06. Aprendizaje por transferencia de PyTorch¶
Nota: Este cuaderno utiliza la nueva [API de soporte multipeso de
torchvision(disponible entorchvisionv0.13+)](https://pytorch.org/blog/introtaining-torchvision-new -api-soporte-multi-peso/).
Hasta ahora hemos construido algunos modelos a mano.
Pero su desempeño ha sido pobre.
Quizás esté pensando: ¿Existe ya un modelo de buen rendimiento para nuestro problema?
Y en el mundo del aprendizaje profundo, la respuesta suele ser sí.
Veremos cómo utilizar una poderosa técnica llamada transferir aprendizaje.
¿Qué es el aprendizaje por transferencia?¶
El aprendizaje por transferencia nos permite tomar los patrones (también llamados pesos) que otro modelo ha aprendido de otro problema y usarlos para nuestro propio problema.
Por ejemplo, podemos tomar los patrones que un modelo de visión por computadora ha aprendido de conjuntos de datos como ImageNet (millones de imágenes de diferentes objetos) y usarlos para impulsar nuestro FoodVision. Modelo mini.
O podríamos tomar los patrones de un modelo de lenguaje (un modelo que ha analizado grandes cantidades de texto para aprender una representación de lenguaje) y utilizarlos como base de un modelo para clasificar diferentes muestras de texto.
La premisa sigue siendo: encuentre un modelo existente que funcione bien y aplíquelo a su propio problema.
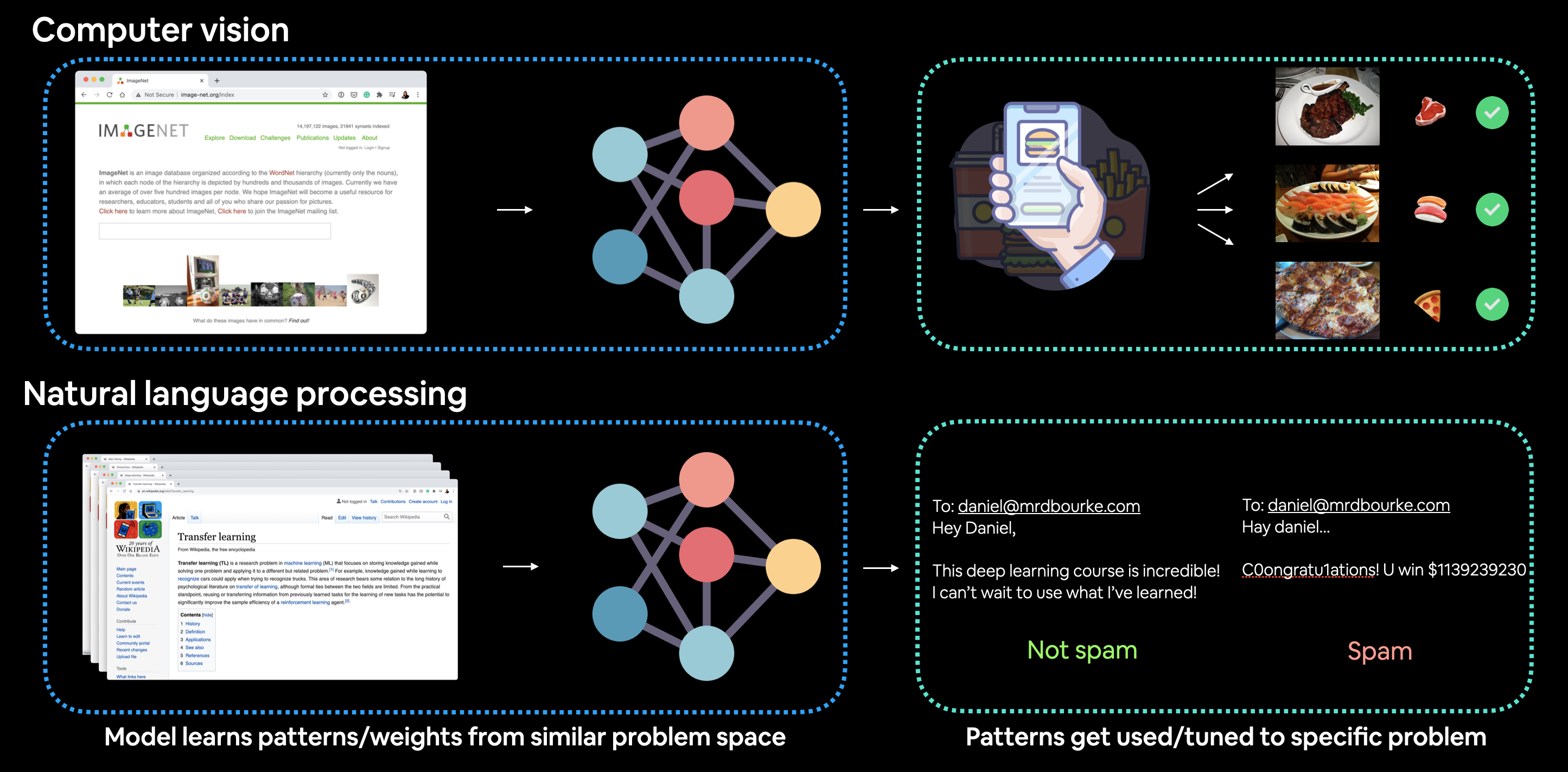
Ejemplo de aprendizaje por transferencia aplicado a la visión por computadora y al procesamiento del lenguaje natural (PLN). En el caso de la visión por computadora, un modelo de visión por computadora podría aprender patrones en millones de imágenes en ImageNet y luego usar esos patrones para inferir otro problema. Y para la PNL, un modelo de lenguaje puede aprender la estructura del lenguaje leyendo toda Wikipedia (y quizás más) y luego aplicar ese conocimiento a un problema diferente.
¿Por qué utilizar el aprendizaje por transferencia?¶
Hay dos beneficios principales al utilizar el aprendizaje por transferencia:
- Puede aprovechar un modelo existente (generalmente una arquitectura de red neuronal) que ha demostrado funcionar en problemas similares al nuestro.
- Puede aprovechar un modelo funcional que ya ha aprendido patrones sobre datos similares a los nuestros. Esto a menudo da como resultado excelentes resultados con menos datos personalizados.
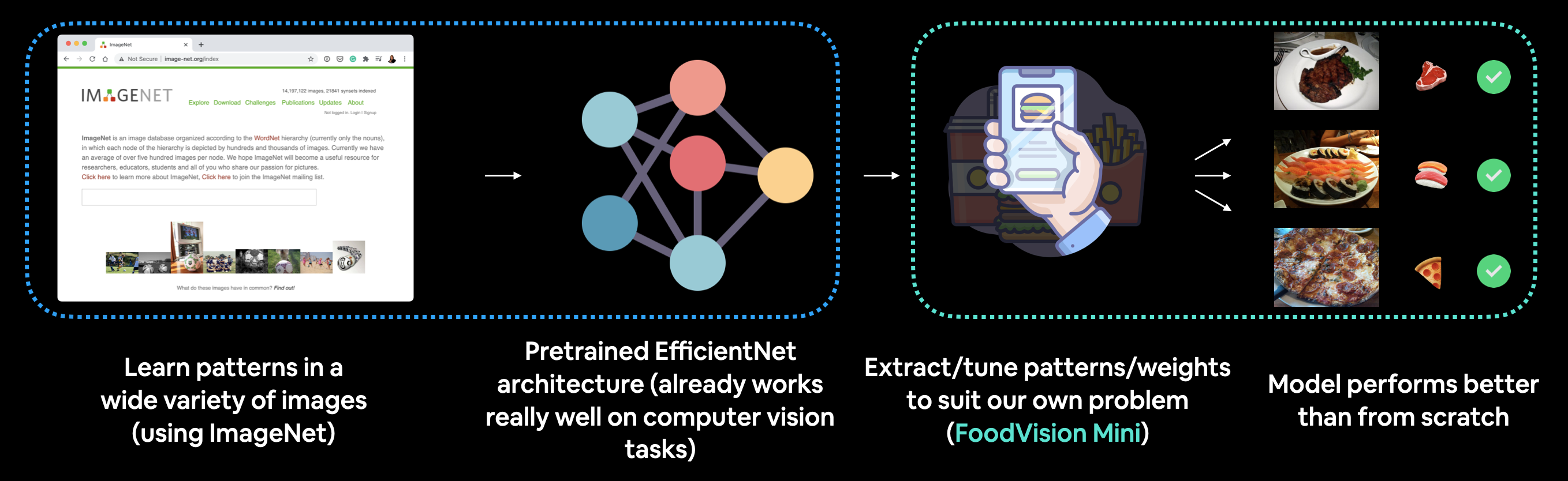
Los pondremos a prueba para nuestro problema FoodVision Mini, tomaremos un modelo de visión por computadora previamente entrenado en ImageNet e intentaremos aprovechar sus representaciones aprendidas subyacentes para clasificar imágenes de pizza, bistec y sushi.
Tanto la investigación como la práctica también respaldan el uso del aprendizaje por transferencia.
Un hallazgo de un artículo de investigación reciente sobre aprendizaje automático recomendó que los profesionales utilicen el aprendizaje por transferencia siempre que sea posible.

Un estudio sobre los efectos de si entrenar desde cero o utilizar el aprendizaje por transferencia era mejor desde el punto de vista de un profesional, encontró que el aprendizaje por transferencia era mucho más beneficioso en términos de costo y tiempo. Fuente: ¿Cómo entrenar tu ViT? Datos, aumento y regularización en Vision Transformers sección 6 del artículo (conclusión).
Y Jeremy Howard (fundador de fastai) es un gran defensor del aprendizaje por transferencia.
Las cosas que realmente marcan la diferencia (aprendizaje por transferencia), si podemos hacerlo mejor en el aprendizaje por transferencia, es algo que cambiará el mundo. De repente, mucha más gente puede realizar un trabajo de primer nivel con menos recursos y menos datos. — [Jeremy Howard en el podcast de Lex Fridman] (https://youtu.be/Bi7f1JSSlh8?t=72)
Dónde encontrar modelos previamente entrenados¶
El mundo del aprendizaje profundo es un lugar asombroso.
Es tan sorprendente que muchas personas alrededor del mundo comparten su trabajo.
A menudo, el código y los modelos previamente entrenados para las últimas investigaciones de vanguardia se publican a los pocos días de su publicación.
Y hay varios lugares donde puede encontrar modelos previamente entrenados para utilizarlos en sus propios problemas.
| Ubicación | ¿Qué hay ahí? | Enlace(s) |
|---|---|---|
| Bibliotecas de dominio PyTorch | Cada una de las bibliotecas de dominio de PyTorch (torchvision, torchtext) viene con modelos previamente entrenados de algún tipo. Los modelos allí funcionan directamente dentro de PyTorch. |
torchvision.models, torchtext.models, torchaudio.models, torchrec.models |
| HuggingFace Hub | Una serie de modelos previamente entrenados en muchos dominios diferentes (visión, texto, audio y más) de organizaciones de todo el mundo. También hay muchos conjuntos de datos diferentes. | https://huggingface.co/models, https://huggingface.co/datasets |
Biblioteca timm (modelos de imágenes PyTorch) |
Casi todos los modelos de visión por computadora más recientes y mejores en código PyTorch, así como muchas otras funciones útiles de visión por computadora. | https://github.com/rwightman/pytorch-image-models |
| Papelesconcódigo | Una colección de los últimos artículos sobre aprendizaje automático con implementaciones de código adjuntas. También puede encontrar aquí puntos de referencia del rendimiento del modelo en diferentes tareas. | https://paperswithcode.com/ |
Con acceso a recursos de alta calidad como los anteriores, debería ser una práctica común al comienzo de cada problema de aprendizaje profundo que asuma preguntar: "¿Existe un modelo previamente entrenado para mi problema?"
Ejercicio: Dedique 5 minutos a revisar
torchvision.models, así como a la [página de modelos de HuggingFace Hub](https: //huggingface.co/models), ¿qué encuentras? (aquí no hay respuestas correctas, es solo para practicar la exploración)
Qué vamos a cubrir¶
Tomaremos un modelo previamente entrenado de torchvision.models y lo personalizaremos para que funcione (y con suerte mejore) nuestro problema FoodVision Mini.
| Tema | Contenido |
|---|---|
| 0. Obteniendo configuración | Hemos escrito bastante código útil en las últimas secciones, descarguémoslo y asegurémonos de poder usarlo nuevamente. |
| 1. Obtener datos | Obtengamos el conjunto de datos de clasificación de imágenes de pizza, bistec y sushi que hemos estado usando para intentar mejorar los resultados de nuestro modelo. |
| 2. Crear conjuntos de datos y cargadores de datos | Usaremos el script data_setup.py que escribimos en el capítulo 05. PyTorch se vuelve modular para configurar nuestros DataLoaders. |
| 3. Obtenga y personalice un modelo previamente entrenado | Aquí descargaremos un modelo previamente entrenado desde torchvision.models y lo personalizaremos según nuestro propio problema. |
| 4. Modelo de tren | Veamos cómo funciona el nuevo modelo previamente entrenado en nuestro conjunto de datos de pizza, bistec y sushi. Usaremos las funciones de entrenamiento que creamos en el capítulo anterior. |
| 5. Evalúe el modelo trazando curvas de pérdidas | ¿Cómo fue nuestro primer modelo de aprendizaje por transferencia? ¿Se ajustaba demasiado o no? |
| 6. Haga predicciones sobre imágenes del conjunto de prueba | Una cosa es comprobar las métricas de evaluación de un modelo, pero otra cosa es ver sus predicciones en muestras de prueba. ¡visualicemos, visualicemos, visualicemos! |
¿Dónde puedes obtener ayuda?¶
Todos los materiales de este curso están disponibles en GitHub.
Si tiene problemas, puede hacer una pregunta en el curso [página de debates de GitHub] (https://github.com/mrdbourke/pytorch-deep-learning/discussions).
Y, por supuesto, está la documentación de PyTorch y los foros de desarrolladores de PyTorch, un lugar muy útil para todo lo relacionado con PyTorch.
0. Configuración¶
Comencemos importando/descargando los módulos necesarios para esta sección.
Para ahorrarnos escribir código adicional, aprovecharemos algunos de los scripts de Python (como data_setup.py y engine.py) que creamos en la sección anterior, 05. PyTorch se vuelve modular.
Específicamente, vamos a descargar el directorio going_modular del repositorio pytorch-deep-learning (si aún no lo tenemos).
También obtendremos el paquete torchinfo si no está disponible.
torchinfo nos ayudará más adelante a darnos una representación visual de nuestro modelo.
Nota: A partir de junio de 2022, este cuaderno utiliza las versiones nocturnas de
torchytorchvision, ya que se requieretorchvisionv0.13+ para usar la API de pesos múltiples actualizada. Puede instalarlos usando el siguiente comando.
# Para que este portátil se ejecute con API actualizadas, necesitamos torch 1.12+ y torchvision 0.13+.
try:
import torch
import torchvision
assert int(torch.__version__.split(".")[1]) >= 12, "torch version should be 1.12+"
assert int(torchvision.__version__.split(".")[1]) >= 13, "torchvision version should be 0.13+"
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
except:
print(f"[INFO] torch/torchvision versions not as required, installing nightly versions.")
!pip3 install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
import torch
import torchvision
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
# Continuar con las importaciones regulares
import matplotlib.pyplot as plt
import torch
import torchvision
from torch import nn
from torchvision import transforms
# Intente obtener torchinfo, instálelo si no funciona
try:
from torchinfo import summary
except:
print("[INFO] Couldn't find torchinfo... installing it.")
!pip install -q torchinfo
from torchinfo import summary
# Intente importar el directorio going_modular, descárguelo de GitHub si no funciona
try:
from going_modular.going_modular import data_setup, engine
except:
# Get the going_modular scripts
print("[INFO] Couldn't find going_modular scripts... downloading them from GitHub.")
!git clone https://github.com/mrdbourke/pytorch-deep-learning
!mv pytorch-deep-learning/going_modular .
!rm -rf pytorch-deep-learning
from going_modular.going_modular import data_setup, engine
Ahora configuremos el código independiente del dispositivo.
Nota: Si estás usando Google Colab y aún no tienes una GPU activada, ahora es el momento de activar una a través de
Runtime -> Cambiar tipo de tiempo de ejecución -> Acelerador de hardware -> GPU.
# Configurar código independiente del dispositivo
device = "cuda" if torch.cuda.is_available() else "cpu"
device
1. Obtener datos¶
Antes de que podamos comenzar a utilizar transferencia de aprendizaje, necesitaremos un conjunto de datos.
Para ver cómo se compara el aprendizaje por transferencia con nuestros intentos anteriores de creación de modelos, descargaremos el mismo conjunto de datos que hemos estado usando para FoodVision Mini.
Escribamos un código para descargar el conjunto de datos pizza_steak_sushi.zip del curso GitHub y luego descomprímalo. .
También podemos asegurarnos de que si ya tenemos los datos, no se vuelvan a descargar.
import os
import zipfile
from pathlib import Path
import requests
# Ruta de configuración a la carpeta de datos
data_path = Path("data/")
image_path = data_path / "pizza_steak_sushi"
# Si la carpeta de imágenes no existe, descárgala y prepárala...
if image_path.is_dir():
print(f"{image_path} directory exists.")
else:
print(f"Did not find {image_path} directory, creating one...")
image_path.mkdir(parents=True, exist_ok=True)
# Download pizza, steak, sushi data
with open(data_path / "pizza_steak_sushi.zip", "wb") as f:
request = requests.get("https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip")
print("Downloading pizza, steak, sushi data...")
f.write(request.content)
# Unzip pizza, steak, sushi data
with zipfile.ZipFile(data_path / "pizza_steak_sushi.zip", "r") as zip_ref:
print("Unzipping pizza, steak, sushi data...")
zip_ref.extractall(image_path)
# Remove .zip file
os.remove(data_path / "pizza_steak_sushi.zip")
¡Excelente!
Ahora tenemos el mismo conjunto de datos que hemos estado usando anteriormente, una serie de imágenes de pizza, bistec y sushi en formato de clasificación de imágenes estándar.
Ahora creemos rutas a nuestros directorios de capacitación y pruebas.
# Directorios de configuración
train_dir = image_path / "train"
test_dir = image_path / "test"
2. Crear conjuntos de datos y cargadores de datos¶
Como hemos descargado el directorio going_modular, podemos usar data_setup.py script que creamos en la sección 05. PyTorch Going Modular para preparar y configurar nuestros DataLoaders.
Pero como usaremos un modelo previamente entrenado de torchvision.models, hay una transformación específica que necesitamos para preparar nuestras imágenes primero.
2.1 Creando una transformación para torchvision.models (creación manual)¶
Nota: A partir de
torchvisionv0.13+, hay una actualización sobre cómo se pueden crear transformaciones de datos usandotorchvision.models. Llamé al método anterior "creación manual" y al nuevo método "creación automática". Este cuaderno muestra ambos.
Cuando se utiliza un modelo previamente entrenado, es importante que los datos personalizados que se incluyen en el modelo se preparen de la misma manera que los datos de entrenamiento originales que se incluyeron en el modelo.
Antes de torchvision v0.13+, para crear una transformación para un modelo previamente entrenado en torchvision.models, la documentación decía:
Todos los modelos previamente entrenados esperan imágenes de entrada normalizadas de la misma manera, es decir, minilotes de imágenes de forma RGB de 3 canales (3 x H x W), donde se espera que H y W sean al menos 224.
Las imágenes deben cargarse en un rango de
[0, 1]y luego normalizarse usandomean = [0.485, 0.456, 0.406]ystd = [0.229, 0.224, 0.225].Puedes usar la siguiente transformación para normalizar:
normalizar = transforma.Normalizar(media=[0.485, 0.456, 0.406], estándar=[0,229, 0,224, 0,225])
La buena noticia es que podemos lograr las transformaciones anteriores con una combinación de:
| Número de transformación | Se requiere transformación | Código para realizar la transformación |
|---|---|---|
| 1 | Minilotes de tamaño [batch_size, 3, height, width] donde la altura y el ancho son al menos 224x224^. |
torchvision.transforms.Resize() para cambiar el tamaño de las imágenes a [3, 224, 224]^ y torch.utils.data.DataLoader() para crear lotes de imágenes. |
| 2 | Valores entre 0 y 1. | torchvision.transforms.ToTensor() |
| 3 | Una media de [0,485, 0,456, 0,406] (valores en cada canal de color). |
torchvision.transforms.Normalize(mean=...) para ajustar la media de nuestras imágenes. |
| 4 | Una desviación estándar de "[0,229, 0,224, 0,225]" (valores en cada canal de color). | torchvision.transforms.Normalize(std=...) para ajustar la desviación estándar de nuestras imágenes. |
Nota: ^algunos modelos previamente entrenados desde
torchvision.modelsen diferentes tamaños hasta[3, 224, 224], por ejemplo, algunos podrían tomarlos en[3, 240, 240]. Para tamaños de imagen de entrada específicos, consulte la documentación.
Pregunta: ¿De dónde provienen los valores de media y desviación estándar? ¿Por qué necesitamos hacer esto?
Estos fueron calculados a partir de los datos. Específicamente, el conjunto de datos ImageNet toma las medias y las desviaciones estándar de un subconjunto de imágenes.
Tampoco necesitamos hacer esto. Las redes neuronales suelen ser bastante capaces de determinar distribuciones de datos apropiadas (calcularán por sí mismas dónde deben estar la media y las desviaciones estándar), pero establecerlas desde el principio puede ayudar a nuestras redes a lograr un mejor rendimiento más rápido.
Compongamos una serie de torchvision.transforms para realizar los pasos anteriores.
# Cree una canalización de transformaciones manualmente (requerido para torchvision <0.13)
manual_transforms = transforms.Compose([
transforms.Resize((224, 224)), # 1. Reshape all images to 224x224 (though some models may require different sizes)
transforms.ToTensor(), # 2. Turn image values to between 0 & 1
transforms.Normalize(mean=[0.485, 0.456, 0.406], # 3. A mean of [0.485, 0.456, 0.406] (across each colour channel)
std=[0.229, 0.224, 0.225]) # 4. A standard deviation of [0.229, 0.224, 0.225] (across each colour channel),
])
¡Maravilloso!
Ahora que tenemos una serie de transformaciones creadas manualmente lista para preparar nuestras imágenes, creemos DataLoaders de entrenamiento y prueba.
Podemos crearlos usando la función create_dataloaders desde el script data_setup.py creado en 05. PyTorch se vuelve modular, parte 2.
Estableceremos batch_size=32 para que nuestro modelo vea minilotes de 32 muestras a la vez.
Y podemos transformar nuestras imágenes usando el canal de transformación que creamos anteriormente configurando transform=manual_transforms.
Nota: He incluido esta creación manual de transformaciones en este cuaderno porque es posible que encuentres recursos que utilicen este estilo. También es importante tener en cuenta que debido a que estas transformaciones se crean manualmente, también son infinitamente personalizables. Entonces, si quisiera incluir técnicas de aumento de datos en su proceso de transformación, podría hacerlo.
# Cree cargadores de datos de entrenamiento y prueba y obtenga una lista de nombres de clases
train_dataloader, test_dataloader, class_names = data_setup.create_dataloaders(train_dir=train_dir,
test_dir=test_dir,
transform=manual_transforms, # resize, convert images to between 0 & 1 and normalize them
batch_size=32) # set mini-batch size to 32
train_dataloader, test_dataloader, class_names
2.2 Creando una transformación para torchvision.models (creación automática)¶
Como se indicó anteriormente, cuando se utiliza un modelo previamente entrenado, es importante que los datos personalizados que se ingresan en el modelo se preparen de la misma manera que los datos de entrenamiento originales que se ingresaron en el modelo.
Arriba vimos cómo crear manualmente una transformación para un modelo previamente entrenado.
Pero a partir de torchvision v0.13+, se agregó una función de creación de transformación automática.
Cuando configura un modelo desde torchvision.models y selecciona los pesos del modelo previamente entrenado que le gustaría usar, por ejemplo, digamos que nos gustaría usar:
pitón
pesos = torchvision.models.EfficientNet_B0_Weights.DEFAULT
Dónde,
EfficientNet_B0_Weightsson los pesos de la arquitectura del modelo que nos gustaría usar (hay muchas opciones diferentes de arquitectura de modelo entorchvision.models).DEFAULTsignifica los mejores pesos disponibles (el mejor rendimiento en ImageNet).- Nota: Dependiendo de la arquitectura del modelo que elija, también puede ver otras opciones como
IMAGENET_V1eIMAGENET_V2, donde generalmente cuanto mayor sea el número de versión, mejor. Aunque si desea lo mejor disponible, "DEFAULT" es la opción más sencilla. Consulte la documentacióntorchvision.modelspara obtener más información.
- Nota: Dependiendo de la arquitectura del modelo que elija, también puede ver otras opciones como
Probémoslo.
# Obtenga un conjunto de pesos de modelo previamente entrenados
weights = torchvision.models.EfficientNet_B0_Weights.DEFAULT # .DEFAULT = best available weights from pretraining on ImageNet
weights
Y ahora para acceder a las transformaciones asociadas con nuestros pesos, podemos usar el método transforms().
Básicamente, esto significa "obtener las transformaciones de datos que se utilizaron para entrenar EfficientNet_B0_Weights en ImageNet".
# Obtenga las transformaciones utilizadas para crear nuestros pesos previamente entrenados.
auto_transforms = weights.transforms()
auto_transforms
Observe cómo auto_transforms es muy similar a manual_transforms, la única diferencia es que auto_transforms vino con la arquitectura del modelo que elegimos, mientras que tuvimos que crear manual_transforms a mano.
El beneficio de crear automáticamente una transformación a través de weights.transforms() es que garantiza que está utilizando la misma transformación de datos que el modelo previamente entrenado que se usó cuando se entrenó.
Sin embargo, la desventaja de utilizar transformaciones creadas automáticamente es la falta de personalización.
Podemos usar auto_transforms para crear DataLoaders con create_dataloaders() tal como antes.
# Cree cargadores de datos de entrenamiento y prueba y obtenga una lista de nombres de clases
train_dataloader, test_dataloader, class_names = data_setup.create_dataloaders(train_dir=train_dir,
test_dir=test_dir,
transform=auto_transforms, # perform same data transforms on our own data as the pretrained model
batch_size=32) # set mini-batch size to 32
train_dataloader, test_dataloader, class_names
3. Obtener un modelo previamente entrenado¶
Muy bien, ¡aquí viene la parte divertida!
En los últimos cuadernos hemos estado construyendo redes neuronales PyTorch desde cero.
Y si bien es una buena habilidad, nuestros modelos no han funcionado tan bien como nos gustaría.
Ahí es donde entra en juego la transferencia de aprendizaje.
La idea general del aprendizaje por transferencia es tomar un modelo que ya funciona bien en un espacio de problemas similar al suyo y luego personalizarlo según su caso de uso.
Dado que estamos trabajando en un problema de visión por computadora (clasificación de imágenes con FoodVision Mini), podemos encontrar modelos de clasificación previamente entrenados en torchvision.models.
Al explorar la documentación, encontrará muchos pilares de arquitectura de visión por computadora comunes, como:
| La columna vertebral de la arquitectura | Código |
|---|---|
| ResNet's | torchvision.models.resnet18(), torchvision.models.resnet50()... |
| VGG (similar a lo que usamos para TinyVGG) | torchvision.models.vgg16() |
| EfficientNet's | torchvision.models.ficientnet_b0(), torchvision.models.ficientnet_b1()... |
| VisionTransformer (ViT) | torchvision.models.vit_b_16(), torchvision.models.vit_b_32()... |
| ConvNeXt | torchvision.models.convnext_tiny(), torchvision.models.convnext_small()... |
Más disponible en torchvision.models |
modelos.torchvision... |
3.1 ¿Qué modelo previamente entrenado debería utilizar?¶
Depende de su problema/del dispositivo con el que esté trabajando.
Generalmente, el número más alto en el nombre del modelo (por ejemplo, ficientnet_b0() -> ficientnet_b1() -> ficientnet_b7()) significa mejor rendimiento pero un modelo más grande.
Se podría pensar que un mejor rendimiento es siempre mejor, ¿verdad?
Eso es cierto, pero algunos modelos de mejor rendimiento son demasiado grandes para algunos dispositivos.
Por ejemplo, supongamos que desea ejecutar su modelo en un dispositivo móvil, tendrá que tener en cuenta los recursos informáticos limitados del dispositivo, por lo que buscará un modelo más pequeño.
Pero si tienes un poder de cómputo ilimitado, como afirma The Bitter Lesson, probablemente elegirás el modelo más grande y con mayor necesidad de cómputo que puedas. poder.
Comprender esta compensación entre rendimiento, velocidad y tamaño llegará con el tiempo y la práctica.
Para mí, he encontrado un buen equilibrio en los modelos ficientnet_bX.
A partir de mayo de 2022, Nutrify (la aplicación basada en aprendizaje automático en la que estoy trabajando) funciona con un ficientnet_b0.
Comma.ai (una empresa que fabrica software de código abierto para vehículos autónomos) [utiliza un ficientnet_b2](https://geohot.github.io/blog/jekyll/ update/2021/10/29/an-architecture-for-life.html) para conocer una representación de la carretera.
Nota: Aunque estamos usando
ficientnet_bX, es importante no apegarse demasiado a ninguna arquitectura en particular, ya que siempre cambian a medida que se publican nuevas investigaciones. Lo mejor es experimentar, experimentar, experimentar y ver qué funciona para su problema.
3.2 Configurar un modelo previamente entrenado¶
El modelo previamente entrenado que usaremos es torchvision.models.ficientnet_b0().
La arquitectura es del artículo EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.
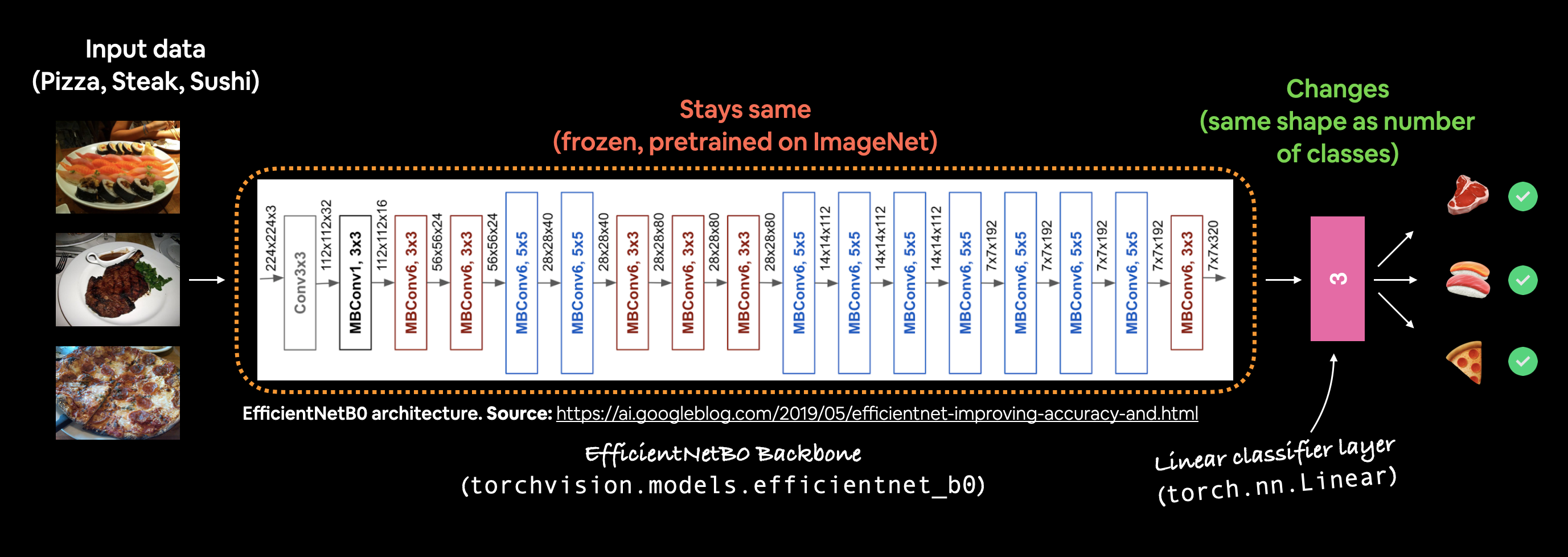
Ejemplo de lo que vamos a crear, un modelo EfficientNet_B0 previamente entrenado de torchvision.models con la capa de salida ajustada para nuestro caso de uso de clasificación de imágenes de pizza, bistec y sushi.
Podemos configurar los pesos de ImageNet previamente entrenados en EfficientNet_B0 usando el mismo código que usamos para crear las transformaciones.
pitón
pesos = torchvision.models.EfficientNet_B0_Weights.DEFAULT # .DEFAULT = mejores pesos disponibles para ImageNet
Esto significa que el modelo ya ha sido entrenado en millones de imágenes y tiene una buena representación base de los datos de las imágenes.
La versión PyTorch de este modelo previamente entrenado es capaz de lograr una precisión de ~77,7% en las 1000 clases de ImageNet.
También lo enviaremos al dispositivo de destino.
# ANTIGUO: configure el modelo con pesos previamente entrenados y envíelo al dispositivo de destino (esto era antes de torchvision v0.13)
# model = torchvision.models.ficientnet_b0(pretrained=True).to(device) # Método ANTIGUO (con pretrained=True)
# NUEVO: Configure el modelo con pesas previamente entrenadas y envíelo al dispositivo de destino (torchvision v0.13+)
weights = torchvision.models.EfficientNet_B0_Weights.DEFAULT # .DEFAULT = best available weights
model = torchvision.models.efficientnet_b0(weights=weights).to(device)
# modelo # descomentar en la salida (es muy largo)
Nota: En versiones anteriores de
torchvision, se creaba un modelo previamente entrenado con código como:
modelo = torchvision.models.ficientnet_b0(preentrenado=True).to(dispositivo)Sin embargo, ejecutar esto usando
torchvisionv0.13+ resultará en errores como los siguientes:
Advertencia de usuario: el parámetro 'preentrenado' está obsoleto desde 0.13 y se eliminará en 0.15; utilice 'pesos' en su lugar.Y...
`Advertencia de usuario: Los argumentos distintos de una enumeración de peso o Ninguno para los pesos están obsoletos desde 0.13 y se eliminarán en 0.15. El comportamiento actual es equivalente a pasar pesos=EfficientNet_B0_Weights.IMAGENET1K_V1. También puede utilizar Weights=EfficientNet_B0_Weights.DEFAULT para obtener los pesos más actualizados.
Si imprimimos el modelo, obtenemos algo similar a lo siguiente:
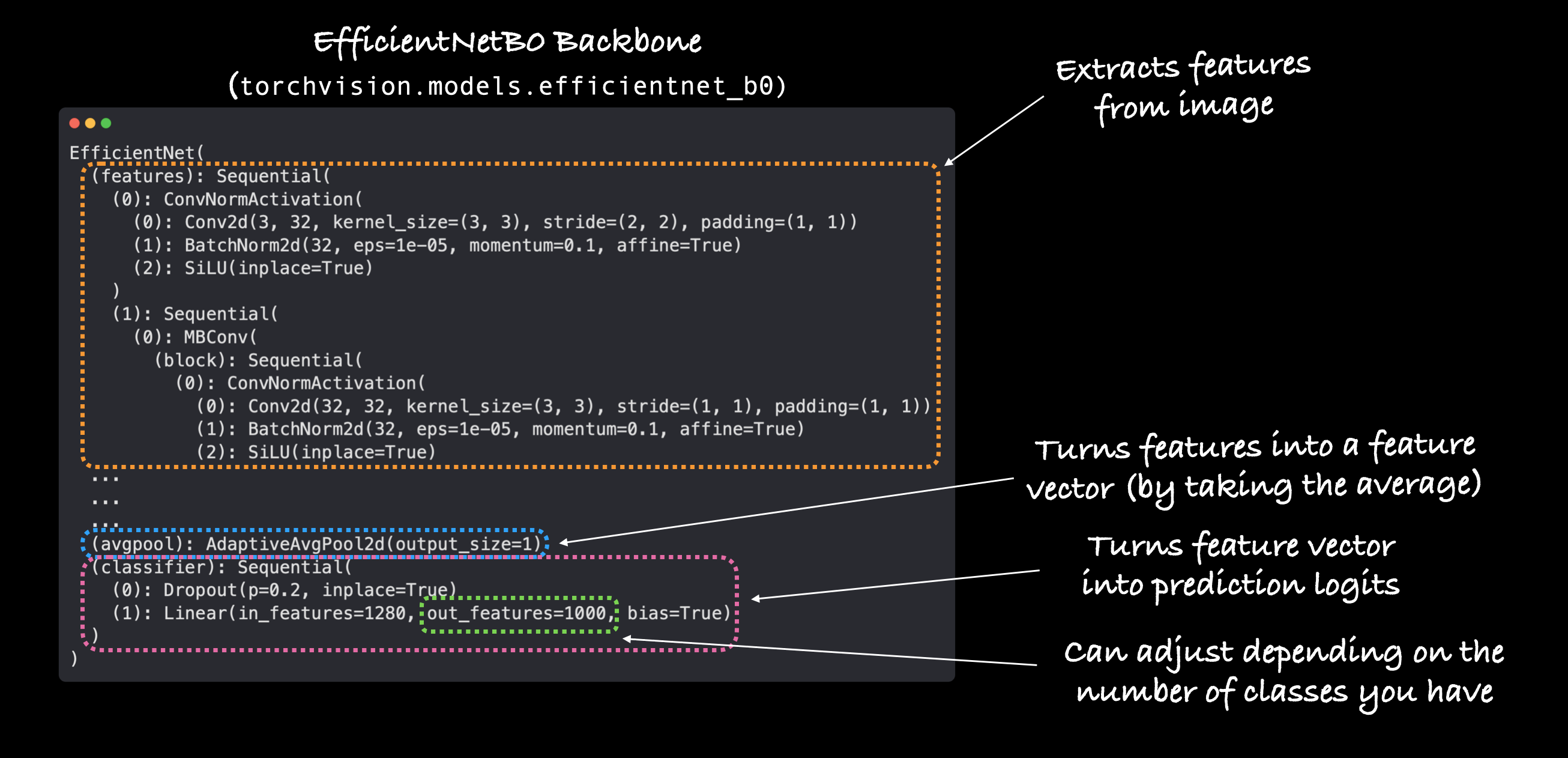
Montones, montones, montones de capas.
Este es uno de los beneficios del aprendizaje por transferencia: tomar un modelo existente, que ha sido elaborado por algunos de los mejores ingenieros del mundo y aplicarlo a su propio problema.
Nuestro ficientnet_b0 se compone de tres partes principales:
características: una colección de capas convolucionales y otras capas de activación para aprender una representación base de los datos de visión (esta representación/colección base de capas a menudo se denomina características o extractor de características, "las capas base del modelo aprenden las diferentes características de las imágenes").avgpool: toma el promedio de la salida de las capas decaracterísticasy lo convierte en un vector de características.classifier: convierte el vector de características en un vector con la misma dimensionalidad que el número de clases de salida requeridas (ya queficientnet_b0está preentrenado en ImageNet y debido a que ImageNet tiene 1000 clases,out_features=1000es el valor por defecto).
3.3 Obteniendo un resumen de nuestro modelo con torchinfo.summary()¶
Para obtener más información sobre nuestro modelo, usemos el método [summary()] de torchinfo (https://github.com/TylerYep/torchinfo#documentation).
Para hacerlo, pasaremos:
model: el modelo del que nos gustaría obtener un resumen.input_size- la forma de los datos que nos gustaría pasar a nuestro modelo, para el caso deficientnet_b0, el tamaño de entrada es(batch_size, 3, 224, 224), aunque otras variantes deeficientenet_bXtiene diferentes tamaños de entrada.- Nota: Muchos modelos modernos pueden manejar imágenes de entrada de diferentes tamaños gracias a [
torch.nn.AdaptiveAvgPool2d()](https://pytorch.org/docs/stable/generated/torch.nn.AdaptiveAvgPool2d .html), esta capa ajusta de forma adaptativa eloutput_sizede una entrada determinada según sea necesario. Puede probar esto pasando imágenes de entrada de diferentes tamaños asummary()o a sus modelos.
- Nota: Muchos modelos modernos pueden manejar imágenes de entrada de diferentes tamaños gracias a [
col_names: las diversas columnas de información que nos gustaría ver sobre nuestro modelo.col_width: qué ancho deben tener las columnas para el resumen.row_settings: qué funciones mostrar en una fila.
# Imprima un resumen usando torchinfo (descomente el resultado real)
summary(model=model,
input_size=(32, 3, 224, 224), # make sure this is "input_size", not "input_shape"
# col_names=["input_size"], # uncomment for smaller output
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"]
)
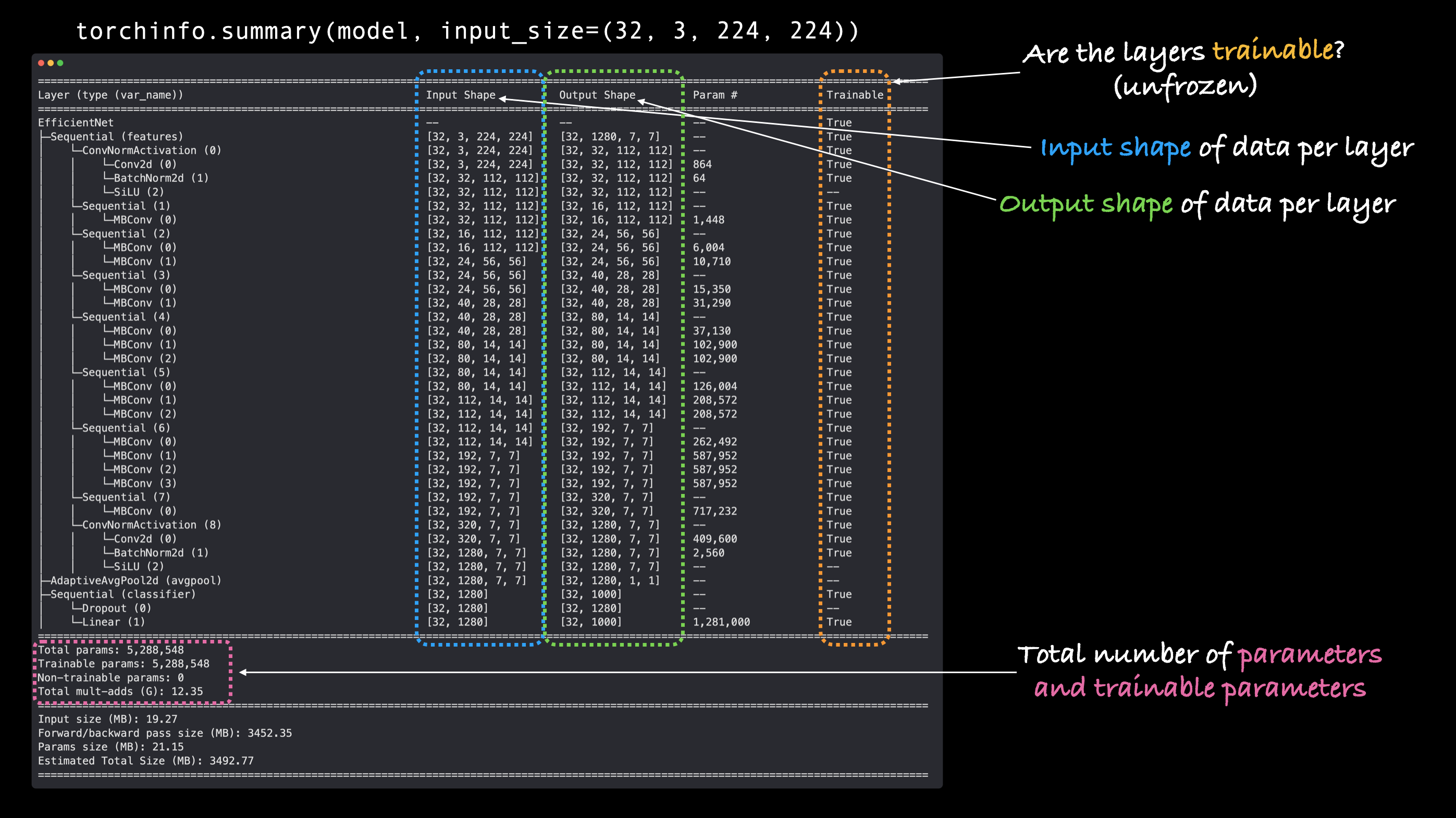
¡Guau!
¡Ese sí que es un gran modelo!
Desde el resultado del resumen, podemos ver todos los diversos cambios de forma de entrada y salida a medida que los datos de nuestra imagen pasan por el modelo.
Y hay muchos más parámetros totales (pesos previamente entrenados) para reconocer diferentes patrones en nuestros datos.
Como referencia, nuestro modelo de secciones anteriores, TinyVGG, tenía 8.083 parámetros frente a 5.288.548 parámetros para ficientnet_b0, ¡un aumento de ~654x!
¿Qué opinas? ¿Esto significará un mejor rendimiento?
3.4 Congelar el modelo base y cambiar la capa de salida para adaptarla a nuestras necesidades¶
El proceso de aprendizaje por transferencia suele ser el siguiente: congelar algunas capas base de un modelo previamente entrenado (normalmente la sección "características") y luego ajustar las capas de salida (también llamadas capas principales/clasificadoras) para satisfacer sus necesidades.
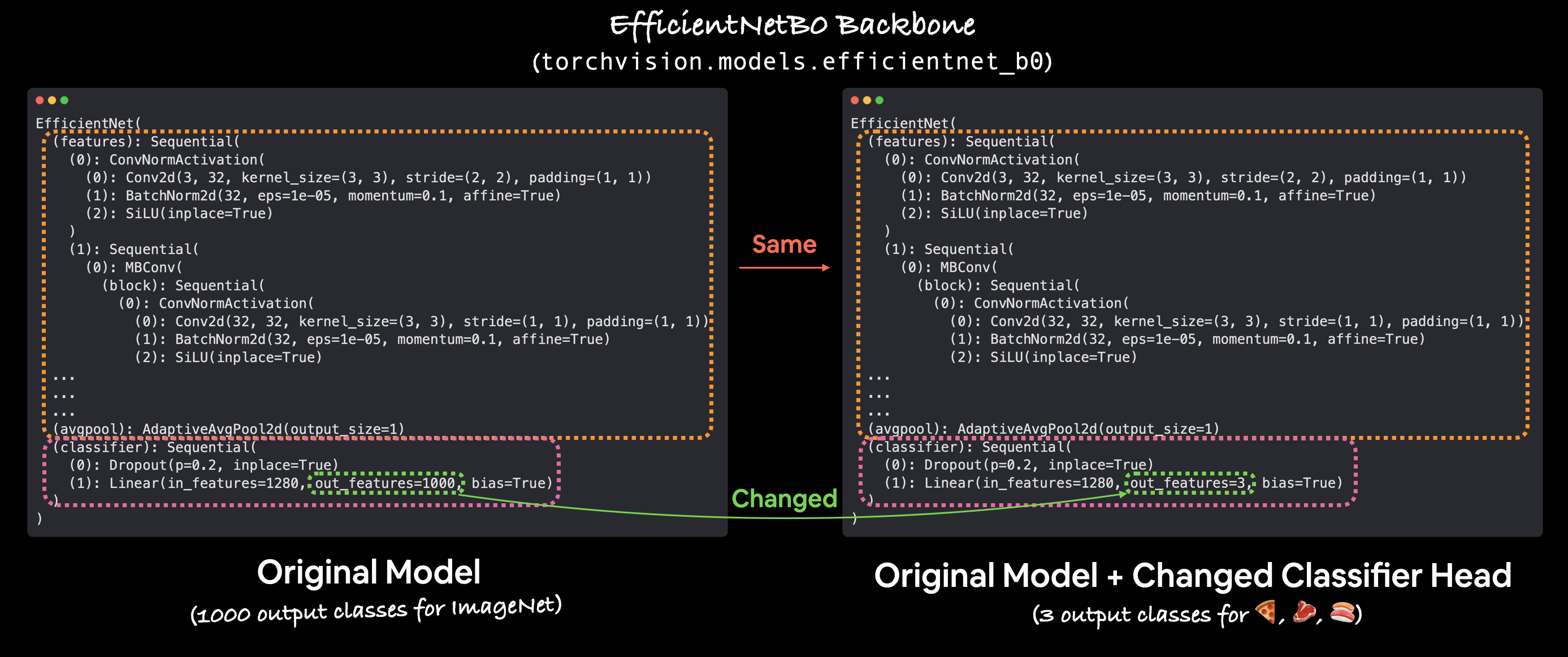
Puede personalizar las salidas de un modelo previamente entrenado cambiando las capas de salida para adaptarlas a su problema. El torchvision.models.ficientnet_b0() original viene con out_features=1000 porque hay 1000 clases en ImageNet, el conjunto de datos en el que se entrenó. Sin embargo, para nuestro problema de clasificar imágenes de pizza, bistec y sushi solo necesitamos out_features=3.
Congelemos todas las capas/parámetros en la sección "características" de nuestro modelo "ficientnet_b0".
Nota: Congelar capas significa mantenerlas como están durante el entrenamiento. Por ejemplo, si su modelo tiene capas previamente entrenadas, congelarlas sería decir: "no cambie ninguno de los patrones en estas capas durante el entrenamiento, manténgalos como están". En esencia, nos gustaría mantener los pesos/patrones previamente entrenados que nuestro modelo ha aprendido de ImageNet como columna vertebral y luego solo cambiar las capas de salida.
Podemos congelar todas las capas/parámetros en la sección "características" configurando el atributo "requires_grad=False".
Para los parámetros con requires_grad=False, PyTorch no realiza un seguimiento de las actualizaciones de gradiente y, a su vez, nuestro optimizador no cambiará estos parámetros durante el entrenamiento.
En esencia, un parámetro con requires_grad=False es "no entrenable" o "congelado" en su lugar.
# Congele todas las capas base en la sección "características" del modelo (el extractor de características) configurando require_grad=False
for param in model.features.parameters():
param.requires_grad = False
¡Características capas extractoras congeladas!
Ahora ajustemos la capa de salida o la parte del "clasificador" de nuestro modelo previamente entrenado a nuestras necesidades.
En este momento, nuestro modelo previamente entrenado tiene out_features=1000 porque hay 1000 clases en ImageNet.
Sin embargo, no tenemos 1000 clases, solo tenemos tres: pizza, bistec y sushi.
Podemos cambiar la parte "clasificador" de nuestro modelo creando una nueva serie de capas.
El "clasificador" actual consta de:
(clasificador): Secuencial(
(0): Abandono(p=0,2, in situ=Verdadero)
(1): Lineal (in_features=1280, out_features=1000, sesgo=Verdadero)
Mantendremos la capa Dropout igual usando [torch.nn.Dropout(p=0.2, inplace=True)](https://pytorch.org/docs/stable/generated/torch.nn.Dropout .html).
Nota: Capas de abandono elimina aleatoriamente conexiones entre dos capas de redes neuronales con una probabilidad de "p". Por ejemplo, si
p=0.2, el 20% de las conexiones entre capas de la red neuronal se eliminarán aleatoriamente en cada pasada. Esta práctica está destinada a ayudar a regularizar (evitar el sobreajuste) un modelo asegurándose de que las conexiones que quedan aprendan características para compensar la eliminación de las otras conexiones (con suerte, estas características restantes son más generales).
Y mantendremos in_features=1280 para nuestra capa de salida Lineal pero cambiaremos el valor out_features a la longitud de nuestros class_names (len(['pizza', 'steak', 'sushi ']) = 3).
Nuestra nueva capa "clasificador" debería estar en el mismo dispositivo que nuestro "modelo".
# Colocar las semillas manuales.
torch.manual_seed(42)
torch.cuda.manual_seed(42)
# Obtenga la longitud de class_names (una unidad de salida para cada clase)
output_shape = len(class_names)
# Vuelva a crear la capa del clasificador y siémbrela en el dispositivo de destino.
model.classifier = torch.nn.Sequential(
torch.nn.Dropout(p=0.2, inplace=True),
torch.nn.Linear(in_features=1280,
out_features=output_shape, # same number of output units as our number of classes
bias=True)).to(device)
¡Lindo!
Capa de salida actualizada, obtengamos otro resumen de nuestro modelo y veamos qué ha cambiado.
# # Hacer un resumen *después* de congelar las características y cambiar la capa del clasificador de salida (descomentar para la salida real)
summary(model,
input_size=(32, 3, 224, 224), # make sure this is "input_size", not "input_shape" (batch_size, color_channels, height, width)
verbose=0,
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"]
)
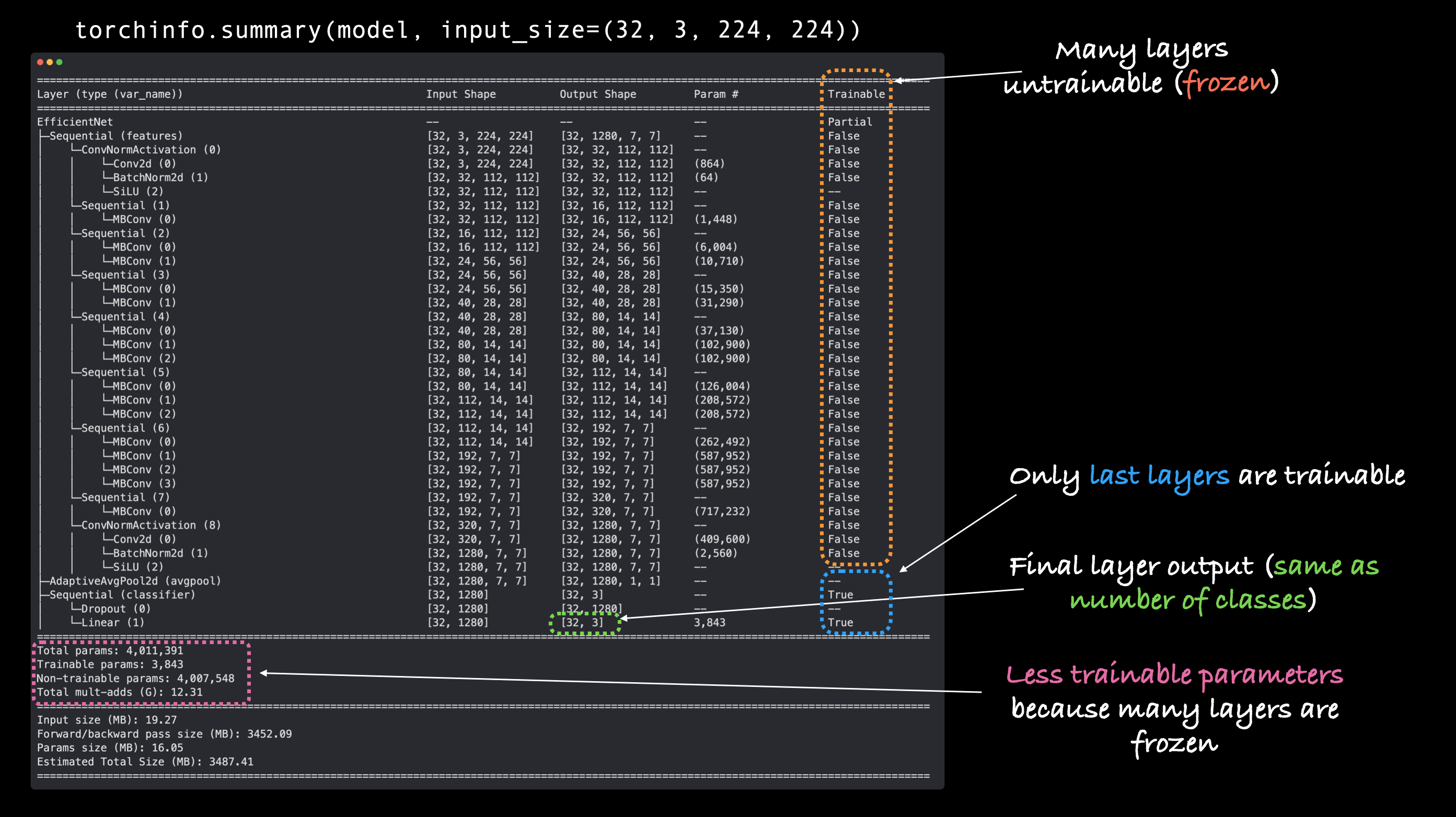
¡Ho, ho! ¡Hay algunos cambios aquí!
Repasémoslos:
- Columna entrenable: verá que muchas de las capas base (las que están en la parte "características") tienen su valor entrenable como "Falso". Esto se debe a que configuramos su atributo
requires_grad=False. A menos que cambiemos esto, estas capas no se actualizarán durante el entrenamiento futuro. - Forma de salida del
clasificador: la parte delclasificadordel modelo ahora tiene un valor de Forma de salida de[32, 3]en lugar de[32, 1000]. Su valor entrenable también es "Verdadero". Esto significa que sus parámetros se actualizarán durante el entrenamiento. En esencia, estamos usando la parte de "características" para alimentar a nuestra parte de "clasificador" con una representación base de una imagen y luego nuestra capa de "clasificador" aprenderá cómo alinear la representación base con nuestro problema. - Menos parámetros entrenables: anteriormente había 5.288.548 parámetros entrenables. Pero como congelamos muchas de las capas del modelo y solo dejamos el "clasificador" como entrenable, ahora solo hay 3843 parámetros entrenables (incluso menos que nuestro modelo TinyVGG). Aunque también hay 4.007.548 parámetros no entrenables, estos crearán una representación base de nuestras imágenes de entrada para alimentar nuestra capa "clasificadora".
Nota: Cuantos más parámetros entrenables tenga un modelo, más potencia de cálculo y más tiempo llevará entrenar. Congelar las capas base de nuestro modelo y dejarlo con parámetros menos entrenables significa que nuestro modelo debería entrenarse con bastante rapidez. Este es un gran beneficio del aprendizaje por transferencia: tomar los parámetros ya aprendidos de un modelo entrenado en un problema similar al suyo y ajustar solo ligeramente los resultados para adaptarlos a su problema.
4. Modelo de tren¶
Ahora que tenemos un modelo previamente entrenado que está semicongelado y tiene un "clasificador" personalizado, ¿qué tal si vemos el aprendizaje por transferencia en acción?
Para comenzar a entrenar, creemos una función de pérdida y un optimizador.
Como todavía estamos trabajando con clasificación de clases múltiples, usaremos nn.CrossEntropyLoss() para la función de pérdida.
Y nos quedaremos con torch.optim.Adam() como nuestro optimizador con lr=0.001.
# Definir pérdida y optimizador
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
¡Maravilloso!
Para entrenar nuestro modelo, podemos usar la función train() que definimos en 05. PyTorch Going Modular sección 04.
La función train() está en el script engine.py dentro del [ Directorio going_modular] (https://github.com/mrdbourke/pytorch-deep-learning/tree/main/going_modular/going_modular).
Veamos cuánto tiempo lleva entrenar nuestro modelo durante 5 épocas.
Nota: Aquí solo entrenaremos los parámetros
clasificadorya que todos los demás parámetros de nuestro modelo se han congelado.
# Establecer las semillas aleatorias
torch.manual_seed(42)
torch.cuda.manual_seed(42)
# iniciar el cronómetro
from timeit import default_timer as timer
start_time = timer()
# Configurar el entrenamiento y guardar los resultados.
results = engine.train(model=model,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=5,
device=device)
# Finalice el cronómetro e imprima cuánto tiempo tardó
end_time = timer()
print(f"[INFO] Total training time: {end_time-start_time:.3f} seconds")
¡Guau!
Nuestro modelo se entrenó bastante rápido (~5 segundos en mi máquina local con una GPU NVIDIA TITAN RTX/ unos 15 segundos en Google Colab con una GPU NVIDIA P100).
¡Y parece que arrasó con los resultados de nuestro modelo anterior!
Con una columna vertebral ficientnet_b0, nuestro modelo logra una precisión de casi el 85%+ en el conjunto de datos de prueba, casi el doble de lo que pudimos lograr con TinyVGG.
Nada mal para un modelo que descargamos con unas pocas líneas de código.
5. Evaluar el modelo trazando curvas de pérdida¶
Nuestro modelo parece estar funcionando bastante bien.
Tracemos sus curvas de pérdida para ver cómo se ve el entrenamiento a lo largo del tiempo.
Podemos trazar las curvas de pérdida usando la función plot_loss_curves() que creamos en [04. Sección 7.8 de conjuntos de datos personalizados de PyTorch] (https://www.learnpytorch.io/04_pytorch_custom_datasets/#78-plot-the-loss-curves-of-model-0).
La función está almacenada en el script helper_functions.py, por lo que intentaremos importarla y descargarla. script si no lo tenemos.
# Obtenga la función plot_loss_curves() de helper_functions.py, descargue el archivo si no lo tenemos
try:
from helper_functions import plot_loss_curves
except:
print("[INFO] Couldn't find helper_functions.py, downloading...")
with open("helper_functions.py", "wb") as f:
import requests
request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/helper_functions.py")
f.write(request.content)
from helper_functions import plot_loss_curves
# Trazar las curvas de pérdidas de nuestro modelo.
plot_loss_curves(results)
¡Esas son algunas curvas de pérdidas de excelente apariencia!
Parece que la pérdida de ambos conjuntos de datos (entrenamiento y prueba) va en la dirección correcta.
Lo mismo ocurre con los valores de precisión, con tendencia al alza.
Esto demuestra el poder de la transferencia de aprendizaje. El uso de un modelo previamente entrenado a menudo genera resultados bastante buenos con una pequeña cantidad de datos en menos tiempo.
Me pregunto qué pasaría si intentaras entrenar al modelo por más tiempo. ¿O si agregamos más datos?
Pregunta: Al observar las curvas de pérdida, ¿nuestro modelo parece estar sobreajustado o insuficientemente ajustado? ¿O tal vez ninguno de los dos? Pista: consulte el cuaderno 04. Conjuntos de datos personalizados de PyTorch, parte 8. ¿Cómo debería ser una curva de pérdida ideal? para obtener ideas .
6. Haga predicciones sobre imágenes del conjunto de prueba.¶
Parece que nuestro modelo funciona bien cuantitativamente pero ¿qué tal cualitativamente?
Averigüemos haciendo algunas predicciones con nuestro modelo en imágenes del conjunto de prueba (éstas no se ven durante el entrenamiento) y grafiquémoslas.
¡Visualiza, visualiza, visualiza!
Una cosa que tendremos que recordar es que para que nuestro modelo haga predicciones sobre una imagen, la imagen debe tener el mismo formato que las imágenes en las que se entrenó nuestro modelo.
Esto significa que necesitaremos asegurarnos de que nuestras imágenes tengan:
- Misma forma: si nuestras imágenes tienen formas diferentes a las que se entrenó nuestro modelo, obtendremos errores de forma.
- Mismo tipo de datos: si nuestras imágenes tienen un tipo de datos diferente (por ejemplo,
torch.int8frente atorch.float32), obtendremos errores de tipo de datos. - Mismo dispositivo: si nuestras imágenes están en un dispositivo diferente a nuestro modelo, obtendremos errores de dispositivo.
- Mismas transformaciones: si nuestro modelo se entrena con imágenes que se han transformado de cierta manera (por ejemplo, normalizadas con una media y una desviación estándar específicas) e intentamos hacer predicciones sobre imágenes transformadas de una manera diferente, estas predicciones pueden me voy.
Nota: Estos requisitos se aplican a todo tipo de datos si intentas hacer predicciones con un modelo entrenado. Los datos que desea predecir deben estar en el mismo formato en el que se entrenó su modelo.
Para hacer todo esto, crearemos una función pred_and_plot_image() para:
- Tome un modelo entrenado, una lista de nombres de clases, una ruta de archivo a una imagen de destino, un tamaño de imagen, una transformación y un dispositivo de destino.
- Abra una imagen con
PIL.Image.open(). - Cree una transformación para la imagen (por defecto será
manual_transformsque creamos anteriormente o podría usar una transformación generada a partir deweights.transforms()). - Asegúrese de que el modelo esté en el dispositivo de destino.
- Active el modo de evaluación del modelo con
model.eval()(esto desactiva capas comonn.Dropout(), por lo que no se usan para la inferencia) y el administrador de contexto del modo de inferencia. - Transforme la imagen de destino con la transformación realizada en el paso 3 y agregue una dimensión de lote adicional con
torch.unsqueeze(dim=0)para que nuestra imagen de entrada tenga la forma[batch_size, color_channels, height, width]. - Haga una predicción sobre la imagen pasándola al modelo asegurándose de que esté en el dispositivo de destino.
- Convierta los logits de salida del modelo en probabilidades de predicción con
torch.softmax(). - Convierta las probabilidades de predicción del modelo en etiquetas de predicción con
torch.argmax(). - Trace la imagen con
matplotliby establezca el título en la etiqueta de predicción del paso 9 y la probabilidad de predicción del paso 8.
Nota: Esta es una función similar a [04. Sección 11.3 de conjuntos de datos personalizados de PyTorch] (https://www.learnpytorch.io/04_pytorch_custom_datasets/#113-putting-custom-image-prediction-together-building-a-function)
pred_and_plot_image()con algunos pasos modificados .
from typing import List, Tuple
from PIL import Image
# 1. Tome un modelo entrenado, nombres de clases, ruta de imagen, tamaño de imagen, una transformación y un dispositivo de destino.
def pred_and_plot_image(model: torch.nn.Module,
image_path: str,
class_names: List[str],
image_size: Tuple[int, int] = (224, 224),
transform: torchvision.transforms = None,
device: torch.device=device):
# 2. Open image
img = Image.open(image_path)
# 3. Create transformation for image (if one doesn't exist)
if transform is not None:
image_transform = transform
else:
image_transform = transforms.Compose([
transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
### Predict on image ###
# 4. Make sure the model is on the target device
model.to(device)
# 5. Turn on model evaluation mode and inference mode
model.eval()
with torch.inference_mode():
# 6. Transform and add an extra dimension to image (model requires samples in [batch_size, color_channels, height, width])
transformed_image = image_transform(img).unsqueeze(dim=0)
# 7. Make a prediction on image with an extra dimension and send it to the target device
target_image_pred = model(transformed_image.to(device))
# 8. Convert logits -> prediction probabilities (using torch.softmax() for multi-class classification)
target_image_pred_probs = torch.softmax(target_image_pred, dim=1)
# 9. Convert prediction probabilities -> prediction labels
target_image_pred_label = torch.argmax(target_image_pred_probs, dim=1)
# 10. Plot image with predicted label and probability
plt.figure()
plt.imshow(img)
plt.title(f"Pred: {class_names[target_image_pred_label]} | Prob: {target_image_pred_probs.max():.3f}")
plt.axis(False);
¡Qué función tan atractiva!
Probémoslo haciendo predicciones sobre algunas imágenes aleatorias del conjunto de prueba.
Podemos obtener una lista de todas las rutas de las imágenes de prueba usando list(Path(test_dir).glob("*/*.jpg")), las estrellas en el método glob() dicen "cualquier archivo que coincida con este patrón ", es decir, cualquier archivo que termine en .jpg (todas nuestras imágenes).
Y luego podemos muestrear aleatoriamente varios de estos usando random.sample(populuation, k) de Python donde población es la secuencia a muestrear y k es el número de muestras a recuperar.
# Obtenga una lista aleatoria de rutas de imágenes del conjunto de prueba
import random
num_images_to_plot = 3
test_image_path_list = list(Path(test_dir).glob("*/*.jpg")) # get list all image paths from test data
test_image_path_sample = random.sample(population=test_image_path_list, # go through all of the test image paths
k=num_images_to_plot) # randomly select 'k' image paths to pred and plot
# Hacer predicciones y trazar las imágenes.
for image_path in test_image_path_sample:
pred_and_plot_image(model=model,
image_path=image_path,
class_names=class_names,
# transform=weights.transforms(), # optionally pass in a specified transform from our pretrained model weights
image_size=(224, 224))
¡Guau!
Esas predicciones parecen mucho mejores que las que nuestro modelo TinyVGG hacía anteriormente.
6.1 Hacer predicciones sobre una imagen personalizada¶
Parece que nuestro modelo obtiene buenos resultados cualitativos con los datos del conjunto de prueba.
Pero ¿qué tal nuestra propia imagen personalizada?
¡Ahí es donde está la verdadera diversión del aprendizaje automático!
Predecir sobre sus propios datos personalizados, fuera de cualquier conjunto de entrenamiento o prueba.
Para probar nuestro modelo en una imagen personalizada, importemos la antigua y fiel imagen pizza-dad.jpeg (una imagen de mi papá comiendo pizza).
Luego lo pasaremos a la función pred_and_plot_image() que creamos anteriormente y veremos qué sucede.
# Descargar imagen personalizada
import requests
# Configurar ruta de imagen personalizada
custom_image_path = data_path / "04-pizza-dad.jpeg"
# Descarga la imagen si aún no existe
if not custom_image_path.is_file():
with open(custom_image_path, "wb") as f:
# When downloading from GitHub, need to use the "raw" file link
request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/images/04-pizza-dad.jpeg")
print(f"Downloading {custom_image_path}...")
f.write(request.content)
else:
print(f"{custom_image_path} already exists, skipping download.")
# Predecir en imagen personalizada
pred_and_plot_image(model=model,
image_path=custom_image_path,
class_names=class_names)
¡Dos pulgares arriba!
¡Parece que nuestro modelo volvió a acertar!
Pero esta vez la probabilidad de predicción es mayor que la de TinyVGG (0.373) en [04. Sección 11.3 de conjuntos de datos personalizados de PyTorch] (https://www.learnpytorch.io/04_pytorch_custom_datasets/#113-putting-custom-image-prediction-together-building-a-function).
Esto indica que nuestro modelo ficientnet_b0 tiene más confianza en su predicción, mientras que nuestro modelo TinyVGG era equivalente a solo adivinar.
Principales conclusiones¶
- El aprendizaje por transferencia a menudo le permite obtener buenos resultados con una cantidad relativamente pequeña de datos personalizados.
- Conociendo el poder del aprendizaje por transferencia, es una buena idea preguntar al comienzo de cada problema: "¿Existe un modelo de buen rendimiento para mi problema?"
- Cuando utilice un modelo previamente entrenado, es importante que sus datos personalizados estén formateados/preprocesados de la misma manera que se entrenó el modelo original; de lo contrario, es posible que se degrade el rendimiento.
- Lo mismo ocurre con la predicción de datos personalizados; asegúrese de que sus datos personalizados estén en el mismo formato que los datos con los que se entrenó su modelo.
- Hay varios lugares diferentes para encontrar modelos previamente entrenados de las bibliotecas del dominio PyTorch, HuggingFace Hub y bibliotecas como
timm(Modelos de imagen de PyTorch).
Ejercicios¶
Todos los ejercicios se centran en practicar el código anterior.
Debería poder completarlos haciendo referencia a cada sección o siguiendo los recursos vinculados.
Todos los ejercicios deben completarse utilizando código independiente del dispositivo.
Recursos:
- Cuaderno de plantilla de ejercicios para 06
- Cuaderno de soluciones de ejemplo para 06 (pruebe los ejercicios antes de mirar esto)
- Vea un video tutorial de las soluciones en vivo en YouTube (errores y todo)
- Haga predicciones sobre todo el conjunto de datos de prueba y trace una matriz de confusión para los resultados de nuestro modelo en comparación con las etiquetas de verdad. Consulte 03. Sección 10 de PyTorch Computer Vision para obtener ideas.
- Obtenga las predicciones "más incorrectas" en el conjunto de datos de prueba y trace las 5 imágenes "más incorrectas". Puedes hacer esto mediante:
- Predecir en todo el conjunto de datos de prueba, almacenar las etiquetas y las probabilidades predichas.
- Ordene las predicciones por predicción incorrecta y luego probabilidades predichas descendentes, esto le dará las predicciones incorrectas con las probabilidades de predicción más altas, en otras palabras, las "más incorrectas".
- Traza las 5 imágenes "más incorrectas", ¿por qué crees que el modelo se equivocó?
- Predice tu propia imagen de pizza/filete/sushi: ¿cómo va el modelo? ¿Qué sucede si predices en una imagen que no es pizza/filete/sushi?
- Entrene el modelo de la sección 4 anterior por más tiempo (10 épocas deberían ser suficientes), ¿qué sucede con el rendimiento?
- Entrene el modelo de la sección 4 anterior con más datos, digamos el 20% de las imágenes de Food101 de pizza, bistec y sushi.
- Puede encontrar el conjunto de datos 20% de pizza, bistec y sushi en el curso GitHub. Fue creado con el cuaderno
extras/04_custom_data_creation.ipynb.
- Puede encontrar el conjunto de datos 20% de pizza, bistec y sushi en el curso GitHub. Fue creado con el cuaderno
- Pruebe un modelo diferente de
torchvision.modelsen los datos de pizza, bistec y sushi. ¿Cómo funciona este modelo?- Tendrás que cambiar el tamaño de la capa clasificadora para adaptarla a nuestro problema.
- Es posible que desee probar un EfficientNet con un número mayor que nuestro B0, ¿tal vez
torchvision.models.ficientnet_b2()?
Extracurricular¶
- Busque qué es el "ajuste de modelo" y dedique 30 minutos a investigar diferentes métodos para realizarlo con PyTorch. ¿Cómo cambiaríamos nuestro código para perfeccionarlo? Consejo: el ajuste fino generalmente funciona mejor si tiene muchos datos personalizados, mientras que la extracción de características suele ser mejor si tiene menos datos personalizados.
- Consulte la nueva/próxima [API de pesos múltiples de PyTorch] (https://pytorch.org/blog/introtaining-torchvision-new-multi-weight-support-api/) (aún en versión beta al momento de escribir este artículo, mayo 2022), es una nueva forma de realizar aprendizaje por transferencia en PyTorch. ¿Qué cambios sería necesario realizar en nuestro código para utilizar la nueva API?
- Intente crear su propio clasificador en dos clases de imágenes; por ejemplo, podría recopilar 10 fotos de su perro y el perro de sus amigos y entrenar un modelo para clasificar a los dos perros. Esta sería una buena manera de practicar la creación de un conjunto de datos y la construcción de un modelo a partir de ese conjunto de datos.