamos a recrear resaltado. Derecha: Ecuación 1 y sección 3.1 del documento de ViT que se relacionan con el token de incorporación de clase que se puede aprender.
Al leer el segundo párrafo de la sección 3.1 del artículo de ViT, vemos la siguiente descripción:
De manera similar al token
[ class ]de BERT, anteponemos una incrustación que se puede aprender a la secuencia de parches incrustados $\left(\mathbf{z}_{0}^{0}=\mathbf{x}_{\text { clase }}\right)$, cuyo estado en la salida del codificador Transformer $\left(\mathbf{z}_{L}^{0}\right)$ sirve como representación de la imagen $\mathbf{y}$ (Ecuación 4).
Nota: BERT (Representaciones de codificador bidireccional de Transformers) es uno de los artículos de investigación originales sobre aprendizaje automático que utiliza la arquitectura Transformer para lograr resultados sobresalientes en entornos naturales. tareas de procesamiento del lenguaje (PNL) y es donde se originó la idea de tener un token
[clase]al comienzo de una secuencia, siendo clase una descripción de la clase de "clasificación" a la que pertenecía la secuencia.
Por lo tanto, necesitamos "preparar una incrustación que se pueda aprender en la secuencia de parches incrustados".
Comencemos viendo nuestra secuencia de tensor de parches incrustados (creado en la sección 4.5) y su forma.
# Ver la incrustación del parche y la forma de la incrustación del parche
print(patch_embedded_image)
print(f"Patch embedding shape: {patch_embedded_image.shape} -> [batch_size, number_of_patches, embedding_dimension]")
Para "anteponer una incrustación que se puede aprender a la secuencia de parches incrustados", necesitamos crear una incrustación que se puede aprender en la forma de embedding_dimension ($D$) y luego agregarla a la dimensión number_of_patches.
O en pseudocódigo:
pitón
patch_embedding = [image_patch_1, image_patch_2, image_patch_3...]
class_token = incrustación_aprendible
patch_embedding_with_class_token = torch.cat((class_token, patch_embedding), dim=1)
Observe que la concatenación (torch.cat()) ocurre en dim=1 (la dimensión number_of_patches).
Creemos una incrustación que se pueda aprender para el token de clase.
Para hacerlo, obtendremos el tamaño del lote y la forma de la dimensión de incrustación y luego crearemos un tensor torch.ones() con la forma [batch_size, 1, embedding_dimension].
Y haremos que el tensor se pueda aprender pasándolo a nn.Parameter() con requires_grad=True.
# Obtenga el tamaño del lote y la dimensión de incrustación
batch_size = patch_embedded_image.shape[0]
embedding_dimension = patch_embedded_image.shape[-1]
# Cree la incrustación del token de clase como un parámetro que se puede aprender y que comparte el mismo tamaño que la dimensión de incrustación (D)
class_token = nn.Parameter(torch.ones(batch_size, 1, embedding_dimension), # [batch_size, number_of_tokens, embedding_dimension]
requires_grad=True) # make sure the embedding is learnable
# Muestra los primeros 10 ejemplos de class_token
print(class_token[:, :, :10])
# Imprime la forma class_token
print(f"Class token shape: {class_token.shape} -> [batch_size, number_of_tokens, embedding_dimension]")
Nota: Aquí solo estamos creando el token de clase incrustado como
torch.ones()para demostración propósitos, en realidad, probablemente crearías el token de clase incrustado contorch.randn()(ya que el aprendizaje automático es todo se trata de aprovechar el poder de la aleatoriedad controlada, generalmente se comienza con un número aleatorio y se mejora con el tiempo).
Vea cómo la dimensión number_of_tokens de class_token es 1 ya que solo queremos anteponer un valor de token de clase al inicio de la secuencia de incorporación del parche.
Ahora que tenemos el token de clase incrustado, antepongamoslo a nuestra secuencia de parches de imágenes, patch_embedded_image.
Podemos hacerlo usando torch.cat() y establecer dim=1 (por lo que class_token' La dimensión number_of_tokensestá preadaptada a la dimensiónnumber_of_patchesdepatch_embedded_image`).
# Agregue la incrustación del token de clase al frente de la incrustación del parche
patch_embedded_image_with_class_embedding = torch.cat((class_token, patch_embedded_image),
dim=1) # concat on first dimension
# Imprima la secuencia de incrustaciones de parches con la incrustación de token de clase antepuesta
print(patch_embedded_image_with_class_embedding)
print(f"Sequence of patch embeddings with class token prepended shape: {patch_embedded_image_with_class_embedding.shape} -> [batch_size, number_of_patches, embedding_dimension]")
¡Lindo! ¡Token de clase aprendible antepuesto!

Al revisar lo que hemos hecho para crear el token de clase que se puede aprender, comenzamos con una secuencia de incrustaciones de parches de imágenes creadas por PatchEmbedding() en una sola imagen, luego creamos un token de clase que se puede aprender con un valor para cada una de las dimensiones de incrustación. y luego lo antepuso a la secuencia original de incrustaciones de parches. Nota: El uso de torch.ones() para crear el token de clase que se puede aprender es principalmente solo para fines de demostración; en la práctica, probablemente lo crearías con torch.randn().
4.7 Creando la incrustación de posición¶
Bueno, tenemos la incrustación del token de clase y la incrustación del parche. Ahora, ¿cómo podríamos crear la incrustación de posición?
O $\mathbf{E}_{\text {pos }}$ de la ecuación 1 donde $E$ significa "incrustación".
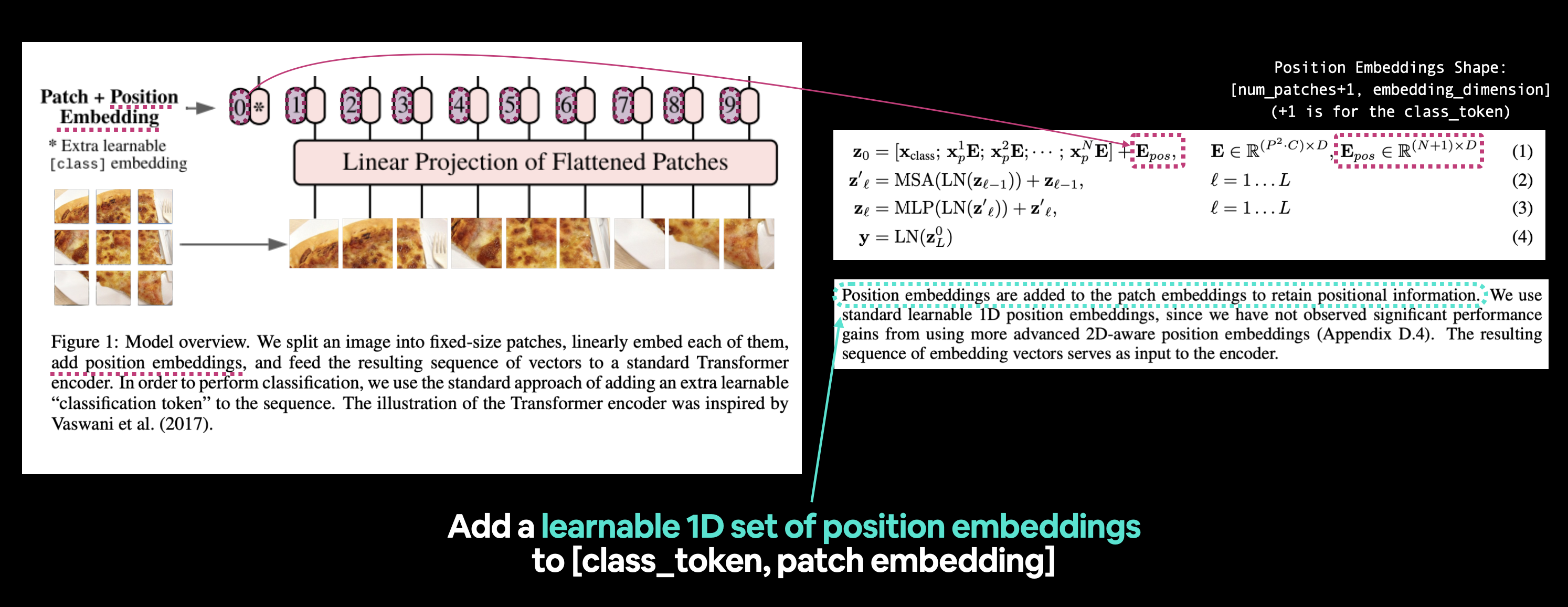
Izquierda: Figura 1 del artículo de ViT con la posición incrustada que vamos a recrear resaltada. Derecha: Ecuación 1 y sección 3.1 del artículo de ViT que se relacionan con la incrustación de posiciones.
Averigüemos más leyendo la sección 3.1 del artículo de ViT (negrita mía):
Las incrustaciones de posición se agregan a las incrustaciones de parches para retener la información posicional. Usamos incrustaciones de posición 1D estándar que se pueden aprender, ya que no hemos observado mejoras significativas en el rendimiento al utilizar incrustaciones de posición 2D más avanzadas (Apéndice D.4). La secuencia resultante de vectores de incrustación sirve como entrada para el codificador.
Con "retener información posicional" los autores quieren decir que quieren que la arquitectura sepa en qué "orden" vienen los parches. Es decir, el parche dos viene después del parche uno y el parche tres viene después del parche dos y así sucesivamente.
Esta información posicional puede ser importante al considerar lo que hay en una imagen (sin información posicional, se podría considerar que una secuencia aplanada no tiene orden y, por lo tanto, ningún parche se relaciona con ningún otro parche).
Para comenzar a crear las incrustaciones de posiciones, veamos nuestras incrustaciones actuales.
# Ver la secuencia de incrustaciones de parches con la incrustación de clases antepuesta
patch_embedded_image_with_class_embedding, patch_embedded_image_with_class_embedding.shape
La ecuación 1 establece que las incrustaciones de posición ($\mathbf{E}_{\text {pos }}$) deben tener la forma $(N + 1) \times D$:
$$\mathbf{E}_{\text {pos }} \in \mathbb{R}^{(N+1) \times D}$$
Dónde:
- $N=H W / P^{2}$ es el número resultante de parches, que también sirve como longitud efectiva de la secuencia de entrada para el Transformer (número de parches).
- $D$ es el tamaño de las incrustaciones de parches; se pueden encontrar diferentes valores para $D$ en la Tabla 1 (dimensión de incrustación).
Afortunadamente, ya tenemos ambos valores.
Entonces, hagamos una incrustación 1D que se pueda aprender con torch.ones() para crear $\mathbf{E}_{\text {pos }}$.
# Calcular N (número de parches)
number_of_patches = int((height * width) / patch_size**2)
# Obtener dimensión de incrustación
embedding_dimension = patch_embedded_image_with_class_embedding.shape[2]
# Cree la incrustación de posición 1D que se puede aprender
position_embedding = nn.Parameter(torch.ones(1,
number_of_patches+1,
embedding_dimension),
requires_grad=True) # make sure it's learnable
# Muestre las primeras 10 secuencias y los 10 valores de incrustación de posición y verifique la forma de la incrustación de posición
print(position_embedding[:, :10, :10])
print(f"Position embeddding shape: {position_embedding.shape} -> [batch_size, number_of_patches, embedding_dimension]")
Nota: Al crear la posición incrustada como
torch.ones()solo para fines de demostración, en realidad, probablemente crearías la posición incrustada contorch.randn()(comience con un número aleatorio y mejorar mediante descenso de gradiente).
¡Incrustaciones de posición creadas!
Agreguémoslos a nuestra secuencia de incrustaciones de parches con un token de clase antepuesto.
# Agregue la incrustación de posición a la incrustación de parche y token de clase
patch_and_position_embedding = patch_embedded_image_with_class_embedding + position_embedding
print(patch_and_position_embedding)
print(f"Patch embeddings, class token prepended and positional embeddings added shape: {patch_and_position_embedding.shape} -> [batch_size, number_of_patches, embedding_dimension]")
Observe cómo los valores de cada uno de los elementos en el tensor de incrustación aumentan en 1 (esto se debe a que las incrustaciones de posición se crean con torch.ones()).
Nota: Podríamos colocar tanto la incrustación del token de clase como la incrustación de posición en su propia capa si quisiéramos. Pero veremos más adelante en la sección 8 cómo se pueden incorporar al método
forward()de la arquitectura ViT general.

El flujo de trabajo que hemos utilizado para agregar las incorporaciones de posición a la secuencia de incorporaciones de parches y tokens de clase. Nota: torch.ones() solo se usa para crear incrustaciones con fines ilustrativos; en la práctica, probablemente usarías torch.randn() para comenzar con un número aleatorio.
4.8 Poniéndolo todo junto: de la imagen a la incrustación¶
Muy bien, hemos recorrido un largo camino en términos de convertir nuestras imágenes de entrada en una ecuación 1 de incrustación y replicación de la sección 3.1 del artículo de ViT:
$$ \begin{alineado} \mathbf{z}_{0} &=\left[\mathbf{x}_{\text {clase }} ; \mathbf{x}_{p}^{1} \mathbf{E} ; \mathbf{x}_{p}^{2} \mathbf{E} ; \cdots ; \mathbf{x}_{p}^{N} \mathbf{E}\right]+\mathbf{E}_{\text {pos }}, & & \mathbf{E} \in \mathbb{R} ^{\left(P^{2} \cdot C\right) \times D}, \mathbf{E}_{\text {pos }} \in \mathbb{R}^{(N+1) \times D} \end{alineado} $$
Ahora juntemos todo en una sola celda de código y pasemos de la imagen de entrada ($\mathbf{x}$) a la incrustación de salida ($\mathbf{z}_0$).
Podemos hacerlo mediante:
- Establecer el tamaño del parche (usaremos
16ya que se usa ampliamente en todo el documento y para ViT-Base). - Obtener una sola imagen, imprimir su forma y almacenar su alto y ancho.
- Agregar una dimensión por lotes a la imagen única para que sea compatible con nuestra capa
PatchEmbedding. - Crear una capa
PatchEmbedding(la que hicimos en la sección 4.5) conpatch_size=16yembedding_dim=768(de la Tabla 1 para ViT-Base). - Pasar la imagen única a través de la capa
PatchEmbeddingen 4 para crear una secuencia de incrustaciones de parches. - Crear una incrustación de token de clase como en la sección 4.6.
- Anteponer la incorporación del token de clase a las incorporaciones de parches creadas en el paso 5.
- Creando una posición incrustada como en la sección 4.7.
- Agregar la incrustación de posición al token de clase y las incrustaciones de parches creadas en el paso 7.
También nos aseguraremos de configurar las semillas aleatorias con set_seeds() e imprimiremos las formas de diferentes tensores a lo largo del camino.
set_seeds()
# 1. Establecer el tamaño del parche
patch_size = 16
# 2. Imprima la forma del tensor de imagen original y obtenga las dimensiones de la imagen.
print(f"Image tensor shape: {image.shape}")
height, width = image.shape[1], image.shape[2]
# 3. Obtenga el tensor de imagen y agregue la dimensión del lote
x = image.unsqueeze(0)
print(f"Input image with batch dimension shape: {x.shape}")
# 4. Crear una capa de incrustación de parches
patch_embedding_layer = PatchEmbedding(in_channels=3,
patch_size=patch_size,
embedding_dim=768)
# 5. Pase la imagen a través de la capa de incrustación del parche.
patch_embedding = patch_embedding_layer(x)
print(f"Patching embedding shape: {patch_embedding.shape}")
# 6. Cree una incrustación de token de clase
batch_size = patch_embedding.shape[0]
embedding_dimension = patch_embedding.shape[-1]
class_token = nn.Parameter(torch.ones(batch_size, 1, embedding_dimension),
requires_grad=True) # make sure it's learnable
print(f"Class token embedding shape: {class_token.shape}")
# 7. Anteponer la incrustación de token de clase a la incrustación de parches
patch_embedding_class_token = torch.cat((class_token, patch_embedding), dim=1)
print(f"Patch embedding with class token shape: {patch_embedding_class_token.shape}")
# 8. Crear posición incrustada
number_of_patches = int((height * width) / patch_size**2)
position_embedding = nn.Parameter(torch.ones(1, number_of_patches+1, embedding_dimension),
requires_grad=True) # make sure it's learnable
# 9. Agregue incrustación de posición a la incrustación de parches con token de clase
patch_and_position_embedding = patch_embedding_class_token + position_embedding
print(f"Patch and position embedding shape: {patch_and_position_embedding.shape}")
¡Guau!
Desde una sola imagen hasta parchear y posicionar incrustaciones en una sola celda de código.
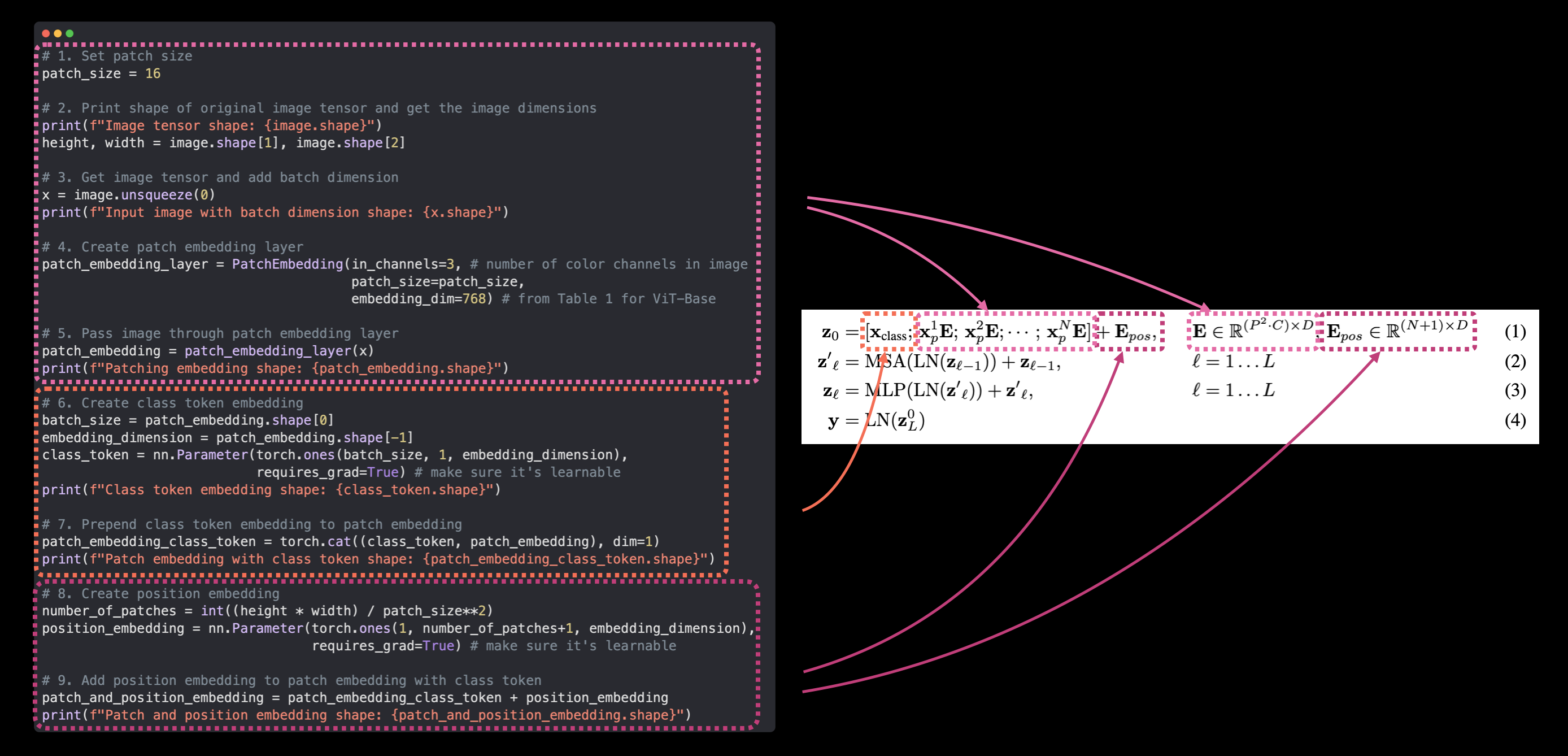
Asignación de la ecuación 1 del artículo de ViT a nuestro código PyTorch. Esta es la esencia de la replicación en papel: tomar un trabajo de investigación y convertirlo en código utilizable.
Ahora tenemos una manera de codificar nuestras imágenes y pasarlas al codificador Transformer en la Figura 1 del artículo de ViT.
<img src="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/images/08-vit-paper-architecture-animation-full-architecture.gif" alt="Animación de la arquitectura del transformador de visión , partiendo de una sola imagen y pasándola a través de una capa de incrustación de parches y luego pasándola a través del codificador del transformador". ancho=900/>
{kind=link}
Animando todo el flujo de trabajo de ViT: desde la incorporación de parches hasta el codificador transformador y el cabezal MLP.
Desde una perspectiva de código, la creación de la incrustación del parche es probablemente la sección más grande de la replicación del documento ViT.
Muchas de las otras partes del documento ViT, como las capas Multi-Head Attention y Norm, se pueden crear utilizando capas de PyTorch existentes.
¡Adelante!
5. Ecuación 2: Atención de múltiples cabezas (MSA)¶
Tenemos nuestros datos de entrada parcheados e integrados, ahora pasemos a la siguiente parte de la arquitectura ViT.
Para comenzar, dividiremos la sección Transformer Encoder en dos partes (comenzaremos poco a poco y aumentaremos cuando sea necesario).
La primera es la ecuación 2 y la segunda la ecuación 3.
Recuerde que la ecuación 2 dice:
$$ \begin{alineado} \mathbf{z}_{\ell}^{\prime} &=\operatorname{MSA}\left(\operatorname{LN}\left(\mathbf{z}_{\ell-1}\right)\right )+\mathbf{z}_{\ell-1}, & & \ell=1 \ldots L \end{alineado} $$
Esto indica una capa de Atención de múltiples cabezales (MSA) envuelta en una capa LayerNorm (LN) con una conexión residual (la entrada a la capa se agrega a la salida de la capa).
Nos referiremos a la ecuación 2 como "bloque MSA".
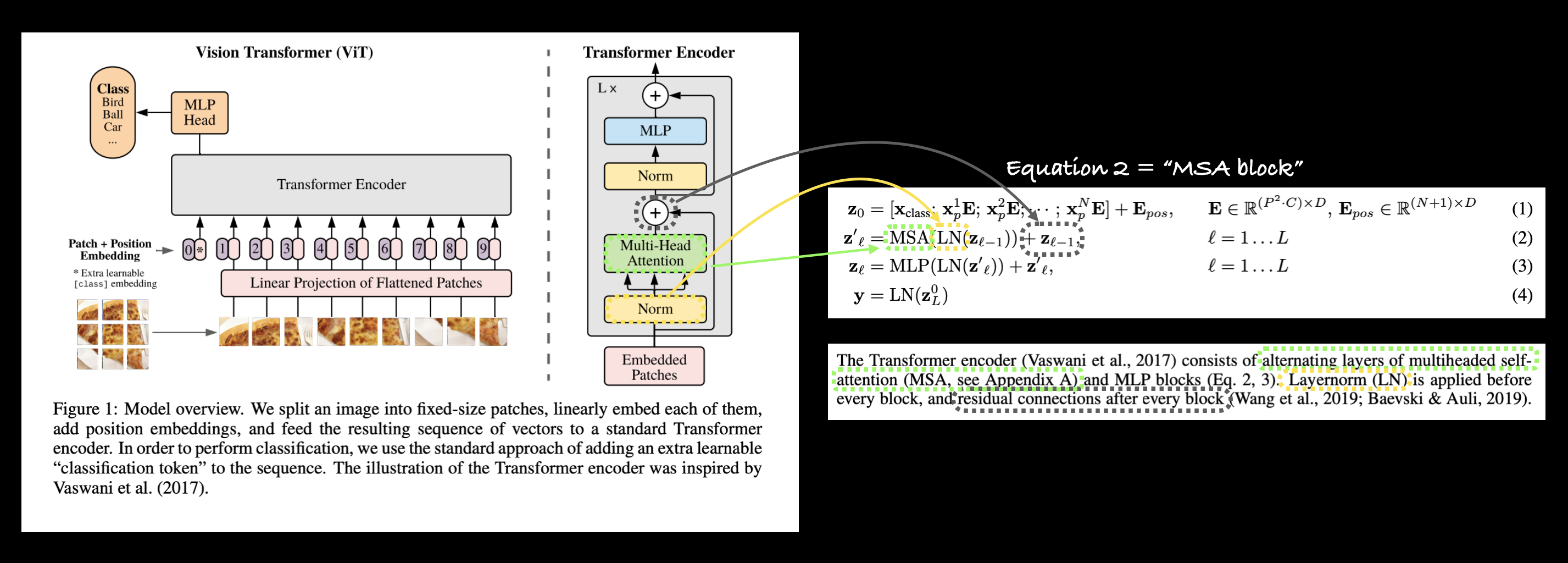
***Izquierda:** Figura 1 del artículo de ViT con las capas Multi-Head Attention y Norm, así como la conexión residual (+) resaltada dentro del bloque Transformer Encoder. Derecha: Mapeo de la capa Multi-Head Self Attention (MSA), la capa Norm y la conexión residual a sus respectivas partes de la ecuación 2 en el documento ViT.*
Muchas capas que se encuentran en los artículos de investigación ya están implementadas en marcos modernos de aprendizaje profundo como PyTorch.
Dicho esto, para replicar estas capas y conexión residual con el código PyTorch podemos usar:
- Autoatención de múltiples cabezales (MSA) -
torch.nn.MultiheadAttention(). - Norma (LN o LayerNorm) -
torch.nn.LayerNorm(). - Conexión residual: agregue la entrada a la salida (veremos esto más adelante cuando creemos el bloque Transformer Encoder completo en la sección 7.1).
5.1 La capa LayerNorm (LN)¶
Normalización de capas (torch.nn.LayerNorm() o Norm o LayerNorm o LN) normaliza una entrada en la última dimensión.
Puede encontrar la definición formal de torch.nn.LayerNorm() en la documentación de PyTorch.
El parámetro principal de torch.nn.LayerNorm() de PyTorch es normalized_shape, que podemos configurar para que sea igual al tamaño de dimensión sobre el que nos gustaría normalizar (en nuestro caso será $D$ o 768 para ViT-Base).
¿Qué hace?
La normalización de capas ayuda a mejorar el tiempo de entrenamiento y la generalización del modelo (capacidad de adaptarse a datos invisibles).
Me gusta pensar en cualquier tipo de normalización como "obtener los datos en un formato similar" o "obtener muestras de datos en una distribución similar".
Imagínese intentar subir (o bajar) un conjunto de escaleras, todas con diferentes alturas y longitudes.
Se necesitarían algunos ajustes en cada paso, ¿verdad?
Y lo que aprendes en cada paso no necesariamente ayudará con el siguiente, ya que todos son diferentes, lo que aumenta el tiempo que te lleva subir las escaleras.
La normalización (incluida la normalización de capas) es el equivalente a hacer que todas las escaleras tengan la misma altura y longitud, excepto que las escaleras son sus muestras de datos.
Entonces, así como puedes subir (o bajar) escaleras con alturas y longitudes similares mucho más fácilmente que aquellas con alturas y anchos diferentes, las redes neuronales pueden optimizar muestras de datos con distribuciones similares (medias y desviaciones estándar similares) más fácilmente que aquellas con diferentes alturas y longitudes. distribuciones.
5.2 La capa de atención automática de múltiples cabezales (MSA)¶
El poder de la autoatención y la atención de múltiples cabezas (autoatención aplicada varias veces) se reveló en la forma de la arquitectura Transformer original introducida en [La atención es todo lo que necesitas](https://arxiv.org /abs/1706.03762) artículo de investigación.
Diseñado originalmente para la entrada de texto, el mecanismo de autoatención original toma una secuencia de palabras y luego calcula qué palabra debe prestar más "atención" a otra palabra.
En otras palabras, en la frase "el perro saltó la valla", quizás la palabra "perro" se relacione fuertemente con "saltó" y "valla".
Esto se simplifica pero la premisa sigue siendo las imágenes.
Dado que nuestra entrada es una secuencia de parches de imágenes en lugar de palabras, la autoatención y, a su vez, la atención de múltiples cabezas calcularán qué parche de una imagen está más relacionado con otro parche, formando eventualmente una representación aprendida de una imagen.
Pero lo más importante es que la capa hace esto por sí sola teniendo en cuenta los datos (no le decimos qué patrones aprender).
Y si la representación aprendida que forman las capas usando MSA es buena, veremos los resultados en el rendimiento de nuestro modelo.
Hay muchos recursos en línea para aprender más sobre la arquitectura de Transformer y el mecanismo de atención en línea, como la maravillosa [publicación ilustrada de Transformer] de Jay Alammar (https://jalammar.github.io/illustrated-transformer/) y la [publicación ilustrada de atención] (https ://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/).
Nos centraremos más en codificar una implementación de PyTorch MSA existente que en crear la nuestra propia.
Sin embargo, puede encontrar la definición formal de la implementación de MSA del documento ViT en el Apéndice A:
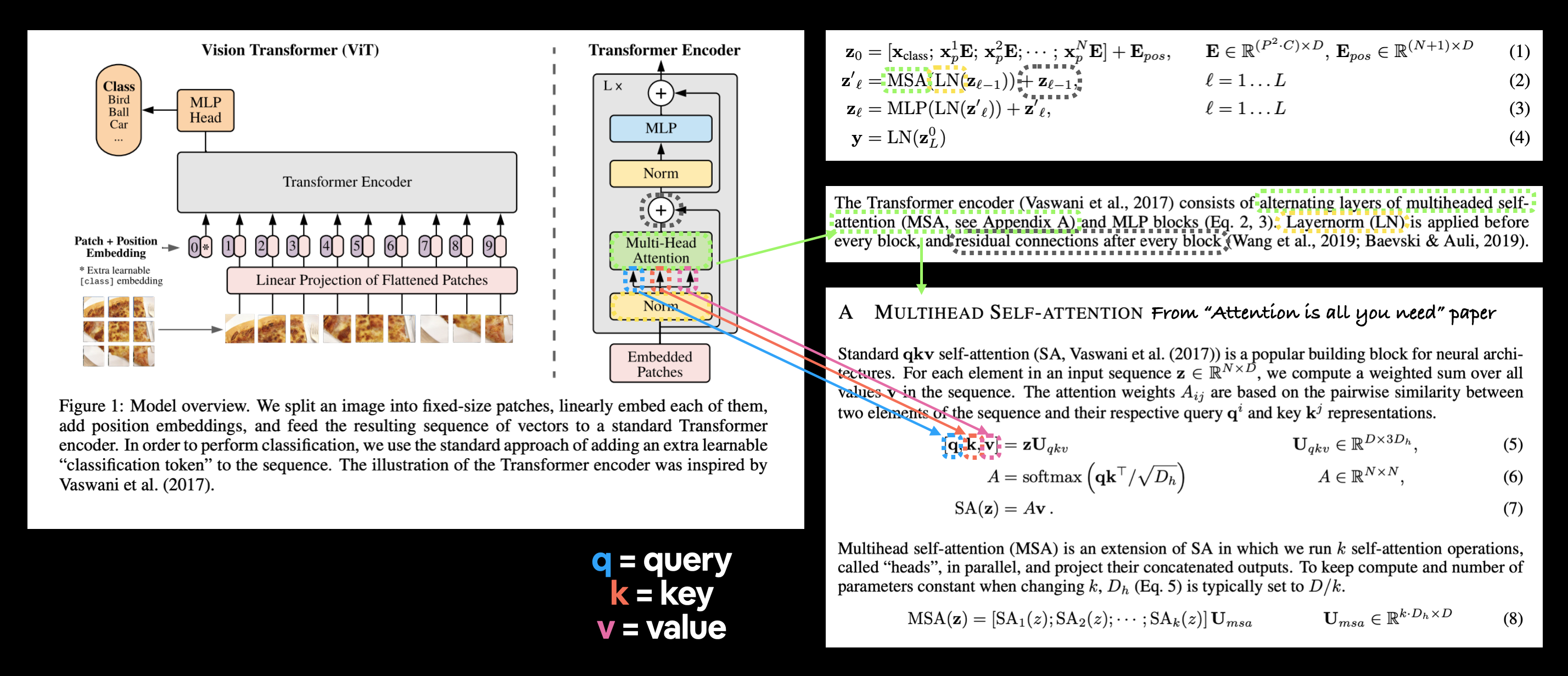
***Izquierda:** Descripción general de la arquitectura de Vision Transformer de la Figura 1 del documento de ViT. Derecha: Las definiciones de la ecuación 2, la sección 3.1 y el Apéndice A del documento de ViT resaltadas para reflejar sus respectivas partes en la Figura 1.*
La imagen de arriba resalta la triple entrada de incrustación en la capa MSA.
Esto se conoce como entrada de consulta, clave, valor o qkv para abreviar, que es fundamental para el mecanismo de autoatención.
En nuestro caso, la entrada de triple incrustación serán tres versiones de la salida de la capa Norma, una para consulta, clave y valor.
O tres versiones de nuestro parche de imagen normalizado por capas y de incrustaciones de posición creadas en la sección 4.8.
Podemos implementar la capa MSA en PyTorch con torch.nn.MultiheadAttention() con los parámetros:
embed_dim: la dimensión de incrustación de la Tabla 1 (tamaño oculto $D$).num_heads- cuántas cabezas de atención usar (de aquí proviene el término "multiheads"), este valor también se encuentra en la Tabla 1 (Cabezas).dropout: si se aplica o no el abandono a la capa de atención (según el Apéndice B.1, el abandono no se utiliza después de las proyecciones qkv).batch_first: ¿nuestra dimensión del lote es lo primero? (sí lo hace)
5.3 Replicando la Ecuación 2 con capas de PyTorch¶
Pongamos en práctica todo lo que hemos discutido sobre las capas LayerNorm (LN) y Multi-Head Attention (MSA) en la ecuación 2.
Para hacerlo, haremos:
- Cree una clase llamada
MultiheadSelfAttentionBlockque herede detorch.nn.Module. - Inicialice la clase con hiperparámetros de la Tabla 1 del artículo de ViT para el modelo ViT-Base.
- Cree una capa de normalización de capa (LN) con
torch.nn.LayerNorm()con el parámetronormalized_shapeigual que nuestra dimensión de incrustación ($D$ de la Tabla 1). - Cree una capa de atención de múltiples cabezas (MSA) con los parámetros apropiados
embed_dim,num_heads,dropoutybatch_first. - Cree un método
forward()para nuestra clase pasando las entradas a través de la capa LN y la capa MSA.
# 1. Crea una clase que hereda de nn.Module
class MultiheadSelfAttentionBlock(nn.Module):
"""Creates a multi-head self-attention block ("MSA block" for short).
"""
# 2. Initialize the class with hyperparameters from Table 1
def __init__(self,
embedding_dim:int=768, # Hidden size D from Table 1 for ViT-Base
num_heads:int=12, # Heads from Table 1 for ViT-Base
attn_dropout:float=0): # doesn't look like the paper uses any dropout in MSABlocks
super().__init__()
# 3. Create the Norm layer (LN)
self.layer_norm = nn.LayerNorm(normalized_shape=embedding_dim)
# 4. Create the Multi-Head Attention (MSA) layer
self.multihead_attn = nn.MultiheadAttention(embed_dim=embedding_dim,
num_heads=num_heads,
dropout=attn_dropout,
batch_first=True) # does our batch dimension come first?
# 5. Create a forward() method to pass the data throguh the layers
def forward(self, x):
x = self.layer_norm(x)
attn_output, _ = self.multihead_attn(query=x, # query embeddings
key=x, # key embeddings
value=x, # value embeddings
need_weights=False) # do we need the weights or just the layer outputs?
return attn_output
Nota: A diferencia de la Figura 1, nuestro
MultiheadSelfAttentionBlockno incluye una conexión de omisión o residual ("$+\mathbf{z}_{\ell-1}$" en la ecuación 2), Incluya esto cuando creemos el codificador de transformador completo más adelante en la sección 7.1.
¡MSABlock creado!
Probémoslo creando una instancia de nuestro MultiheadSelfAttentionBlock y pasando por la variable patch_and_position_embedding que creamos en la sección 4.8.
# Crear una instancia de MSABlock
multihead_self_attention_block = MultiheadSelfAttentionBlock(embedding_dim=768, # from Table 1
num_heads=12) # from Table 1
# Pase el parche y coloque la imagen incrustada a través de MSABlock
patched_image_through_msa_block = multihead_self_attention_block(patch_and_position_embedding)
print(f"Input shape of MSA block: {patch_and_position_embedding.shape}")
print(f"Output shape MSA block: {patched_image_through_msa_block.shape}")
Observe cómo la forma de entrada y salida de nuestros datos permanece igual cuando pasan por el bloque MSA.
Esto no significa que los datos no cambien a medida que avanzan.
Puede intentar imprimir el tensor de entrada y salida para ver cómo cambia (aunque este cambio se producirá en valores 1 * 197 * 768 y podría ser difícil de visualizar).
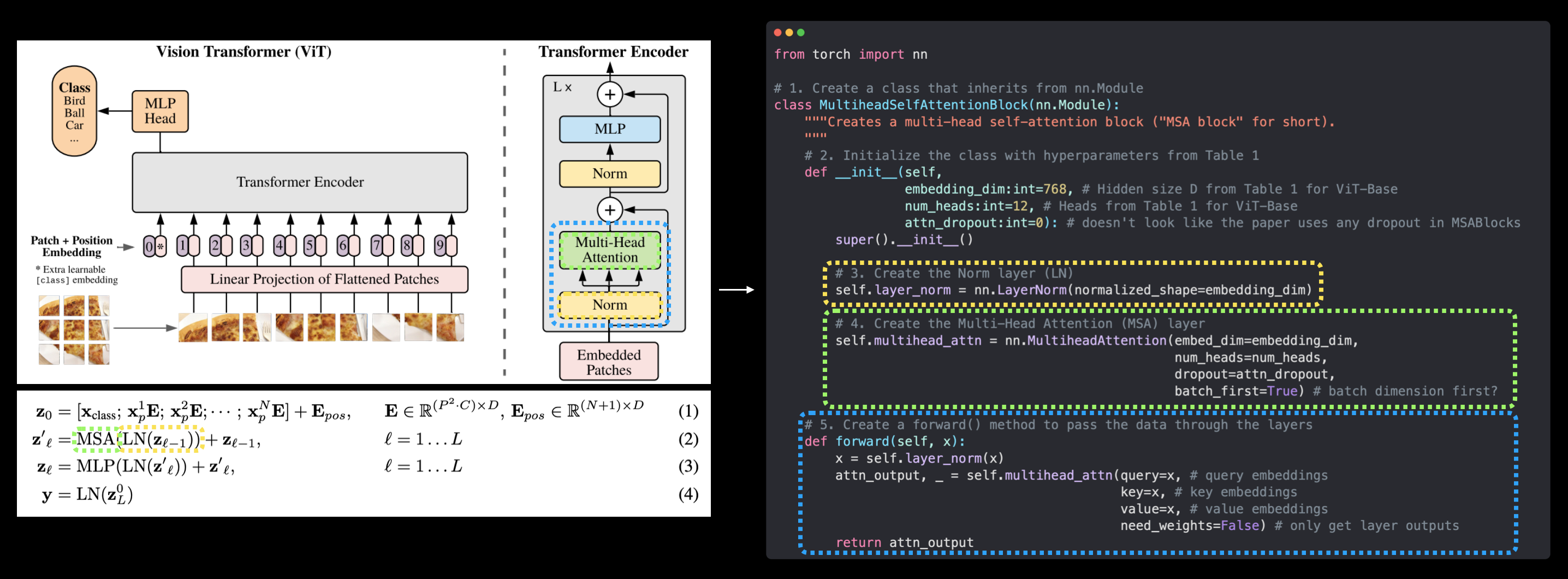
***Izquierda:** Arquitectura Vision Transformer de la Figura 1 con las capas Multi-Head Attention y LayerNorm resaltadas; estas capas constituyen la ecuación 2 de la sección 3.1 del documento. Derecha: Replicando la ecuación 2 (sin la conexión de salto al final) usando capas de PyTorch.*
¡Ahora hemos replicado oficialmente la ecuación 2 (excepto por la conexión residual al final, pero llegaremos a esto en la sección 7.1)!
¡A la siguiente!
6. Ecuación 3: Perceptrón multicapa (MLP)¶
¡Estamos en racha aquí!
Sigamos así y repliquemos la ecuación 3:
$$ \begin{alineado} \mathbf{z}_{\ell} &=\operatorname{MLP}\left(\operatorname{LN}\left(\mathbf{z}_{\ell}^{\prime}\right)\right)+ \mathbf{z}_{\ell}^{\prime}, & & \ell=1 \ldots L \end{alineado} $$
Aquí MLP significa "perceptrón multicapa" y LN significa "normalización de capa" (como se discutió anteriormente).
Y la adición al final es la conexión de salto/residual.
Nos referiremos a la ecuación 3 como el "bloque MLP" del codificador Transformer (observe cómo continuamos con la tendencia de dividir la arquitectura en partes más pequeñas).

***Izquierda:** Figura 1 del artículo de ViT con las capas MLP y Norm, así como la conexión residual (+) resaltada dentro del bloque Transformer Encoder. Derecha: Mapeo de la capa de perceptrón multicapa (MLP), la capa de norma (LN) y la conexión residual con sus respectivas partes de la ecuación 3 en el artículo de ViT.*
6.1 Las capas MLP¶
El término MLP es bastante amplio ya que puede referirse a casi cualquier combinación de múltiples capas (de ahí el "multi" en perceptrón multicapa).
Pero generalmente sigue el patrón de:
capa lineal -> capa no lineal -> capa lineal -> capa no lineal
En el caso del artículo de ViT, la estructura de MLP se define en la sección 3.1:
El MLP contiene dos capas con una no linealidad GELU.
Donde "dos capas" se refiere a capas lineales (torch.nn.Linear() en PyTorch) y "GELU no linealidad" es la función de activación no lineal GELU (Unidades lineales de error gaussiano) ([torch.nn.GELU()](https://pytorch.org/docs/stable/generated/torch.nn.GELU .html) en PyTorch).
Nota: Una capa lineal (
torch.nn.Linear()) a veces también puede denominarse "capa densa" o "capa de avance". Algunos artículos incluso utilizan los tres términos para describir lo mismo (como en el artículo de ViT).
Otro detalle furtivo sobre el bloque MLP no aparece hasta el Apéndice B.1 (Capacitación):
La Tabla 3 resume nuestras configuraciones de entrenamiento para nuestros diferentes modelos. ...La eliminación, cuando se usa, se aplica después de cada capa densa excepto las proyecciones qkv y directamente después de agregar incrustaciones posicionales a parches.
Esto significa que cada capa lineal (o capa densa) en el bloque MLP tiene una capa de eliminación ([torch.nn.Dropout()](https://pytorch.org/docs/stable/generated/torch.nn. Dropout.html) en PyTorch).
cuyo valor se puede encontrar en la Tabla 3 del artículo de ViT (para ViT-Base, dropout=0.1).
Sabiendo esto, la estructura de nuestro bloque MLP será:
norma de capa -> capa lineal -> capa no lineal -> abandono -> capa lineal -> abandono
Con valores de hiperparámetros para las capas lineales disponibles en la Tabla 1 (el tamaño de MLP es el número de unidades ocultas entre las capas lineales y el tamaño oculto $D$ es el tamaño de salida del bloque MLP).
6.2 Replicando la Ecuación 3 con capas de PyTorch¶
Pongamos en práctica todo lo que hemos discutido sobre las capas LayerNorm (LN) y MLP (MSA) en la ecuación 3.
Para hacerlo, haremos:
- Cree una clase llamada
MLPBlockque herede detorch.nn.Module. - Inicialice la clase con hiperparámetros de la Tabla 1 y la Tabla 3 del documento de ViT para el modelo ViT-Base.
- Cree una capa de normalización de capa (LN) con
torch.nn.LayerNorm()con el parámetronormalized_shapeigual que nuestra dimensión de incrustación ($D$ de la Tabla 1). - Cree una serie secuencial de capas MLP usando
torch.nn.Linear(),torch.nn.Dropout()ytorch.nn.GELU()con valores de hiperparámetro apropiados de la Tabla 1 y Tabla 3. - Cree un método
forward()para nuestra clase pasando las entradas a través de la capa LN y las capas MLP.
# 1. Crea una clase que hereda de nn.Module
class MLPBlock(nn.Module):
"""Creates a layer normalized multilayer perceptron block ("MLP block" for short)."""
# 2. Initialize the class with hyperparameters from Table 1 and Table 3
def __init__(self,
embedding_dim:int=768, # Hidden Size D from Table 1 for ViT-Base
mlp_size:int=3072, # MLP size from Table 1 for ViT-Base
dropout:float=0.1): # Dropout from Table 3 for ViT-Base
super().__init__()
# 3. Create the Norm layer (LN)
self.layer_norm = nn.LayerNorm(normalized_shape=embedding_dim)
# 4. Create the Multilayer perceptron (MLP) layer(s)
self.mlp = nn.Sequential(
nn.Linear(in_features=embedding_dim,
out_features=mlp_size),
nn.GELU(), # "The MLP contains two layers with a GELU non-linearity (section 3.1)."
nn.Dropout(p=dropout),
nn.Linear(in_features=mlp_size, # needs to take same in_features as out_features of layer above
out_features=embedding_dim), # take back to embedding_dim
nn.Dropout(p=dropout) # "Dropout, when used, is applied after every dense layer.."
)
# 5. Create a forward() method to pass the data throguh the layers
def forward(self, x):
x = self.layer_norm(x)
x = self.mlp(x)
return x
Nota: A diferencia de la Figura 1, nuestro
MLPBlock()no incluye una conexión de omisión o residual ("$+\mathbf{z}_{\ell}^{\prime}$" en la ecuación 3 ), incluiremos esto cuando creemos el codificador Transformer completo más adelante.
¡Clase MLPBlock creada!
Probémoslo creando una instancia de nuestro MLPBlock y pasando por la variable patched_image_through_msa_block que creamos en la sección 5.3.
# Crear una instancia de MLPBlock
mlp_block = MLPBlock(embedding_dim=768, # from Table 1
mlp_size=3072, # from Table 1
dropout=0.1) # from Table 3
# Pasar la salida de MSABlock a través de MLPBlock
patched_image_through_mlp_block = mlp_block(patched_image_through_msa_block)
print(f"Input shape of MLP block: {patched_image_through_msa_block.shape}")
print(f"Output shape MLP block: {patched_image_through_mlp_block.shape}")
Observe cómo la forma de entrada y salida de nuestros datos nuevamente permanece igual cuando entran y salen del bloque MLP.
Sin embargo, la forma cambia cuando los datos pasan a través de las capas nn.Linear() dentro del bloque MLP (expandido al tamaño MLP de la Tabla 1 y luego comprimido nuevamente al tamaño Oculto $D$ de la Tabla 1).
Izquierda: Arquitectura de Vision Transformer de la Figura 1 con las capas MLP y Norm resaltadas; estas capas constituyen la ecuación 3 de la sección 3.1 del documento. Derecha: Replicando la ecuación 3 (sin la conexión de salto al final) usando capas de PyTorch.
¡Ho, ho!
¡La ecuación 3 se replicó (excepto por la conexión residual al final, pero llegaremos a esto en la sección 7.1)!
Ahora que tenemos las ecuaciones 2 y 3 en el código PyTorch, juntémoslas para crear el codificador Transformer.
7. Cree el codificador del transformador¶
Es hora de apilar nuestro MultiheadSelfAttentionBlock (ecuación 2) y MLPBlock (ecuación 3) y crear el codificador Transformer de la arquitectura ViT.
En el aprendizaje profundo, un "codificador" o "codificador automático" generalmente se refiere a una pila de capas que "codifica" una entrada (la convierte en alguna forma de representación numérica). ).
En nuestro caso, Transformer Encoder codificará nuestra imagen parcheada incrustándola en una representación aprendida utilizando una serie de capas alternas de bloques MSA y bloques MLP, según la sección 3.1 del documento ViT:
El codificador Transformer (Vaswani et al., 2017) consta de capas alternas de autoatención multicabezal (MSA, ver Apéndice A) y bloques MLP (Ec. 2, 3). Layernorm (LN) se aplica antes de cada bloque y conexiones residuales después de cada bloque (Wang et al., 2019; Baevski & Auli, 2019).
Hemos creado bloques MSA y MLP pero ¿qué pasa con las conexiones residuales?
Las conexiones residuales (también llamadas conexiones de omisión), se introdujeron por primera vez en el artículo [Aprendizaje residual profundo para el reconocimiento de imágenes](https://arxiv.org /abs/1512.03385v1) y se logran agregando una(s) capa(s) de entrada a su salida posterior.
Donde la salida de la subsecuencia podría ser una o más capas posteriores.
En el caso de la arquitectura ViT, la conexión residual significa que la entrada del bloque MSA se vuelve a agregar a la salida del bloque MSA antes de pasar al bloque MLP.
Y lo mismo sucede con el bloque MLP antes de pasar al siguiente bloque Transformer Encoder.
O en pseudocódigo:
x_input -> MSA_block -> [MSA_block_output + x_input] -> MLP_block -> [MLP_block_output + MSA_block_output + x_input] -> ...
¿Qué hace esto?
Una de las ideas principales detrás de las conexiones residuales es que evitan que los valores de peso y las actualizaciones de gradiente sean demasiado pequeños y, por lo tanto, permiten redes más profundas y, a su vez, permiten aprender representaciones más profundas.
Nota: La icónica arquitectura de visión por computadora "ResNet" recibe su nombre debido a la introducción de conexiones residuales. Puede encontrar muchas versiones previamente entrenadas de arquitecturas ResNet en
torchvision.models.
7.1 Creación de un codificador Transformer combinando nuestras capas personalizadas¶
Basta de hablar, veamos esto en acción y hagamos un codificador ViT Transformer con PyTorch combinando nuestras capas creadas previamente.
Para hacerlo, haremos:
- Cree una clase llamada
TransformerEncoderBlockque herede detorch.nn.Module. - Inicialice la clase con hiperparámetros de la Tabla 1 y la Tabla 3 del documento de ViT para el modelo ViT-Base.
- Cree una instancia de un bloque MSA para la ecuación 2 usando nuestro
MultiheadSelfAttentionBlockde la sección 5.2 con los parámetros apropiados. - Cree una instancia de un bloque MLP para la ecuación 3 usando nuestro
MLPBlockde la sección 6.2 con los parámetros apropiados. - Cree un método
forward()para nuestra claseTransformerEncoderBlock. - Cree una conexión residual para el bloque MSA (para la ecuación 2).
- Cree una conexión residual para el bloque MLP (para la ecuación 3).
# 1. Crea una clase que hereda de nn.Module
class TransformerEncoderBlock(nn.Module):
"""Creates a Transformer Encoder block."""
# 2. Initialize the class with hyperparameters from Table 1 and Table 3
def __init__(self,
embedding_dim:int=768, # Hidden size D from Table 1 for ViT-Base
num_heads:int=12, # Heads from Table 1 for ViT-Base
mlp_size:int=3072, # MLP size from Table 1 for ViT-Base
mlp_dropout:float=0.1, # Amount of dropout for dense layers from Table 3 for ViT-Base
attn_dropout:float=0): # Amount of dropout for attention layers
super().__init__()
# 3. Create MSA block (equation 2)
self.msa_block = MultiheadSelfAttentionBlock(embedding_dim=embedding_dim,
num_heads=num_heads,
attn_dropout=attn_dropout)
# 4. Create MLP block (equation 3)
self.mlp_block = MLPBlock(embedding_dim=embedding_dim,
mlp_size=mlp_size,
dropout=mlp_dropout)
# 5. Create a forward() method
def forward(self, x):
# 6. Create residual connection for MSA block (add the input to the output)
x = self.msa_block(x) + x
# 7. Create residual connection for MLP block (add the input to the output)
x = self.mlp_block(x) + x
return x
¡Hermoso!
¡Bloque codificador de transformador creado!

***Izquierda:** Figura 1 del artículo de ViT con el codificador transformador de la arquitectura ViT resaltado. Derecha: Transformer Encoder asignado a las ecuaciones 2 y 3 del documento ViT, el Transformer Encoder se compone de bloques alternos de la ecuación 2 (Atención de múltiples cabezales) y la ecuación 3 (perceptrón multicapa).*
Vea cómo estamos empezando a reconstruir la arquitectura general como si fueran legos, codificando un ladrillo (o ecuación) a la vez.

Asignación del codificador ViT Transformer al código.
Quizás hayas notado que la Tabla 1 del artículo de ViT tiene una columna Capas. Esto se refiere a la cantidad de bloques Transformer Encoder en la arquitectura ViT específica.
En nuestro caso, para ViT-Base, apilaremos 12 de estos bloques Transformer Encoder para formar la columna vertebral de nuestra arquitectura (llegaremos a esto en la sección 8).
Obtengamos un torchinfo.summary() de pasar una entrada de forma (1, 197, 768) -> (batch_size, num_patches, embedding_dimension) a nuestro bloque Transformer Encoder.
# Crea una instancia de TransformerEncoderBlock
transformer_encoder_block = TransformerEncoderBlock()
# # Imprima un resumen de entrada y salida de nuestro codificador de transformador (descomentar para obtener un resultado completo)
# resumen(modelo=transformer_encoder_block,
# tamaño_entrada=(1, 197, 768), # (tamaño_lote, núm_parches, dimensión_incrustación)
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"])

¡Guau! ¡Mira todos esos parámetros!
Puede ver nuestra entrada cambiando de forma a medida que se mueve a través de las distintas capas en el bloque MSA y el bloque MLP del bloque Transformer Encoder antes de finalmente regresar a su forma original al final.
Nota: El hecho de que nuestra entrada al bloque Transformer Encoder tenga la misma forma en la salida del bloque no significa que los valores no hayan sido manipulados, el objetivo general del bloque Transformer Encoder (y apilarlos juntos ) es aprender una representación profunda de la entrada utilizando las distintas capas intermedias.
7.2 Creación de un codificador Transformer con las capas Transformer de PyTorch¶
Hasta ahora, hemos creado nosotros mismos los componentes y la capa Transformer Encoder.
Pero debido a su aumento en popularidad y efectividad, PyTorch ahora tiene capas de transformadores incorporadas como parte de torch.nn.
Por ejemplo, podemos recrear el TransformerEncoderBlock que acabamos de crear usando [torch.nn.TransformerEncoderLayer()](https://pytorch.org/docs/stable/generated/torch.nn.TransformerEncoderLayer.html#torch. nn.TransformerEncoderLayer) y configurando los mismos hiperparámetros que arriba.
# Crea lo mismo que arriba con torch.nn.TransformerEncoderLayer()
torch_transformer_encoder_layer = nn.TransformerEncoderLayer(d_model=768, # Hidden size D from Table 1 for ViT-Base
nhead=12, # Heads from Table 1 for ViT-Base
dim_feedforward=3072, # MLP size from Table 1 for ViT-Base
dropout=0.1, # Amount of dropout for dense layers from Table 3 for ViT-Base
activation="gelu", # GELU non-linear activation
batch_first=True, # Do our batches come first?
norm_first=True) # Normalize first or after MSA/MLP layers?
torch_transformer_encoder_layer
Para inspeccionarlo más a fondo, obtengamos un resumen con torchinfo.summary().
# # Obtener el resultado de la versión de PyTorch del Transformer Encoder (descomentar para obtener el resultado completo)
# resumen(modelo=torch_transformer_encoder_layer,
# tamaño_entrada=(1, 197, 768), # (tamaño_lote, núm_parches, dimensión_incrustación)
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"])

El resultado del resumen es ligeramente diferente al nuestro debido a cómo torch.nn.TransformerEncoderLayer() construye su capa.
Pero las capas que utiliza, la cantidad de parámetros y las formas de entrada y salida son las mismas.
Quizás esté pensando: "si pudimos crear Transformer Encoder tan rápidamente con capas de PyTorch, ¿por qué nos molestamos en reproducir las ecuaciones 2 y 3?"
La respuesta es: practicar.
Ahora que hemos replicado una serie de ecuaciones y capas de un papel, si necesitas cambiar las capas y probar algo diferente, puedes hacerlo.
Pero existen ventajas al utilizar las capas prediseñadas de PyTorch, como por ejemplo:
- Menos propenso a errores - Generalmente, si una capa ingresa a la biblioteca estándar de PyTorch, se ha probado y se ha intentado que funcione.
- Rendimiento potencialmente mejor: a partir de julio de 2022 y PyTorch 1.12, la versión implementada por PyTorch de
torch.nn.TransformerEncoderLayer()puede ver [una aceleración de más del doble en muchas cargas de trabajo comunes](https:// pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/).
Finalmente, dado que la arquitectura ViT utiliza varias capas de transformador apiladas encima de cada una para la arquitectura completa (la Tabla 1 muestra 12 capas en el caso de ViT-Base), puede hacer esto con torch.nn.TransformerEncoder(encoder_layer, num_layers ) donde:
encoder_layer: la capa de Transformer Encoder de destino creada contorch.nn.TransformerEncoderLayer().num_layers: el número de capas de Transformer Encoder que se apilarán juntas.
8. Juntándolo todo para crear ViT¶
Está bien, está bien, ¡hemos recorrido un largo camino!
Pero ahora es el momento de hacer lo emocionante de juntar todas las piezas del rompecabezas.
Combinaremos todos los bloques que hemos creado para replicar la arquitectura ViT completa.
Desde el parche y la incrustación posicional hasta los codificadores Transformer y el cabezal MLP.
Pero espera, aún no hemos creado la ecuación 4...
$$ \begin{alineado} \mathbf{y} &=\operatorname{LN}\left(\mathbf{z}_{L}^{0}\right) & & \end{alineado} $$
No se preocupe, podemos incluir la ecuación 4 en nuestra clase de arquitectura ViT general.
Todo lo que necesitamos es una capa torch.nn.LayerNorm() y una capa torch.nn.Linear() para convertir el índice 0 ($\mathbf{z}_{L}^{0}$) de el logit del codificador del transformador genera el número objetivo de clases que tenemos.
Para crear la arquitectura completa, también necesitaremos apilar varios de nuestros TransformerEncoderBlock uno encima del otro, podemos hacer esto pasando una lista de ellos a torch.nn.Sequential() (esto hacer un rango secuencial de TransformerEncoderBlocks).
Nos centraremos en los hiperparámetros de ViT-Base de la Tabla 1, pero nuestro código debería poder adaptarse a otras variantes de ViT.
Crear ViT será nuestro mayor bloque de código hasta el momento, ¡pero podemos hacerlo!
Finalmente, para darle vida a nuestra propia implementación de ViT, hagamos lo siguiente:
- Cree una clase llamada
ViTque herede detorch.nn.Module. - Inicialice la clase con hiperparámetros de la Tabla 1 y la Tabla 3 del documento de ViT para el modelo ViT-Base.
- Asegúrese de que el tamaño de la imagen sea divisible por el tamaño del parche (la imagen debe dividirse en parches pares).
- Calcule el número de parches usando la fórmula $N=H W / P^{2}$, donde $H$ es la altura de la imagen, $W$ es el ancho de la imagen y $P$ es el tamaño del parche.
- Cree un token de incrustación de clase que se pueda aprender (ecuación 1) como se hizo anteriormente en la sección 4.6.
- Cree un vector de incrustación de posición que se pueda aprender (ecuación 1) como se hizo anteriormente en la sección 4.7.
- Configure la capa de eliminación de incrustación como se explica en el Apéndice B.1 del documento de ViT.
- Cree la capa de incrustación de parches utilizando la clase
PatchEmbeddingcomo se indica arriba en la sección 4.5. - Cree una serie de bloques Transformer Encoder pasando una lista de
TransformerEncoderBlockcreados en la sección 7.1 atorch.nn.Sequential()(ecuaciones 2 y 3). - Cree el encabezado MLP (también llamado encabezado clasificador o ecuación 4) pasando una capa
torch.nn.LayerNorm()(LN) y una capatorch.nn.Linear(out_features=num_classes)(dondenum_classeses el número objetivo de clases) capa lineal atorch.nn.Sequential(). - Cree un método
forward()que acepte una entrada. - Obtenga el tamaño del lote de la entrada (la primera dimensión de la forma).
- Cree la incrustación de parche utilizando la capa creada en el paso 8 (ecuación 1).
- Cree la incrustación del token de clase usando la capa creada en el paso 5 y expándala a través del número de lotes encontrados en el paso 11 usando [
torch.Tensor.expand()](https://pytorch.org/docs/stable /generated/torch.Tensor.expand.html) (ecuación 1). - Concatene la incrustación del token de clase creada en el paso 13 con la primera dimensión de la incrustación del parche creada en el paso 12 usando [
torch.cat()](https://pytorch.org/docs/stable/generated/torch. cat.html) (ecuación 1). - Agregue la incrustación de posición creada en el paso 6 a la incrustación de parche y token de clase creada en el paso 14 (ecuación 1).
- Pase el parche y coloque la incrustación a través de la capa de eliminación creada en el paso 7.
- Pase el parche y la posición incrustada del paso 16 a través de la pila de capas de Transformer Encoder creada en el paso 9 (ecuaciones 2 y 3).
- Pase el índice 0 de la salida de la pila de capas de Transformer Encoder del paso 17 a través del cabezal clasificador creado en el paso 10 (ecuación 4).
- Baila y grita ¡¡¡woohoo!!! ¡Acabamos de construir un transformador de visión!
¿Estás listo?
Vamos.
# 1. Cree una clase ViT que herede de nn.Module
class ViT(nn.Module):
"""Creates a Vision Transformer architecture with ViT-Base hyperparameters by default."""
# 2. Initialize the class with hyperparameters from Table 1 and Table 3
def __init__(self,
img_size:int=224, # Training resolution from Table 3 in ViT paper
in_channels:int=3, # Number of channels in input image
patch_size:int=16, # Patch size
num_transformer_layers:int=12, # Layers from Table 1 for ViT-Base
embedding_dim:int=768, # Hidden size D from Table 1 for ViT-Base
mlp_size:int=3072, # MLP size from Table 1 for ViT-Base
num_heads:int=12, # Heads from Table 1 for ViT-Base
attn_dropout:float=0, # Dropout for attention projection
mlp_dropout:float=0.1, # Dropout for dense/MLP layers
embedding_dropout:float=0.1, # Dropout for patch and position embeddings
num_classes:int=1000): # Default for ImageNet but can customize this
super().__init__() # don't forget the super().__init__()!
# 3. Make the image size is divisble by the patch size
assert img_size % patch_size == 0, f"Image size must be divisible by patch size, image size: {img_size}, patch size: {patch_size}."
# 4. Calculate number of patches (height * width/patch^2)
self.num_patches = (img_size * img_size) // patch_size**2
# 5. Create learnable class embedding (needs to go at front of sequence of patch embeddings)
self.class_embedding = nn.Parameter(data=torch.randn(1, 1, embedding_dim),
requires_grad=True)
# 6. Create learnable position embedding
self.position_embedding = nn.Parameter(data=torch.randn(1, self.num_patches+1, embedding_dim),
requires_grad=True)
# 7. Create embedding dropout value
self.embedding_dropout = nn.Dropout(p=embedding_dropout)
# 8. Create patch embedding layer
self.patch_embedding = PatchEmbedding(in_channels=in_channels,
patch_size=patch_size,
embedding_dim=embedding_dim)
# 9. Create Transformer Encoder blocks (we can stack Transformer Encoder blocks using nn.Sequential())
# Note: The "*" means "all"
self.transformer_encoder = nn.Sequential(*[TransformerEncoderBlock(embedding_dim=embedding_dim,
num_heads=num_heads,
mlp_size=mlp_size,
mlp_dropout=mlp_dropout) for _ in range(num_transformer_layers)])
# 10. Create classifier head
self.classifier = nn.Sequential(
nn.LayerNorm(normalized_shape=embedding_dim),
nn.Linear(in_features=embedding_dim,
out_features=num_classes)
)
# 11. Create a forward() method
def forward(self, x):
# 12. Get batch size
batch_size = x.shape[0]
# 13. Create class token embedding and expand it to match the batch size (equation 1)
class_token = self.class_embedding.expand(batch_size, -1, -1) # "-1" means to infer the dimension (try this line on its own)
# 14. Create patch embedding (equation 1)
x = self.patch_embedding(x)
# 15. Concat class embedding and patch embedding (equation 1)
x = torch.cat((class_token, x), dim=1)
# 16. Add position embedding to patch embedding (equation 1)
x = self.position_embedding + x
# 17. Run embedding dropout (Appendix B.1)
x = self.embedding_dropout(x)
# 18. Pass patch, position and class embedding through transformer encoder layers (equations 2 & 3)
x = self.transformer_encoder(x)
# 19. Put 0 index logit through classifier (equation 4)
x = self.classifier(x[:, 0]) # run on each sample in a batch at 0 index
return x
- 🕺💃🥳 ¡¡¡Guau!!! ¡Acabamos de construir un transformador de visión!
¡Qué esfuerzo!
¡Lento pero seguro creamos capas y bloques, entradas y salidas y los juntamos todos para construir nuestro propio ViT!
Creemos una demostración rápida para mostrar lo que sucede con la incorporación del token de clase que se expande en las dimensiones del lote.
# Ejemplo de creación de la clase incrustada y expandida en una dimensión por lotes
batch_size = 32
class_token_embedding_single = nn.Parameter(data=torch.randn(1, 1, 768)) # create a single learnable class token
class_token_embedding_expanded = class_token_embedding_single.expand(batch_size, -1, -1) # expand the single learnable class token across the batch dimension, "-1" means to "infer the dimension"
# Imprime el cambio de formas.
print(f"Shape of class token embedding single: {class_token_embedding_single.shape}")
print(f"Shape of class token embedding expanded: {class_token_embedding_expanded.shape}")
Observe cómo la primera dimensión se expande al tamaño del lote y las otras dimensiones permanecen iguales (porque se deducen de las dimensiones "-1" en .expand(batch_size, -1, -1)).
Muy bien, es hora de probar la clase ViT().
Creemos un tensor aleatorio con la misma forma que una sola imagen, pasemos a una instancia de "ViT" y veamos qué sucede.
set_seeds()
# Crea un tensor aleatorio con la misma forma que una sola imagen.
random_image_tensor = torch.randn(1, 3, 224, 224) # (batch_size, color_channels, height, width)
# Crear una instancia de ViT con la cantidad de clases con las que estamos trabajando (pizza, bistec, sushi)
vit = ViT(num_classes=len(class_names))
# Pasar el tensor de imagen aleatorio a nuestra instancia de ViT
vit(random_image_tensor)
¡Pendiente!
Parece que nuestro tensor de imágenes aleatorias llegó hasta nuestra arquitectura ViT y está generando tres valores logit (uno para cada clase).
Y debido a que nuestra clase ViT tiene muchos parámetros, podríamos personalizar img_size, patch_size o num_classes si quisiéramos.
8.1 Obteniendo un resumen visual de nuestro modelo ViT¶
Creamos a mano nuestra propia versión de la arquitectura ViT y vimos que un tensor de imagen aleatorio puede fluir a través de ella.
¿Qué tal si usamos torchinfo.summary() para obtener una descripción visual de las formas de entrada y salida de todas las capas de nuestro modelo?
Nota: El documento de ViT establece el uso de un tamaño de lote de 4096 para el entrenamiento; sin embargo, esto requiere una gran cantidad de memoria de procesamiento de CPU/GPU para manejarlo (cuanto mayor sea el tamaño del lote, más memoria se requerirá). Entonces, para asegurarnos de que no tengamos errores de memoria, nos quedaremos con un tamaño de lote de 32. Siempre puedes aumentar esto más adelante si tienes acceso a hardware con más memoria.
from torchinfo import summary
# # Imprima un resumen de nuestro modelo ViT personalizado usando torchinfo (descomente el resultado real)
# resumen(modelo=vit,
# tamaño_entrada=(32, 3, 224, 224), # (tamaño_lote, canales_color, alto, ancho)
# # col_names=["input_size"], # descomentar para resultados más pequeños
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"]
# )
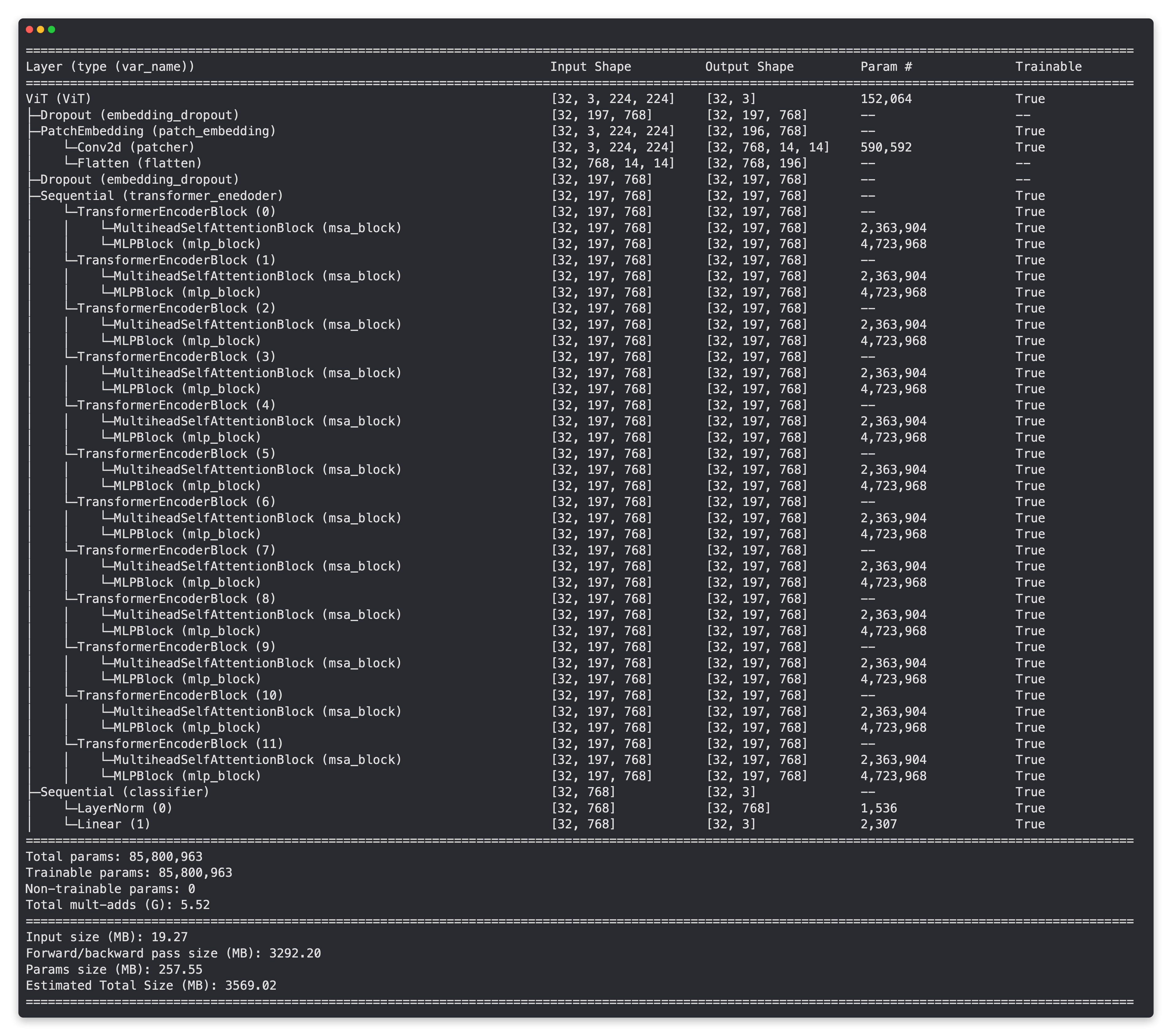
¡Esas son algunas capas bonitas!
Consulte también el número total de parámetros, 85.800.963, ¡nuestro modelo más grande hasta el momento!
El número está muy cerca del ViT-Base previamente entrenado de PyTorch con tamaño de parche 16 en [torch.vision.models.vit_b_16()](https://pytorch.org/vision/main/models/generated/torchvision.models. vit_b_16.html#torchvision.models.vit_b_16) con 86,567,656 parámetros totales (aunque este número de parámetros es para las 1000 clases en ImageNet).
Ejercicio: Intente cambiar el parámetro
num_classesde nuestro modeloViT()a 1000 y luego cree otro resumen contorchinfo.summary()y vea si el número de parámetros se alinea entre nuestro código ytorchvision.models.vit_b_16().
9. Configurando el código de entrenamiento para nuestro modelo ViT¶
Bueno, es hora de la parte fácil.
¡Capacitación!
¿Por qué fácil?
Porque tenemos la mayor parte de lo que necesitamos listo, desde nuestro modelo (vit) hasta nuestros DataLoaders (train_dataloader, test_dataloader) y las funciones de entrenamiento que creamos en 05. PyTorch Going Modular sección 4.
Para entrenar nuestro modelo podemos importar la función train() desde [going_modular.going_modular.engine](https://github.com/mrdbourke/pytorch-deep-learning/blob/main/going_modular/going_modular/train .py).
Todo lo que necesitamos es una función de pérdida y un optimizador.
9.1 Creando un optimizador¶
Buscando en el artículo de ViT "optimizador", sección 4.1 sobre estados de entrenamiento y ajuste:
Entrenamiento y ajuste. Entrenamos todos los modelos, incluidos ResNets, usando Adam (Kingma & Ba, 2015) con $\beta_{1}=0.9, \beta_{2}=0.999$, un tamaño de lote de 4096 y aplicar una caída de peso alta de $0.1$, que encontramos útil para la transferencia de todos los modelos (el Apéndice D.1 muestra que, en contraste con las prácticas comunes, Adam funciona ligeramente mejor que SGD para ResNets en nuestro entorno).
Entonces podemos ver que eligieron usar el optimizador "Adam" ([torch.optim.Adam()](https://pytorch.org/docs/stable/generated/torch.optim.Adam.html#torch. optim.Adam)) en lugar de SGD (descenso de gradiente estocástico, [torch.optim.SGD()](https://pytorch.org/docs/stable/generated/torch.optim.SGD.html#torch.optim .SGD)).
Los autores establecieron los valores $\beta$ (beta) de Adam en $\beta_{1}=0.9, \beta_{2}=0.999$, estos son los valores predeterminados para el parámetro betas en torch.optim.Adam( betas=(0.9, 0.999)).
También indican el uso de [decaimiento de peso] (https://paperswithcode.com/method/weight-decay) (reduciendo lentamente los valores de los pesos durante la optimización para evitar el sobreajuste), podemos configurar esto con el parámetro weight_decay en torch.optim.Adam(weight_decay=0.3) (de acuerdo con la configuración de ViT-* entrenado en ImageNet-1k).
Estableceremos la tasa de aprendizaje del optimizador en 0,003 según la Tabla 3 (de acuerdo con la configuración de ViT-* entrenado en ImageNet-1k).
Y como se mencionó anteriormente, usaremos un tamaño de lote menor que 4096 debido a limitaciones de hardware (si tiene una GPU grande, no dude en aumentarlo).
9.2 Creando una función de pérdida¶
Curiosamente, buscar en el artículo de ViT "pérdida" o "función de pérdida" o "criterio" no arroja resultados.
Sin embargo, dado que el problema objetivo con el que estamos trabajando es la clasificación de clases múltiples (lo mismo para el artículo de ViT), usaremos [torch.nn.CrossEntropyLoss()](https://pytorch.org/docs /stable/generated/torch.nn.CrossEntropyLoss.html).
9.3 Entrenando nuestro modelo ViT¶
Bien, ahora que sabemos qué optimizador y función de pérdida vamos a usar, configuremos el código de entrenamiento para entrenar nuestro ViT.
Comenzaremos importando el script engine.py desde going_modular.going_modular luego configuraremos el optimizador y la función de pérdida y finalmente usaremos la función train() de engine.py para entrenar nuestro modelo ViT para 10 épocas (estamos usando una cantidad menor de épocas que el documento ViT para asegurarnos de que todo funcione).
from going_modular.going_modular import engine
# Configure el optimizador para optimizar los parámetros de nuestro modelo ViT utilizando hiperparámetros del artículo de ViT.
optimizer = torch.optim.Adam(params=vit.parameters(),
lr=3e-3, # Base LR from Table 3 for ViT-* ImageNet-1k
betas=(0.9, 0.999), # default values but also mentioned in ViT paper section 4.1 (Training & Fine-tuning)
weight_decay=0.3) # from the ViT paper section 4.1 (Training & Fine-tuning) and Table 3 for ViT-* ImageNet-1k
# Configure la función de pérdida para la clasificación de clases múltiples
loss_fn = torch.nn.CrossEntropyLoss()
# Establecer las semillas
set_seeds()
# Entrene el modelo y guarde los resultados del entrenamiento en un diccionario.
results = engine.train(model=vit,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=10,
device=device)
¡Maravilloso!
¡Nuestro modelo ViT ha cobrado vida!
Aunque los resultados de nuestro conjunto de datos sobre pizza, bistec y sushi no parecen muy buenos.
¿Quizás sea porque nos faltan algunas cosas?
9.4 Lo que le falta a nuestra configuración de entrenamiento¶
La arquitectura ViT original logra buenos resultados en varios puntos de referencia de clasificación de imágenes (a la par o mejores que muchos resultados de última generación cuando se lanzó).
Sin embargo, nuestros resultados (hasta ahora) no son tan buenos.
Hay varias razones por las que esto podría deberse, pero la principal es la escala.
El artículo original de ViT utiliza una cantidad mucho mayor de datos que el nuestro (en el aprendizaje profundo, generalmente siempre es bueno tener más datos) y un programa de entrenamiento más largo (consulte la Tabla 3).
| Valor de hiperparámetro | Papel ViT | Nuestra implementación |
|---|---|---|
| Número de imágenes de entrenamiento | 1,3 millones (ImageNet-1k), 14 millones (ImageNet-21k), 303 millones (JFT) | 225 |
| Épocas | 7 (para el conjunto de datos más grande), 90, 300 (para ImageNet) | 10 |
| Tamaño del lote | 4096 | 32 |
| Preparación de la tasa de aprendizaje | 10k pasos (Tabla 3) | Ninguno |
| [Decaimiento de la tasa de aprendizaje](https://medium.com/analytics-vidhya/learning-rate-decay-and-methods-in-deep-learning-2cee564f910b#:~:text=Learning%20rate%20decay%20is%20a ,ayuda%20tanto%20optimización%20 como%20generalización.) | Lineal/Coseno (Tabla 3) | Ninguno |
| Recorte de degradado | Norma global 1 (Tabla 3) | Ninguno |
Aunque nuestra arquitectura ViT es la misma que la del artículo, los resultados del artículo ViT se lograron utilizando muchos más datos y un esquema de capacitación más elaborado que el nuestro.
Debido al tamaño de la arquitectura ViT y su gran número de parámetros (mayores capacidades de aprendizaje) y la cantidad de datos que utiliza (mayores oportunidades de aprendizaje), muchas de las técnicas utilizadas en el esquema de capacitación en papel de ViT, como el calentamiento de la tasa de aprendizaje, el aprendizaje La caída de velocidad y el recorte de gradiente están diseñados específicamente para prevenir el sobreajuste (regularización).
Nota: Para cualquier técnica de la que no esté seguro, a menudo puede encontrar rápidamente un ejemplo buscando "NOMBRE DE LA TÉCNICA de pytorch", por ejemplo, digamos que desea aprender sobre el calentamiento de la velocidad de aprendizaje y lo que hace, podría hacerlo. busque "calentamiento de la tasa de aprendizaje de pytorch".
La buena noticia es que hay muchos modelos ViT previamente entrenados (que utilizan grandes cantidades de datos) disponibles en línea; veremos uno en acción en la sección 10.
9.5 Trazar las curvas de pérdidas de nuestro modelo ViT¶
Hemos entrenado nuestro modelo ViT y hemos visto los resultados como números en una página.
Pero sigamos ahora el lema del explorador de datos de ¡visualizar, visualizar, visualizar!
Y una de las mejores cosas que se pueden visualizar para un modelo son sus curvas de pérdida.
Para comprobar las curvas de pérdida de nuestro modelo ViT, podemos usar la función plot_loss_curves de helper_functions.py que creamos en [04. Sección 7.8 de conjuntos de datos personalizados de PyTorch] (https://www.learnpytorch.io/04_pytorch_custom_datasets/#78-plot-the-loss-curves-of-model-0).
from helper_functions import plot_loss_curves
# Trazar las curvas de pérdida de nuestro modelo ViT.
plot_loss_curves(results)
Hmm, parece que las curvas de pérdida de nuestro modelo están por todos lados.
Al menos la pérdida parece ir en la dirección correcta, pero las curvas de precisión no son muy prometedoras.
Es probable que estos resultados se deban a la diferencia en los recursos de datos y el régimen de entrenamiento de nuestro modelo ViT frente al documento ViT.
Parece que nuestro modelo está muy insuficientemente adaptado (no logra los resultados que nos gustaría).
¿Qué tal si vemos si podemos solucionarlo incorporando un modelo ViT previamente entrenado?
10. Usando un ViT previamente entrenado de torchvision.models en el mismo conjunto de datos¶
Hemos discutido los beneficios de usar modelos previamente entrenados en 06. Aprendizaje por transferencia de PyTorch.
Pero dado que ahora entrenamos nuestro propio ViT desde cero y logramos resultados no óptimos, los beneficios del aprendizaje por transferencia (usando un modelo previamente entrenado) realmente brillan.
10.1 ¿Por qué utilizar un modelo previamente entrenado?¶
Una nota importante en muchos artículos de investigación sobre aprendizaje automático moderno es que muchos de los resultados se obtienen con grandes conjuntos de datos y vastos recursos informáticos.
Y en el aprendizaje automático moderno, el ViT original totalmente entrenado probablemente no se consideraría una configuración de entrenamiento "súper grande" (los modelos son cada vez más grandes).
Leyendo la sección 4.2 del artículo de ViT:
Finalmente, el modelo ViT-L/16 previamente entrenado en el conjunto de datos público ImageNet-21k también funciona bien en la mayoría de los conjuntos de datos, aunque requiere menos recursos para el entrenamiento previo: podría entrenarse usando una nube estándar TPUv3 con 8 núcleos en aproximadamente 30 dias.
A partir de julio de 2022, el precio por alquilar un TPUv3 (Unidad de procesamiento Tensor versión 3) con 8 núcleos en Google Cloud es de $8 USD por hora.
Alquilar uno por 30 días seguidos costaría $5,760 USD.
Este costo (monetario y de tiempo) puede ser viable para algunos equipos de investigación o empresas más grandes, pero para muchas personas no lo es.
Por lo tanto, tener un modelo previamente entrenado disponible a través de recursos como torchvision.models, la biblioteca [timm (Torch Image Models)](https:/ /github.com/rwightman/pytorch-image-models), el HuggingFace Hub o incluso de los propios autores de los artículos (hay una tendencia creciente entre los investigadores de aprendizaje automático a publicar El código y los modelos previamente entrenados de sus artículos de investigación, soy un gran admirador de esta tendencia, muchos de estos recursos se pueden encontrar en Paperswithcode.com).
Si está concentrado en aprovechar los beneficios de una arquitectura de modelo específica en lugar de crear su arquitectura personalizada, le recomiendo encarecidamente utilizar un modelo previamente entrenado.
10.2 Obtener un modelo ViT previamente entrenado y crear un extractor de funciones¶
Podemos obtener un modelo ViT previamente entrenado desde torchvision.models.
Empezaremos desde arriba asegurándonos primero de tener las versiones correctas de "torch" y "torchvision".
Nota: El siguiente código requiere
torchv0.12+ ytorchvisionv0.13+ para utilizar la última API de pesos de modelotorchvision.
# Lo siguiente requiere torch v0.12+ y torchvision v0.13+
import torch
import torchvision
print(torch.__version__)
print(torchvision.__version__)
Luego configuraremos el código agonista del dispositivo.
device = "cuda" if torch.cuda.is_available() else "cpu"
device
Finalmente, obtendremos ViT-Base previamente entrenado con tamaño de parche 16 de torchvision.models y lo prepararemos para nuestro caso de uso de FoodVision Mini convirtiéndolo en un modelo de aprendizaje de transferencia de extractor de funciones.
Específicamente, haremos:
- Obtenga los pesos previamente entrenados para ViT-Base entrenados en ImageNet-1k desde [
torchvision.models.ViT_B_16_Weights.DEFAULT](https://pytorch.org/vision/stable/models/generated/torchvision.models.vit_b_16. html#torchvision.models.ViT_B_16_Weights) (DEFAULTsignifica mejor disponible). - Configure una instancia de modelo ViT a través de
torchvision.models.vit_b_16, pásele los pesos previamente entrenados paso 1 y envíelo al dispositivo de destino. - Congele todos los parámetros en el modelo ViT base creado en el paso 2 estableciendo su atributo
requires_gradenFalse. - Actualice el clasificador principal del modelo ViT creado en el paso 2 para adaptarlo a nuestro propio problema cambiando el número de
out_featuresa nuestro número de clases (pizza, bistec, sushi).
Cubrimos pasos como este en 06. Aprendizaje por transferencia de PyTorch [sección 3.2: Configuración de un modelo previamente entrenado] (https://www.learnpytorch.io/06_pytorch_transfer_learning/#32-setting-up-a-pretrained-model) y [sección 3.4: Congelar el modelo base y cambiar la capa de salida para adaptarla a nuestras necesidades](https://www.learnpytorch.io/06_pytorch_transfer_learning/#34-freezing-the-base-model-and-changing-the-output-layer- a-nuestras-necesidades).
# 1. Obtenga pesas previamente entrenadas para ViT-Base
pretrained_vit_weights = torchvision.models.ViT_B_16_Weights.DEFAULT # requires torchvision >= 0.13, "DEFAULT" means best available
# 2. Configurar una instancia de modelo ViT con pesos previamente entrenados
pretrained_vit = torchvision.models.vit_b_16(weights=pretrained_vit_weights).to(device)
# 3. Congelar los parámetros base.
for parameter in pretrained_vit.parameters():
parameter.requires_grad = False
# 4. Cambie el cabezal clasificador (configure las semillas para garantizar la misma inicialización con el cabezal lineal)
set_seeds()
pretrained_vit.heads = nn.Linear(in_features=768, out_features=len(class_names)).to(device)
# pretrained_vit # descomentar para la salida del modelo
¡Se ha creado un modelo de extractor de funciones ViT previamente entrenado!
Comprobémoslo ahora imprimiendo un torchinfo.summary().
# # Imprimir un resumen usando torchinfo (descomentar para el resultado real)
# resumen (modelo = vit preentrenado,
# tamaño_entrada=(32, 3, 224, 224), # (tamaño_lote, canales_color, alto, ancho)
# # col_names=["input_size"], # descomentar para resultados más pequeños
# col_names=["input_size", "output_size", "num_params", "entrenable"],
# ancho_columna=20,
# row_settings=["var_names"]
# )
¡Guau!
Observe cómo solo la capa de salida es entrenable, mientras que el resto de las capas no se pueden entrenar (congeladas).
Y el número total de parámetros, 85.800.963, es el mismo que el de nuestro modelo ViT personalizado anterior.
Pero el número de parámetros entrenables para pretrained_vit es mucho, mucho menor que nuestro vit personalizado: solo 2,307 en comparación con 85,800,963 (en nuestro vit personalizado, dado que estamos entrenando desde cero, todos los parámetros se pueden entrenar).
Esto significa que el modelo previamente entrenado debería entrenarse mucho más rápido; potencialmente podríamos incluso usar un tamaño de lote mayor, ya que menos actualizaciones de parámetros consumirán memoria.
10.3 Preparación de datos para el modelo ViT previamente entrenado¶
Descargamos y creamos DataLoaders para nuestro propio modelo ViT en la sección 2.
Así que no necesariamente necesitamos hacerlo de nuevo.
Pero en nombre de la práctica, descarguemos algunos datos de imágenes (imágenes de pizza, bistec y sushi para Food Vision Mini), configuremos directorios de tren y prueba y luego transformemos las imágenes en tensores y DataLoaders.
Podemos descargar imágenes de pizza, bistec y sushi desde el curso GitHub y la función download_data() que creamos en [07. Sección 1 de seguimiento de experimentos de PyTorch] (https://www.learnpytorch.io/07_pytorch_experiment_tracking/#1-get-data).
from helper_functions import download_data
# Descargue imágenes de pizza, bistec y sushi desde GitHub
image_path = download_data(source="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip",
destination="pizza_steak_sushi")
image_path
Y ahora configuraremos las rutas del directorio de entrenamiento y prueba.
# Configurar rutas de directorio de tren y prueba
train_dir = image_path / "train"
test_dir = image_path / "test"
train_dir, test_dir
Finalmente, transformaremos nuestras imágenes en tensores y convertiremos los tensores en DataLoaders.
Dado que estamos usando un modelo previamente entrenado en forma de torchvision.models, podemos llamar al método transforms() para obtener las transformaciones requeridas.
Recuerde, si va a utilizar un modelo previamente entrenado, generalmente es importante asegurarse de que sus propios datos personalizados se transformen/formateen de la misma manera que los datos en los que se entrenó el modelo original.
Cubrimos este método de creación de transformaciones "automáticas" en [06. Sección 2.2 de aprendizaje por transferencia de PyTorch] (https://www.learnpytorch.io/06_pytorch_transfer_learning/#22-creating-a-transform-for-torchvisionmodels-auto-creation).
# Obtenga transformaciones automáticas a partir de pesas ViT previamente entrenadas
pretrained_vit_transforms = pretrained_vit_weights.transforms()
print(pretrained_vit_transforms)
Y ahora que tenemos las transformaciones listas, podemos convertir nuestras imágenes en DataLoaders usando el método data_setup.create_dataloaders() que creamos en 05. PyTorch Going Modular sección 2.
Dado que estamos usando un modelo de extracción de características (parámetros menos entrenables), podríamos aumentar el tamaño del lote a un valor más alto (si lo configuramos en 1024, estaríamos imitando una mejora encontrada en Mejores líneas base de ViT simples para ImageNet -1k, un artículo que mejora el artículo original de ViT y sugiere lecturas adicionales). Pero como solo tenemos ~200 muestras de entrenamiento en total, nos quedaremos con 32.
# Configurar cargadores de datos
train_dataloader_pretrained, test_dataloader_pretrained, class_names = data_setup.create_dataloaders(train_dir=train_dir,
test_dir=test_dir,
transform=pretrained_vit_transforms,
batch_size=32) # Could increase if we had more samples, such as here: https://arxiv.org/abs/2205.01580 (there are other improvements there too...)
10.4 Modelo ViT del extractor de funciones del tren¶
Modelo de extractor de funciones listo, DataLoaders listos, ¡es hora de entrenar!
Como antes, usaremos el optimizador Adam (torch.optim.Adam()) con una tasa de aprendizaje de 1e-3 y torch.nn.CrossEntropyLoss() como función de pérdida.
Nuestra función engine.train() que creamos en 05. PyTorch Going Modular sección 4 se encargará del resto.
from going_modular.going_modular import engine
# Crear optimizador y función de pérdida.
optimizer = torch.optim.Adam(params=pretrained_vit.parameters(),
lr=1e-3)
loss_fn = torch.nn.CrossEntropyLoss()
# Entrene el cabezal clasificador del modelo de extracción de características ViT previamente entrenado
set_seeds()
pretrained_vit_results = engine.train(model=pretrained_vit,
train_dataloader=train_dataloader_pretrained,
test_dataloader=test_dataloader_pretrained,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=10,
device=device)
¡Santa vaca!
Parece que nuestro extractor de funciones ViT previamente entrenado funcionó mucho mejor que nuestro modelo ViT personalizado entrenado desde cero (en la misma cantidad de tiempo).
Seamos visuales.
10.5 Trazar curvas de pérdida del modelo ViT del extractor de características¶
Nuestros números de modelo de funciones ViT previamente entrenados se ven bien en los conjuntos de entrenamiento y prueba.
¿Cómo se ven las curvas de pérdidas?
# Trazar las curvas de pérdida
from helper_functions import plot_loss_curves
plot_loss_curves(pretrained_vit_results)
¡Guau!
Estas son algunas curvas de pérdida cercanas a las de un libro de texto (realmente buenas) (consulte [04. PyTorch Custom Datasets sección 8](https://www.learnpytorch.io/04_pytorch_custom_datasets/#8-what-should-an-ideal-loss -curve-look-like) para saber cómo debería ser una curva de pérdidas ideal).
¡Ese es el poder del aprendizaje por transferencia!
Logramos obtener resultados sobresalientes con la misma arquitectura del modelo, excepto que nuestra implementación personalizada fue entrenada desde cero (peor rendimiento) y este modelo de extracción de características tiene el poder de pesos previamente entrenados de ImageNet detrás.
¿Qué opinas?
¿Nuestro modelo de extracción de características mejoraría más si continuaras entrenándolo?
10.6 Guardar el modelo ViT del extractor de funciones y verificar el tamaño del archivo¶
Parece que nuestro modelo de extractor de funciones ViT está funcionando bastante bien para nuestro problema Food Vision Mini.
Quizás queramos intentar implementarlo y ver cómo va en producción (en este caso, implementar significa poner nuestro modelo entrenado en una aplicación que alguien podría usar, por ejemplo, tomar fotografías de comida con su teléfono inteligente y ver si nuestro modelo piensa que es pizza). filete o sushi).
Para hacerlo, primero podemos guardar nuestro modelo con la función utils.save_model() que creamos en 05. PyTorch Going Modular sección 5.
# guardar el modelo
from going_modular.going_modular import utils
utils.save_model(model=pretrained_vit,
target_dir="models",
model_name="08_pretrained_vit_feature_extractor_pizza_steak_sushi.pth")
Y como estamos pensando en implementar este modelo, sería bueno saber su tamaño (en megabytes o MB).
Como queremos que nuestra aplicación Food Vision Mini se ejecute rápidamente, generalmente un modelo más pequeño con buen rendimiento será mejor que un modelo más grande con gran rendimiento.
Podemos verificar el tamaño de nuestro modelo en bytes usando el atributo st_size de Python [pathlib.Path().stat()](https://docs.python.org/3/library/pathlib.html# pathlib.Path.stat) mientras le pasa el nombre de ruta de archivo de nuestro modelo.
Luego podemos escalar el tamaño en bytes a megabytes.
from pathlib import Path
# Obtenga el tamaño del modelo en bytes y luego conviértalo a megabytes
pretrained_vit_model_size = Path("models/08_pretrained_vit_feature_extractor_pizza_steak_sushi.pth").stat().st_size // (1024*1024) # division converts bytes to megabytes (roughly)
print(f"Pretrained ViT feature extractor model size: {pretrained_vit_model_size} MB")
Hmm, parece que nuestro modelo de extractor de funciones ViT para Food Vision Mini resultó tener un tamaño de aproximadamente 327 MB.
¿Cómo se compara esto con el modelo de extracción de características EffNetB2 en [07. Sección 9 de seguimiento de experimentos de PyTorch] (https://www.learnpytorch.io/07_pytorch_experiment_tracking/#9-load-in-the-best-model-and-make-predictions-with-it)?
| Modelo | Tamaño del modelo (MB) | Pérdida de prueba | Precisión de la prueba |
|---|---|---|---|
| Extractor de funciones EffNetB2 ^ | 29 | ~0,3906 | ~0,9384 |
| Extractor de funciones ViT | 327 | ~0,1084 | ~0,9384 |
Nota: ^ el modelo EffNetB2 de referencia se entrenó con un 20 % de datos de pizza, bistec y sushi (el doble de imágenes) en lugar del extractor de funciones ViT, que se entrenó con un 10 % de pizza, bistec y sushi. datos. Un ejercicio sería entrenar el modelo de extracción de funciones de ViT con la misma cantidad de datos y ver cuánto mejoran los resultados.
El modelo EffNetB2 es aproximadamente 11 veces más pequeño que el modelo ViT con resultados similares en cuanto a pérdida de prueba y precisión.
Sin embargo, los resultados del modelo ViT pueden mejorar más cuando se entrena con los mismos datos (20% de datos de pizza, bistec y sushi).
Pero en términos de implementación, si estuviéramos comparando estos dos modelos, algo que tendríamos que considerar es si la precisión adicional del modelo ViT vale el aumento de ~11 veces en el tamaño del modelo.
Quizás un modelo tan grande tardaría más en cargarse/ejecutarse y no proporcionaría una experiencia tan buena como EffNetB2, que funciona de manera similar pero en un tamaño mucho más reducido.
11. Haz predicciones sobre una imagen personalizada¶
Y finalmente, terminaremos con la prueba definitiva, prediciendo sobre nuestros propios datos personalizados.
Descarguemos la imagen del papá de la pizza (una foto de mi papá comiendo pizza) y usemos nuestro extractor de funciones ViT para predecirla.
Para hacerlo, podemos usar la función pred_and_plot() que creamos en [06. Sección 6 de PyTorch Transfer Learning] (https://www.learnpytorch.io/06_pytorch_transfer_learning/#6-make-predictions-on-images-from-the-test-set), por conveniencia, guardé esta función en going_modular .going_modular.predictions.py en el curso GitHub.
import requests
# Función de importación para hacer predicciones sobre imágenes y trazarlas.
from going_modular.going_modular.predictions import pred_and_plot_image
# Configurar ruta de imagen personalizada
custom_image_path = image_path / "04-pizza-dad.jpeg"
# Descarga la imagen si aún no existe
if not custom_image_path.is_file():
with open(custom_image_path, "wb") as f:
# When downloading from GitHub, need to use the "raw" file link
request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/images/04-pizza-dad.jpeg")
print(f"Downloading {custom_image_path}...")
f.write(request.content)
else:
print(f"{custom_image_path} already exists, skipping download.")
# Predecir en imagen personalizada
pred_and_plot_image(model=pretrained_vit,
image_path=custom_image_path,
class_names=class_names)
¡Dos pulgares arriba!
¡Felicidades!
¡Hemos recorrido todo el camino desde un trabajo de investigación hasta un código de modelo utilizable en nuestras propias imágenes personalizadas!
Principales conclusiones¶
- Con la explosión del aprendizaje automático, todos los días aparecen nuevos artículos de investigación que detallan los avances. Y es imposible mantenerse al día con todo, pero puede limitar las cosas a su propio caso de uso, como lo que hicimos aquí, replicando un documento de visión por computadora para FoodVision Mini.
- Los artículos de investigación sobre aprendizaje automático a menudo contienen meses de investigación realizados por equipos de personas inteligentes comprimidos en unas pocas páginas (por lo que desentrañar todos los detalles y replicar el artículo en su totalidad puede ser un desafío).
- El objetivo de la replicación en papel es convertir artículos de investigación sobre aprendizaje automático (texto y matemáticas) en código utilizable.
- Dicho esto, muchos equipos de investigación de aprendizaje automático están comenzando a publicar código con sus artículos y uno de los mejores lugares para verlo es Paperswithcode.com.
- Dividir un trabajo de investigación sobre aprendizaje automático en entradas y salidas (¿qué entra y sale de cada capa/bloque/modelo?) y capas (¿cómo manipula cada capa la entrada?) y bloques (una colección de capas) y replicar cada parte paso a paso (como lo hemos hecho en este cuaderno) puede ser muy útil para la comprensión.
- Hay modelos previamente entrenados disponibles para muchas arquitecturas de modelos de última generación y, con el poder del aprendizaje por transferencia, a menudo funcionan muy bien con pocos datos.
- Los modelos más grandes generalmente funcionan mejor, pero también ocupan más espacio (ocupan más espacio de almacenamiento y pueden tardar más en realizar inferencias).
- Una gran pregunta es: en cuanto a la implementación, ¿vale la pena o está alineado con el caso de uso el rendimiento adicional de un modelo más grande?
Ejercicios¶
Nota: Estos ejercicios requieren el uso de
torchvisionv0.13+ (lanzado en julio de 2022); las versiones anteriores pueden funcionar, pero probablemente tendrán errores.
Todos los ejercicios se centran en practicar el código anterior.
Debería poder completarlos haciendo referencia a cada sección o siguiendo los recursos vinculados.
Todos los ejercicios deben completarse utilizando código independiente del dispositivo.
Recursos:
- [Cuaderno de plantilla de ejercicios para 08] (https://github.com/mrdbourke/pytorch-deep-learning/blob/main/extras/exercises/08_pytorch_paper_replicating_exercises.ipynb).
- Cuaderno de soluciones de ejemplo para 08 (pruebe los ejercicios antes de mirar esto).
- Vea un [video tutorial de las soluciones en YouTube] en vivo (https://youtu.be/tjpW_BY8y3g) (errores y todo).
- Replica la arquitectura ViT que creamos con [capas transformadoras de PyTorch] integradas (https://pytorch.org/docs/stable/nn.html#transformer-layers).
- Querrá considerar reemplazar nuestra clase
TransformerEncoderBlock()con [torch.nn.TransformerEncoderLayer()](https://pytorch.org/docs/stable/generated/torch.nn.TransformerEncoderLayer.html #torch.nn.TransformerEncoderLayer) (contienen las mismas capas que nuestros bloques personalizados). - Puedes apilar
torch.nn.TransformerEncoderLayer()uno encima del otro con [torch.nn.TransformerEncoder()](https://pytorch.org/docs/stable/generated/torch.nn .TransformerEncoder.html#torch.nn.TransformerEncoder).
- Querrá considerar reemplazar nuestra clase
- Convierta la arquitectura ViT personalizada que creamos en un script de Python, por ejemplo,
vit.py.- Debería poder importar un modelo ViT completo usando algo como
from vit import ViT.
- Debería poder importar un modelo ViT completo usando algo como
- Entrene un modelo de extracción de funciones de ViT previamente entrenado (como el que creamos en [08. PyTorch Paper Replicating sección 10](https://www.learnpytorch.io/08_pytorch_paper_replicating/#10-bring-in-pretrained-vit-from -torchvisionmodels-on-same-dataset)) en el 20% de los datos de pizza, bistec y sushi, como el conjunto de datos que utilizamos en [07. Sección 7.3 de seguimiento de experimentos de PyTorch] (https://www.learnpytorch.io/07_pytorch_experiment_tracking/#73-download- Different-datasets).
- Vea cómo funciona en comparación con el modelo EffNetB2 con el que lo comparamos en [08. Sección 10.6 de replicación de papel de PyTorch] (https://www.learnpytorch.io/08_pytorch_paper_replicating/#106-save-feature-extractor-vit-model-and-check-file-size).
- Intente repetir los pasos del ejercicio 3, pero esta vez use los pesos previamente entrenados "
ViT_B_16_Weights.IMAGENET1K_SWAG_E2E_V1" de [torchvision.models.vit_b_16()](https://pytorch.org/vision/stable/models/ generado/torchvision.models.vit_b_16.html#torchvision.models.vit_b_16).- Nota: ViT previamente entrenado con pesos SWAG tiene un tamaño de imagen de entrada mínimo de
(384, 384)(el ViT previamente entrenado en el ejercicio 3 tiene un tamaño de entrada mínimo de(224, 224)), aunque esto es accesible en el método de pesos.transforms().
- Nota: ViT previamente entrenado con pesos SWAG tiene un tamaño de imagen de entrada mínimo de
- Nuestra arquitectura de modelo ViT personalizada imita fielmente la del documento ViT; sin embargo, nuestra receta de capacitación omite algunas cosas. Investigue algunos de los siguientes temas de la Tabla 3 en el artículo de ViT que nos perdimos y escriba una oración sobre cada uno y cómo podría ayudar con la capacitación:
*Preentrenamiento de ImageNet-21k (más datos).
- Calentamiento del ritmo de aprendizaje.
- Caída de la tasa de aprendizaje.
- Recorte de degradado.
Extracurricular¶
- Ha habido varias iteraciones y ajustes en Vision Transformer desde su lanzamiento original y los más concisos y de mejor rendimiento (a julio de 2022) se pueden ver en [Mejores líneas base de ViT simples para ImageNet-1k](https:// arxiv.org/abs/2205.01580). A pesar de las actualizaciones, nos limitamos a replicar un "Transformer Vanilla Vision" en este portátil porque si comprendes la estructura del original, puedes conectar diferentes iteraciones.
- El repositorio
vit-pytorchen GitHub de lucidrains es uno de los recursos más extensos de diferentes arquitecturas ViT implementadas en PyTorch. Es una referencia fenomenal y la utilicé a menudo para crear los materiales que hemos analizado en este capítulo. - PyTorch tiene su [implementación propia de la arquitectura ViT en GitHub] (https://github.com/pytorch/vision/blob/main/torchvision/models/vision_transformer.py), se utiliza como base de los modelos ViT previamente entrenados. en
torchvision.modelos. - Jay Alammar tiene fantásticas ilustraciones y explicaciones en su blog sobre el [mecanismo de atención] (https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/) ( la base de los modelos Transformer) y Modelos Transformer.
- Adrish Dey tiene un fantástico resumen de Layer Normalization (un componente principal de la La arquitectura ViT) puede ayudar al entrenamiento de redes neuronales.
- El mecanismo de autoatención (y autoatención de múltiples cabezales) está en el corazón de la arquitectura ViT, así como de muchas otras arquitecturas Transformer, y se introdujo originalmente en [La atención es todo lo que necesita](https:/ /arxiv.org/abs/1706.03762) documento.
- El canal de YouTube de Yannic Kilcher es un recurso sensacional para recorridos visuales de artículos; puede ver sus videos de los siguientes artículos:
- Atención es todo lo que necesita (el documento que presentó la arquitectura Transformer).
- [Una imagen vale 16 x 16 palabras: transformadores para el reconocimiento de imágenes a escala] (https://youtu.be/TrdevFK_am4) (el artículo que presentó la arquitectura ViT).